卷烟终端陈列识别方法研究
2022-06-26张侃弘周欣然栾晓宇李敏刚
张侃弘,周欣然,栾晓宇,2,李敏刚
(1.上海烟草集团有限责任公司 信息中心,上海 200082;2.上海烟草集团有限责任公司 营销中心,上海 200082)
随着卷烟精准营销工作不断升级,及时准确地掌握零售终端的店面货架陈列情况,对卷烟陈列分析和投放策略制定具有显著价值。目前已经采集了海量的卷烟终端陈列图像信息,但是缺少有效的手段将其有效转换为数值信息,以便实施自动化的数据挖掘。因此,研究一套在线智能陈列识别方法,十分必要。
针对卷烟品牌培育策略,孙晶[1]提出了使用图像识别技术分析柜台陈列,建立消费者与卷烟品牌的信息关联。冯军平等[2]也就AI技术在卷烟营销的应用做了展望。但文献[1-2]均未对技术实现提供可执行的系统方案。早期研究人员大多利用传统的图像处理技术对货架陈列商品进行识别。陈哲凡等[3]在SURF(Speeded Up Robust Features)算法基础上提出了一种基于匹配角度聚类的匹配算法。郑建彬等[4]提出了一种改进的SIFT(Scale-invariant feature transform)误匹配点剔除方法。这类方法都是通过模板图和待检测目标的匹配度得出识别结果,由于无法针对待检测目标建立模型,识别效果很容易达到瓶颈。通过Haar、LBP、HOG结合SVM,也可以实现检测识别功能,但仅依赖人工设计的特征无法利用海量数据优化特征提取质量,难以应对越来越多样复杂的环境。
近十年来,深度学习开始广泛应用,Faster R-CNN[5]是一个经典的二阶段目标检测器,调节其预设锚框的比例可以适应真实场景下的不同尺寸比例的商品目标。此外一种单阶段高效并具有在线难易样本平衡的检测器RetinaNet[6]被较广泛地应用。另一种广泛应用的算法YoloV4[7],结合了大量的有效策略且兼顾速度和性能的平衡。然而利用单一的检测手段,无法对柜台的陈列情况做出准确分析,对香烟相似细品类识别能力也不足。本文结合目标检测、度量学习等技术,提出了一种融合标签平滑策略和经纬度信息的陈列识别方法,大大提升了陈列识别准确率,为后续数据分析和挖掘提供了可靠的依据。
