基于深度神经网络的猪咳嗽声识别方法
2022-06-21沈明霞王梦雨刘龙申
沈明霞 王梦雨 刘龙申 陈 佳 太 猛 张 伟
(1.南京农业大学工学院, 南京 210031; 2.江苏智慧牧业装备科技创新中心, 南京 210031)
0 引言
养猪业是畜牧业的重要组成部分[1],猪养殖生产中,对猪呼吸道疾病诊疗是主要工作基础[2-3]。咳嗽是猪呼吸道疾病的主要早期症状[4],因此通过识别咳嗽声进行猪早期呼吸道疾病预警成为当前关注点[5]。
国内外科研人员在识别猪只咳嗽声方面的研究主要分为3类:一是基于一般声学分析算法的咳嗽声识别,GUARINO等[6]使用滤波器组结合振幅解调进行特征提取,通过动态时间规整算法(DTW)将这些特征向量与参考集进行比较,咳嗽声识别正确率为85.5%。EXADAKTYLOS等[7]利用功率谱密度(PSD)研究病猪咳嗽声的频率特征,利用模糊C均值聚类算法对咳嗽和其它声音分类,咳嗽声识别正确率为82%。徐亚妮等[8]提取梅山母猪声音信号的功率谱密度作为特征,提出了模糊C均值聚类算法的改进方法,对梅山猪的咳嗽声与尖叫声进行聚类分析,取到了较好的分类效果。二是基于传统机器学习的咳嗽声识别算法研究,原始的信号输入往往只经过一层处理,模型结构简单、易于学习,但对于较为复杂的信号处理能力具有局限性[9-12]。文献[13-15]分别构建基于不同特征提取(LPCC、MFCC)的隐马尔可夫(HMM)模型和矢量量化(VQ)模型对猪咳嗽声进行识别,都取得了一定成果。三是基于深度学习技术的猪咳嗽声识别,深层神经网络被广泛应用于医学影像分析、农作物识别、人脸识别等各个领域[16-19]。YIN等[20]提出了一种基于AlexNet模型和谱图特征的分类算法,总体识别准确率达到96.8%,F1值达到96.2%。SHEN等[2]通过将MFCC与多层CNN融合得到MFCC-CNN特征,总体识别准确率为96.6%,使用softmax和线性支持向量机(SVM)分类器进行分类后,咳嗽识别准确率分别提高了7.21%和3.86%,F1值分别提高了10.37%和5.21%。黎煊等[1]提出了基于双向长短时记忆网络-连接时序分类的声学模型(BLSVM-CTC),利用五折交叉验证试验,猪咳嗽声识别率为92.40%,误识别率为3.55%,总识别率为93.77%。
