基于Vitis AI的可行驶区域检测定制计算系统设计
2022-06-20李慧琳柴志雷
李慧琳 柴志雷









摘 要:针对基于卷积神经网络的可行驶区域检测方法计算耗时长、实时性差等问题,基于Vitis AI为其设计了一种定制计算系统,并通过采用模型定点化、网络剪枝、硬件定制等优化方法,实现了对可行驶区域检测方法的高效计算。实验结果表明,在Xilinx ZCU102异构计算平台上,可编程逻辑部分的工作频率为200 MHz时,所实现的可行使区域检测系统的识别帧率可达到46 FPS,计算性能可达903 GOPS,能效比为50.45 GOPS/W,可以较好地满足实际系统的需求。
关键词:现场可编程门阵列;Vitis AI;可行驶区域检测;定制计算系统;卷积神经网络
中图分类号:TP391.4 文献标识码:A文章编号:2096-4706(2022)01-0073-06
Abstract: Aiming at the problems of long calculation time and poor real-time performance of the drivable area detection method based on convolutional neural network, a customized computing system is designed based on Vitis AI, and optimization methods such as model fixed-pointization, network pruning, and hardware customization are adopted, which realizes the efficient computing of the drivable area detection method. The experimental results show that on the Xilinx ZCU102 heterogeneous computing platform, when the operating frequency of the programmable logic part is 200 MHz, the recognition frame rate of the realizable area detection system can reach 46 FPS, the computing performance can reach 903 GOPS, and the energy efficiency ratio is 50.45 GOPS/W, which can better meet the needs of the actual system.
Keywords: field programmable gate array; Vitis AI; drivable area detection; customized computing systems; convolutional neural network
0 引 言