1 研究方法
1.1 整体流程
陈列分析系统的整体流程主要分为图像采集、烟盒检测、烟盒对齐、烟盒细分类和陈列分析5个部分,如图1所示。
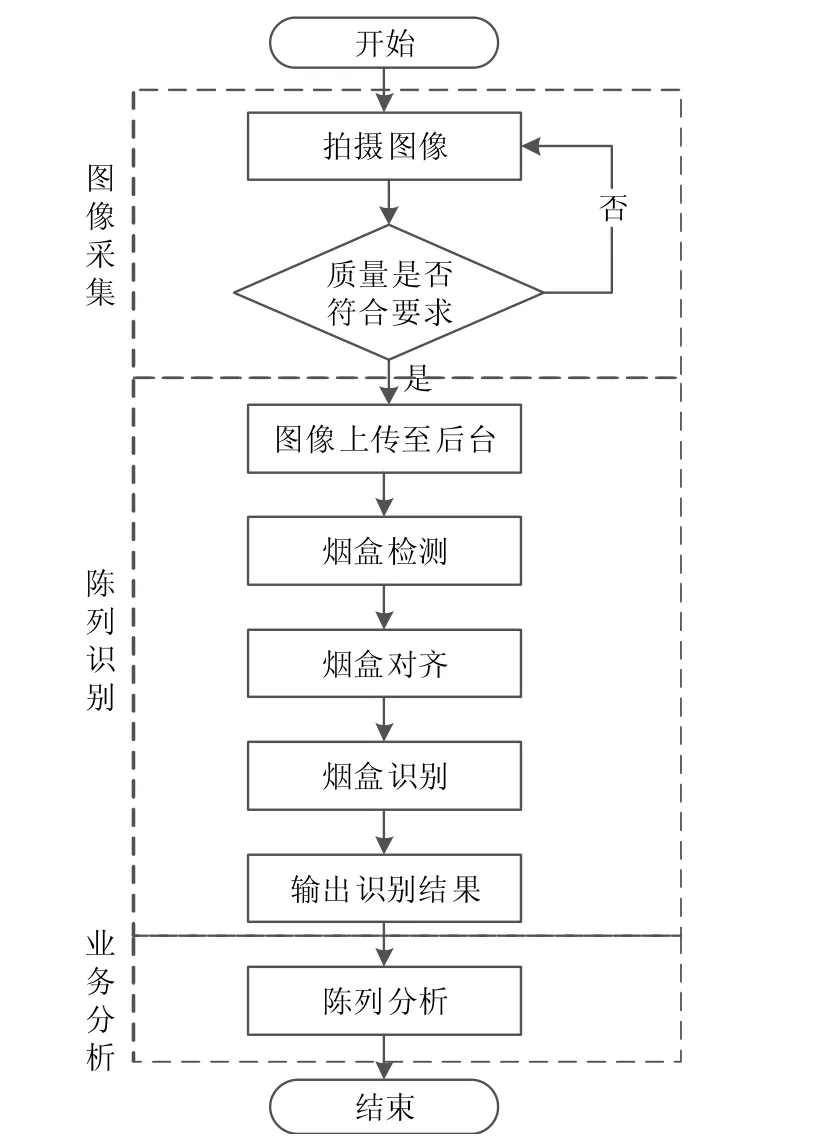
图1 柜台陈列分析流程示意图
1.2 图像采集
图像采集的质量高低对最终的识别效果有重大影响,通过制定图像采集规范和强化采集前端预处理两类措施来提高图像采集质量。图像采集人员应该按照表1的规范要求来采集图像。
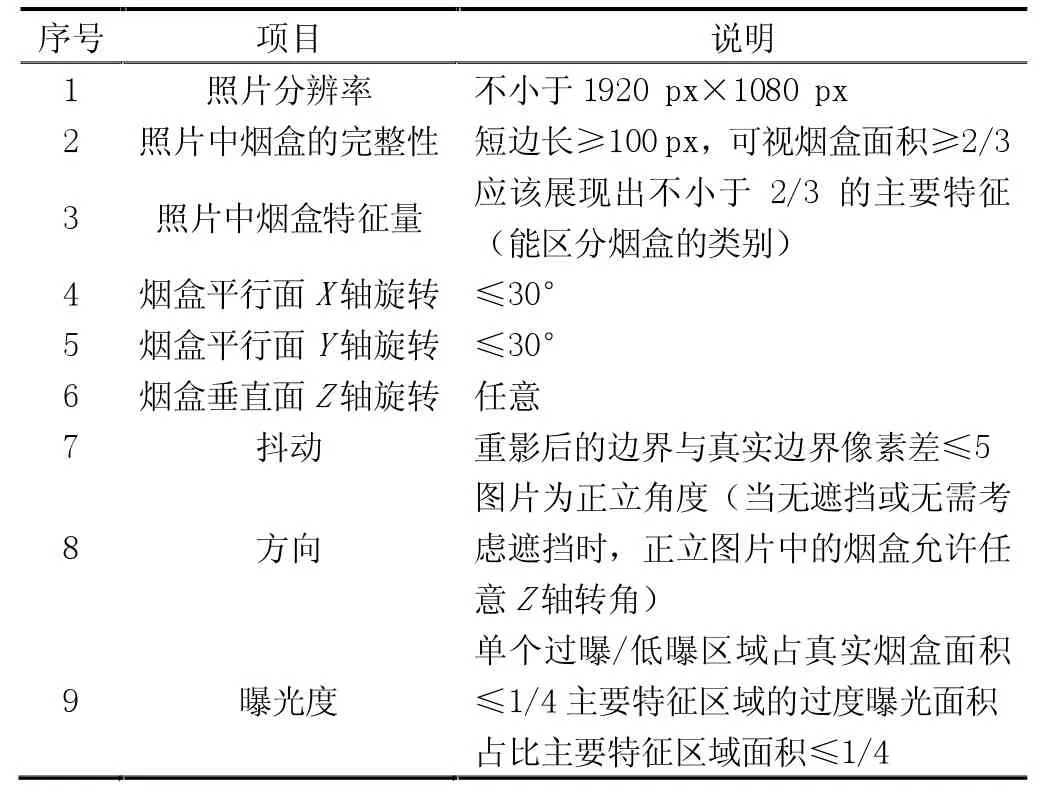
表1 数据标准表
前端预处理程序安装在采集设备上,主要通过调用OpenCV的图像处理接口实现,重点检测以下几类问题:(1)非烟盒状物体的判别;(2)清晰度的检测;(3)防作弊。一旦发现这些问题,程序就会提示采集人员进行重新采集。
1.3 烟盒检测
烟盒检测即检测出烟盒的图像坐标位置,这是烟盒识别的前提,其结果直接影响烟盒识别的效果。考虑到柜台陈列场景中烟盒的尺度多变且光线复杂,本文选择兼顾速度和性能的YoloV4网络作为烟盒检测网络。然而YoloV4网络原有的锚框是针对COCO数据集设计的,不太适合长宽比较为固定的烟盒物体。为此,通过K-means聚类算法针对烟盒数据重新聚类,得到合适的九种锚框:[28,45]、[36,75]、[51,89]、[60,127]、[93,91]、[91,165]、[131,217]、[179,294]、[465,458]。
1.3.1 锚框(anchor box)的作用
YoloV4通过3个不同尺度的特征层预测目标,每个特征层在基于预设的3个锚框回归目标尺寸和确定类别。锚框的尺寸越靠近真实样本尺寸分布的聚类中心,网络初始时便具备更高的回归精度,有利于网络收敛。
1.3.2 K-means聚类
K-means均值聚类算法(K-means clustering algorithm)是一种迭代求解的聚类分析算法,本文使用步骤如下。