现有研究成果表明将声音信号转换成声谱图,利用神经网络进行识别,可有效提高识别精度[21-23]。本文通过谱减法对截取的猪只有效声音段进行去噪,从而消除环境中的干扰噪声,利用将声音信号的短时能量和短时过零率作为特征参量的双门限端点检测法进行猪只有效声音信号获取,分别提取猪只咳嗽、鸣叫、喷嚏以及呼噜声的logFBank以及MFCC两种声音特征后,输入CNNs和DFSMN两类神经网络模型进行猪咳嗽声识别训练,比较两种特征提取方法对模型效果的影响,以及不同迭代次数的影响,最后进行4种声音信号的四分类模型训练。
1 数据采集与预处理
1.1 实验对象
实验数据采集自江苏省镇江市句容江苏农博园梅山猪育种中心,采集时间为2018年6月,采集对象为10只2—3月龄、体质量(50±5)kg的梅山猪,其中5只体温升高至40.5℃,表现为连续性咳嗽,呼吸增快,经专业饲养人员诊断为患病。另外5只为健康猪只,无咳嗽症状。
1.2 实验设备
录音设备为韩国现代数字E66型智能录音笔,最大内存16 GB,音频储存格式为wav,采样精度为16位,采样频率为48 kHz,每2 h保存为一个录音文件,以年-月-日-时-分-秒格式命名。
1.3 数据采集
分别将患病猪只及健康猪只放置在2个相邻猪舍内,将2支录音笔分别悬挂于猪舍内距离地面高度约1.6 m处,共采集到有效录音数据57 h。图1为实验数据采集现场图。

图1 实验数据采集现场图Fig.1 Pig house of experimental data collection
1.4 数据预处理与数据集划分
本次实验中猪舍采集到的音频包含猪只的咳嗽、鸣叫、喷嚏、呼噜声等可用数据以及人声、金属器皿碰撞等其它环境噪声,利用音频处理软件Adobe Audition(AU)进行有声段截取,共截取有效声音(咳嗽声、呼噜声、鸣叫声及喷嚏声)536段。
谱减法是声音信号处理过程中常用的去噪方法之一,将声音信号类比为目标信号与噪声信号的叠加,获取声音信号的前几帧或静默段作为噪声信号,获取平均噪声能量,实现声音信号的去噪处理。图2为谱减法处理前后时长为10 s的连续咳嗽声降噪效果波形对比图,由图2b可知,猪连续声音信号噪声得到明显削减,并通过人耳试听进一步验证,猪声音样本没有失真。

图2 谱减法去噪前后猪咳嗽声波形图Fig.2 Sound waveform of pig cough before and after spectral subtraction denoising
利用将声音信号的短时能量和短时过零率作为特征参量的双门限端点检测法对去噪后的536段录音信号进行端点检测,共得到咳嗽声1 058个,其它声音样本420个,其中喷嚏声184个,鸣叫声121个,呼噜声115个。验证集和测试集的数目分别设置为本类声音样本个数的10%,每次实验进行随机选取,剩余样本设置为训练集。表1为数据集划分结果。
