基于改进型集成学习的风电功率预测研究
2022-06-22李思莹陈海宝
李思莹,陈海宝
(滁州学院 计算机与信息工程学院,安徽 滁州 239000)
0 引言
风电固有的间歇性和波动性,给电网的安全带来了风险。准确的风电功率预测可以增强预见性,在提高电网安全的基础上又提升了能源使用的经济性[1]。近年来,很多学者将风电功率预测研究重点放在了机器学习方法上,机器学习方法在非线性建模方面拥有巨大的优势。Vapnik所研究的SVM理论在20世纪90年代引起了广泛重视,并被逐渐完善。SVM能在有限样本下找到最优的分类,避免了可能出现的过学习、欠学习和陷入局部最小的问题。文献[2]以SVM为核心,用SVM实现风电功率预测,表明了SVM方法的有效性。文献[3]基于支持向量机和改进的蜻蜓算法进行短期风电功率预测,取得了较理想的预测精度,且泛化性能好,突出了SVM在风电应用中的优越性。但上述基于SVM的机器学习法,仅建立了单一的预测模型,这种模型大多不能完整地展现数据的各项特征,往往会“顾此失彼”。更加合理的方法是,集中优势模型,采用组合模型的方法完成预测,进一步提高模型精度。
作为模型结合的方法之一,集成学习一直被广大学者所研究和改进[4]。集成学习模型相较于单一模型有着更好的数据处理和泛化能力,可以将各子模型的学习成果进行整合,从而提升模型整体的预测精度。文献[5]提出了基于支持向量机集成的SDAE在线风电系统动态安全评估,仿真结果表明了该方法的有效性和准确性。文献[6]提出了一种改进集成学习算法的SVM风速预测方法,该方法预测精度高,运行速度较快,更进一步地实现了风速预测。基于集成学习和SVM思想的模型应用于风电功率预测中,有利于增强电网稳定性,因此有着重要的研究意义。
本文将机器学习与集成学习相结合,提出了一种基于集成学习思想的风电功率预测方法。首先采用模糊C均值(Fuzzy C-Means,FCM)聚类法进行工况辨识,再采用SVM建立子学习器模型。在主学习器模型的基础上,提出了一种改进的SVM主学习器模型,将样本到聚类中心的距离加入主学习器模型中,更加符合工程的实际情况,且进一步提高了预测精度。
1 方法
1.1 SVM算法



1.2 集成学习模型

2 基于SVM和集成学习的风电功率预测
2.1 数据准备
本文基于大连某风电场的实际运行数据进行预测。选取2015年10月的数据共6 480组,采样间隔为2 min。首先利用拉依达准则对6 480组数据进行去除异常点的预处理,剩下5 831组数据;再对5 831组数据进行建模,将前3 500组数据作为子学习器的训练样本,中间2 000组数据作为主学习器的训练样本,后331组数据作为测试样本。图1为原始风电功率序列,图2为拉依达准则处理后的风电功率序列。

图1 原始风电功率序列Fig.1 Original wind power sequence
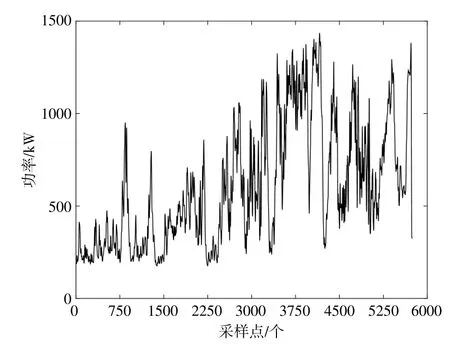
图2 数据处理后的风电功率序列Fig.2 Wind power sequence after data processing
2.2 基于FCM聚类法的工况辨识
由于本文采用的实验数据中未包含启动时间段,故只研究风能追逐区、恒转速发电区、恒功率发电区3种工况。本文采用FCM聚类法解决风电机组工况之间的模糊性问题。利用FCM聚类法将数据聚类成3类,聚类后各工况的样本如图3所示。