(1)统计训练数据集中所有的检测对象的宽高。
(2)从所有样本中随机选择k个框作为二维聚类中心点。
(3)计算每个真实框(ground truth)和每个聚类中心点的距离,将所有的ground truth分配给距离最近的聚类中心。
(4)所有真实框分配完毕以后,对每个簇重新计算聚类中心点,方式为对该簇中所有真实框取均值。
(5)重复步骤(3)和(4),直到聚类中心改变量足够小,得到k个聚类中心即为目标锚框,此处k为9。
(6)考虑到K-means的收敛结果受到初始随机影响,容易收敛到局部最优值。故多次调整随机数种子,重复(1)到(5)步骤得到多组结果。然后计算每组锚框的距离、求和以及排序,选择居中的那一组作为最终选择。
1.4 烟盒对齐
采集图像时采集设备镜头和柜台陈列面会存在倾斜和俯仰角,这会使烟盒在图像中呈现出姿态差异性,影响识别效果。本文采用相似变换技术做烟盒姿态对齐操作,以降低姿态差异影响。首先对分辨率固定为200×300像素的烟盒图片,人工标注烟盒4个角点(简称原始角点),并从左上角按顺时针排序,设置其对应目标角点坐标为(10,10)、(190,10)、(190,290)、(10,290);然后利用Opencv求解原始角点到目标角点的相似变换矩阵M,M的公式可表示为:
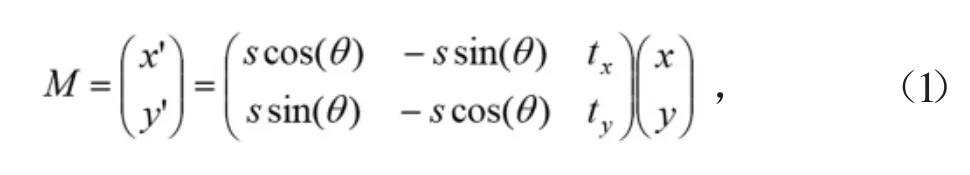
其中(x,y)代表原始点位,(x′,y′)代表目标点位,s为缩放因子,θ为旋转因子,tx和ty为平移因子。设计卷积网络并以此为监督加以训练,网络预测变换矩阵内的变换因子,以实现对齐目的,网络图如图2所示。

图2 烟盒对齐网络图
该网络的输入为(300,200,3)尺寸的烟盒图片,输出4维向量值[θ,s,tx,ty]。在烟盒对齐网络中采用Smooth_L1 loss作为回归损失,它收敛快、对离群点和异常值不敏感、不易发散,公式如下:

其中x表示网络预测值与真实值的差值。
1.5 标签平滑