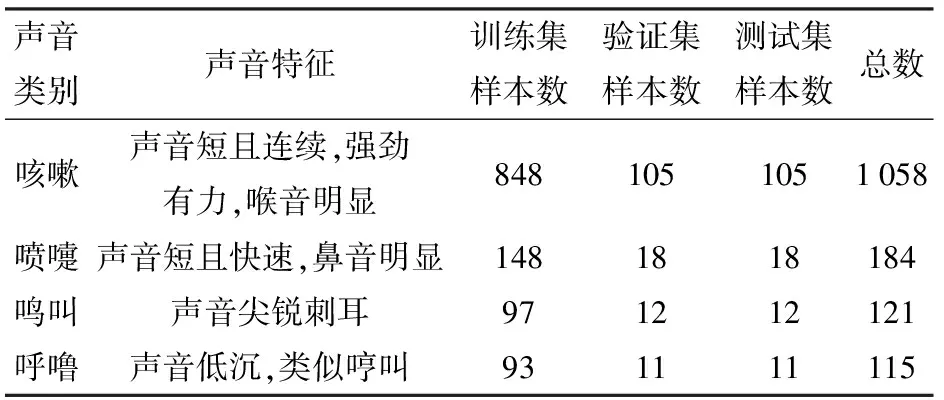
表1 数据集划分结果Tab.1 Data set partitioning results 个
2 猪咳嗽声识别
2.1 猪声音特征参数提取
滤波器组(FBank)特征由于相邻滤波器组有重叠,相邻的特征高度相关,MFCC特征是在logFBank(FBank取对数)特征的基础上再进行离散余弦变换(DCT)得到,具有更好的判别度。分别提取上述得到的声音信号的logFBank和MFCC两种音频特征。通过实验分析比较这两种声学特征对咳嗽声识别模型效果的影响,提取的特征存储为npy文件。图3为算法整体流程图,检测样本格式等信息正确后逐个提取特征并保存,否则跳过此样本。

图3 猪只声音特征提取算法流程图Fig.3 Flow chart of pig sound feature extraction algorithm
为了补偿声音信号中被压抑的高频部分,突出高频的共振峰,需要在频域上面乘以一个系数,预加重系数设置为0.97。预加重对噪声无影响,提高了输出信噪比,公式为
s′n=sn-ksn-1
(1)
式中s′n——预加重后的声音信号
sn——n时刻声音采样值
sn-1——n-1时刻声音采样值
k——预加重系数
由于原始音频样本时间长度不固定,但具有微观上的短时平稳性,为了便于傅里叶变换,加窗切分为固定长度的小片段。为了保证信号不失真,根据奈奎斯特采样定律,采样频率设置为48 kHz,帧长设置为25 ms。为了避免窗边界对信号的遗漏,帧与帧之间设置一部分重叠区域,即帧移设置为10 ms。采用汉明窗消除每一帧信号在其两端出现的信号不连续问题,从而使傅里叶变换之后取得更高质量的频谱。汉明窗计算公式为
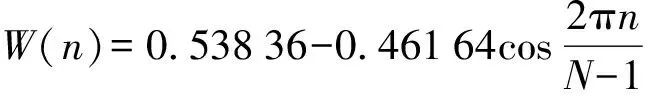
(2)
式中W(n)——汉明窗函数
N——信号总的采样点个数
n——采样点序号
加窗过程为汉明窗函数与原信号作乘积变换,公式为
S′(n)=W(n)S(n)
(3)
式中S(n)——原始帧信号
S′(n)——加窗后信号
为了方便深度神经网络学习,需要将时域信号转换到频域,本实验在每一帧进行2 048点短时傅里叶变换(Short time Fourier transform, STFT),计算公式为
(4)
式中Xn(W)——短时傅里叶变换频域值
x(n)——第n个采样点的采样值
m——汉明窗长度ω——角频率
R——窗口随时间滑动的距离
W——汉明窗函数
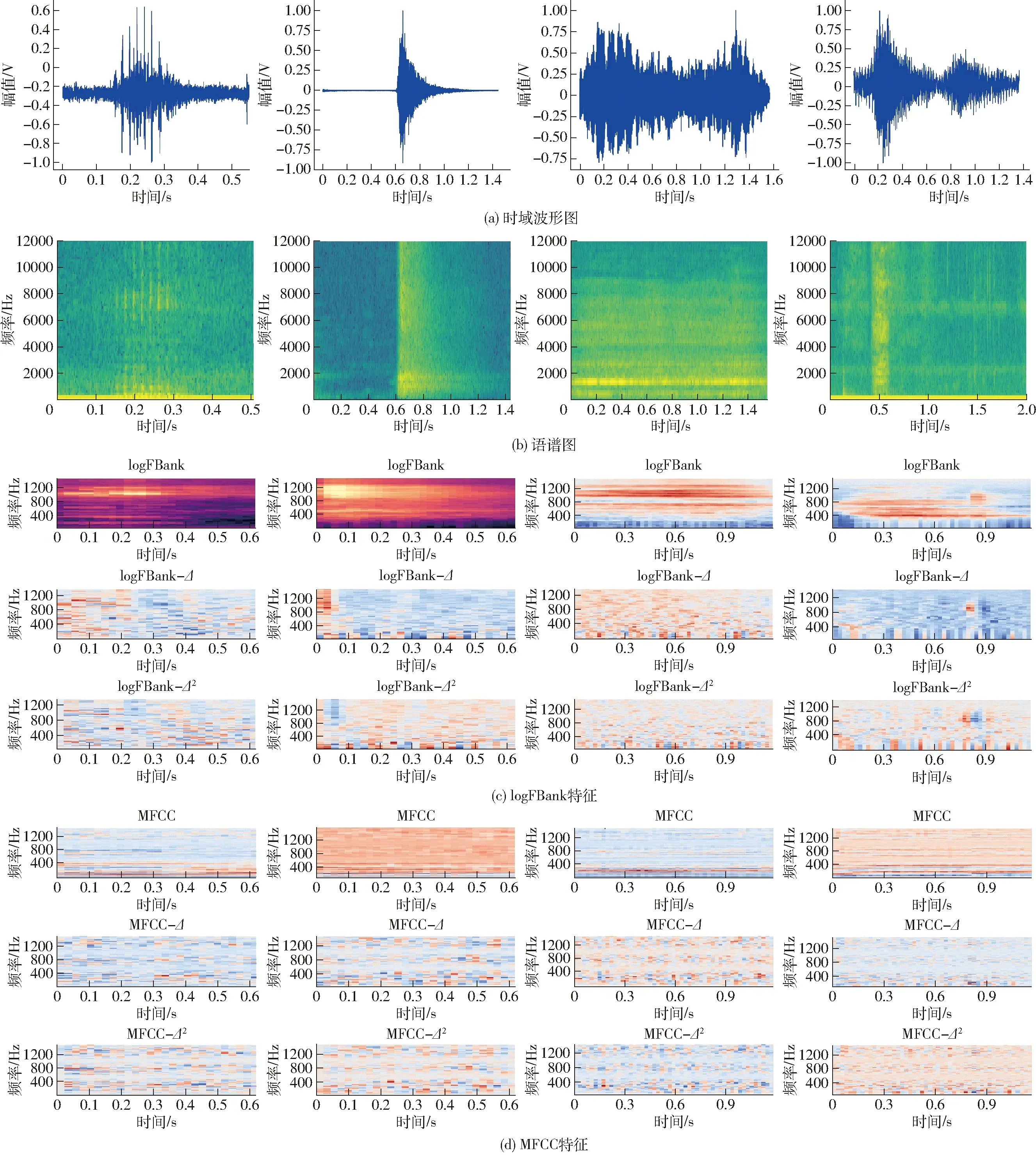