图3 FCM聚类后各工况内的样本Fig.3 Samples in each working condition after FCM clustering
从图3可以看出,这3类工况的区别主要为功率高低的不同。
2.3 子学习器的生成
在各工况区间内,采用SVM算法建立子学习器。将用于主学习器训练的数据(2 000组)分别输入到各个子学习器中,完成各子学习器模型的测试。各个子学习器的测试结果如图4所示。

图4 各子学习器的测试结果Fig.4 Test results of each sub-learner
为了更加直观地表示出各个子学习器的预测值和真实值的误差,计算测试数据的均方根误差和平均相对误差,结果如表1所示。

表1 各子学习器测试误差Table 1 Test error of each sub-learner
由表1可知,各个误差值均较小,在允许的范围内。良好的各子学习器预测精度也为集成后总体预测奠定了基础。
2.4 主学习器的生成
将3个子学习器的预测结果作为主学习器的训练样本进行主学习器的训练。在建立主学习器模型时,采用加权平均集成法和SVM集成法两种不同的结合策略。
(1)加权平均集成法
加权平均作为直观简单、运算量小的一种普遍方法,被很多研究所使用。本文所采用的加权平均法基于输入子学习器的样本个数,对每一个子学习器的预测结果计算权重,将各子学习器的结果进行加权。预测结果如图5所示。

图5 加权平均法的预测结果Fig.5 Forecast results of the weighted average method
通过图5可以看出,加权平均法的预测走势大致正确,但是精准度上有待提高。这是由于加权平均法中权重的确定是从训练数据中计算所得,而在实际建模中,随机性强的集成器容易导致过拟合。因此在波动性较强的风电功率预测中,加权平均法不是最合适的结合策略。
(2)SVM集成法
在风电功率预测工程中,因为训练数据较大,需要预测精度值较高,所以子学习器和主学习器均使用支持向量机进行建模,可以更好地提升预测精度,误差缩小到允许的范围。集成SVM的流程如图6所示。

图6 集成SVM流程示意图Fig.6 Schematic diagram of the integrated method SVM process
基于SVM主学习器模型的预测结果如图7所示。通过图7可以看出,机器学习的方法相比加权平均法,最终的预测精度更高,拟合程度更强,这是因为主学习器采用了机器学习的方法完成了进一步学习。因此,支持向量机作为主学习器可以很好地应用于工程中。

图7 学习法的预测结果Fig.7 The prediction result of the learning
最后,分析比较主学习器加权平均集成预测法和SVM集成预测法的均方根误差、平均相对误差,判断各方法的精度,误差值如表2所示。

表2 两种预测模型的评价指标Table 2 Evaluation indicators of the two prediction models
通过表2可以看出:集成方法预测误差较低,这是因为集成方法兼顾了几种模型的特点,弥补了单一模型“顾此失彼”的局限性;由于SVM集成法基于机器学习方法完成了二次训练,所以均方根误差值和平均相对误差值都小于加权平均集成法,实际验证结果与理论预测结果相吻合。
3 基于改进的SVM和集成学习的风电功率预测
在基于SVM建立子学习器模型时,由于使用聚类算法,聚类中心可在一定程度上表征子学习器所覆盖的运行工况。但此时将子学习器输出的数据输入到主学习器中,未考虑样本与聚类中心的贴近程度,即忽略了工况对结果的影响。因此在建立主学习器模型时,考虑样本到聚类中心的距离是必要的,从而完成对SVM主学习器的改进。图8和图9分别为主学习器训练样本与测试样本到聚类中心的距离。从图8、图9可以看出,在3个子学习器中,工况不同,样本到聚类中心的距离也不同。所以在建立主学习器模型时将工况因素考虑进去是非常必要的。在实验中,将2 000组样本到3个聚类中心的距离分别记为d1,d2,d3,则主学习器的输入值为3个子学习器的输出值和d1,d2,d3。在主学习器的输入中加入工况信号,能够使其在训练参数时计及运行工况的因素,从理论上能进一步提高集成模型的精度,并且更加符合工程的实际要求。

图8 主学习器训练样本与各聚类中心的距离Fig.8 The distance between the main learner test sample and each cluster center