可行驶区域检测,指的是自动驾驶系统通过分析车辆前方拍摄的区域图像,来判断前方是否为没有车辆行人等障碍物的可行驶区域。可行驶区域检测是自动驾驶系统中环境感知的核心任务之一,目前主要有基于传统计算机视觉和基于深度学习两种不同的方法。传统计算机视觉的方法包含基于颜色、纹理、边缘等直接特征和基于间接特征的可行驶区域检测,这些方法受限于人工设计特征和先验知识,对环境的鲁棒性不高,通常只能在特定的简单环境下使用[1]。基于深度学习的方法是通过语义分割来得到可行驶区域的,基于语义分割对图像中的每一个像素点给出一个分类结果,自动提取出语义特征,可以不受限于先验知识和特定的场景输出稠密的预测图。这种预测在很大程度上保留了原始图像的边缘信息和语义信息,有助于无人驾驶对场景的理解。因此基于深度學习的可行驶区域检测已经成为目前环境感知中的主流方法[2]。与传统的方法相比,基于深度学习的方法不依赖于手工特征,分割精度大大提升,能够解决复杂环境下的图像处理问题,可以极大提高算法对环境的鲁棒性[3]。
但基于深度学习的可行使区域检测方法计算复杂度高、运算量大。如Chen等人[4]提出的道路分割网络PLARD,在NVIDIA GTX Titan GPU平台上依然需要耗时0.16 s;SNE-RoadSeg+网络[5]使用Tensor RT加速后,在2.5 GHz工作频率的GPU平台上仍然耗时0.08 s。可见上述关于可行使区域检测的工作还难以满足自动驾驶等对实时性要求较高的应用场景的需要,而且上述基于GPU的加速方法还存在计算功耗高、散热困难,难以用于车载场景等嵌入式环境的问题。
为了提升可行使区域检测的计算性能及能效比,不少工作开始尝试基于FPGA设计定制计算系统进行加速。文献[6]提出了用于可行使区域检测的深度卷积神经网络Q-SegNet,并基于Xilinx ZCU104对其进行加速,达到了501 GOPS/W的能效比;文献[7]提出二进制SegNet模型,并在Xilinx VCU118上实现了351.7 GOPS/W的能效比。可见基于FPGA的方式由于硬件架构可定制、能适应不同位宽、可更好地支持定点化等优势可以获得更好地能效比,是嵌入式环境下实现可行使区域检测的一种有效途径。
但是传统的基于FPGA的定制计算系统需要通过编写VHDL/Verilog或者HLS等硬件描述语言实现,要求开发人员具有底层的硬件和系统知识,且开发难度大、开发周期长[8]。为此Xilinx提出了Vitis AI,它提供了一系列完整的工具和API,帮助用户完成具体的量化、剪枝等优化和编译预训练好的模型,不需要编写HDL和具备底层硬件知识,降低了基于FPGA设计定制计算系统的难度,可以快速地在Xilinx平台上部署AI推理模型。但是针对特定模型,如何根据其计算特点快速确定适合Vitis AI实现的优化方法并充分利用Vitis AI优化能力及硬件定制能力获得最佳计算性能?这方面的研究尚不多见。
因此本文以FCN可行使区域检测模型为对象,研究了其网络模型的计算特性,并针对Vitis AI提出了参数量化、剪枝、模型压缩等优化方法;同时基于DPU对硬件架构进行了定制;完成了一套完整的定制软硬件系统。该定制系统在ZCU102上达到了46 FPS的处理性能及50.45 GOPS/W的能效比,验证了本文方法的有效性。说明基于Vitis AI的方式有望成为FPGA定制深度学习计算系统的一种可行手段。
