基于机器学习模型的企业信用风险预警研究
2022-07-02周双双张子鹏
周双双 张子鹏
摘要:本文基于大数据和机器学习方法,探索构建企业信用风险预警模型,并对公司信用类债券发行人的违约风险进行监测。在1000余个指标中,通过信息值和随机森林指标重要度计算等方法,筛选出14个对信用风险有显著影响的指标,构建机器学习模型,计算企业的违约概率,并利用ROC曲线确定预警阈值,将高于阈值的企业列入预警名单。经实际违约企业情况检验,模型预警效果良好。
关键词:机器学习 信用债券 风险监测
引言
在经济增速放缓影响企业盈利、金融去杠杆加大再融资难度、前期债务快速增长加重当期还款压力等多重因素影响下,我国贷款不良率和债券违约率有所攀升,企业债务风险已成为值得关注的金融风险之一。2014—2021年,我国债券市场违约金额逐年攀升,累计达6369.9亿元,违约主体涉及中央国有企业、地方国有企业、民营企业等。近年来,国家高度重视金融风险防范工作,将防范化解金融风险列为“三大攻坚战”之一,多次强调要夯实金融稳定的基础,深化信用体系改革。因此,对企业债务风险进行实时动态监测预警,是当前形势下贯彻落实防范化解重大金融风险工作部署的重要举措。
企业债务风险监测预警可前置风险管控端口,是防控市场信用风险的重要抓手。相对于亡羊补牢式的风险处置而言,未雨绸缪式的风险监测预警可实现风险的早预警、早发现、早防范、早处置,有利于减缓企业债务风险发生后对经济社会造成的冲击,降低风险防范化解的成本。
本文的主要创新点包括以下三方面。一是创新实证方法,充分挖掘大数据信息。传统研究主要选择企业财务数据,且数据频率以年度为主,难以准确、及时监测信用风险。本文创新性地应用机器学习模型,发挥大数据优势,通过机器对大量财务和非财务数据进行自我学习,挖掘海量、多维、动态数据信息,提高监测预警准确性、及时性和前瞻性。二是采用集成学习(Ensemble)算法,解决正负样本不均问题。我国刚性兑付打破时间较晚,违约樣本出现的时间较短,时间序列数据较少,难以使用传统的实证方法进行风险监测。本文创新性地采用基于套袋法(Bagging,全称为Bootstrap aggregating,意为自助聚合)的Ensemble算法,有效解决正负样本严重不均衡问题。三是计算每家企业的预测违约概率,提升信用区分度。传统信用评级方法是将企业信用风险分为若干档,相同档内的企业信用风险缺乏区分度。本文采用机器学习模型,计算每家企业的预测违约概率,并转换为信用评分,这样可以直观反映企业信用风险状况,显著区分不同企业之间的信用差异。
样本选择、指标筛选及模型拟合
(一)样本选择
笔者选取截至2021年6月末历史上有公募信用债发行记录的5521家企业作为建模样本,其中,含有历史违约记录1的企业有133家。对于已违约企业、无违约无存续债企业、无违约有存续债企业,观测日分别为首次违约日、最后一笔信用债到期日、2021年6月30日。自变量为样本截至观测日可获取的财务及非财务数据指标;因变量为样本历史上是否发生违约,违约记为1,未违约记为0。
(二)指标筛选
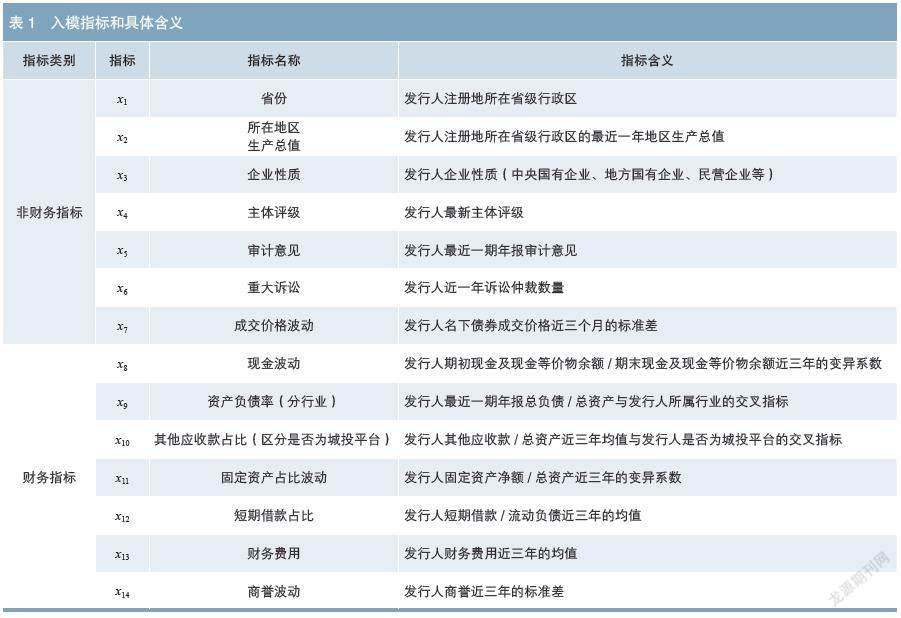
