融合自适应感受野与多支路特征的鞋型识别算法
2022-06-16张家钧唐云祁杨智雄
张家钧,唐云祁,杨智雄
(中国人民公安大学侦查学院,北京 100032)
0 概述
通过作案人遗留在犯罪现场的嫌疑鞋印推断嫌疑鞋型,进而在监控视频中追踪犯罪嫌疑人已经成为公安机关侦破案件的重要技战法。随着监控摄像头的普及,该技战法在侦查破案中具有重要作用。文献[1]介绍2016 年某超市内发生的一起命案,现场唯一有价值的物证是数枚来自同一人的带血鞋印。在该案件中,侦查人员通过特征标示、拼接比较、重合比较等方法确定监控视频中一男子所穿鞋型与案发现场鞋型为同类鞋型,在监控视频中成功锁定犯罪嫌疑人,实现了从案发现场遗留鞋印到监控的跨模态追踪溯源。
“鞋印+监控”技战法虽然有较强的实战价值,但是在监控视频中比对嫌疑鞋型的工作全部由人工完成。我国警力尚处于不足的状态,无法确保在规定时间内精准搜索到犯罪嫌疑人。因此,一种面向监控视频的鞋型自动识别算法成为研究热点。相比人脸识别问题,面向监控视频的鞋型识别问题更复杂,其原因为受运动、光照、分辨率较低等因素的影响,在监控视频中的鞋子区域大多是模糊不清的,导致可利用有效特征较少。因此,通过提取低分辨率鞋子影像有效特征进行鞋型自动识别是现阶段亟须解决的难题。
针对上述问题,本文提出一种基于自适应感受野模块与多支路特征融合的鞋型识别算法。通过构建自适应感受野模块(Adaptive Receptive Field Module,ARFM),在模块末端连接通道注意力机制,使网络自动选择合适大小的感受野特征,设计三支路特征融合模型,充分利用有效特征进行鞋型识别,采用Center Loss[2]和标签平滑损失[3]联合函数对网络进行训练,使样本实现更好的聚类效果。
1 相关工作
基于内容的图像检索(Content-Based Image Retrieval,CBIR)是计算机视觉领域的研究热点。在深度学习发展之前,CBIR 主要基于手工标注的特征,如尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)[4],因手工特征描述受限,导致检索效率较低。自深度学习得到迅速发展之后,特别是AlexNet[5]、VGGNet[6]、GoogLeNet[7]、ResNet[8]、DenseNet[9]等深度卷积神经网络的出现,得益于其强大的特征提取能力,深度学习广泛应用在图像分类、目标检测[10]、图像检索[11]等领域。