1 基于CNN的可行驶区域检测
1.1 算法原理
本文采用的基于深度学习的语义分割算法全卷积网络(Fully Convolutional Networks, FCN)[9]整体架构如图1所示。FCN被广泛应用于像素级别分类,其输出是带有图像语义信息的类别矩阵。全卷积网络模型主要用输入输出、卷积池化和反卷积层构成,其核心思想是将一个全连接层转换为一个1×1大小的卷积层,使用反卷积或者上采样操作生成与输入图像大小相同的类别矩阵。FCN是语义分割的代表算法,该网络主要丢弃了CNN的全连接层并且用卷积层替代,在提高分割效率的同时也降低了计算的复杂度。
1.2 计算性能分析
本文所用网络架构FCN-8s共有8层,在功率为65 W的通用计算平台i56500上对模型进行性能分析,结果表明该模型处理224×224×3尺寸的图像需要187 ms,帧率为5.4 FPS。
如表1所示,该网络参数量总计2.80×107个,需占用内存约106.81 MB,计算量共3.41×1010即34.1 GFLOPs浮点运算,可见该模型较大的参数量和巨大的浮点计算量影响了计算的实时性。因此本文拟分别从算法层面降低计算量并通过DPU架构优化进行硬件加速两个方面解决上述计算问题。
2 降低模型的计算量
2.1 网络定点化
由1.2分析可知,模型存在大量的浮点计算,浮点计算耗时明显高于定点计算。因此将浮点参数转换为适当位宽的定点参数是降低深度神经网络模型计算复杂度的一个行之有效的方法,且可以利用FPGA能灵活地支持不同位宽的定点数的优势充分提升计算能效,还能够起到压缩存储空间的作用。
本文量化采用8比特对称均匀量化方案,通过二次幂大小的放缩比例来把原始浮点数据映射到特定的对称整数区间中,对硬件加速器较为友好。通过式和式确定缩放比例scale,即定点位置。其中fmin、fmax表示真实浮点数集合的最大值和最小值,本文中float32的值为-3.4×1038和3.4×1038。INT_MIN、INT_MIX表示给定整数位宽能表示的最小值和最大值,本文8 bit量化位宽的两个值分别为-128和127。
式为量化的公式,其中x为原浮点类型参数,scale为式算出的缩放比例,Xint为量化后的定點数。
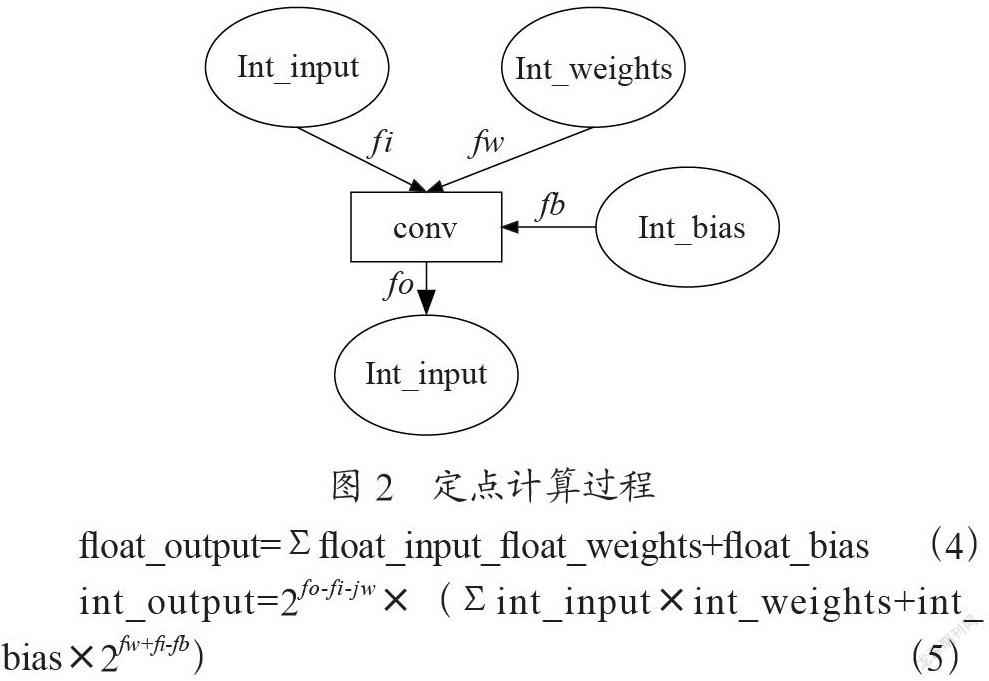
如图2所示卷积层conv为例,分析硬件对定点数的计算过程,其中fi、fx、fb、fo是各种数据的定点位置。由量化原理结合式可以得出式,可以看到量化后的运算只有整数乘加和移位运算,对硬件非常友好,也是这种量化方案的优势所在。
根据上述量化原理,同时基于vai_q_tensorflow对本文模型进行量化。整体量化流程如图3所示,Vitis AI量化器使用浮点模型作为输入并且执行预处理操作,如折叠batchnorm层并且移除无用节点,然后将权重、偏差和激活量化为给定的位宽。量化校准激活之后,量化模型转换为可部署到DPU上的模型,最后使用Vitis AI编译器将该模型编译部署到DPU上。
2.2 通过降低通道数提升计算性能