在指标方面,基于数据情况和业务理解,笔者加工1000余个指标,包括财务基础指标132个、财务衍生指标171个,通过均值、方差、变异系数加工财务分析指标903个、非财务指标152个,均已删除缺失率较高的指标。其中,财务指标基于样本观测日近三年的财报数据(含季报、半年报和年报共12个时点的财报数据)进行加工;非财务指标包含工商信息、主体评级、审计意见、法律诉讼、成交价格、地方经济财政等。
在进行指标筛选时,首先,区分定性指标和定量指标,将其进行变量分箱并计算信息值(IV),其中,定性指标依据变量取值进行分箱,定量指标基于分类决策树进行最优分箱。另外,利用随机森林算法计算指标重要度,经初步筛选,得到IV值较高或者重要度较高的指标共219个。其次,对初筛指标进行更细化的分箱调整和证据权重(WOE)转换,进行分箱调整时关注各指标分箱个数、每个分箱中的样本数、分箱中违约率单调性、可解释性等因素,使得各个指标分箱更加合理。最后,计算WOE转换后各指标的相关系数,对于共线性较强的一组指标,仅保留IV值较高或更加符合业务逻辑的一个指标,得到65个候选指标。
(三)模型拟合
在模型拟合方面,违约样本比例仅为2.41%,存在较严重的正负样本不均衡情况。基于套袋法的Ensemble算法提供了一种简单有效的改进方法,即利用套袋法在原始训练集的随机子集上构建某一种分类器的多个实例,然后集成这些分类器,形成最终预测结果。实践中,笔者采用套袋法先对未违约样本进行欠采样,即每次有放回地随机选取1/5的未违约样本,与违约样本分别组成5组训练样本。再将每组训练样本的85%划定为训练集,其余15%划定为测试集,采用逐步回归方法对65个候选指标进行筛选并拟合逻辑回归模型。拟合结果显示,由5组训练样本得到的5个逻辑回归子模型入模指标有较高的一致性。最后,选取5个子模型中显著性检验p值均小于0.05的14个指标入模,重新拟合每个子模型的回归系数,取每个子模型中回归系数的平均值,得到最终逻辑回归模型:
=-2.4537+0.8766x1+0.5205x2+0.5027x3
+0.7921x4+0.3201x5+0.2567x6+0.6611x7
+0.7471x8+0.2122x9+0.8072x10+1.4045x11
+0.5591x12+0.9113x13+0.1991x14
其中,p'为基于欠采样训练样本计算的违约概率,x1至x14为各入模指标经WOE转换之后的指标,具体含义见表1。
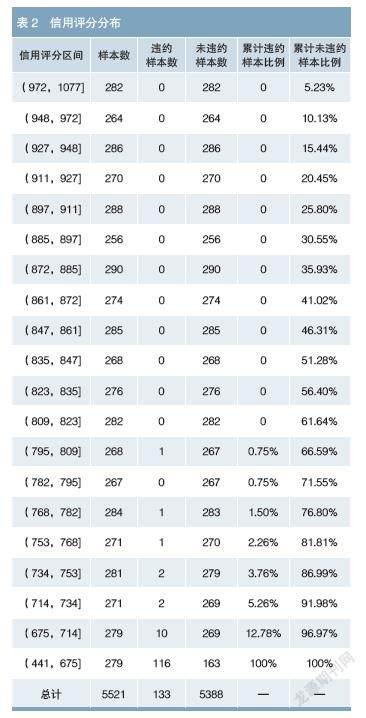
在模型结果方面,根据拟合的模型计算违约概率p',将其调整为与原始样本分布相吻合的违约概率p。然后,按照以下设置对模型进行转换:当违约几率2(odds)即p /(1-p)为1时,对应的信用评分设为600分(此时违约概率p为50%)。同时,违约几率每翻一番,设对应的信用评分降低20分;违约几率每降低一半,设对应的信用评分提高20分。转换后得到每个样本的总体信用评分以及在每个入模指标上的得分,信用评分越低表示违约风险越高。将所有样本的信用评分进行等频分箱,共分为20档,即每个信用评分区间中大约有5%的样本,各档的信用评分分布如表2所示。可以看到,87.22%的违约样本的信用评分位于信用评分最低一档,说明模型对违约样本和未违约样本有较好的区隔能力。
