融合数据增强与半监督学习的药物不良反应检测
2022-06-16佘朝阳徐广义邓忠莹
佘朝阳,严 馨,徐广义,陈 玮,邓忠莹
(1.昆明理工大学 信息工程与自动化学院,昆明 650504;2.昆明理工大学 云南省人工智能重点实验室,昆明 650504;3.云南南天电子信息产业股份有限公司,昆明 650041)
0 概述
药物不良反应(Adverse Drug Reaction,ADR)检测是药物研究和开发的重要组成部分。以往的研究数据主要来源于药物不良反应报告[1]、生物医学文献[2]、临床笔记[3]或医疗记录[4]。目前,医疗社交媒体例如MedHelp、好大夫、寻医问药、丁香医生等均提供了诸如专家问诊、论坛讨论、电话视频交流等形式多样的信息收集手段,形成了具有权威性、时效性和全面性的互联网医疗数据源,为药物不良反应检测提供了丰富的语料基础。
药物不良反应检测通常被看作涉及ADR的文本二分类问题,即辨别文本是否包含ADR的问题。早期,大多数研究均基于词典识别文本中的ADR[5-6],但这类方法无法识别词典中未包含的非常规ADR词汇。后来有些研究人员发现,利用统计机器学习方法抽取特征能够有效提高准确性[7-8]。随着深度学习的不断发展和广泛应用,基于深度学习方法的ADR 检测模型大量涌现。LEE等[9]为Twitter中的ADR分类建立了卷积神经网络(Convolutional Neural Network,CNN)模型,COCOS等[10]开发了一个递归神经网络(Recurrent Neural Network,RNN)模型,通过与任务无关的预训练或在ADR检测训练期间形成词嵌入向量,并将其作为输入。HUYNH等[11]提出2种新的神经网络模型,即将CNN 与RNN 连接起来的卷积递归神经网络(Convolutional Recurrent Neural Network,CRNN)以及在CNN中添加注意力权重的卷积神经网络(Convolutional Neural Network with Attention,CNNA),针对Twitter数据集分别进行了ADR分类任务。PANDEY等[12]分别采用Word2Vec和GloVe模型从多渠道的医学资源中训练临床词的词向量,将无监督的词嵌入表示输入到双向长期短期记忆(Bi-directional Long Short-Term Memory,Bi-LSTM)神经网络中,并使用注意力权重来优化ADR 抽取的效果。
尽管深度学习模型往往表现很好,但通常需要基于大量标注数据进行监督学习。当标注数据过少时,容易出现过拟合现象,严重影响预测的准确性。目前,已有大量的研究从英文语料中检测ADR,但由于缺乏公开可用的中文医疗社交媒体的数据集,目前针对此方面的研究非常有限。
为解决标注数据不足的问题,本文提出一种基于数据增强与半监督学习(Semi-Supervised Learning,SSL)的药物不良反应检测方法。通过对未标注数据进行数据增强,使用分类模型产生低熵标签,以获得较为准确的伪标签。此外,将标注数据、未标注数据和增强数据混合,在文本向量空间中对混合样本进行插值,以扩增样本数量。
