基于循环特征与深度学习算法的建筑能耗预测方法研究
2022-06-29卢岩
卢 岩
(山东聊建现代建设有限公司,山东 聊城 252000)
新技术的不断出现,社会经济的不断提高,使得人们对于建筑的质量提出了越来越多的要求,不仅仅关于建筑质量问题,同时对于建筑智慧程度也有更多的要求[1]。随着越来越多物联网技术的使用,各种传感器、监控等使用逐渐增多,使得建筑自身的能耗越来越高[2]。如何在满足建筑智能、智慧化的同时,有效控制、预测建筑能耗的使用,对当前社会的经济发展,具有重要的意义[3]。
智慧建筑的发展,更注重用户的居住体验、环境的建立优化等方面,通过大数据技术的发展,可以有效对智慧建筑内的人员、环境、设备、能耗等方面形成海量的数据积累[4]。这些数据可以帮助人们对建筑的运行状态等有更深的了解,有效实现各类数据子系统和数据岛之间的连接,方便研究人员通过算法来对其规律等进行总结和整理[5]。对于建筑的运维人员来说,准确预测建筑能耗,可以有效降低其运行成本,并能积极响应国家电力部门的号召,具有重要的市场应用价值[6]。
为了有效提高对于建筑能耗预测的准确程度,本文提出了一种基于循环特征和深度学习算法的预测方法。该方法基于建筑能耗的循环特征,利用频谱分析的方法提取建筑日周期特征,并获得残余能耗数据,通过深度学习网络模型,进行能耗模型预测构建。最终通过实际建筑对该方法进行验证,证明其有效性。
1 基于循环特征与深度学习算法的建筑能耗预测模型
1.1 能耗预测模型方案
建筑能耗的预测方案如图1所示[7]。

图1 建筑能耗预测方案
整个预测方法的计算流程如下:
(1)根据建筑能耗的数据,利用频谱分析技术,提取其具有循环特征的数据部分,根据该特征数据来确定整个建筑能耗中的稳定时间序列部分。
(2)对原始数据进行处理,删除掉其中的稳定序列部分数据,从而提取其能耗残余数据部分,并对其进行数据转换,使其成为深度学习算法的训练数据集。
(3)将步骤2中获得的训练数据集用于构建系统集成预测模型,从而可以用于建筑残余能耗部分预测。
(4)将预测得到的残余能耗数据与循环特征中的稳定数据进行集合,实现对于整个建筑的能耗预测。
1.2 循环特征提取
建筑能耗数据是一维时间序列数据,可以等效为复杂信号数据的波形数据[8]。通过频谱分析的方法,可以将其转化成多个简单波形的叠加,并提取其循环周期特性[9]。利用傅里叶级数进行数据变换,对其进行波形分解,将数据中存在的循环特征部分进行提取[10]。
该方法已经在多个领域被证实有效,尤其是在电力预测、信号交通预测、故障检修等方面,均取得了不错的成绩,从而可以用于建筑能耗信息中的潜在数据特征挖掘工作[11]。利用该方法,可以将整个建筑中的日循环特征数据进行提取,具体步骤为:
(1)对于建筑能耗,设其为周期为T的数据系列f(t),通过傅里叶级数变换,可以得到建筑能耗的级数表示式为
(1)

将其转换成三角函数多项式的形式为
(2)
式中:系数b0,bk,ck表示形式为
(3)
(4)
(5)
为了准确获得建筑能耗的周期性特性,需要对获得到的能耗数据进行平均处理,从而可以获得该建筑的每日的平均能耗情况[12]。其表达式为
(6)
式中:pt为每天在t时刻的能耗平均值;vjt代表在第j天的t时刻时候的能耗情况;D表示建筑能耗统计的总天数。
利用频谱函数对上述日平均消耗情况进行处理,提取器日消耗的循环特性,从而得到前文所需要的稳定消耗部分[13]。计算过程为
(7)
式中:N为该建筑每天收集到的能耗数量值。为了进一步达到获取循环特征的目的,需要对于式(7)中的系数利用最小二乘法进行处理,使其可以被化简,从而得到整个能耗的循环特性。
(2)通过在原始数据中减掉循环特性部分的数据,即可获得该建筑的能耗残余情况。从而可以表示为
(8)
式中:xjt为在第j天的t时刻时候的能耗残余特征情况。能耗的残余特征情况可以有效反映出该建筑的独特性和数据随机性[14]。将能耗残余数据进行组合处理,从而可以获得该数据的一维系列{x1,x2,…,xn},将其进一步转换成深度学习网络的数据训练集(X0,y)。
1.3 深度学习网络模型构建
本文采用的深度学习的置信网络模型(deep belief network and extreme learning machine,简称DEEM)含有多个网络层,利用深度置信网络的特征提取能力,将各层网络中的数据提取出多个特征数据[15]。再将其与目标能耗有机结合,最终形成深度学习需要的多个数据训练集,并利用极限学习的方法来生成系统的能耗预测模型。
具体的模型建立过程如下:
(1)将原始数据中获得的残余能耗训练数据输入到深度置信网络模型中,通过逐层残余能耗数据提取,获得其数据特征,该数据与目标能耗残余构成新的训练数据集。
通过第i层构建的数据集为(Xi,y),其中Xi的表达式为
Xi=gi(Xi-1,Wi,αi,βi)
(9)
式中:gi为激活函数;Xi-1为上一层的输出;Wi,αi,βi为第i层与第i-1层之间的连接关系。

