基于改进MobileFaceNet的羊脸识别方法
2022-06-21张宏鸣周利香李永恒郝靳晔李书琴
张宏鸣 周利香 李永恒 郝靳晔 孙 扬 李书琴
(西北农林科技大学信息工程学院, 陕西杨凌 712100)
0 引言
现阶段中国大多数羊场采用耳标识别、射频识别[1]的方式对动物进行身份识别,该类方法的身份识别标识容易丢失。目前,监控设备已成为羊场的基本设施。基于计算机视觉技术对羊脸进行检测,进而识别不同羊只,成为智慧养殖领域智能识别的解决方案之一。
已有学者使用计算机视觉技术进行动物身份识别的研究[2-5]。在传统机器学习方面,部分学者应用传统特征提取方法进行牛的分类识别[6]、猪只个体识别。然而数据采集工作量较大,数据处理后的灰度图像的训练失去了较多颜色信息,对单色脸部识别效果不理想。在深度学习方面,HANSEN等[7]、WANG等[8]用迁移学习技术,使用VGG网络人脸预训练模型,分别实现了猪和牛的非接触式脸部识别。GUO等[9]使用改进的卷积神经网络结构实现金丝猴非接触式面部识别。SALAMA等[10]实现了绵羊的识别。何东健等[11]使用改进YOLO v3实现挤奶奶牛个体的身份识别,刘月峰等[12]提出了一种基于幅值迭代剪枝算法的网络筛选方法实现奶牛的进食行为识别。但基于YOLO网络的识别模型参数量大,对于面部特征相似的个体识别精度仍有待提高。现有的动物面部识别数据多为近距离拍摄数据,在闭集训练集上达到了很好的识别效果,但处理增量数据需要重新进行分类器训练,且远距离场景下错误分类概率更高。面部识别算法应用推广中人脸识别占据主导地位,主要算法有DeepID[13-14]系列算法、FaceNet[15]、InsightFace[16]算法,DeepID系列算法使用Softmax损失函数,模型识别率与人脸类别数成反比。FaceNet算法中采用三元组损失函数监督学习人脸特征提升了识别率,但模型计算耗时长。InsightFace算法中使用MobileFaceNet[17]作为主干特征提取网络,Arcface[18]损失函数加大类间距,相比于MobileNet,VGG及其他识别网络在人脸识别领域模型规模小,识别率高。故本文选择MobileFaceNet,并针对羊只体型较小、面部相似性大、奶山羊颜色单一且花色区别不大的问题,对MobileFaceNet进行改进与优化。目标检测算法[19-24]中YOLO v4的检测速度快,可进行大规模的羊脸识别数据采集,降低人工采集数据集成本,具有现实场景下羊脸识别的潜力。
因此,本文采用单级式目标检测方法中的YOLO v4算法构建羊脸检测器,以批量获取羊脸,构建识别数据集。针对远距离下羊只个体识别率不高的问题,提出一种基于融合空间信息的高效通道注意力(Efficient channel coalesce spatial information attention,ECCSA)MobileFaceNet的轻量级羊脸识别模型(ECCSA-MFC),以期为非接触式羊脸识别提供参考方法。
1 识别方法
1.1 视频与图像采集
因采集单一样本会使得检测器的稳定性和复杂场景下的适应性较差,试验选择滩羊和关中奶山羊两类羊作为研究对象,分距离对室内室外不同光照、不同高度、不同角度的羊脸进行拍摄和录像,对所有采集的羊只进行人工干预驱赶,并增加摄像机抖动情形,以采集存在抖动情况的单羊过道现实应用场景。共采集远距离羊脸视频42段,近距离羊脸视频89段,共计131段视频数据,奶山羊个体62只,滩羊个体57只,共计119只羊。处理后的分辨率调整为1 920像素×1 080像素,部分场景如图1所示。

图1 羊脸原始数据样例Fig.1 Original examples of sheep face
1.2 技术路线
本研究使用深度学习的方法实现非接触式的羊面部识别,技术路线如图2所示。