图4 猪声音时频域特征转换Fig.4 Feature conversion of pig sound in time-frequency domain
短时傅里叶变换后得到的幅度谱与每一个梅尔刻度滤波器进行频率相乘累加,滤波器组个数设置为64。为了更接近人耳听声原理,滤波后取对数,最终得到logFBank特征。MFCC特征梅尔刻度滤波器组个数设置为128,离散余弦变换(DCT)后,返回倒谱数64个。最终将时域特征转换到频域,得到4种声音信号的各两种声音特征,分别再对其求一阶差分和二阶差分,得到3个特征进行零-均值标准化(z-score)处理,转换成三维数组作为咳嗽声识别模型的输入。
图4为时频域转换结果,从左到右依次为呼噜声、喷嚏声、鸣叫声、咳嗽声,图中Δ为一阶差分。通过对比分析4种声音各自的时域和频域特征图可发现,不同声音信号的语谱图存在明显差异,4种声音信号的logFBank及MFCC特征也存在差异,这是本实验进行分类识别的基础。
2.2 猪咳嗽声识别模型
采用提取的logFBank和MFCC及其一阶、二阶差分组合作为特征参数,分别经过CNNs和DFSMN两种深度学习模型训练后比较总体精确度、咳嗽声和非咳嗽声识别精确度、召回率及F1值等指标,综合判定模型性能。图5为深度神经网络模型整体训练流程图。

图5 模型训练整体流程图Fig.5 Overall process of model training
2.2.1基于CNNs的猪咳嗽声识别模型
卷积神经网络是目前比较流行的一种深度学习算法,在图像特征提取、语音处理等领域效果优异。一个深层CNNs模型通常包含卷积层、激活层、池化层和全连接层。卷积层是用若干个卷积核进行卷积运算,即卷积核在二维特征数据上按特定步长滑动计算权重矩阵和扫描所得的数据矩阵的乘积,得到一个输出,一层所有卷积核的个数即为本层卷积输出通道数。激活层通常使用ReLU函数,用于非线性运算,使得神经网络能更好地解决更加复杂的问题。
池化层通常在各个卷积层之间,降低各个特征的维度,减少过拟合,通常有最大池化(Max pooling)和平均池化(Average pooling)两种形式,最大池化即把上层结果特征元素的最大值作为输出,平均池化即将特征平均值作为下层输入,本文选择最大池化层。全连接层通常在模型尾部,所有神经元都有权重连接,用于特征分类。图6为基于CNNs的猪只咳嗽声识别模型的整体结构,包括3层卷积加最大池化层以及3层全连接层。