1 相关工作
1.1 文本增强
在少样本场景下采用数据增强技术,与同等标注量的无增强监督学习模型相比,其性能会有较大幅度的提升。文本增强技术如EDA算法[13]、回译[14]、TF-IDF等通常只针对标注数据进行有监督地数据增强。XIE等[15]将有监督的数据增强技术扩展到未标注数据中,以尽可能地利用未标注数据。GUO 等[16]针对文本分类任务,提出词级的wordMixup 和句子级的senMixup这2 种文本增强策略,通过分别对词嵌入向量和句子向量进行线性插值,以产生更多的训练样本,提升分类性能。
1.2 半监督学习
半监督学习是一种在不需要大量标签的情况下训练大量数据模型的方法。监督学习方法仅在标注数据上训练分类器而忽略了未标注数据。SSL 通过利用未标注数据的方法来减轻对标注数据的需求。在通常情况下,未标注数据的获取要比标注数据容易得多,因此SSL 所带来的性能提升通常都是低成本的。SSL 方法主要分为两类:一类是对一个输入添加微小的扰动,输出应该与原样本保持不变,即一致性正则化;另一类是使用预测模型或它的某些变体生成伪标签,将带有伪标签的数据和标注数据进行混合,并微调模型。
将增强技术与半监督学习方法整合于一个框架中的技术在计算机视觉领域已经取得成功。例如MixMatch[17]和FixMatch[18]方法均表现出了良好的性能。然而在自然语言处理领域,由于受文本的语法、语义关系等影响,此类方法的应用极少。
基于上述方法,本文将文本增强技术与半监督学习方法相结合,应用于面向中文医疗社交媒体的ADR 检测任务。利用回译对未标注数据进行增强,以获取低熵标签,并将得到的伪标签未标注数据和标注数据进行Mixup 操作,降低对标注数据的需求,充分发挥大量未标注数据的价值,提升ADR 检测模型的准确性。
2 本文方法
给定有限标注的数据集Xl=和其对应的标签Yl=,以及大量的未标注数据集Xu=,其中n和m是2个数据集中的数据量,∈{0,1}C是一个one-hot 向量,C是类别数。本文目标是能有效利用标注数据和未标注数据一起训练模型。为此,本文提出一种标签猜测方法,为未标注数据生成标签,将未标注数据视为附加的标注数据,并在标注数据以及未标注数据上利用Mixup 方法进行半监督学习。最后,引入了熵最小化损失。本文方法的总体框架如图1 所示。
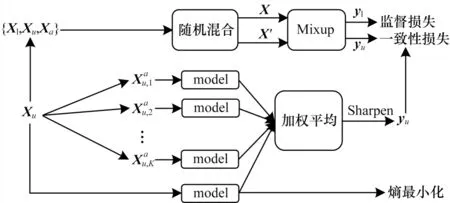
图1 本文方法框架Fig.1 Framework of method in this paper
回译是一种常见的文本增强技术,用机器翻译把一段中文翻译成另一种语言,然后再翻译回中文。通过对同一未标注数据进行不同中间语言的回译,可以得到不同的增强数据,且能保留原始文本的语义。对于未标注数据集Xu中的每一个,生成K个增强数据,其中k=[1,K],K表 示数据增强的次数。