本文所用通道剪枝方法中通道的选择是通过LASSO regression来做的,即在损失函数中添加L1范数对权重进行约束。图4是对卷积层进行通道剪枝的示意图,其中A为输入特征图,B为经过通道剪枝后的特征图,c为B的通道数,W为卷积核,kh和kw为卷积核尺寸,所以每个卷积核的维度为kh×kw×c。由于特征图的部分通道被裁剪,所以相应卷积核的通道已经没有存在的价值,也要被裁剪掉。C为输出特征图,n为输出特征图的通道数,即W卷积核的个数,可以看出C的维度和卷积核的数量有关,且输出是完整的,故通道剪枝的过程不会对下一层卷积造成影响,仅影响卷积内部的运算即参数量和计算量。
本文的裁剪通道是通过优化一个二值决策变量0和1选取的,其中0表示裁剪,1表示保留,即式中的βi,其中c为通道数量,i为通道数量的索引,Xi和Wi分别对应输入特征图和卷积核的每个通道,对应图中的B和W,因此,当βi为0时,即通道无作用被裁减掉,βi为1则保留该通道。Y表示转成矩阵形式的输出,对应于图中的C,N表示对样本的采样数,双竖线表示矩阵的二范数。求解此NP-hard问题需要加入L1正则化项,问题变为式所示的Lasso回归问题,通过最优化该式即可选取出裁剪通道。
在对完整的网络结构进行剪枝时,由于后面是池化层的特征图连接了后面反卷积的特征图,此时需要考虑前后部分产生的重构误差,实现较难且裁剪的损失概率变大,所以通道剪枝时应当选择前后都是卷积的层。
3 基于Vitis AI的定制计算架构实现
3.1 Vitis AI
如图5所示,Vitis AI开发环境可以在Xilinx硬件平台上加速AI推断,包括边缘器件和Alveo系列数据中心加速卡。此环境由经过最优化的IP核、工具、库、模型和设计示例组成。Vitis AI的开发流程需要Vitis AI和Vitis IDE,包含3个基本步骤。首先Vitis AI开发套件用于构建模型,输入是预先训练好的浮点模型。再使用Vitis软件平台来构建定制的硬件平台,生成包括DPU IP以及其他内核在内的硬件信息。最后在构建的硬件上运行构建好的可执行软件,使用C++或者Python调用Vitis AI运行时环境来加载并运行编译后的模型软件。
3.2 DPU
3.2.1 DPU架构
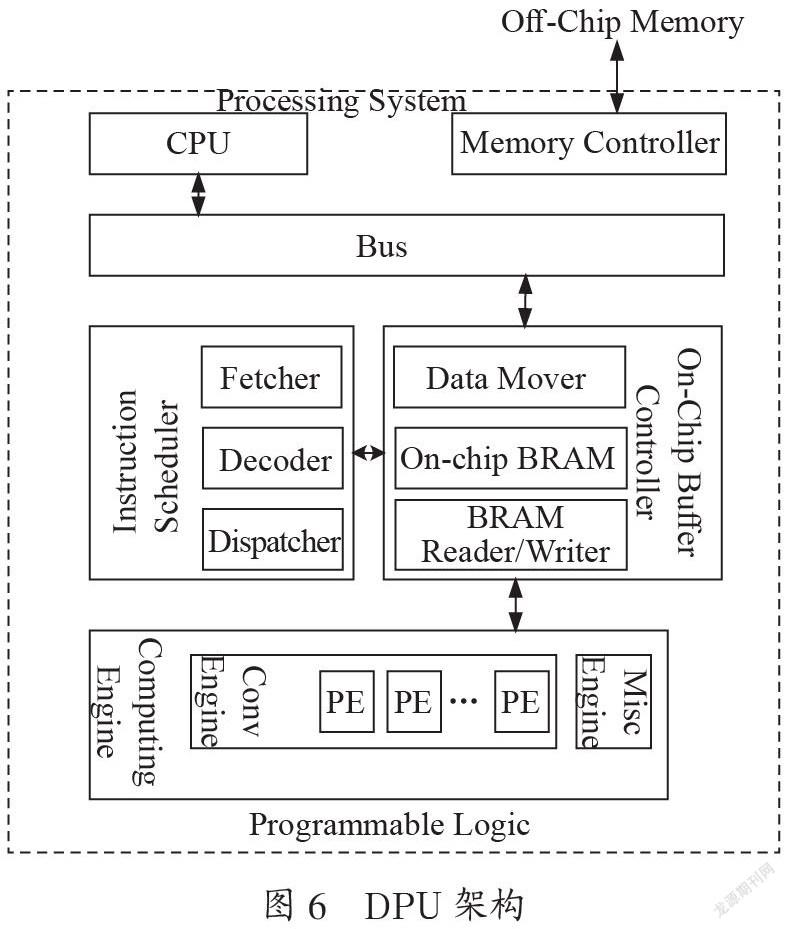
图6是DPU的硬件架构,DPU参数可以根据实际应用进行配置,以优化资源利用率和实现功能定制。DPU编译器将神经网络模型转化为一系列DPU指令,DPU启动后从片外存储器中获取这些指令来控制计算引擎可编程逻辑的调度。计算引擎采用深度流水线设计并包含一个或者多个处理单元PE,每个处理单元由乘法器、加法器和累加器等构成。DPU在片上存储器BRAM中存储模型数据、缓存输入、输出和中间数据来减少外部存储器的带宽。DPU通过AXI总线直接连接到处理器系统PS端进行数据传输,其中有一个获取指令的低带宽端口和两个存取数据的高带宽端口。
3.2.2 通过配置DPU提升计算性能
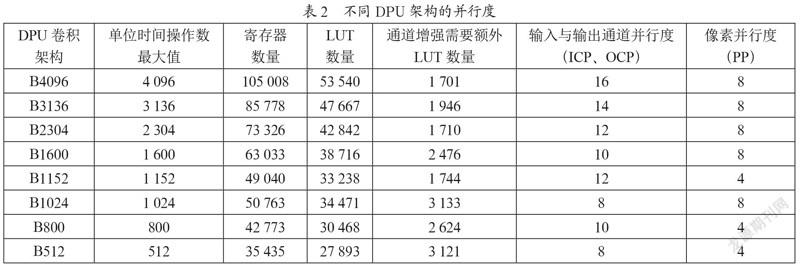
DPU IP可以配置各种与卷积单元并行度相关的卷积架构,如表2所示,DPU IP的架构包括从B4096到B512共八种型号。DPU卷积架构的并行度包括了像素并行度、输入通道并行度和输出通道并行度,输入通道并行度等于输出通道并行度,不同的架构所需可编程逻辑资源不等,通常并行度越高的架构耗费高资源实现更高的性能。