图2 技术路线图Fig.2 Technology roadmap
主要包括4个步骤:
(1)数据集构建:使用FFMpeg处理原始视频数据,将视频转化成图像,对图像进行羊脸区域标注,根据羊脸检测数据集和羊脸识别数据集构建要求,进行数据集准备。
(2)羊脸检测:利用羊脸检测数据集训练基于YOLO v4模型的羊脸检测模型,用于现实应用中羊脸识别数据集自动式构建,同时作为实际应用场景下的羊脸检测器。
(3)羊脸识别:利用调用羊脸检测器生成的羊脸识别数据集,训练本文提出的ECCSA-MFC羊脸识别模型。
(4)结果输出:准备测试视频数据,调用羊脸检测器与羊脸识别模型,计算特征向量,对比特征向量的最佳阈值,输出试验结果。
1.3 数据集构建
由于采集的羊脸视频数据的前后帧之间相似性很高,首先对采集的视频数据使用FFMpeg处理成图像,每12帧提取1帧,为了避免后期训练的识别模型出现过拟合情况,使用结构相似度方法(Structural similarity, SSIM)[25]对图像进行检查,删减相似性高的前后帧图像。共获得原始图像4 836幅,试验共构建两个数据集。对羊脸检测数据集中的所有图像进行人工手动羊脸框定。通过高斯噪声、水平翻转、随机裁剪等数据增强方法对羊脸检测数据进行扩充。部分羊脸检测原始数据及标注数据如图3a所示。对于羊脸识别数据集,将检测器检测出的羊脸按照不同个体进行人工分类,为了保证后续识别模型的准确性,对每一文件夹下的羊脸图像进行人工筛选,剔除模糊、侧脸、误检测、不属于此类的其他类别羊脸,保证每个文件夹下的羊脸清晰、正脸、尺寸为112像素×112像素。图3b为羊脸识别数据集样例。

图3 羊脸数据集样例Fig.3 Samples of sheep face data
为了验证识别模型在实际场景应用中的鲁棒性和准确性,试验将这119只羊的脸部数据按照开集识别[26]和闭集识别[27]对训练集和验证集进行随机分类,其具体处理结果如表1所示。
1.4 羊脸检测
1.4.1基于YOLO v4的羊脸检测方法
YOLO v4算法改进了原有YOLO目标检测架构,主干网络采用CSPDarknet53,颈部采用空间金字塔和最大池化进行多尺度融合增大感受野,采用路径聚合网络对不同的输出层进行特征融合。满足羊脸实时检测的需求,故本试验采用YOLO v4进行羊脸检测。

