基于深度学习的单目图像深度信息恢复
2022-06-23秦文光付新竹
秦文光,付新竹,张 楠
(1.山西中煤华晋集团公司王家岭矿,山西运城 043300;2.中国矿业大学,江苏徐州 221100)
0 引言
随着计算机视觉技术在日常生活中的普遍应用[1-2],通过算法进行图像处理在近年获得极大关注。计算机视觉研究领域的两大主要任务为物体识别[3-4]和三维重建[5-6],2012 年深度学习兴起后,三维重建打开了更为广泛的思考角度,三维重建的关键就是获取图像对应的真实深度信息。从图像中估计场景的深度信息在计算机视觉领域已经探索很久了,在深度学习的推动下应用广泛。如最近比较流行增强现实和虚拟现实[7],就是借助于场景的深度信息来进行视觉渲染以达到更好的效果。对于更高级的机器视觉任务,如机器人导航[8]和汽车自动驾驶[9-10]的导航定位系统,就是通过场景的深度信息实现精准定位,完成实际导航过程中障碍物躲避和智能路线规划等任务。
由于卷积神经网络(Convolution Neural Network,CNN)的进步和发展,单目图像的深度估计效果逐渐增强,Eigen 和Fergus[11]构建了可获取全局特征的粗网络结构和可获取局部特征的精网络结构,再联合两个架构层获取的特征得到深度信息。Tompson 等[12]提出了将深度卷积网络和马尔科夫随机场(MRF)进行结合,用于单幅图像的人体姿态识别。Li 等[13]提出了一种深度卷积神经网络(DCNN)用于预测图像的法线和深度信息,使用条件随机场(CRF)对得到的深度图进行后处理。Liu 等[14]还提出了一种基于CNN 和CRF 的深度估计方法。Luo W 等[15]提出了一种使用交叉熵的匹配网络,有助于计算所有像素的浮动差值。Laina 等[16]使用深度残差网络进行深度估计,提出了一种在网络中高效学习特征映射上采样的方法以提高输出图像的分辨率。上述文献都得到了相对不错的研究结果,但图像深度信息恢复网络中参数量过大导致图像细节深度信息的丢失进而预测结果准确率不高的问题一直存在。
为了解决上述难题,本文提出一种改进的RG-ResNet网络模型。将大量的图像和对应深度信息的数据对输入到网络中进行训练,通过卷积神经网络自动提取输入待恢复图像的特征信息并输出对应的深度图,以此实现对输入的单张RGB 图像的深度估计,得到准确的图像深度恢复结果。
1 RG-ResNet网络模型
分组卷积(Groupable Convolution,GConv)的方式可以大幅降低网络参数数量,但存在组与组之间信息不相关的缺点。为此,本文提出一种改进的RG-ResNet 网络模型来实现单目图像的深度信息恢复。主要研究内容及创新点有:(1)基于分组卷积的思想提出相关联分组卷积(Related Groupable Convolution,RGConv),解决分组卷积组与组之间信息无法关联的缺陷,保留分组卷积少参数数量的优势;(2)基于RGConv 提出改进后的RG-ResNet残差模块;(3)结合编-解码端到端的网络结构构建RG-ResNet网络模型。
1.1 相关联分组卷积
GConv 是当前轻量型网络设计的核心模块,简洁且参数量低。GConv 易于实施,但是通过图1 所示的分组卷积计算方式发现,每次卷积都是对该组内的信息进行卷积,造成了不同组内的通道数据无关联。为了提升通道间的相关联性,同时保留GConv 少参数量和低计算量的优势,本文提出了一种能够使得不同分组的通道信息可以交流的分组方式RGConv。
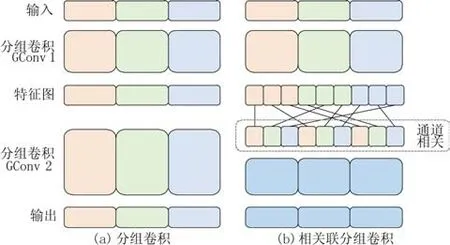
图1 分组卷积和相关联分组卷积Fig.1 Groupable convolution and related groupable convolution
图2 描述了具体的分组规则:将上一层分组卷积的结果进行1~3 标号,后对其每一个标号组续分3 组,同以1~3标号,续分组以其父组号和本身标号组成新的标号按照矩阵排列,根据矩阵中下标不共线规则从左至右连线,组成新的排序组进行后续的卷积操作。图1 右图同样经过GConv1得到对应的特征图,将得到的三组特征继续划分为3组,然后根据图2所示的分组规则进行对应组合,最终使得输出结果可融合不同组的通道信息。