文献[12]提出全连接层具有较强的语义特征描述能力,并且其本身是向量形式,因此在早期工作中,直接选择全连接层作为图像的表示向量,但是仅选择一层全连接层会限制网络的检索性能。因此,文献[13]提出融合多层全连接层特征进行图像检索,取得更优的检索结果。文献[14]对GoogLeNet的3 组inception 结构进行平均池化、1×1 卷积和全连接层操作,并将这3 组提取到的1 024 维特征进行拼接,并对得到3 072 维特征向量进行检索,其检索结果优于传统的特征提取算法。文献[15]指出,全连接层对图像分类的贡献突出,但是缺乏图像细节特征和局部几何不变特性,对图像的尺寸、位置等变化较敏感。因此,研究人员将卷积层的输出作为图像特征表示向量,卷积层中神经元仅连接特征图中的部分区域并且参数共享,具有对图像几何变换的有效性。将卷积层的输出作为图像特征表示向量需要选择合适的卷积特征聚合方法,如SPoC[16]、CroW[17]、R-MAC[18]、SCDA[19]、PWA[20]、GEM[21]等方法。文献[22]基于CroW 和SCDA 方法提出深度卷积特征聚合(DFW)方法,综合考虑深度卷积特征的位置、区域和通道的重要性,并对特征进行加权聚合,以获得更优的检索效果。文献[23]基于CroW 方法提出一种新的空间和通道特征加权聚合方法,生成差异性加权向量,并对权重矩阵进行滤波处理,具有较优的检索结果。
文献[24]提出在卷积神经网络中每层提取的特征具有层次性,低层特征主要包含纹理、边缘等细节特征,随着层数的加深,网络感受野逐渐增大,高层特征主要包含高级语义特征。基于此,文献[25]融合低层细节特征和高层语义特征,提高网络检索性能。文献[26]提出融合全局特征和局部特征的两阶段的图像检索方法,利用全局特征进行检索得到top30 结果,采用局部特征进行重新检索排序,在Google Landmarks dataset v2 数据集上达到最高的检索精度。文献[15]提出多层特征融合的检索精度相比于单独使用低层特征或者高层特征的检索精度高。文献[27]提出一种三支路特征层融合的模型,使网络充分利用有效特征进行行人重识别,实验结果表明,多层特征融合模型具有更优的检索性能。针对传统神经网络在学习目标高层语义特征时存在目标边缘、纹理等浅层特征丢失的问题,文献[28]采用Haar-like 提取目标边缘、纹理特征,同时利用Adaboost 进行特征降维,以提取目标的边缘、纹理浅层特征,将目标浅层特征与神经网络提取的深层特征相融合,能够有效提升检测精度。文献[29]通过Gabor 滤波器获取目标不同方位的特征,利用MS-CLBP 获取目标的局部纹理、空间和轮廓信息,并将浅层特征与神经网络学习到的高层语义特征相融合输入到SVM 分类器中,得到优于当时最先进方法的分类精度。