表1 羊脸数据集处理结果Tab.1 Sheep face dataset processing results
1.4.2羊脸检测试验设置
在Darknet深度学习框架下搭建YOLO v4算法。根据本试验所需类别对自定义的数据集进行相关参数设置,通过K-means++聚类方法重新计算出锚框大小,采用3通道处理策略,输入检测框尺寸为608像素×608像素,设置动量为0.949,权重衰减正则系数为1×10-5,调整学习率为1×10-3,采取学习率10倍衰减方式进行模型迭代,将迭代轮次设置为2 000次,在每一轮迭代训练时进行Mosaic数据增强,损失函数采用完美交并比方法(Complete intersection over union,CIOU),进行非极大值抑制。
1.4.3羊脸检测评价指标
通过计算羊脸对象真实框和预测框之间的交并比(Intersection over union,IoU)、准确率及F1值进行检测模型评估。
1.5 羊脸识别
1.5.1MobileFaceNet网络结构
MobileFaceNet源于MobileNetV2[28],拥有工业级精度和运算速度,相比于大型网络,该模型参数少且所占内存小,降低了训练过拟合风险。MobileFaceNet使用512×7×7(通道数×长×宽)可分离卷积代替平均池化层。将激活函数ReLU替换为PReLU,训练过程中采用Arcface损失函数增大类间分类距离,通过归一化层加快模型收敛速度,防止模型过拟合。
1.5.2ECCSA融合空间信息的通道注意力
ECA是一种针对深度CNN的高效通道注意模块,去除了SE[29]模块中的全连接层(Fully connected layers,FC)。ECA在全局池化层(Global average pooling,GAP)之后的特征上通过一个可以权重共享的1维卷积进行学习,自适应地确定核尺寸k,通过执行1维卷积,保证了模型效率和计算效果,通过Sigmoid函数来学习通道注意力。本文提出的ECCSA模块如图4所示,其中C、W、H分别表示图像的通道数、长、宽。在ECA基础上并行增加空间注意力[30]进行空间分类像素域的学习,提高特征提取能力。
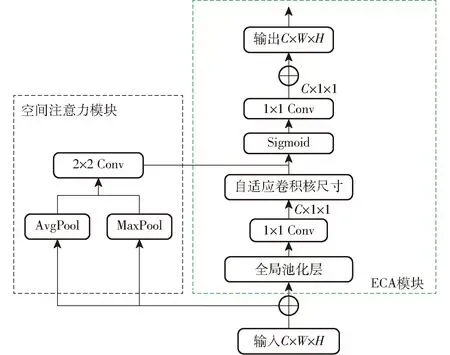
图4 ECCSA模块Fig.4 ECCSA module
1.5.3融合空间通道注意力的ECCSA-MFC
由于不同个体羊外观相似,脸部类间差异更小,羊脸易受异物遮盖,MobileFaceNet算法对羊脸识别效果并不理想,识别准确率不高。为了提高模型的鲁棒性和全局性,本文提出ECCSA-MFC模型,该模型针对MobileFaceNet主干网络做了3处改进。
(1)融合ECCSA模块的特征提取层

图5 改进的MobileFaceNet网络结构Fig.5 Improved MobileFaceNet network structure
为了增加主干特征的接受范围,在特征提取层中加入ECCSA,保证模型低复杂度的同时,提高神经网络提取特征的跨通道交互和空间分类像素域学习的能力。对原有MobileFaceNet网络的网络颈部进行改进,融合了空间信息的高效通道注意力识别模型ECCSA-MFC网络结构如图5所示。网络输入羊脸图像的尺寸为112×112×3,通过两层CBP进行特征融合,该层由2×2卷积(Conv)、批量归一化(BN)、PReLU激活函数构成。运用带有ECCSA模块的深度可分离卷积层(DW层)对上层提取特征进行处理,再经过倒残差层(DWRes层)对低维特征进行学习。其中DWRes层包含多个DW层,再通过Flatten层进行数据压平得到512×1的特征向量。
(2)学习率动态调优
为了避免模型训练过程中陷入局部最优解,使用余弦退火算法对学习率进行动态调优。
(3)ImageNet数据集上的预训练模型
在羊脸识别模型训练前对输入图像进行预处理后,使用人脸数据集上的预训练模型初始化ECCSA-MFC的均值和方差,对图像按照通道进行标准化,加快模型的收敛深度,提高模型性能。
1.5.4羊脸识别试验设置
(1)图像预处理
在羊脸识别模型训练前需对输入图像进行预处理,使用在ImageNet数据集上计算得到的均值和方差,对图像按照通道进行标准化,加快模型的收敛深度。
(2)数据增强
为了增加训练图像的数量并使网络对某些变换更加鲁棒,在训练图像上随机执行了4个操作:随机翻转30°;图像尺寸变换至112像素×112像素;数据形式转换为张量形式(tensor),并进行归一化;在羊脸上添加随机遮盖以模拟现实场景下的遮盖情况。
(3)参数设置
试验使用Arcface损失函数,设置动态初始化学习率为1×10-3,加入余弦退火进行学习率动态调优。为了防止训练模型过拟合,设置dropout为0.6,学习动量为5×10-4,迭代周期(Epoch)为50,批量大小(Batch size)为32。
1.5.5羊脸识别模型评价指标
(1)拒识率和误识率
拒识率(False reject rate,FRR)决定了模型的易用程度,误识率(False accept rate,FAR)决定了模型的安全性。通过FRR和FAR可确定识别模型的最佳阈值,在羊脸识别系统中,将FAR设置为千分之一,在FAR固定的条件下,若FRR低于5%,则模型效果较优。
(1)
(2)
式中NFR——错误拒绝次数
FRR——拒识率,%FAR——误识率,%
NFA——错误接受次数
NGRA——类内测试总数
NIRA——类间测试总数
(2)识别率
采用十折交叉验证的方式,计算每一轮检测的识别率(Detection and identification rate,DIR),DIR的计算公式为
DIR(T,1)=
(3)
式中Pg——羊脸识别库中的羊脸图像
DIR——准确识别率
Pj——待识别的羊脸图像
Rank——识别结果标记函数,识别错误赋值为0,识别正确赋值为1
Pj*——待识别羊与识别库中羊匹配的第j*幅图像的计算阈值
T——采用InsightFace中的阈值计算方式得到的最佳阈值
2 试验与结果分析
2.1 羊脸检测
通过YOLO v4目标检测方法训练羊脸检测模型,使用OpenCV读取视频流,进行羊脸检测并保存检测框中的羊脸信息。最终YOLO v4羊脸检测模型的平均交并比(IOU)为76.68%、准确率为97.91%、F1值为93.84%。实现了对羊脸数据的实时检测,同时为羊脸视频识别奠定基础。
羊脸检测训练数据中包含不同光照条件、遮挡及镜头抖动情况,图6a表明该模型能够检测出室内近距离下的羊脸。图6b表明在镜头抖动情况下,该模型能够精准检测到远距离模糊羊脸,满足羊脸检测需求。