烟盒对齐之后,可以将其判别为三种大类:已入库的烟盒类别(简称已知类别)、未入库的烟盒类别(简称未知烟盒)、非烟盒物体。硬标签将所有类别的距离都置于相同距离,以三类为例:中华软、中华硬、钻石荷花三类硬标签分别表示为[1,0,0]、[0,1,0]、[0,0,1],两两之间的距离均为1,显然不太合理。而软标签[0.9,0.1,0]、[0.1,0.9,0]、[0,0,1]更利于表达相似关系,对未知烟盒及非烟盒的度量也更具区分性。标签平滑[8]将硬标签转为软标签,属于正则化策略。做法是首先将训练集随机分为两部分,一部分通过图3的Efficient-Net骨干网络[9]训练一个细分类模型,利用模型对另一部分数据做Top-N投票(投票值即模型预估相似度);然后将人工标注的one-hot向量更换为人工标注和基础模型预估相似度的加权融合标签,公式如下:

其中∂∈(0,1)为融合系数,yhi为硬标签向量;ysi为软标签向量;i表示第i类烟盒。
1.6 融合经纬度的细粒度度量网络
为提高细粒度度量学习网络的识别率,将经纬度值特征与图像特征拼接作为融合特征,改进特征提取效果。首先将烟盒图片以及相对应的经纬度坐标值作为网络输入;之后用Efficientnet作为骨干网络提取特征,其中图像经过该网络映射为N维特征向量,经纬度值经多层全连接映射为M维特征向量;接着对N维特征向量和M维特征向量做Concate操作,得到(N+M)维的特征向量Embeddings;最后采用Arcface度量损失解决细粒度分类问题。其网络结构如图3所示。
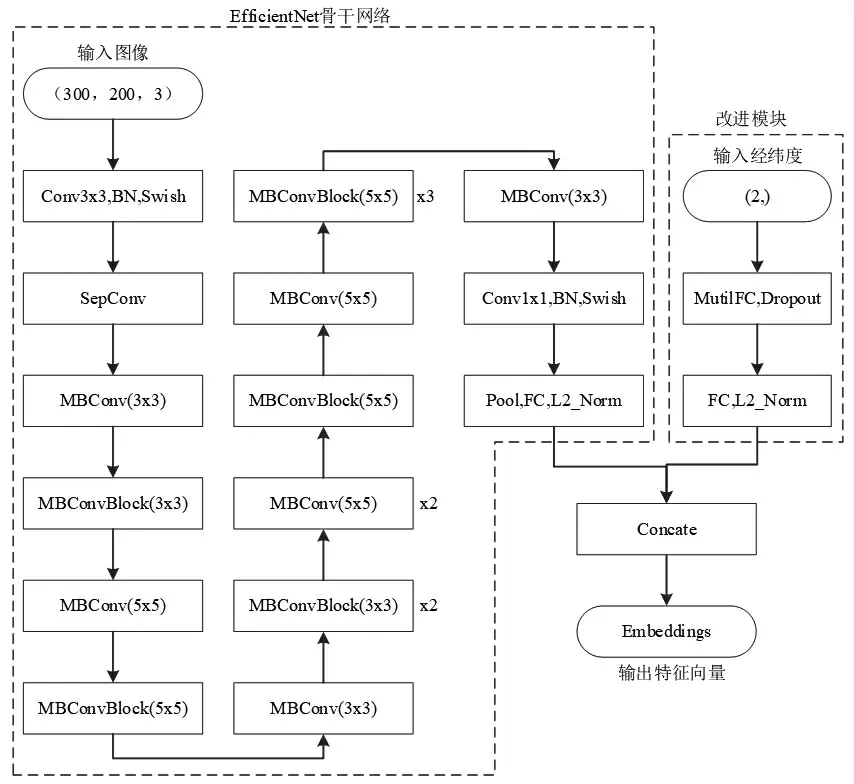
图3 烟盒细粒度度量网络结构
在度量网络中融合图像特征和经纬度特征,并以经纬度信息作为部分先验信息,其意义为:样本的经纬度体现为样本附加属性,如果样本的经纬度分支向量度量距离近,在整个向量距离的阈值约束下,便体现为放松对纹理相似性的要求。反之,如果经纬度分支向量距离较远,体现了样本采集点和库中数据分布特征差距大,则要加重对纹理相似性的验证。经纬度分支网络起到了挖掘样本分布的作用。考虑到实际推理时,存在经纬度超出训练数据集的采集范围以及未采集到经纬度的情况,此时统一将经纬度置为[-1,-1],特征融合示意图如图4所示。