阈值选取和训练效果
阈值选取是影响二分类模型效果的重要因素。笔者根据模型预测违约概率,计算不同阈值下模型对应的假阳率和真陽率并绘制散点图,形成ROC曲线3。在ROC曲线上找出使假阳率尽可能低、真阳率尽可能高的点。这里通过ROC曲线确定的最优预警阈值为违约概率2.6%(对应的信用评分为705),即违约概率大于等于2.6%(信用评分小于等于705)的企业预测为高信用风险。
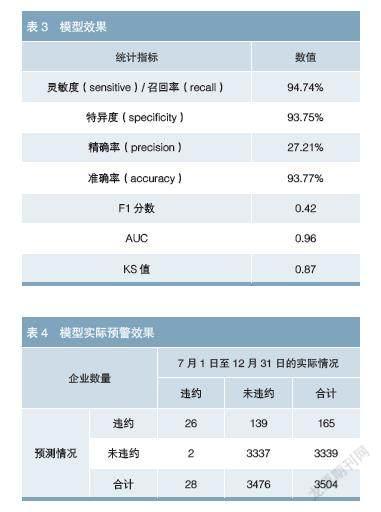
通过比较样本的预测违约概率与选取的阈值的大小,笔者对每个建模样本进行“违约”“未违约”的分类预测。将每个建模样本的模型预测情况与实际违约情况进行比较,统计模型在建模样本上的训练效果。结果显示,模型整体灵敏度(召回率)4为94.74%,即94.74%的违约企业被正确识别;特异度5为93.75%,即93.75%的未违约企业被正确识别;准确率6为93.77%,即全部企业中93.77%被正确识别;精确率7为27.21%,即在模型识别的违约企业中27.21%是正确的(见表3)。模型精确率相对不高的原因是进行企业信用风险监测的主要目的在于发现高风险企业,因此更关注模型的灵敏度,即模型命中实际违约企业的比例越高就越好,而扩大命中比例相应会降低精确率。
从通常用来检验二分类模型效果的指标来看,模型的F1分数8为0.42,AUC9为0.96,KS值10为0.87。以上各指标表明模型对违约样本的预测能力较好,对违约样本和非违约样本有较强的区隔能力,模型效果良好。
模型实证效果检验
依据模型,笔者对截至2021年6月末有存续且未违约公募信用类债券的3504家企业进行预测,并将企业按信用评分由低到高排序,将预测违约概率大于等于2.6%定义为高风险企业,共得到165家企业。跟踪其后续违约情况,实际预测效果如表4矩阵所示。数据显示,模型预警到2021年7月1日至12月31日违约的28家企业中的26家,命中率11为92.86%,且命中的26家违约企业均在高风险前100名内,说明模型对违约企业具有良好的监测预警效果。
从目前来看,使用本文模型可起到提前预警企业信用风险的作用。未来,一方面,随着实际违约企业的不断积累,应持续跟踪和评估模型效果,不断对模型进行优化迭代。另一方面,企业处于动态发展中,应以一定的频率获取企业最新的数据并代入模型,更新计算结果,实现对企业债务风险的动态监测预警。
参考文献
[1] 方匡南,范新妍,马双鸽. 基于网络结构Logistic模型的企业信用风险预警[J]. 统计研究,2016,33(4).
[2] 郭晔,黄振,王蕴. 未预期货币政策与企业债券信用利差——基于固浮利差分解的研究[J]. 金融研究,2016(6).
[3] 李萌,王近. 内部控制质量与企业债务违约风险[J]. 国际金融研究,2020(8).
[4] 陆正飞,何捷,窦欢. 谁更过度负债:国有还是非国有企业[J].经济研究,2015(11).
[5] 谭小芬,李源. 新兴市场国家非金融企业债务:现状、成因、风险与对策[J]. 国际经济评论,2018(5).
[6] 汪莉,陈诗一. 政府隐性担保、债务违约与利率决定[J].金融研究,2015(9).
作者单位:中央结算公司深圳分公司
责任编辑:陈森 刘颖