2.1 标签猜测
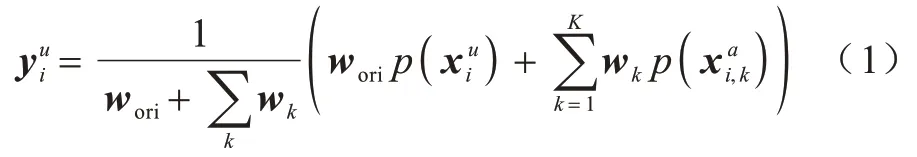
为了避免加权过于平均,对预测结果使用如式(2)所示的锐化函数进行处理:
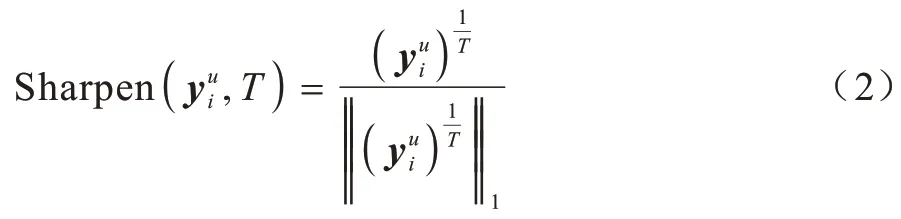
其中:‖·‖1是L1 范式;T是给定的超参数,当T趋向于0 时,生成的标签是一个one-hot 向量。
2.2 Mixup 图像增强方法
Mixup 是ZHANG 等[19]提出的一种图像增强方法,Mixup 的主要思想非常简单,即给定2 个标记数据(xi,yi)和(xj,yj),其中x是图像,而y是标签的onehot 向量,通过线性插值构建虚拟训练样本,如式(3)和式(4)所示:
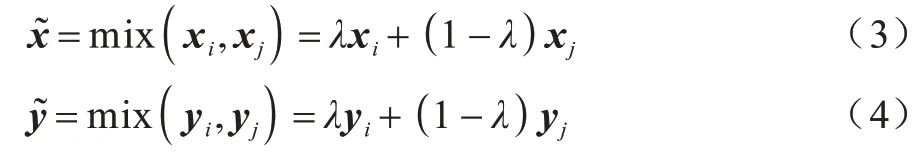
其中:混合因子λ∈[0,1],由Beta 分布得到:

新的训练样本将被用于训练神经网络模型。Mixup 可以看作是一种数据增强方法,能够基于原始训练集创建新的数据样本。同时,Mixup 强制对模型进行一致性正则化,使其在训练数据之间的标签为线性。作为一种简单有效的增强方法,Mixup可以提升模型的鲁棒性和泛化能力。
受Mixup 在图像分类领域运用的启发,本文尝试将其应用于文本分类任务中。通过标签猜测得到未标注数据的标签后,将标注数据Xl、未标注数据Xu和增强数据Xa=合并成一个大型的数据集X=Xl∪Xu∪Xa,对应的标签为Y=Yl∪Yu∪Ya,其中Ya=,并且定义,即对未标注数据,其所有的增强样本与原始样本共享相同的标签。
在训练过程中,本文从数据集X中随机采样2 个样本x、x′,根据式(7)和式(8)分别计算Mixup(x,x′)和mix(y,y′):
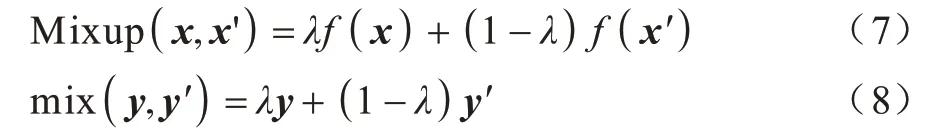
其中:f(·)是将文本编码为向量的神经网络。
混合样本通过分类模型获得预测值p(Mixup(x,x′)),将预测结果和混合标签进行一致性正则化,使用两者的KL 散度作为损失,计算公式如式(9)所示:
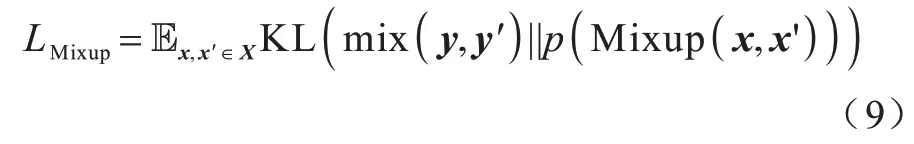
由于x、x′是从数据集X中随机采样而来的,因此2 个样本的来源有3 种情况:2 个都是标注数据,各有1 个标注数据和1 个未标注数据,2 个都是未标注数据。基于以上情况,将损失分为2 类:
1)监督损失。当x∈Xl时,即当实际使用的大部分信息来自于标注数据时,使用监督损失训练模型。
2)一致性损失。当样本来自未标注数据或增强数据时,即x∈Xu∪Xa,大部分信息来自于未标注数据,使用KL 散度作为一致性损失,能够使混合样本与原始样本具有相同的标签。
2.3 熵最小化
为使模型能够基于未标注数据预测出置信度更高的标签,本文使用未标注数据的预测概率最小熵作为损失函数:
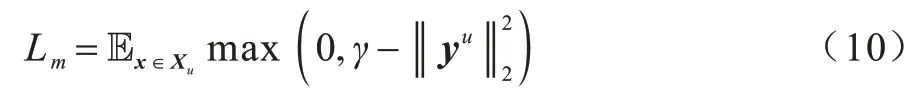
其中:γ是边界超参数。
结合2 种损失,构造总损失函数的表示式如式(11)所示:

3 本文模型
本文模型包含编码层、Mixup 层、分类层共3 层。输入文本经过编码层得到向量表示,Mixup 层通过随机混合的文本向量表示和对应的分类标签生成混合样本和混合标签。混合样本的向量表示经过Mixup 层被送入分类层。分类层通过全连接层和softmax 函数计算预测值,并针对混合样本的标签和预测值计算分类损失。本文模型的结构如图2所示。

图2 本文模型结构Fig.2 Structure of model in this paper
3.1 编码层
编码层分为ERNIE 层、BiLSTM 层、Attention 层共3 个子层。
3.1.1 ERNIE 层
传统的词向量模型Word2vec 得到的是静态词向量,无法体现1 个词在不同语境中的不同含义,而预训练模型能够动态捕捉上下文信息,提高文本表示能力。其 中ERNIE 等[20]提出一种知识掩码(Knowledge Masking,KM)策略,在训练阶段引入外部知识,并随机选取字、短语、命名实体进行mask,可以潜在地学习到被掩码的短语和实体之间的先验知识。此外,新增预训练任务,使ERNIE 词向量从训练数据中获取到更可靠的词法、语法以及语义信息。
中文医疗文本存在一词多义的问题,往往需要结合上下文语境才能获得精确的语义信息,且药物不良反应检测通常与外部知识、药物实体等密切相关。因此,本文使用百度开源的ERNIE 中文预训练模型,并充分利用该模型的外部知识和实体信息。
ERNIE 采用多层Transformer 作为编码器,通过自注意力机制捕获每个词向量在文本序列中的上下文信息,并生成上下文语境表征嵌入。以语料中的一个文本为例,文本中的词序列x=[w1,w2,…,wn],其中:n表示文本长度;wi表示文本中的第i个词。文本经过ERNIE 预训练模型得到词序列的向量表示E=[e1,e2,…,en],其中:ei∈Rd表示第i个词的词向量;d表示词向量的维度。
3.1.2 BiLSTM 层
BiLSTM 层以词向量表示为输入,计算词语在上下文中的向量表示:

3.1.3 Attention 层
Attention 层将BiLSTM 层的隐藏状态作为输入,通过自注意力权重分配来计算文本多个侧面的向量表示,表达式如下:
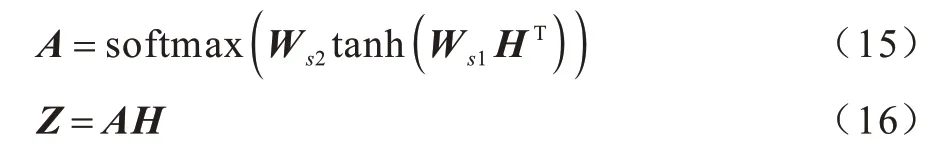
其中:A∈Rr×n表示注意力权重矩阵,由2 层感知器网络计算得到;分别是2 层注意力层的权重矩阵;da、r是超参数,da表示注意力层隐藏状态的维度,r是注意力机制的个数。
将文本表示矩阵Z∈Rr×2u中的r个向量拼接得到文本的向量表示z,其维度为2ur。
3.2 Mixup 层