(10)
式中:f=1,2,…,N;λ为加权向量。表示为
(11)

(12)
(13)
与传统的深度学习相比,本文采用的模型充分利用了原始能耗数据的特征,并多次运用深度学习模型中的各层提取得到的特征数据,使预测结果更准确。
为了评估模型的预测性能优劣,选择常用的MAE(mean absolute error,表示平均绝对误差)、MAPE(mean absolute percentage error,表示平均绝对百分比误差)、RMSE(root mean square error,表示均方根误差)和r(pearson correlation coefficient,表示皮尔逊相关系数)指标作为评判指标。各指标的表达式为
(14)
(15)
(16)
(17)

2 实验结果与数据分析
2.1 实验方案
为了验证本文设计的建筑能耗预测模型的准确性,选择真实建筑作为验证对象,选择其能耗数据用于实验预测。
选择的实验建筑为网络上数据公开的百货商场,并进行能耗情况预测。每个实验中的能耗数据均包括原始数据和能耗残余两部分,并将其中的70%的数据用作样本训练,剩余的30%作为测试数据。模型数据输入个数设置为10,并将本模型与其他几种当前流行的回归模型做对比,主要选择的对比模型包括套索回归、多项式回归、岭回归等。
为了验证频谱函数挖掘的循环特征性能,需要采用贝叶斯准则(bayesian information criterion,简称BIC)来验证和评价该频谱函数的表现效果。BIC值越低意味着模型的性能越好,其表示式为

(18)

(19)

整个模型中,对于最优循环特征的寻找,通过不断增加循环分量,使得BIC值最低。提取此时的能耗情况,进行特征提取。
选择几种主流的学习方法作为本文学习方法的对比,主要包括DBN(deep belief networks,表示深度置信网络)、ELM(extreme machine learning,表示极限学习机)、SVR(support vector regression,表示支持向量回归)等。并进一步将本文获取的循环特征与上述三种方法结合,进行能耗预测,与本文模型进行数据比较。
2.2 实验结果
2.2.1 循环特征对比
为了获得合适的循环分量,将循环分量的个数从1增加至30,并比较BIC值,取数值最小的循环分量,使得循环特征更明显,且不存在过拟合的现象。图2给出了BIC值与循环分量的关系曲线,图中可以看到,当频谱函数的循环分量选择25时BIC值最低,因此将循环分量个数设置为25。

图2 不同循环分量个数的BIC值
图3显示了该建筑的循环能耗特征,通过频谱图可以看到,该百货大楼具有24小时的循环周期,且能耗每隔3~4 h出现明显的子能耗。这两个循环周期组合后形成了该建筑的循环能耗特征分量。

图3 循环特征频谱分析
图4描述了该商场能耗的500个原始数据,将该能耗中的稳定能耗部分从原始数据中去除后,可以获得残余能耗曲线数据情况。该商场的残余能耗数据情况如图5所示。
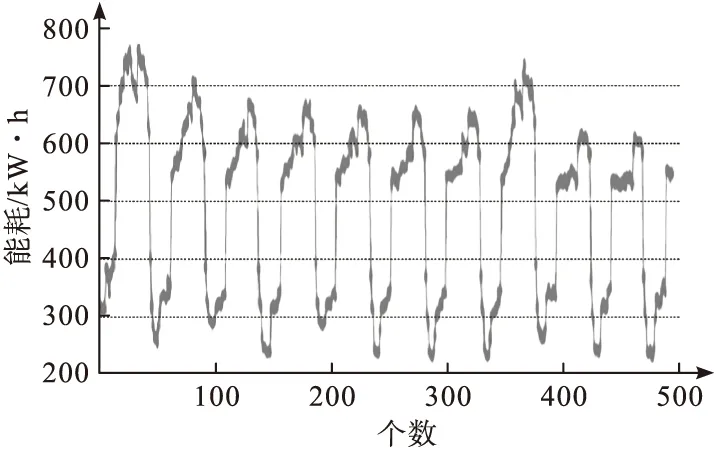
图4 商场能耗的原始数据