本文使用的CNNs模型包括3层卷积层,输入通道数分别为3、32、32,输出通道数分别为32、32、32,卷积核(kernel-size)均为3,步长(stride)默认为1,无填充(padding-mode)。激活层均采用ReLU函数,利用最大池化层(MaxPool2d)提取重要信息,减少计算量,kernel-size和stride均为2。全连接层输入输出通道数分别为576×256、256×256、256×2。模型具体参数结构如表2所示。
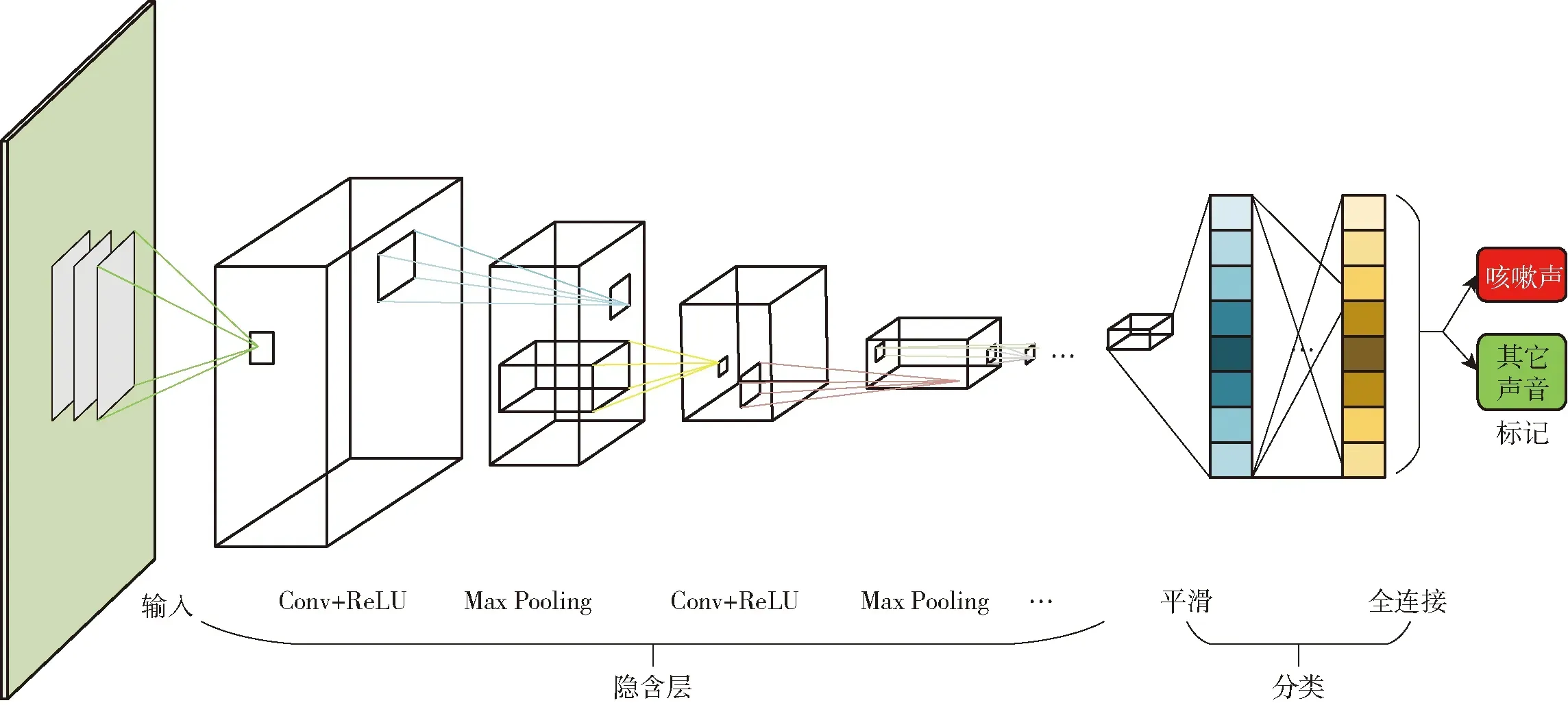
图6 基于CNNs的咳嗽声识别模型结构Fig.6 Structure of cough recognition model based on CNNs
2.2.2基于DFSMN的猪咳嗽声识别模型
前馈序列记忆神经网络(DFSMN)通过进一步在cFSMN的记忆模块之间添加跳转连接(Skip connection),从而可以将低层记忆模块的输出直接累加到高层记忆模块里,有利于解决网络深度造成的梯度消失问题。DFSMN记忆单元公式为
(5)
其中
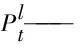
Vl——第l个隐含层和第l个线性投影层的权值
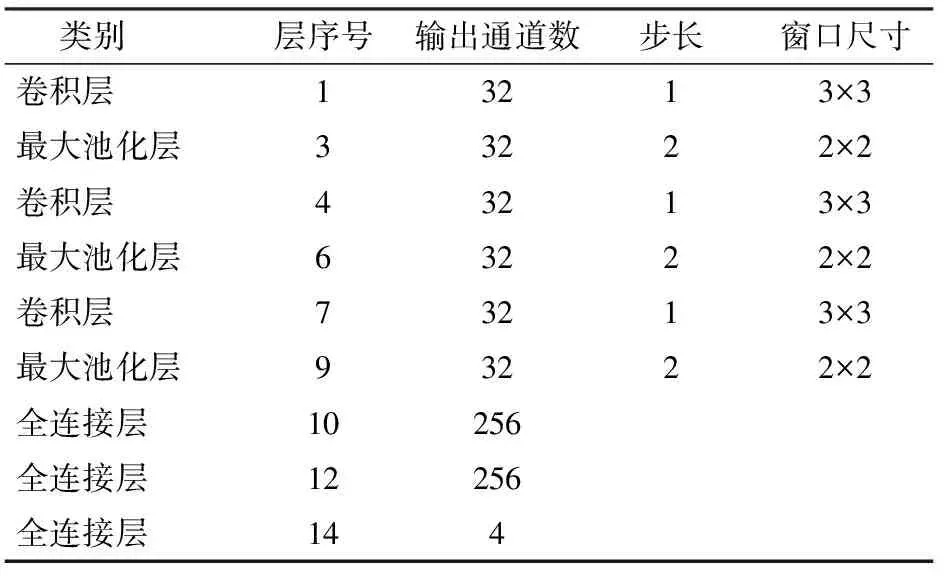
表2 CNNs模型结构参数Tab.2 Model structure parameters of CNNs

bl——第l个隐含层和第l个线性投影层的偏置

H(·)——记忆模块之间的跳转连接函数
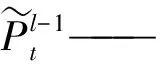

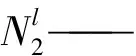



图7 DFSMN结构Fig.7 Structure of DFSMN


s1——反向滤波器的编码步幅因子
s2——前向滤波器的编码步幅因子
在声音信号预处理中,相邻帧信息由于重叠而具有很强的冗余性,DFSMN将步长因子添加到记忆块中,以消除这种冗余。总延迟与每个记忆块中的步长和前向过滤器顺序有关,计算公式为
(6)
式中τ——记忆模块的延迟
L——记忆模块总数
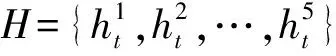
咳嗽声识别模型输入层接着一层卷积网络,DFSMN部分由3层DFSMN组成,紧接着3个ReLU激活函数层和3层全连接层,最后是输出部分。