图4 图像和经纬度特征融合示意图
1.7 损失函数
本文中采用Arcface作为基础度量损失函数[10],其主要优点是:同类问题的人脸识别领域表现良好,在公开数据集LFW上达到了99.53%的准确率。并且复杂性低、易于编程实现、训练效率高、直接优化弧度(Geodesic distance margin)与余弦度量方式目标一致。其工作流程图如图5所示。

图5 Arcface工作流程图
Arcface的损失可用以下公式表示:
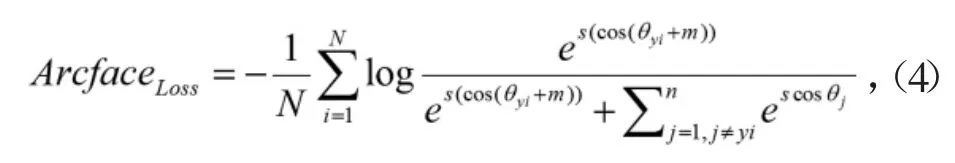
其中N为训练批次数,i为网络输出Embeddings,s为特征尺度,cosθj为每类权重,θyi为i与类别权重的角度。
2 实验分析
2.1 实验环境
软件环境为:Ubuntu16.04的操作系统、Pycharm2019的IDE工具、python3.7(64位)的开发环境以及模型训练时使用的并行计算平台CUDA10.0、CUDNN7.5。硬件环境为:Inter Xeon(R)Silver 4114@2.2 GHz×40、125.6 GB内 存、4×Quadro RTX 6000显卡(24 G显存)。
2.2 实验数据
本文采用rp2k公开数据集和采自A省的烟盒陈列图像进行试验,包含351个品规,共计71 062张图像。将此数据集划分为两份训练集,分别为17 094张、17 110张,验证集16 525张(包含样本平衡后多余数据)和测试集20 333张。
2.3 实验准备
(1)图片预处理
所有训练样本均归一化到[0,1]之间、白化操作。
(2)基准网络和预训练权重
为了便于对比实验结果,基准网络采用ImageNet预训练分类网络EfficientNet-b3作为骨干网,同时修改最后全连接层输出维度作为嵌入向量,并对此向量进行L2正则化[11]。