图5 商场残余能耗的原始数据
为了比较分析本文模型的优势,选择对比模型的参数设置为:
(1)设置套索回归模型的惩罚系数为 1,维数选择为26;
(2)设置岭回归模型的惩罚系数为 0.01,维数选择为26;
(3)设置多项式回归模型的最高维数为 10。
使用上述三个模型进行建模,并选择 ELM模型作为其参与能耗的预测模型。
每种方法分别做了10次残余能耗预测实验,并根据前文标准进行分析比较。计算结果如表1所示,给出了不同模型的预测评价结果。

表1 不同循环特征模型的预测性能结果
从表1中可以看到,在循环特性的数据提取上,相对于对比模型中的套索回归、岭回归和多项式回归,本文选择的频谱分析方法在性能上有比较大的优势,所有的评价指标中MAE指标、RMSE指标和MAPE指标均小于其他模型,证明本文模型的精确程度,同时在r指标上,频谱分析的模型比其他模型的结果更大,也同样可以证明该模型的预测精确性。
其他模型在能耗预测方面也有较好的性能,但是在这三种模型的对比方面,多项式回归模型的性能更好,比其他模型的预测精度更高。
2.2.2 学习方法对比
为了表示该模型的优越性,利用其他数据学习方法与本文算法进行对比。
选择DBN、ELM和SVR三种模型的参数以使得其获得最好的性能,参数选择为:
(1)选择DBN的结构中,共含有2个隐层,每个隐层中均含有一定数量的节点,选择节点数量为650个,对于回归函数部分,设置其隐节点的数量为35,以获得更好的预测结果;
(2)对于ELM,设定其隐节点数量为60;
(3)对于SVR,选择RBF函数为内核函数,设置惩罚系数为0.5,内核系数设置为0.6。
不同模型的预测结果如表2所示,表2中给出不同预测模型的评价情况(其中,“模型+CF”表示该模型的预测是基于循环特征,CF为利用频谱分析方法提取建筑能耗的循环特征)。

表2 不同预测模型的预测结果
从表2中可以看到,对比本文所采用的建筑原始数据、能耗混合数据以及循环特征-残余能耗数据,比较基于SVR、ELM、DBN 和本文所采用DEEM模型的能耗预测结果,从而可以证明本文方法的效果。
而且,循环特征结合能耗残余数据的预测模型,其预测结果也会由于基于原始数据和能耗混合数据的预测。在本文的预测结果评价指标上,DEEM+CF模型准确率优于DEEM模型21.77%,DBN+CF模型准确率优于DBN模型23.32%,ELM+CF模型准确率优于ELM模型25.17%,SVR+CF模型准确率优于SVR模型27.48%。
同时,对于循环特征结合能耗残余数据预测中,本文使用的DEEM+CF方法也优于DBN+CF、ELM+CF 和 SVR+CF模型。在本文的预测结果评价指标上,DEEM+CF的预测精度均是最高,优于DBN+CF模型3.48%,优于ELM+CF模型6.54%、由于SVR+CF模型10.22%。而且,根据标准差的对比情况,本文采用DEEM+CF模型预测稳定性很高,优于DBN、ELM模型。
2.3 实验分析
根据前文的实验结果可以发现,对于智能建筑的能耗问题,通过频谱分析,确认其具有明显的日循环特性。经过频谱分析后,去除周期特征得到的残余能耗数据随机性更明显。
基于循环特征和深度学习算法的建筑能耗预测模型比基于原始数据的训练模型预测准确度更高,而且预测稳定性也更高。
相比其他预测模型,基于循环特征和深度学习的方法可以精准的对于建筑能耗进行预测,相比于其他模型和数据算法等,本文的方法更有效。
3 结 论
为了有效处理智能建筑的能耗预测问题,本文提出了基于循环特征和深度学习算法的预测模型。利用频谱分析的方式,得到建筑的残余能耗,并将其作为训练数据,用于能耗的预测。将本文的算法与其他算法做比较,无论是与其他回归模型进行对比还是与其他学习方法进行对比,本文的方法在预测的准确性和稳定性方面都远远优于其他。可以证明本文算法的有效性,为建筑能耗的预测提供了一种新的分析预测方法和手段。