卷积层输入通道数为每种特征及其一阶和二阶差分组合,设置为3,输出通道数依据经验值即卷积核个数,设置为2的倍数32,卷积核通道数依据输入通道数设置为3;DFSMN层模型输入特征维度由上层卷积运算后进行数组重新组合得到,具体输入分别为1 984、256、256个单元,输出特征维度与下一层矩阵维度匹配,可进行矩阵运算,输出均为256个单元;全连接层同理,输入分别为9 728、256、256个单元,输出为256、256、4个单元。图8为基于DFSMN的咳嗽声识别模型框架,图中InF、OutF分别表示输入、输出特征,In-Conv、L-Conv、R-Conv分别表示输入、左半部分、右半部分网络的一维卷积层。
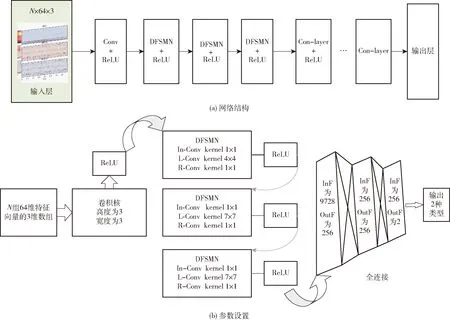
图8 基于DFSMN的咳嗽声识别模型Fig.8 Cough recognition model based on DFSMN
2.2.3模型训练步骤与参数设置
深度神经网络模型训练步骤通常随机生成初始模型参数,算法代入设定好的学习率和迭代次数N;由损失函数获得损失值(loss);计算导数后由优化函数(optimizer)得到下一次迭代的优化参数;不断迭代直至迭代N次。
本文的神经网络具体操作步骤如下:①整体网络框架构建,包括训练集、验证集、测试集样本数据加载。由于原始音频时长不一,特征提取后帧数不同,在输入模型之前需要对数据进行长度统一,本文取最大长度40帧为阈值,不足40部分由零填充,超过40强制截取最大长度。创建以时间为名的文件夹,用来存储模型结果。②超参数初始化,每轮模型训练中,利用shuffle函数打乱样本顺序。训练一次取出样本数据64个,全部数据参与训练完成一次迭代周期,初始轮数设置为100轮。设定随机梯度下降(Stochastie gradient descent, SGD)为优化器,学习率初始化为0.001,动量设置为0.9,学习衰减率为0.98。优化器公式为
(7)
Δθt=-ηgt
(8)
式中θt-1——模型参数
η——学习率
gt——损失值关于参数的梯度


(9)
式中H——损失函数值
p——样本真实分布
q——模型预测的样本分布
p(x)——期望输出
q(x)——实际输出
③开始训练后每次迭代完成计算损失并更新参数,每50个迭代周期降低一次学习率。④训练结束对比验证集和测试集的训练效果,手动调整相对应的超参数,当训练集和验证集的损失值、精确率浮动误差不超过2%时,停止训练。
3 实验结果与分析
本实验均在一台配置为1块GTX1080Ti显卡、有效内存31.1 GB、2块Xeon Gold 5118CPU的工作站进行训练,所涉及算法均基于pytorch深度学习开发库。
3.1 模型评价指标