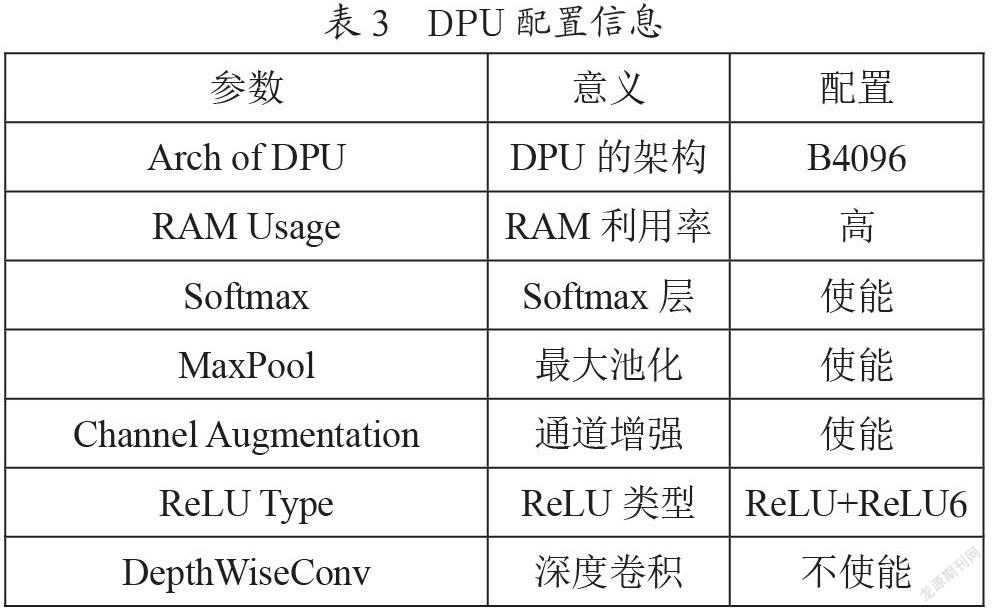
针对不同的卷积神经网络可以配置不同的DPU卷积架构,如DPU核心数、RAM利用率、通道增强、深度卷积、最大池化、ReLU类型以及Softmax等皆可配置。本文所设计DPU的配置如表3,在一个DPU IP中最多可以选择三个内核,每个内核都可以根据需要配置为不同的架构,使用多个DPU内核会消耗更多的可编程逻辑资源。本文实验中所用板卡为Xilinx Zynq UltraScale系列板卡,DPU配置了一个B4096架构的内核。本文DPU设置为高RAM利用率,这是因为网络的权重、偏差和中间特征都缓冲在片上存储器中,设置为高RAM利用率意味着片上存储更大,DPU能更灵活地处理中间数据。本文DPU在硬件中实现了Softmax功能,其硬件实现比软件实现快160倍,实现硬件Softmax模块额外需要约10 000个LUT、4个BRAM和14个DSP,配置最大池化即网络的池化操作可以在DPU上进行。
通道增强能在网络输入通道数低于DPU硬件通道并行度时提高DPU的效率,本文中网络输入通道数为3,B4096型号DPU架构的通道并行度为16,故配置通道增强功能。ReLU类型可以决定在DPU上配置哪种激活函数,默认是ReLU和ReLU6。在深度可分离卷积中,运算分为深度卷积和点卷积两步进行,配置深度可分离卷积的并行度下降约一半,本设计中不配置。
3.2.3 总体设计
如图7所示,本文实现的FPGA硬件加速器系统设计基于ARM+FPGA架构,主要包括了双倍速率的片外存储DDR、FCN DMA(Direct Memory Access,直接存储器訪问)、片上缓存BRAM、可编程逻辑FCN加速器等。加速器主要包括处理单元PE模块、片上缓冲器和可编程网络逻辑模块。PE模块的设计有利于减少数据移动,减少片外内存的访问次数,同时提高数据的复用率。PE模块可以完成卷积、最大池化和激活操作[10]。片上和片外通过AXI总线相连,主机PC负责整个系统的任务调度,发布工作和指令并且监控系统的工作状态。对于不同的图像输入,系统读取初始输入图像的输入和权重,将其存储在外部存储器DDR中,然后加速器从DDR读取和写入相应的输入数据,硬件加速器通过AXI总线与ARM通信并接受配置信号。
4 实验结果与分析
4.1 实验环境
CNN模型:FCN。
FPGA平台:Xilinx Zynq® UltraScale+™ XCZU9EG-2FFVB1156E MPSoC开发板。
4.2 降低通道数后的实验结果分析
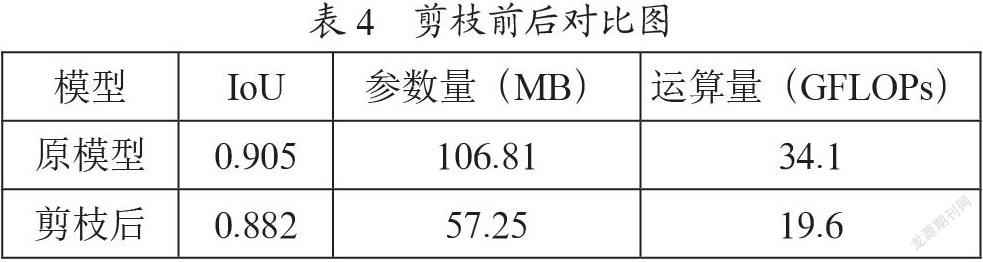
为了验证通道剪枝的有效性,实验对原模型、剪枝后的模型进行了参数量和运算量的比较。由表4可以看到,剪枝后模型的参数量和运算量都下降了近一半,而精度损失了0.023,在牺牲少量精度的情况下实现了参数量及运算量的大量压缩,因此说明剪枝是有效的。
4.3 定点化的实验结果分析
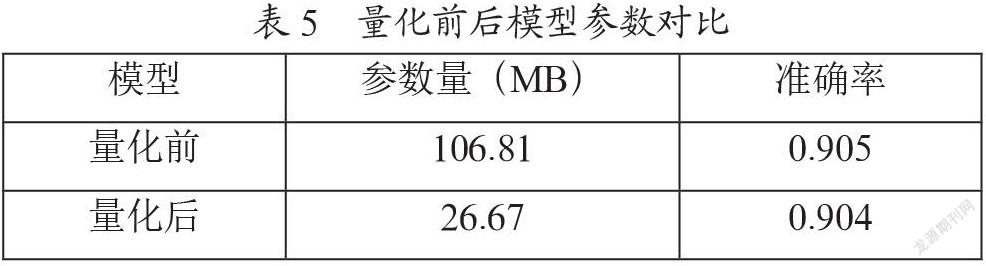
量化后的神经网络模型参数如表5所示,参数量下降为原来的1/4左右,与浮点网络相比量化后网络的准确率只下降了0.1%,精度的下降在可接受的范围内,因而量化是有效的。