图9 主学习器测试样本与各聚类中心的距离Fig.9 The distance between the main learner training sample and each cluster center
基于改进的主学习器风电功率预测具体步骤如下:
①利用拉依达准则对输入数据进行预处理;
②基于FCM完成工况划分,将子学习器的训练数据划分成3个子类,对每一个子类进行SVM子学习器建模,完成3个子学习器的建模;
③将主学习器的训练数据分别输入到3个子学习器中,然后将3个子学习器的输出值作为主学习器的一部分输入,主学习器的训练数据和3个聚类中心的欧式距离作为主学习器的另一部分输入。将以上变量输入到主学习器中进行风电功率的预测。
改进的主学习器建模流程如图10所示。

图10 改进的主学习器模型流程图Fig.10 Flow chart of the improved master learner model
建立主学习器模型后,将350组测试数据输入到各子学习器中,各子学习器的输出和样本到聚类中心的距离作为主学习器的输入,训练主学习器。图11为基于改进主学习器模型的预测结果。
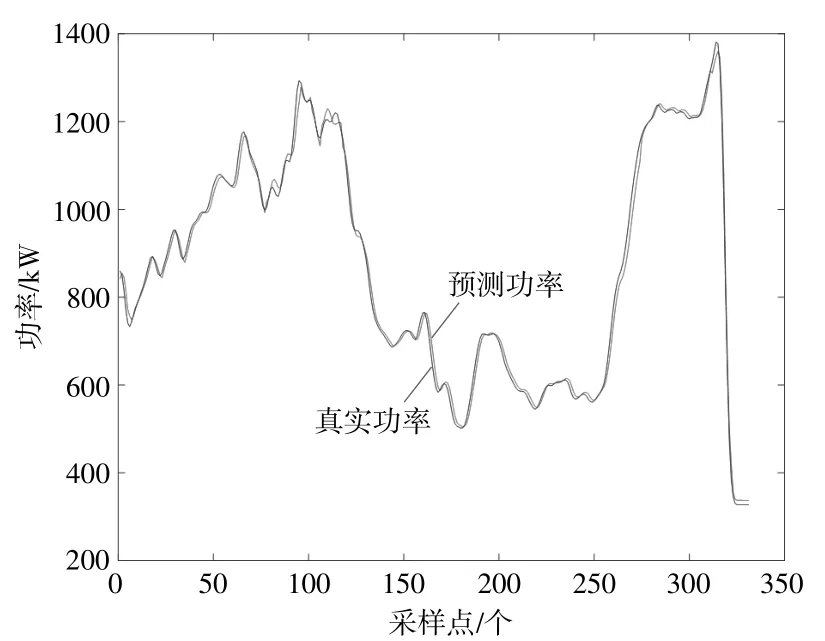
图11 改进主学习器的预测结果Fig.11 Prediction result of the improved master learner
为了体现该方法的有效性,分别计算加权平均法集成模型、SVM集成模型和SVM优化集成模型的均方根误差、平均相对误差。3种模型的预测误差如表3所示。

表3 不同集成方法的预测误差Table 3 Forecast errors of different integrated methods
通过表3可以看出,SVM优化集成的组合模型相比于其它模型,由于将主学习器训练数据到每一个聚类中心的距离作为输入,考虑到了样本对于不同工况的贡献程度,使得均方根误差和平均相对误差减小,大幅度提高了模型精度。由此可见,本文提出的方法提高了预测精度,适合应用在波动性较强的风电功率预测中。
4 结论
针对单一的SVM算法学习能力不足、无法有效利用大数据资源提高精度,本文将集成学习应用在风电功率预测中。该方法可在不同工况下同时建立各工况的子学习器,提高了模型精度。基于集成学习的思想,采用FCM完成了风电机组实际SCADA历史数据的工况辨识,建立了各工况的SVM子学习器模型。在建立主学习器模型时,提出一种改进的主学习器模型,将样本到聚类中心的距离加入到主学习器模型中,考虑了运行工况对主学习器的影响。通过实验对比可知,本文提出的风电功率预测方法预测精度高,满足工程实际要求。