(3)训练参数配置
每次实验均采用相同的超参数配置。本文中使用Adam优化器,最大训练批次为15,BatchSize为128,初始学习率为0.001且学习率分别在8、10、12批次时依次衰减10%。在整个网络迭代过程中,输入的每个batch样本都做随机采样处理。
2.4 实验结果及分析
本文实验主要分为三部分:标签平滑实验、经纬度融合实验和优化策略消融实验。
2.4.1 标签平滑实验
(1)本文把加入标签平滑策略的基准网络作为实验网络,在数据、训练超参数和网络结构等完全相同的条件下,修改标签平滑中融合系数∂,∂=0.0时表示基准网络。做了以下对比实验。实验结果如图6所示。
由图6可知:当融合系数∂=0.1时,网络在Top1和Top5的准确率分别为92.7%和98.2%,比基准网络的准确率在Top1和Top5上分别高出0.5%和1.9%;当融合系数∂分别为0.2、0.3和0.4时,准确率都低于∂=0.1的准确率;实验发现当融合系数∂=0.1时网络最佳。
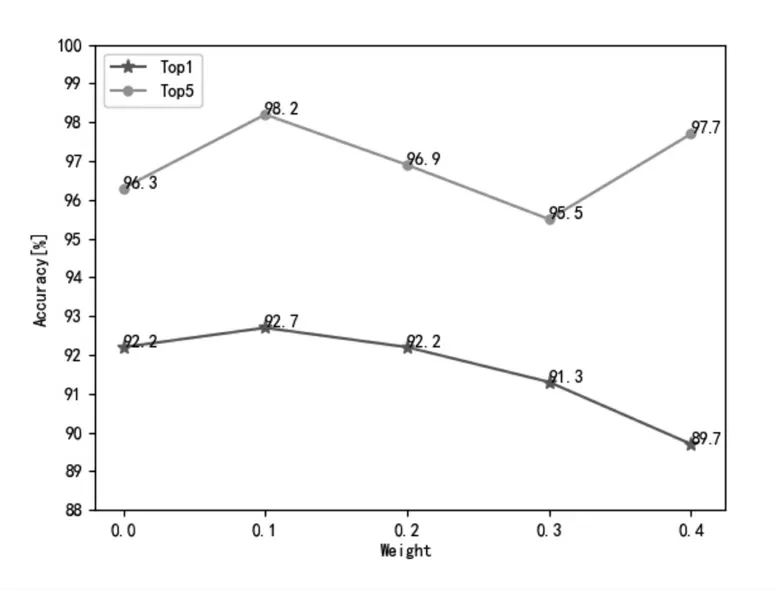
图6 不同权重的标签平滑实验结果
(2)为验证引入标签平滑策略对未知烟盒及非烟盒的识别有效,本文保证数据和训练参数不变的条件下,分别训练基准网络和基准网络+标签平滑网络,并在rp2k商品数据集上测试,统计模型对未知烟盒及非烟盒的识别率。实验结果见表2。
由表2可知:基准网络+标签平滑模型在rp2k商品数据测试集上测试,在未知烟盒与非烟盒物体的区分上准确率提高了4.5%,表明引入标签平滑策略对未知烟盒及非烟盒的识别有效。
2.4.2 经纬度融合实验
(1)本文把加入经纬度策略的基准网络作为实验网络,在数据、训练超参数等完全相同的条件下,只改变多层感知机的层数,做了以下对比实验,实验结果如图7所示。
在图7中,横坐标BL代表基准网络;横坐标M1代表基准网络+3层FC经纬度网络;横坐标M2代表基准网络+5层FC经纬度网络;横坐标M3代表基准网络+7层FC经纬度网络。由实验结果可得出:使用基准网络+7层FC经纬度网络的准确率最高、效果最好。

