基于文本内容的敏感数据识别方法研究与实现
2022-07-04郭玲玲

摘 要:为防止敏感数据泄密事件问题,为对敏感数据的有效访问和管理工作建立基础,发明并完成了基于文本内容的敏感数据识别技术。经过对敏感数据库系统和已知秘密文件数据库系统的深入研究,实现了通过设定文本内容的敏感数据辨识阈值,进而确定未知文本内容是否存在有敏感数据。并介绍了文字预处理、文本辨识和阈值评估等工作的细节设计与完成流程等。而通过识别数据库中的一些相关文档,可确保该方法的敏感数据的处理过程简单、实用、准确。
关键词:文本内容; 敏感数据 ;识别方法
目前,防范数据泄漏的方式主要可以分成三种:安全审计、安全控制和文件加密【1】。其中,敏感数据辨识技术在防范信息泄漏的安全管理中起了关键作用。一旦可以智能地辨识并保存从内部互联网发送到外部网络上的加密信息,则能够大大简化自动辨识或访问控制规则的复杂度,从而有效地避免了敏感数据出现风险的概率。
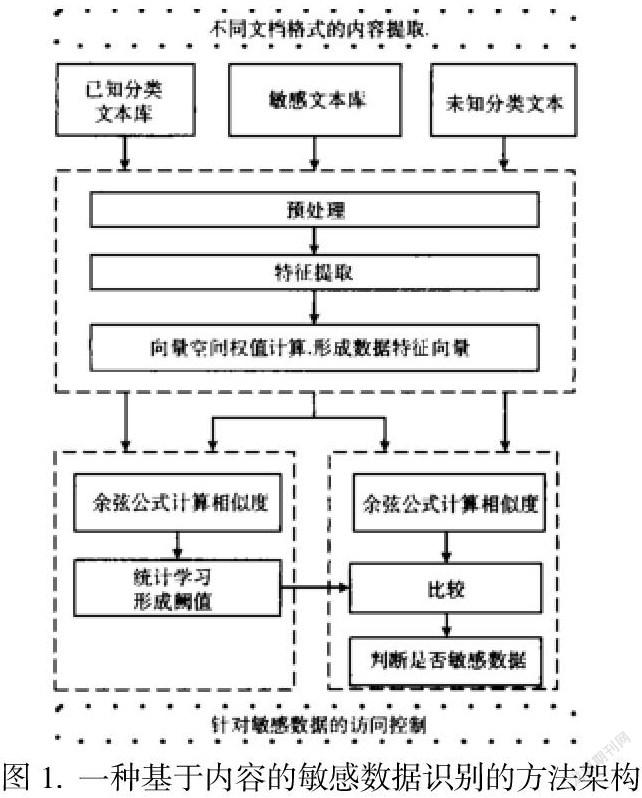
一、体系结构
文字类型可包括如下过程:首先,创建数据集合,包含培训集和测试集。接着创建文字表示模式,确定文字类型。然后学习训练集,并构建分类器。最后,进行试验与性能评价。
本文的资源收集项目主要涵盖了培训集和测试集,也涉及了敏感文本库和已有的文本库。敏感的数据库系统中,通常包括了大量的敏感数据文件,主要用于机器学习。而目前已知的分类数据库系统通常由2种小词库构成,一类是加密数据,另一类则不是加密数据,主要用来生成在统计学习时是否产生了敏感数据的阈值。
主要实现过程如下:
主要实现流程如下:
1.通过对敏感数据空间的文本数据库进行预处理和特征提取,TFIDF算法能够预测向量空间的权重,进而产生数据特征向量。
2.用敏感数据形成的特征向量计算余弦,并根据阈值确定方法确定阈值。
二、功能组成
21预处理方法
在识别文本敏感数据的过程中,第一步是通过中国科学院中文方法分析系统预处理阶段ICTCLAS,将文本分为单独的短语,并标注词性、词长和词频,以促进特征的提取效率。
通过ICTCLAS分词界面,分词文件,统计单词长度,标记词性,如名词(n)、动词(v)、形容词(a)等。
2特征提取
在文本学习与分析的过程中,若以所有词性分词为关键词,由于计算工作量大,且冗余数据太多,后期的计算误差也较大。
(1)词性选择
在文本中,可以按照词性选取最能代表文章内容的关键字,也可以用于后期特征提取,可以减少信息冗余,缩短运算步骤。因此,可以提取分析文本短语中的名词短语,并剔除其他单词,进行词性选择。
(2)词频统计
统计关键词的频率,形成分词三元组,包括短语、短语在本文中的频率和词性。T加上一个词频项,进行进一步表示。
(3)选择单词长度
在文字中,汉字往往比词汇更有表现力。计算每个关键词的长度,并删除一个单词的所有关键词。
(4)词频选择
在文本中,只出现一次的单词都是偶然的,并不具备代表性,所以可以从统计后的文本分割三元组中,删去只出现一次的短语。
2.3计算特征向量
2.3.1计算敏感数据的特征向量
计算单词权重也是度量特征值的有效方式。目前,基于统计方法的TF-IDF公式已经获得了广泛的运用,并且已经在大量的现实应用中被证实是合理和高效的。核心思想是一个词语如果在其他文献中出现的数量越少,含有的信息就越多,越能代表文献的类型。反之,一旦在其他文献中大量出现,这个词语就不具备代表性。