图6 羊脸检测结果Fig.6 Results of sheep face detection
2.2 羊脸识别
2.2.1模型识别结果对比
对MobileFaceNet使用余弦退火改变学习率计算方式,并初始化均值和方差,进行模型初步精度优化,如表2所示。进行动态学习率调优得到的C-MFC模型识别率相比原有模型,在闭集上提升了0.67个百分点,开集上提升了4.38个百分点,且误识率和拒识率均有所降低。
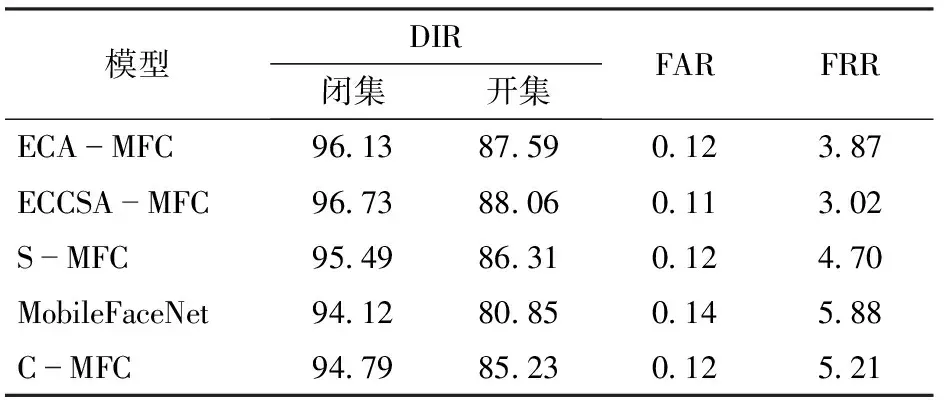
表2 不同模型效果对比Tab.2 Effect comparison of different models %