4.4 配置DPU后的实验结果分析
表6展示了配置DPU的硬件资源使用情况及资源利用率。通过运行分析DPU的运算性能,经过优化后进行DPU加速的推理过程总耗时为21.7 ms,系统的识别帧率为46 FPS,达到了实时性的要求。所设计系统可编程逻辑部分的工作频率为200 MHz时,性能达到了903 GOPS,功耗为17.9 W,具有50.45 GOPS/W的能效比。
表7是本文方案与其他论文的实验结果对比,可以看出与使用相同FPGA平台的文献[11]和文献[12]相比,本文方法的性能分别是其2.9倍和1.8倍,能耗比分别是其3.9倍和1.6倍,性能计算和能耗比指标都更为优秀。
5 结 论
本文以FCN图像分割算法为例,设计并实现了基于Vitis AI的可行驶区域检测的卷积神经网络加速器架构。基于Vitis AI工具对分割网络进行通道剪枝、数据量化、DPU配置等一系列优化,解决了可行驶区域算法网络规模大、无法满足实时性要求的问题。实验结果表明通过定制硬件系统性能获得了极大的提升。
现有的FPGA定制方式难度大,神经网络加速中的很多参数都需要研究人员的实际经验来确定,编写低层次语言的工作量巨大。基于Vitis AI定制神经网络系统方便,可以达到很好的性能,有望成为一种很好的优化部署方式。
参考文献:
[1] CHEN T,CHEN B D,ZHANG X,et al. Free Space Detection Using Stereo Confidence Metrics and Obstacle Position Probability Maps [C]//2018 14th IEEE International Conference on Signal Processing(ICSP).Beijing:IEEE,2018:1071-1075.
[2] FAN R,WANG H L,CAI P D,et al. SNE-RoadSeg:Incorporating Surface Normal Information into Semantic Segmentation for Accurate Freespace Detection [C]//Computer Vision–ECCV 2020.Glasgow:springer,2020:340-356.
[3] 李升波,关阳,侯廉,等.深度神经网络的关键技术及其在自动驾驶领域的应用 [J].汽车安全与节能学报,2019,10(2):119-145.
[4] CHEN Z,ZHANG J,TAO D C. Progressive LiDAR adaptation for road detection [J].IEEE/CAA Journal of Automatica Sinica,2019,6(3):693-702.
[5] WANG H L,FAN R,CAI P D,et al. SNE-RoadSeg+:Rethinking Depth-normal Translation and Deep Supervision for Freespace Detection [J/OL].arXiv:2107.14599 [cs.CV].(2021-07-30).https://arxiv.org/abs/2107.14599.