2.5阈值确定方法
通过对比计算结果与阈值,并分析余弦的相似性,将有助于确定文档是否对数据敏感。因此本文将通过研究现有的分析文献来判断阈值。先得到安全文档和敏感文件的词库,接着再处理和统计敏感词集的余留部分。然后,再经过定义相同范围的阈值,才能确定对数据的最敏感,并由此定义失败率最并且最能保证未知秘密文件阈值的方式。
三、具体的应用
(1)建立数据库
该系统还能够通过改变数据集中训练库的文本数据类型,来辨识在不同环境下的敏感数据。
(2)预处理和特征选择
数据说明,在特征选择过程中,词类选取后满足关键词要求的比率约为百分之三十,而字长法选取后满足关键词要求的比率约为27%,而字频分析法选取后满足关键词要求的比率约为10%。冗余分词比率将逐步减小,而后续的运算过程也将越来越简化【2】。
(3)计算特征向量
根据获得的关键字,通过TFIDF算法计算,用向量表示敏感数据,获得敏感数据的特征向量V。
(4)计算已知分类和敏感数据的余弦值
已知分类文档的特征向量计算的相同量的敏感数据,和无敏感数据或敏感数据的特征向量V余弦之间的最大相似度值。获得余弦相似度值,就必须找寻出它们之间的排列顺序。
(5)确定阈值
以长度范围为单位,从值的底部开始,每次添加一个范围单位,将每个值设置为一个阈值,并计算在该阈值环境中判断的错误率。计算后,将最低错误率作为实际阈值。
(6)阈值用于識别敏感文档
根据上述定义的阈值,对所有在未知文件库中的文件都进行了预处理和分析,并获取了基于敏感数据的特征向量。使用了对敏感数据的特征矢量运算后,就能够使用余音运算得到相应的结果。余弦运算基本原理主要包括:根据结果可确定的错误阈值为0.7,并统计未知文档库的错误识别情况和60.45%的错误率。
(7)性能测试
提升对文本内容的敏感数据的识别率,提升识别的效率,简化识别的过程,节约识别的时间,促进文本敏感数据识别技术的发展。
结语:
综上所述,本文主要研究了一个基于词性、词频和词长的简便有效的文本特征提取方式,利用智能技术来自动设定阈值,来确定对文本中是否存在有的数据敏感。该方式较以往自动设定阈值的方式,更为实用、精确、灵活。该方法既可有效地避免数据泄漏的问题,同时也可以更高效地实现对敏感数据的甄别与访问控制。在文件识别处理过程中,由于机器学习数据库大小和待处理文件长度的提高,处理效能也将大大提高,但是要求也会同时提高,因此唯有通过对技术加以持续地提高与发展,并同时持续地加以完善与优化,才可以紧跟新时代的发展脚步,从而有效地识别处文本内容中的敏感数据,为后续的工作打下一个坚实的基础,促进我国文本识别技术的发展【3】。
参考文献:
[1]林臻彪.基于数据流分析的防文件网络泄露关键技术研究[D].郑州:解放军信息工程大学,2009.
[2]李晓红.中文文本分类中的特征词抽取方法[J].计算机工程与设计,2009,30 ( 17>:4127-4129.
[3]刘蔚琴.网络敏感信息监控系统研究[D].广州:广东工业大学,2008.
作者简介:郭玲玲,出生年月:1987.2,性别:女,籍贯(精确到市):安徽省宿州市,民族:汉,学历 :本科,职称职务:工程师,研究方向:敏感信息检测。