图7 不同数量FC层的实验结果
(2)本文把加入经纬度策略的基准网络作为实验网络,在训练超参数和网络结构等完全相同的条件下,只改变带有经纬度的样本占训练集的百分比,做了以下对比实验,实验结果如图8所示。

图8 样本带有不同经纬度量的实验结果
在图8中,横坐标数值表示带有经纬度信息的样本占总样本的比率,纵坐标数值表示细分类准确率。由实验数据可得:当带有经纬度信息的样本占总样本的比率为100%时,模型的识别效果最好,在Top1和Top5上准确率分别为92.6%和96.7%,比基准网络在Top1和Top5上都高出0.4%。
(3)为验证经纬度融合对基准网络的影响,做了以下对比实验,实验结果如图9所示。
在图9中横坐标M1为基准网络;横坐标M2为基准网络+经纬度融合(FC=7)网络,训练时使用的数据与M1相同,都是不带有经纬度信息的数据。由图可知:M2与M1相比,经纬度模块加入基准网络时,不使用带有经纬度信息的样本训练,不影响基准网络的精度。

图9 经纬度信息对基准网络的影响
2.4.3优化策略消融实验
本文以基准网络为基础,加入标签平滑和经纬度融合策略做了以下消融实验。实验一为不使用标签平滑或经纬度融合策略的基准网络;实验二为基准网络+标签平滑的实验,标签平滑的融合系数α=0.1;实验三为基准网络+经纬度融合的实验,其中提取经纬度特征的多层感知机为5层,带有经纬度的样本占训练样本的50%;试验四为基准网络+标签平滑+经纬度融合的实验,其中标签平滑的融合系数与实验二相同,经纬度融合的信息与实验三相同。实验结果见表3。

表3 实验结果
由表3可知:标签平滑策略在Top1和Top5的准确率上分别比基准网络高0.5%和1.9%;经纬度融合策略在Top1和Top5的准确率上均比基准网络高0.4%;标签融合+经纬度融合策略在Top1准确率上比基准网络高1.5%。由实验结果可得:本文提出的标签平滑+经纬度融合策略对基准网络的优化有效,比基准网络的识别精确率高1.5%。