本文基于Mixup 方法,在文本的向量空间中混合样本。混合过程是先随机选取一个样本,然后将同批次的样本随机打乱后抽取另一个样本,对2 个样本(zi,yi)和(zj,yj)进行插值。抽取过程均为不放回抽取。样本混合因子λ由式(5)和式(6)得到:

在训练的过程中,Mixup 层通过随机混合批次内的文本向量表示得到扩增的文本向量表示,其中M表示一个批次的样本数据量。
3.3 分类层
混合样本通过一个全连接层和softmax 激活函数,得到分类标签的预估概率值:

其中:W∈RC×2ur和b∈RC分别是权重矩阵和偏置。
4 实验结果与分析
4.1 实验数据
由于目前中文医疗社交媒体没有公开可用的药物不良反应检测数据集,因此本文从好大夫网站收集用户的诊疗记录。如图3 所示,每个诊疗记录包含患者的信息、病情描述、医生诊疗建议等内容。

图3 诊疗记录样例Fig.3 Sample of treatment record
本文选取80 余种常用药作为研究内容,其中包含降压药、抗过敏药、抗生素等,获取了网站2011 年以后包含相关药物的诊疗记录,并选择记录中的病情描述内容作为本文的原始语料。最终共获得42 800 个文本,每个文本都提及了一种或者多种药物。通过对文本进行预处理,删除URL、英文字母、特殊字符等并去停用词。原始语料来源于中文社交媒体,需要对其进行分词。对于医疗数据,传统的jieba 分词效果并不理想,因此本文使用北京大学开源分词工具pkuseg 进行分词,调用其自带的medicine 模型将大部分的医药专业词汇分词出来。
为得到标注数据,本文从语料中选取6 000 条数据让5 名药学专业学生进行人工标注,设定分类标签y∈{0,1}。当不同人员之间存在争议,同一数据的标注结果不一致时,以多数人的结果为准。标注样例如表1所示。最终得到包含ADR 的数据有2 379 条,不包含ADR 的数据有3 621 条,并从中随机选择4 800 条作为训练集,1 200 条作为测试集。

表1 标注数据样例Table 1 Samples of labeled data
4.2 参数设置
本文采用Pytorch 实现所提模型和算法,将文本的最大词序列长度设为256。ERNIE 预训练模型包含12 个Encoder 层,多头注意力机制的头数为12,隐藏层维度为768。将BiLSTM 层的隐藏状态维度u设为300,Attention 层自注意力机制的参数r设为24,注意力层隐藏状态维度da设为128。未标注数据的增强次数K对于伪标签的影响较大,参照文献[21],设置K=2,即对于每个未标注数据执行2 次数据增强。将Beta 分布中的α设置为0.4,当α较小时,Beta(α,α)采样得到的值大部分落在0 或1 附近,使样本混合因子λ接近1,从而在合成样本时偏向某一个样本创建出相似的数据。
模型采用Adam 梯度下降算法训练,初始学习率设为0.001,β1=0.9,β2=0.999,ε=1×10-8,batchsize=64。训练过程采用提前停止策略,若模型性能在5 个epoch 后仍然没有提升,则停止训练。