图2 相关联卷积分组规则Fig.2 Grouping rules ofrelated Convolution
1.2 RG-ResNet残差模块
ResNet 深层残差结构用于降维和升维的1*1 卷积实质上是特殊的GConv,相当于对输入特征图的每个通道都分配了一个通道数为1的1*1卷积核进行卷积。因此基于ResNet 的残差网络模块增加RGConv 结构,改进后的模块如图3 中左图(stride=1)所示,将ResNet 中的1*1卷积全部替换为RGConv,将原有的3*3 卷积替换为GConv,即为所提的RG-ResNet残差模块。

图3 RG-ResNet残差模块Fig.3 Residual structure of RG-ResNet
图3 所示分别为stride=1 和stride=2 的残差结构,stride=1 为左图,主分支通过1*1 的RGConv 的具体操作为:首先通过分组数为输入通道数的GConv,而后通过相关联分组规则输出新排列的通道组。输出经过BN 层和ReLU 激活函数后,进行3*3的分组卷积(分组数为输入通道数),再次经过BN 层后进行1*1 的RGConv,与侧分支的输入通道进行同维度的相加,结果经过ReLU 激活函数输出。右图为当stride=2 时的RG-ResNet 残差结构,输入首先通过主分支同stride=1 的结构,侧分支将上一层的输出进行平均池化操作,而后与stride=1 的结构不同在于这里主、侧分支进行通道拼接而非同维度的相加操作,拼接后的结果经过ReLU激活函数输出。
1.3 网络结构
网络整体结构如图4所示,采用编-解码结构进行网络搭建。编码部分采用RG-ResNet 残差结构堆叠进行特征提取,解码结构采用上采样逐步恢复图像的细节特征和空间分辨率。

图4 RG-ResNet整体结构Fig.4 The structure of RG-ResNet
1.3.1 编码器构建
网络的编码器部分采用所提的RG-ResNet 残差模块进行多次叠加,不断增加网络深度用于提取图像特征。本文采用50 层的残差网络的设计方式,对RG-ResNet 残差模块进行叠加操作,网络结构如图5所示。

图5 编码器结构Fig.5 Encoder structure
RG-ResNet 的两种残差模块,经过第一个残差模块(黄色模块)时的1*1卷积并非分在经组卷积,因为此时的网络输入通道数量较少。再对RG-ResNet 中stride=1(绿色模块)和stride=2(蓝色模块)进行如图5 所示的叠加,构成编码器实现对图像的特征提取,编码部分详细参数如表1所示。

表1 编码器网络参数Tab.1 Encoder parameters
1.3.2 解码器构建
输入图像经过前述编码模块提取输入图像的特征信息,但是由于经过多层卷积,特征图的分辨率较低,输出的尺寸过小,需要将图像恢复到原来的尺寸,选用反池化+卷积的上采样操作扩大图像分辨率,流程如图6所示。将分辨率较低的特征图通过U1进行反池化操作,池化索引采用图6标识的位置增补0的2×2像素块。反池化操作后的结果进行卷积核为5*5 的卷积C1、C3 操作,经过BN归一化和ReLU激活函数进行处理,经过C1操作后的特征图再次进行C3的卷积核为3*3的卷积操作,将C3和C2 处理后的结果进行同维度的通道相加后经过ReLU激活函数,得到分辨率较高的特征图输出结果。