通过混淆矩阵形式清楚表示分类识别结果的咳嗽声正确识别个数、咳嗽声误识别个数、其它声音正确识别个数与误识别个数,并通过准确率(Accuarcy)、精确率(Precision)、召回率(Recall)和F1值来衡量猪咳嗽声识别模型的性能。
3.2 不同迭代次数和特征提取方法对模型效果的影响
3.2.1不同迭代次数
影响深度学习模型性能的因素通常包括学习率、迭代次数、初始化参数等,数据集数量、迭代次数、模型深度对模型效果的影响尚未发现普遍规律。
实验设置从100轮开始每次增加50轮直至250轮,MFCC-CNNs模型测试集准确率在100~200轮之间不断上升,在训练轮数200时咳嗽声精确率达到97%,其它声音精确率为93%,召回率咳嗽声为96%,其它声音为93%,F1值咳嗽声为98%,其它声音为93%,总体识别准确率为96.71%。随着训练轮数继续增加,模型准确率并不会继续提高,识别准确率稳定在91%以上。logFBank-CNNs模型性能较稳定,测试集的准确率基本稳定在94%左右。MFCC-DFSMN模型最高准确率在200轮时达到92.46%,总体识别率较低,模型总体性能较差。logFBank-DFSMN模型咳嗽声识别准确率稳定在90%以上,最高达到95.89%。
表3为不同迭代次数对不同模型在验证集和测试集上咳嗽声和其它声音的识别效果对比,表中P1、P2、R1、R2、F1、F2、A分别表示咳嗽声和其它声音的精确率、召回率、F1值以及总体识别准确率。综上分析在训练轮数为200时,MFCC-CNNs模型对咳嗽声的识别效果最好。不同特征与神经网络的组合随训练次数不同,识别准确率存在上下波动情况,波动幅度不超过4%,总体稳定性较好。
3.2.2不同特征提取方法
表4、5为两种神经网络模型训练次数为200时不同特征输入下咳嗽声和其它声音的精确率、召回率、F1值和总体识别准确率的比较。模型在两种特征输入下,测试集和验证集的结果基本相同。
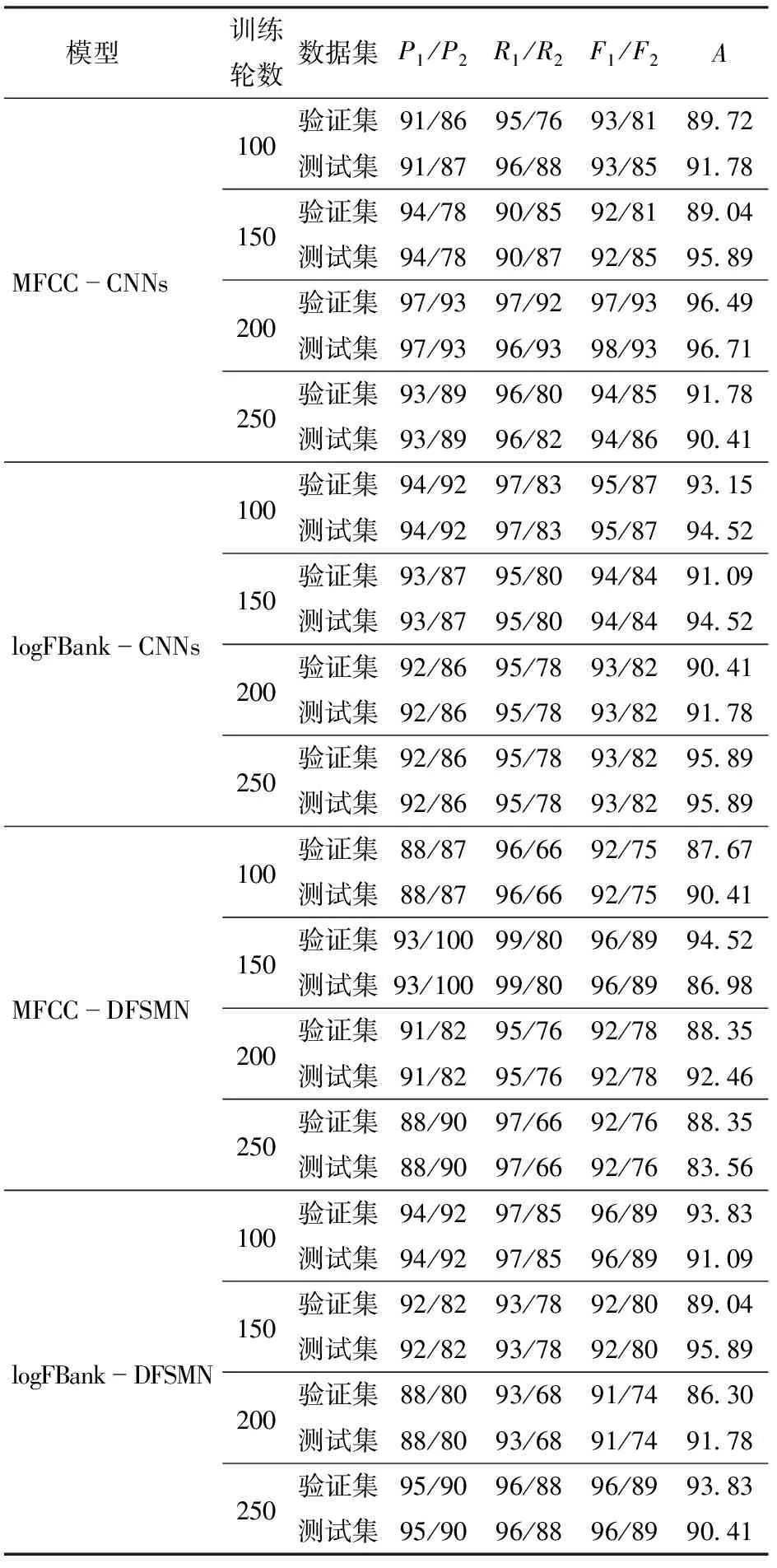
表3 不同迭代次数识别效果Tab.3 Experiment results of different iteration times %
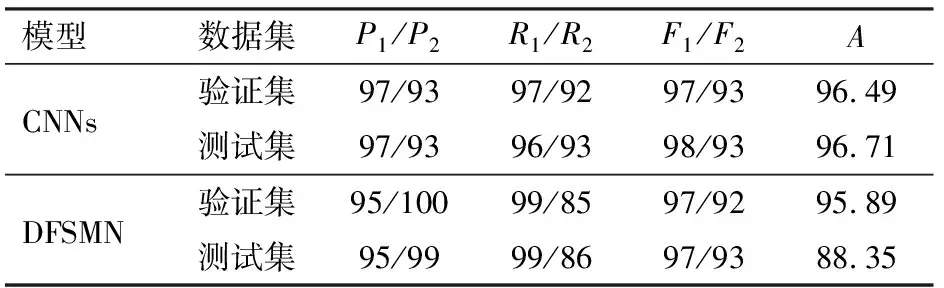
表4 MFCC特征识别效果Tab.4 Recognition effect of MFCC %

表5 logFBank特征识别效果Tab.5 Recognition effect of logFBank %