4.3 实验对比
4.3.1 ADR 检测模型的对比实验
本文选择了如下6 种基于深度学习的ADR 检测模型进行对比实验:
1)CNN[11]模型:采用不同尺度的卷积神经网络构建文本分类器。分别设置滤波器宽度为2、3、4、5,每个滤波器的大小均为25。
2)CNN+Att[11]模型:在CNN 网络最上层加入注意力机制。
3)BiL+Att[12]模型:采用BiLSTM 作为编码器,加入注意力机制。
4)ERNIE[20]模型:采用百度开源的ERNIE 中文预训练模型作为编码器,得到文本表示,直接连接一个全连接层实现文本分类。
5)ERNIE+BiL+Att 模型:基于BiL+Att 模型,使用ERNIE 模型得到词向量表示。
6)ERNIE+BiL+Att+S-Mixup模型:在ERNIE+BiL+Att 模型的编码层之上加Mixup 层。对标注数据进行文本增强,即有监督的Mixup(Supervised Mixup,S-Mixup)。
选取4 800 条标注数据训练模型,使用精确率、召回率和F1 值作为评价指标。实验结果如表2 所示。
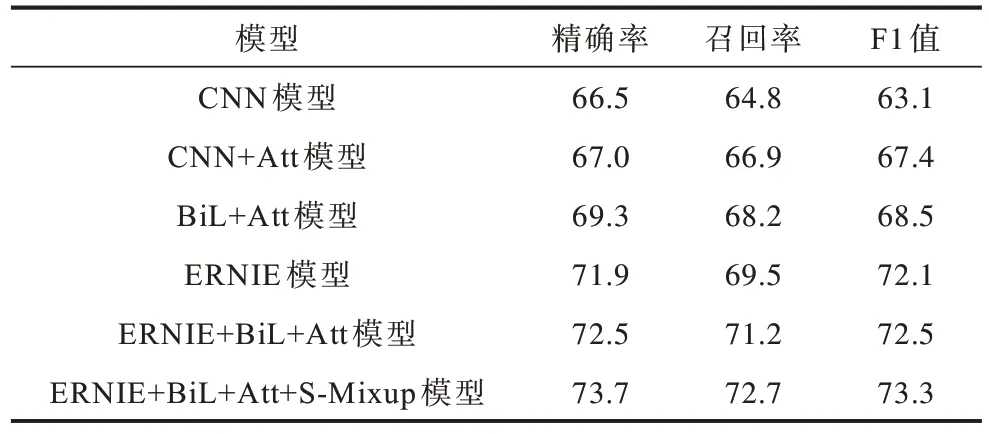
表2 不同ADR 检测模型的实验结果Table 2 Experimental results of different ADR detection models %
由表2 可知,CNN 模型的效果最差,而采用BiLSTM 获取上下文信息,并引入注意力机制获取文本的重要特征,能提高模型效果。对比BiL+Att 和ERNIE+BiL+Att 模型,利用ERNIE 预训练模型得到的动态词向量更符合语义环境,模型的性能也能得到有效提升。
本文对ERNIE 预训练模型进行微调,实验效果显著,说明了预训练模型在ADR 检测任务中能达到较好的分类效果。然而对比ERNIE 与ERNIE+BiL+Att 模型,后者的实验效果仍有小幅度提升,体现了ERNIE+BiL+Att 模型的优势。
由表2 还可以看出,ERNIE+BiL+Att+S-Mixup 模型的精确率、召回率和F1 值均优于其他模型。这是因为神经网络的训练通常需要大量的标注数据,而当标注数据有限时,效果往往不太理想。ERNIE+BiL+Att+S-Mixup 模型引入Mixup,通过对标注数据进行文本增强,在一定程度上增加了训练样本的数量,从而使ADR检测模型的性能得到明显的提升。
4.3.2 半监督模型的对比实验
本文选取了如下5 种半监督模型进行对比实验:
1)ERNIE+BiL+Att+S-Mixup 模型:仅使用标注数据。
2)Pseudo-Label[22]模型:先使用标注数据训练模型,将未标注数据经过分类模型后得到的预测值作为伪标签,使用带有伪标签的数据和标注数据一起训练模型。
3)Π-Model[23]模型:对于同一数据的输入,使用不同的正则化进行2 次预测,通过减小2 次预测的差异,提升模型在不同扰动下的一致性。