图7 羊脸识别模型训练过程Fig.7 Training process of sheep face recognition model
本研究目的是在模型得到初步优化的基础上,构建空间信息的高效通道注意力识别模型(ECCSA-MFC),提高远距离下的羊脸识别率。首先对MobileFaceNet的DW结构进行改进,对空间注意力模块(S-MFC)、ECA模块(ECA-MFC)以及ECCSA模块融合DW的模型(ECCSA-MFC)进行试验与结果分析。羊脸识别模型训练过程中在验证集上的识别率(DIR)、损失值(Loss)和最佳阈值(Threshord)的变化曲线如图7所示。可以看出本文提出的ECCSA-MFC比S-MFC、ECA-MFC模块的羊脸识别率高,在50轮迭代计算中,DIR曲线均稳定高于ECA-MFC和S-MFC模型,并且在固定范围内振荡;损失值处于逐渐稳步收敛状态,且收敛效果优于ECA-MFC和S-MFC,而单独使用空间注意力模块进行改进的S-MFC可能会出现梯度爆炸的情况;从阈值的变化情况看,本文提出的ECCSA-MFC模型阈值稳定在1.6左右,与正常推理阈值波动范围一致,证明了ECCSA-MFC模型效果比ECA-MFC、S-MFC更加优越。
将3种方法得到的收敛后模型进行保存计算,得到不同模型的DIR、FAR和FRR。由表2可见,仅使用ECA模块的ECA-MFC模型的效果,在闭集识别中相比于C-MFC提升了1.34个百分点,在开集识别中相比于C-MFC提升了2.36个百分点。S-MFC模型虽然在闭集识别率上比C-MFC提升了0.7个百分点,但在开集识别中的提升效果略低于ECA-MFC模型。ECCSA-MFC模型在开集和闭集中均取得最好的识别效果,闭集识别率达到96.73%,比C-MFC提升了1.94个百分点;开集识别率达到88.06%,比C-MFC提升了2.83个百分点。
由表3可得,ECCSA-MFC在实现模型更加轻量化的同时,能够稳定提升识别率,模型所占内存仅为4.8 MB,相比MobileFaceNet减小了0.3 MB。
2.2.2实际场景下结果对比
为了验证本文模型在实际场景下的效果,分别使用奶山羊和滩羊的开集验证集进行分类识别试验。奶山羊的验证集数据中前6只来自远景下采集的数据,后6只来自近景下采集的数据,11只滩羊的验证数据均为近景数据。制作奶山羊和滩羊的分类识别混淆矩阵用以直观展示模型在验证集上的分类结果,如图8所示,从左到右依次是C-MFC、ECA-MFC、S-MFC、ECCSA-MFC模型分类结果。原有的MFC结构拥有近距离识别能力,在近距离羊只身份识别中,能够做到准确识别。ECA-MFC和S-MFC对近距离花色差异较大的滩羊的识别效果尚可,但识别颜色单一且距离较远的奶山羊仍然存在误识别的可能。ECCSA-MFC模型能够很好地改善C-MFC在远距离下对奶山羊的识别效果,并且在近距离的识别中不仅能够准确地识别花色差异较大的滩羊,在颜色单一的奶山羊远距离下仍然能够正确识别羊只真实身份。这更加充分证明了ECCSA-MFC模型拥有对不同距离下羊脸正确分类识别的能力。图9为使用1.2节中滩羊远距离模拟单过道现实场景视频中视频帧识别结果。

表3 不同网络复杂度对比Tab.3 Complexity evaluation of different networks

图8 验证集识别结果对比Fig.8 Comparison of verification set identification results

图9 视频帧识别结果Fig.9 Video frame recognition result
3 结论
(1)基于YOLO v4算法的羊脸检测方法的检测准确率为97.91%,为羊脸数据采集工作减轻了负担,为视频监控下进行羊脸识别提供了技术支撑。
(2)提出了一种引入融合空间信息的高效通道注意力的ECCSA-MFC模型,能够有效增加主干特征的提取范围。相比于原有MFC模型带来的性能增益明显,模型所占内存比MobileFaceNet减小了0.3 MB,模型识别率得到有效提升,其中模型的闭集识别率比C-MFC提升了1.94个百分点,开集识别率比C-MFC提升了2.83个百分点。