由图9a可以明显发现,以MFCC为特征的两种模型准确率均高于以logFBank为特征的模型,且MFCC-CNNs的准确率最高。由图9可以看出,CNNs模型在迭代周期数为25时,准确率还处于上升阶段,此时损失值曲线处于不断下降状态,波动较小,而后逐渐平稳,模型收敛。DFSMN模型准确率与损失值趋于平稳状态要早于CNNs模型,最终logFBank-CNNs、logFBank-DFSMN、MFCC-CNNs、MFCC-DFSMN 4种模型验证集训练损失值分别为0.032、0.044、0.025、0.028。
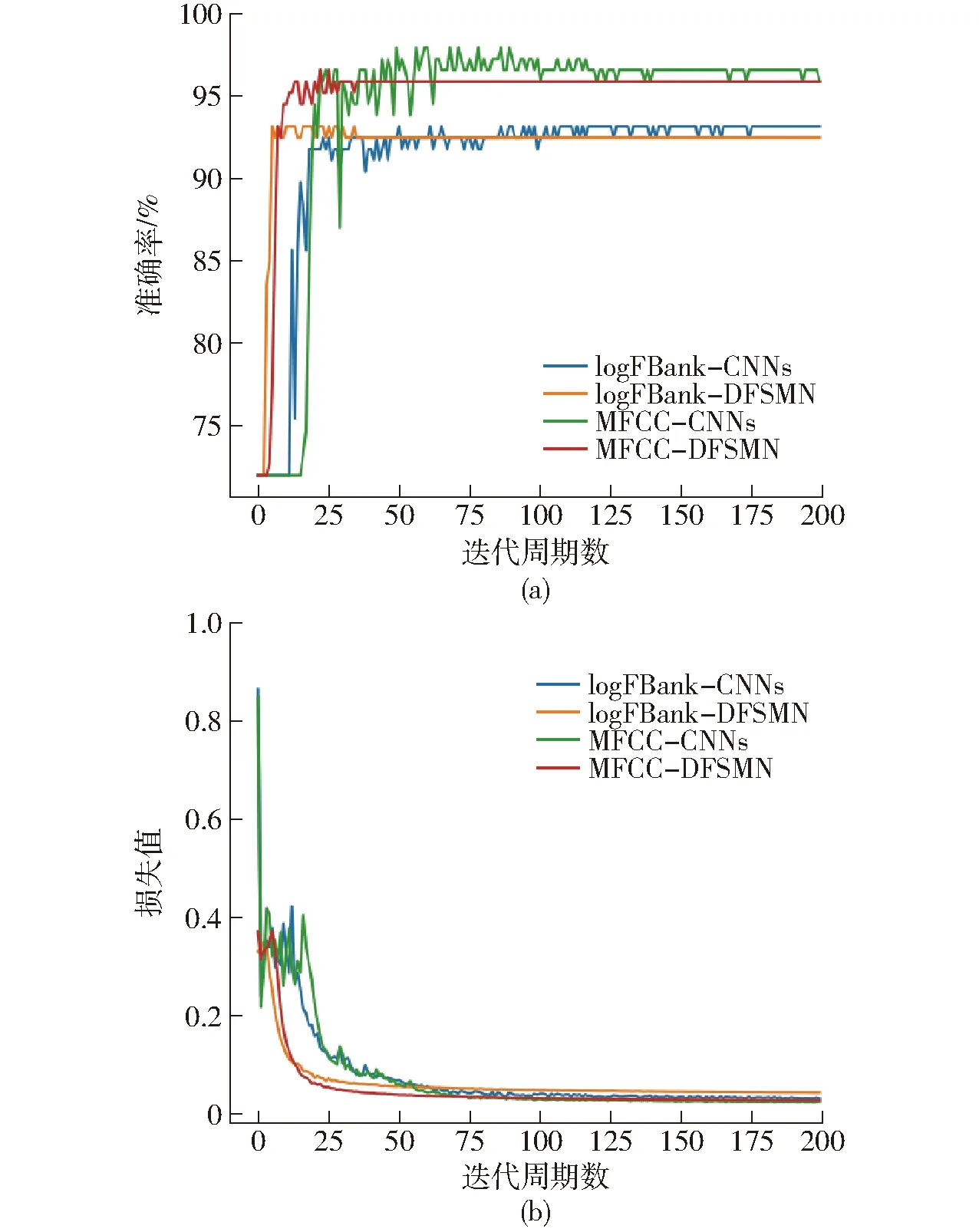
图9 4种模型验证集准确率、损失值变化曲线Fig.9 Accuracy and loss curves of four models
3.3 MFCC-CNNs对4种声音的分类效果
猪只的咳嗽声和喷嚏声由人耳试听存在一定相似度,为了更加准确地对猪只的不同声音进行区分,在二分类的基础上将标签数增加至4个,检验MFCC-CNNs模型对4种声音分类识别的效果。表6为训练100轮后测试集上的模型评价指标结果。由测试集结果可知,总体识别准确率为92.47%。相较咳嗽声,其它3种声音召回率和F1值都比较低,考虑原因是样本数量不均衡或者样本数量较少导致。图10为MFCC-CNNs模型训练过程,图10a表明验证集准确率尚未达到训练集水平,图10b表明损失值均随着网络迭代周期数逐步下降,最终趋于稳定,损失值分别为0.009、0.052。
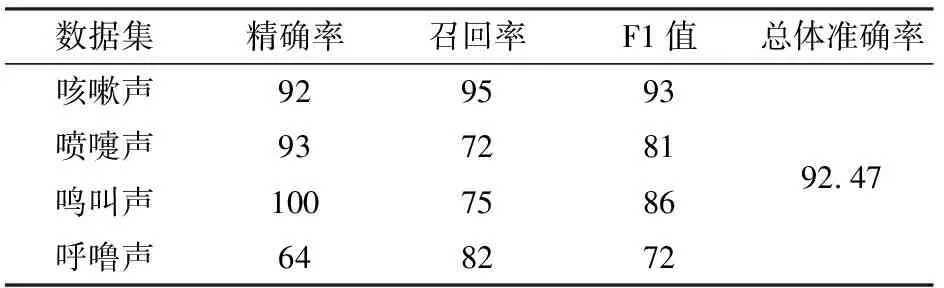
表6 MFCC-CNNs四分类效果对比Tab.6 Comparison of four classification effects of MFCC-CNNs %
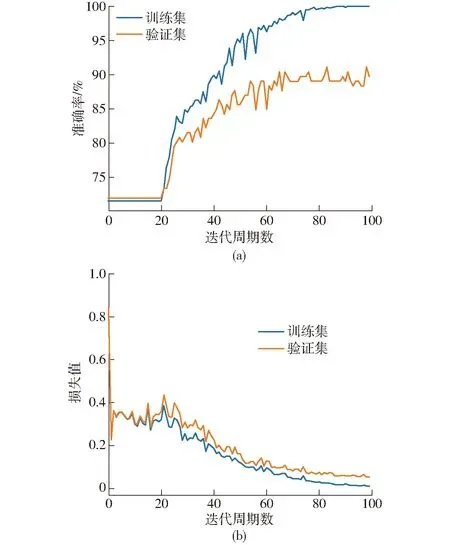
图10 MFCC-CNNs训练过程Fig.10 MFCC-CNNs training process
4 结论
(1)提出了一种基于MFCC-CNNs的深度神经网络猪咳嗽声识别方法。通过传统谱减法处理后原始声音噪声明显减小,利用双门限端点检测法得到有效声音信号后分别提取logFBank和MFCC特征,结果显示以MFCC为特征的CNNs咳嗽声识别模型准确率最高,咳嗽声识别精确率为97%,召回率为96%,F1值为98%,总体识别准确率为96.71%。
(2)将深层卷积神经网络与前馈序列记忆神经网络引入猪咳嗽声识别领域,通过设置不同迭代次数的对比实验可知,不同迭代次数对二分类模型结果的影响最大误差不超过4%,且以MFCC为特征输入的模型准确率普遍高于以logFBank为特征输入的模型。