图6 上采样结构Fig.6 Upsampling structure
1.3.3 损失函数
Huber 损失函数又为平滑平均绝对误差损失函数,能够比较清晰地估计出图像中物体的深度信息,对异常值处理更加鲁棒。Huber损失函数如式(1)所示。


式中:f(xi)为估计值;Yi为目标值;λ为超参数取λ=0.15; 设 置c的 值 如 式(2); 令a=f(xi)-Y,c=
2 实验结果
实验设备选取型号NVIDIA GTX 1080Ti 显卡的计算机,操作系统为Ubuntu18.04,选择Pytorch 深度学习框架。训练初始学习率(learning rate)设为0.000 1,训练衰减因子α=0.999。预设批量处理大小(batch size)为8,最大迭代次数(max epoch)为20,损失函数使用Huber损失函数,最终训练模型参数总数量为25 M。训练过程中对前几层的模型权重进行冻结不训练,同时进行数据增强,避免过拟合,提升训练效果。
2.1 评价标准
根据目前单目图像深度信息恢复采用的最通用评价指标进行对所提出的网络框架进行评估,通用的评估方式[11]为:均方根误差(Root Mean Squared Error,RMSE);平均对数误差(Root Mean Squared log Error,RMSElog);平均相对误差(Average Relative Error,Abs-REL);准确度(Accuracy)。
2.2 不同网络对比实验与分析
将所提出的网络与目前已有的单目图像深度信息恢复的编-解码结构网络架构进行比对。本文提出的方法与单目图像深度信息恢复的前沿方法[13-14,16]均采用NYU Depth V2 包含659 张图像对的室内场景进行对比测试,实验结果如表2 所示。对表中分析,本文所提方法能够在保证精度的前提下有效地降低错误率。虽然该方法[13-14,16]在3 种误差评估方面都达到了近期较高水平,但本文提出的模型在均方根误差上比表中效果最佳的Laina 等[16]的方法提高了19.8%,同时平均相对误差高于表中最优数据3%,相比之下本文提出的方法要优于表中的其他方法。

表2 本文方法与其他方法的定量结果对比Tab.2 Comparison of network quantitative proposed by this paper and others
由于该方法[16]在单目图像深度估计的实验结果最优,采用此方法与本文提出的方法进行定性实验比对,如图7 所示。图中Laina 等[16]所提网络的实验结果整体预测准确,但是图中物体边缘模糊且轮廓不够清晰,在物体细节和边缘的深度信息恢复上存在信息丢失、错误等缺陷。相较而言,本文所提方法在框线内一些细节(如桌子、沙发、柜子、门框等)的深度信息恢复中,可得到较为准确的结果,保证了深度信息恢复的完整性和准确性。综上,本文提出的方法能够实现单目图像的深度信息恢复,同比于目前其他先进算法,准确率占优同时保证了场景细节深度信息的准确恢复。

图7 不同网络深度信息恢复结果对比Fig.7 Comparison of information recovery results of different network depths
3 结束语
为了解决目前图像深度信息恢复网络中参数量过大的难题提出RG-ResNet,用于实现单目图像的深度信息恢复,本文结合编-解码结构,提出了两个单目图像深度信息恢复的网络模型。
本文首先提出了RGConv 的卷积方式,其保留了分组卷积低参数量的优势,同时弥补了组与组之间通道信息无关联的缺陷,而后基于RGConv 对ResNet 残差模块进行改进,构建RG-ResNet 网络模型。实验结果表明,在基于NYU Depth V2 数据集上RG-ResNet 网络效果更好,并且与目前先进算法相比在图像物体边界、局部细节深度信息的恢复方面能够达到较好的效果。
在实际应用场景中,不同的天气环境、硬件等因素都会对网络的预测结果造成直接的影响,并且目前一个功能的应用都是多种算法的相互配合,这就要求单一算法能够实现更加稳定准确的输出,本文在对网络的稳定性和鲁棒性方面的实验不足,因此下一步将加入实际场景影响因素的考虑和硬件优化的处理,进一步验证所提出方法的实际可应用性。