[6] AHAMAD A,SUN C C,NGUYEN H M,et al. Q-SegNet: Quantized deep convolutional neural network for image segmentation on FPGA [C]//2021 International Symposium on Intelligent Signal Processing and Communication Systems(ISPACS).Hualien City:IEEE,2021:1-2.
[7] LYU H R,AN F W,ZHAO S R,et al. A703.4 GOPs/W Binary SegNet Processor with Computing-Near-Memory Architecture for Road Detection [J].IEEE Design & Test,2020,39(2):74-83.
[8] 陈辰,柴志雷,夏珺.基于Zynq7000 FPGA异构平台的YOLOv2加速器设计与实现 [J].计算机科学与探索,2019,13(10):1677-1693.
[9] SHELHAMER E,LONG J,DARRELL T. Fully Convolutional Networks for Semantic Segmentation [J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(4):640-651.
[10] ZHANG J L,LI J. Improving the Performance of OpenCL-based FPGA Accelerator for Convolutional Neural Network [C]//The 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays. Monterey:Association for Computing Machinery,2017:25-34.
[11] CHEN Y H,KRISHNA T,EMER J,et al. 14.5 Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks [C]//2016 IEEE International Solid-State Circuits Conference(ISSCC).San Francisco:IEEE,2016:262-263.
[12] BIANCO S,CADENE R,CELONA L,et al. Benchmark Analysis of Representative Deep Neural Network Architectures [J].IEEE Access,2018,6:64270-64277.
作者簡介:李慧琳(1997—),女,汉族,湖南郴州人,硕士研究生在读,研究方向:嵌入式系统;柴志雷(1975—),男,汉族,山西新绛人,教授,博士,研究方向:软件定义的高效计算机系统、嵌入式系统、软硬件协同设计等。