3 应用分析
模型训练和调优后,将其部署到Ubuntu服务器,对A省的9个地市跟踪运行了3个月。在这期间,安排采集人员每周拜访门店1次,每次采集约5张照片。采集的照片数量和模型检出效果见表4。
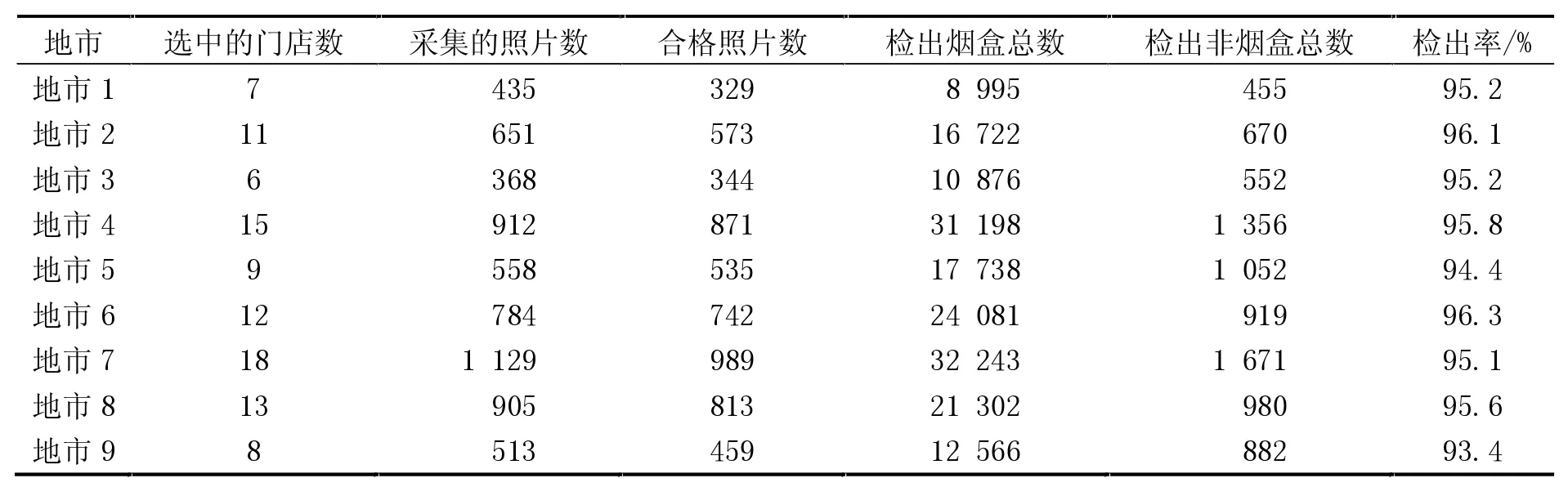
表4 样本采集情况和模型检出结果
在表4中,“合格照片数”是由人工根据表1所述质量标准筛选出来的;“检出烟盒总数”是指模型从对应的图像数据集中识别出的烟盒总数(个别识别出的烟盒有可能是非烟盒物体);“检出非烟盒总数”是模型从对应数据集中识别出的非烟盒总数(个别识别出的非烟盒有可能是烟盒物体)。
从每个地市随机抽取10张合格的照片,进行人工核对,结果见表5。
在表5中,“实际烟盒总数”是人工统计出的结果,“识别正确烟盒总数”是人工核对模型识别结果后得到的数量。实际检出率=正确检出烟盒总数/实际烟盒总数;细分类准确率=识别正确烟盒总数/正确检出烟盒总数;总的准确率=识别正确烟盒总数/实际烟盒总数。从表中数据可以看出,平均总的准确率为92.0%,其中平均细分类准确率为96.7%,表明该模型在实际应用中有效。
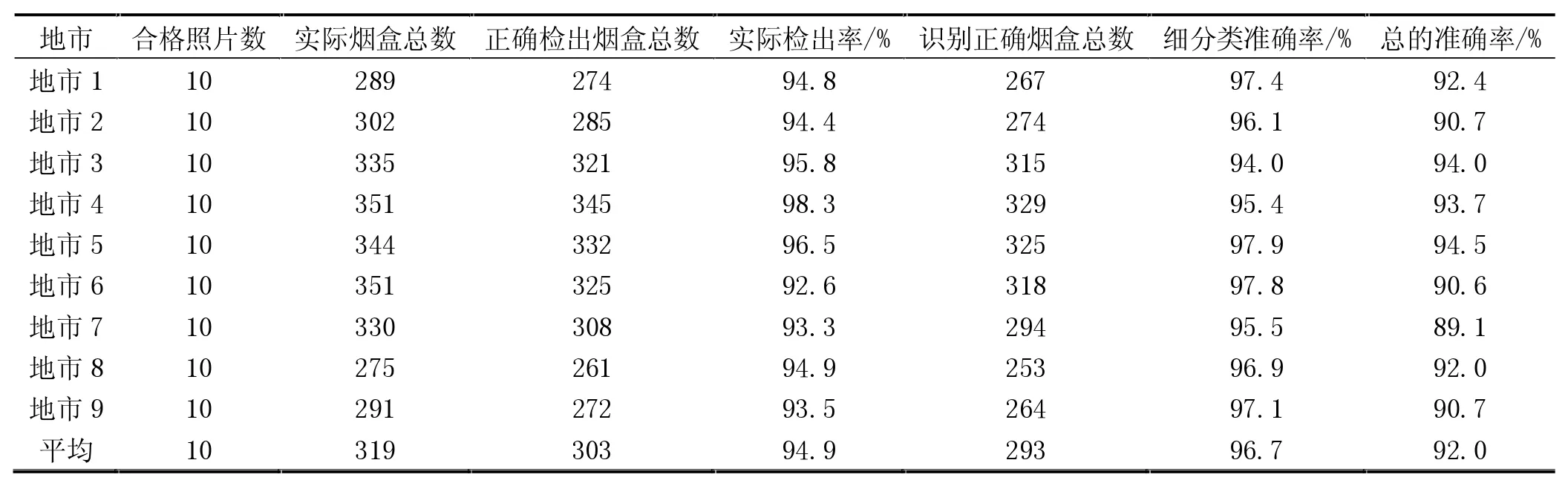
表5 人工核对结果
4 结论
本文提出了一种卷烟终端陈列分析方法,特别对烟盒细类识别进行了改进,实验结果表明:本文方法在实验条件下的Top1准确率为93.7%,高于基准方法1.5%,在应用环境下的识别准确率为92%,能够有效区分烟盒细品类,为柜台陈列模型分析提供了可靠数据支撑,有助于分析门店陈列和产品销售的关系,为市场人员提供改善品牌卷烟陈列建议。其贡献如下。
(1)该方法提出一种完整的卷烟终端识别流程。
(2)针对烟盒细类高相似度,设计了针对性的标签平滑策略。
(3)根据烟盒的地区分布差异,提出经纬度信息的融合网络结构,有效约束了嵌入空间的搜索范围,进一步提高识别精度。
(4)应用环境下的卷烟陈列识别的准确率达到92%,可以用于改善业务分析,比如提高上柜率分析的效率。