4)Mean Teachers[24]模型:使用时序组合模型,对模型参数进行EMA 平均,将平均模型作为teacher预测人工标签,由当前模型预测。
5)ERNIE+BiL+Att+SS-Mixup 模型:即本文模型。先对未标注数据进行多次增强,将预测值加权平均作为低熵标签,并共享原始样本和增强样本。使用标注数据、未标注数据和增强数据一起对模型进行训练,即半监督的Mixup(Semi-Supervised Mixup,SS-Mixup)。
从训练集中选取不同数量的标注数据和5 000 条未标注数据。使用准确率(Accuracy,Acc)作为评价指标,实验结果如表3 所示。
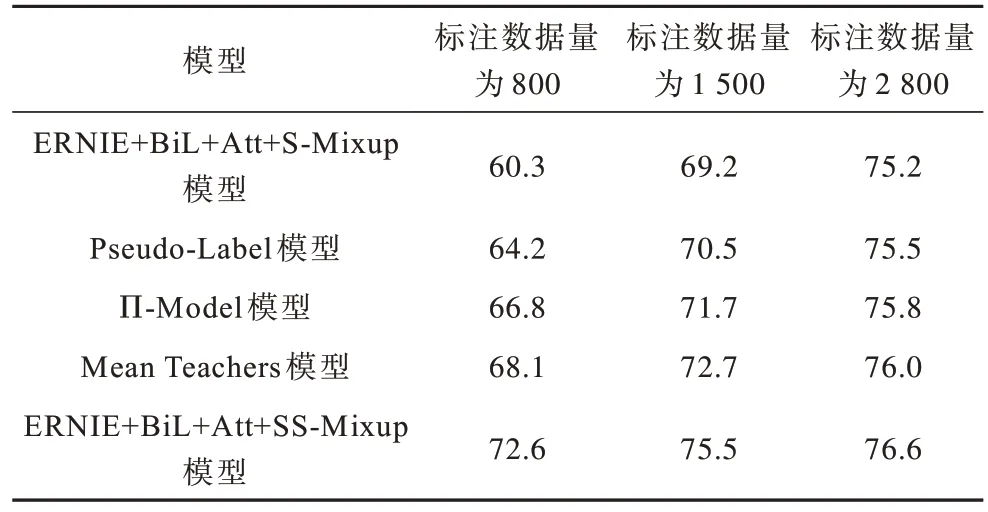
表3 不同半监督模型的Acc 值对比Table 3 Acc value comparison of different semisupervised models %
由表3可知,与传统的半监督模型相比,本文模型在不同标注数据量的情况下,准确率均最高。当标注数据的数量较少时,准确率增长幅度尤其突出。随着标注数据的增加,本文模型带来的额外提升效果会逐渐降低。从表3中还可以看出,当标注数据量为1 500条时,本文模型与ERNIE+BiL+Att+S-Mixup模型在2 800条标注数据时的表现相近。即通过本文对未标注数据的半监督学习,相当于免费获得了近一倍的额外标注数据。说明本文模型有效利用了未标注数据的信息,缓解了标注数据量不足的影响。同时,本文模型对未标注数据有较好的标签预测能力。
4.3.3 不同未标注数据量的对比实验
为进一步对比未标注数据量对本文模型的影响,从训练集中挑选了800 条标注数据和不同数量的未标注数据。实验结果如表4 所示。
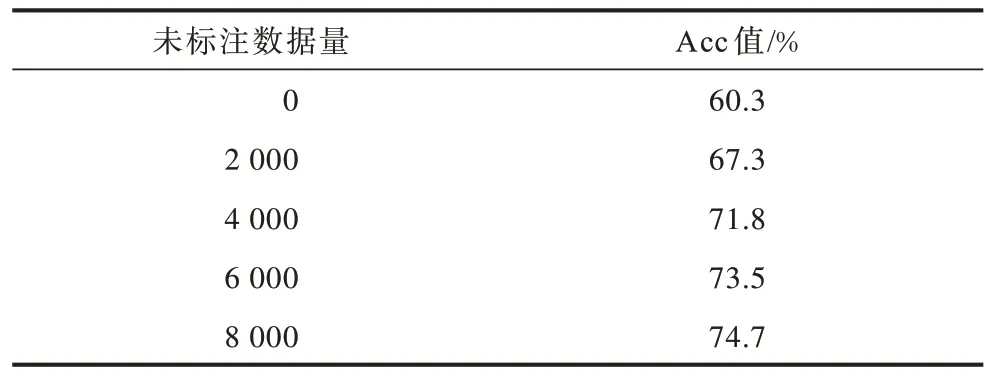
表4 不同未标注数据量的Acc 结果Table 4 Acc results of different unmarked data quantities
由表4 可知,当标注数据量一定时,未标注数据的数量越多,本文模型的预测结果越准确,表明本文模型能够有效利用未标注数据的信息,帮助模型提升性能。
5 结束语
本文面向中文医疗社交媒体提出一种融合数据增强与半监督学习的ADR 检测方法。通过利用回译的文本增强技术对未标注数据进行多次增强,并在模型的编码层和分类层之间加入Mixup 层,对混合样本的文本向量采取插值操作以扩充样本数量。此外,通过半监督学习训练分类模型,充分利用标注数据与未标注数据。实验结果表明,本文方法充分利用未标注数据解决了标注数据不足的问题。当标注数据量较少时,模型的准确率提升幅度尤其突出,且随着未标注数据量的增加,模型性能得到提升。下一步将研究文本中药物和不良反应的关系,通过辨别文本中出现的ADR信息是否已知,从而挖掘潜在的ADR 信息,提升本文模型的性能。