针对监控视频中行人所穿鞋型自动识别研究较少的问题,本文将深度学习运用到鞋型识别工作中,不仅取代人工盯查监控工作,大幅加快鞋型匹配速度,还可以避免人工盯查监控时受主观因素的影响,提升公安机关侦破案件的效率。
2 本文算法
2.1 自适应感受野
感受野是指神经网络中每层输出特征图的像素点在原始图像上映射的区域大小,网络感受野越大表示其接触到原图像范围越大,所包含的特征信息更加全面。增大感受野的主要方式是增加网络深度和采用下采样操作,在深度学习初期,网络层数越深,训练得到的模型效果越好,但是通过池化层增大网络感受野的弊端是随着图像分辨率的降低,图像的细节信息也会随之丢失。因此,本文提出一种自适应感受野模块,其骨干网络采用ResNet50,模块结构如图1 所示。
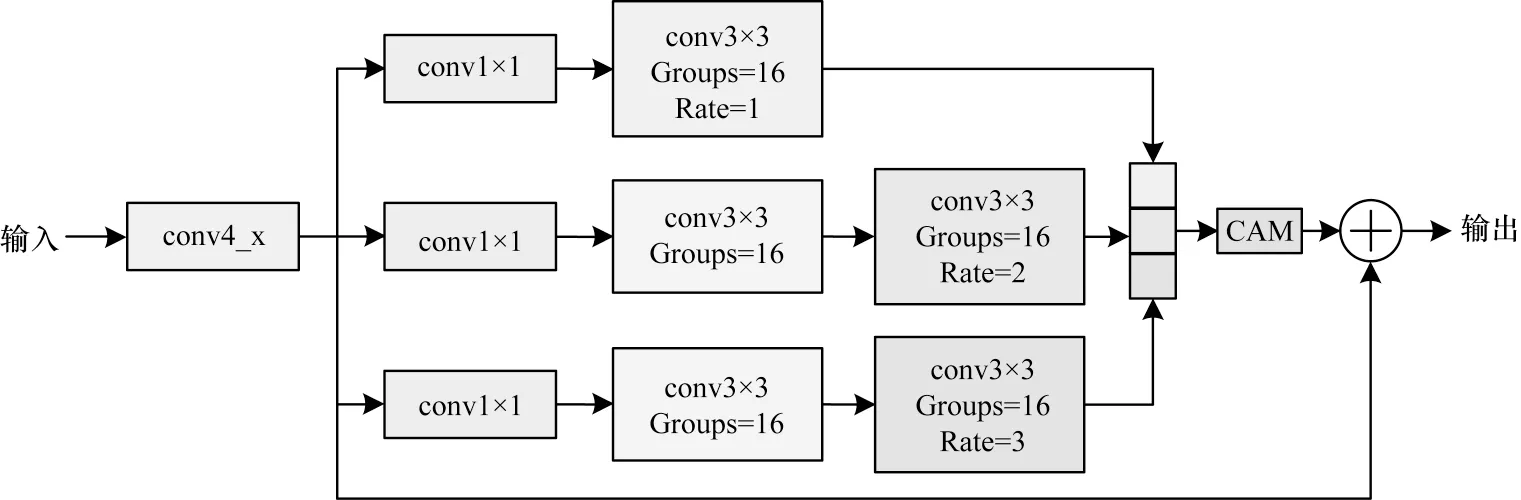
图1 自适应感受野模块Fig.1 Adaptive receptive field module
为获得不同大小的网络感受野,本文设计3 条卷积支路,每条支路采用不同空洞率的空洞卷积[30]。本文在3×3 卷积层中采用分组卷积[31],Groups 设置为16,减少模块参数量,使自适应感受野模块轻量化,在模块末端连接通道注意力机制[32],实现自适应选择合适大小的感受野特征[33],从而提升鞋型识别性能。图2 为引入自适应感受野模块之后的网络架构。
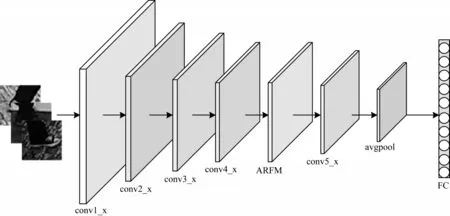
图2 本文网络架构Fig.2 Architecture of the proposed network
2.1.1 空洞卷积
空洞卷积是指在传统卷积的基础上增加零填充,通过设置不同的膨胀率,在不增加额外参数的情况下扩大网络感受野。感受野的计算如式(1)所示:
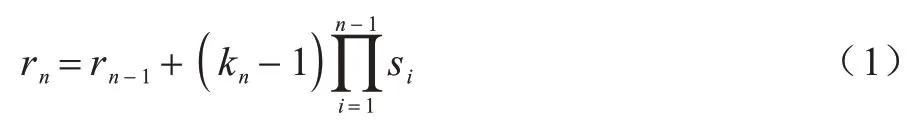
其中:rn为该层网络感受野大小;rn-1为前层网络感受野大小;kn为该层卷积核大小;si为i层步长。
不同膨胀率的空洞卷积示意图如图3 所示,图3(a)为传统的标准卷积操作,感受野大小为3×3。图3(b)表示空洞卷积的膨胀率大小为2,通过增加零填充,此时感受野大小为5×5。空洞卷积在不增加额外计算量的同时仅使用不同的膨胀率获得不同大小的感受野,以捕获更加全面的特征信息。
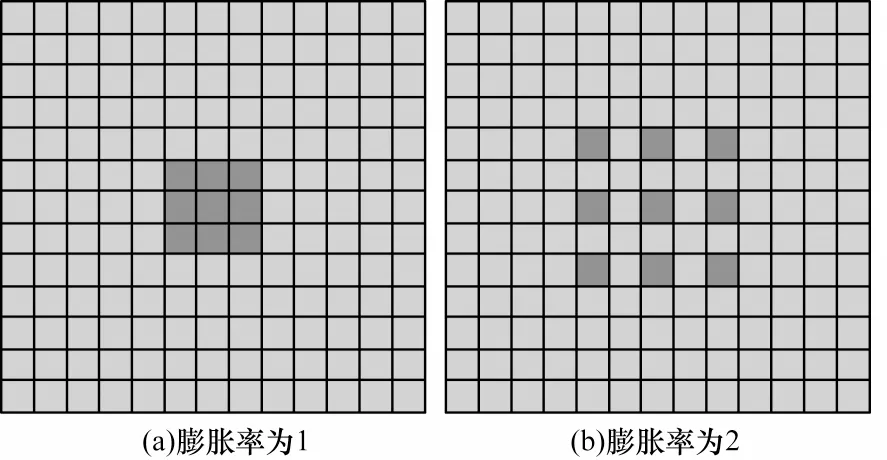
图3 不同膨胀率的空洞卷积示意图Fig.3 Schematic diagram of cavity convolution with different dilation rates
空洞卷积卷积核的计算如式(2)所示:
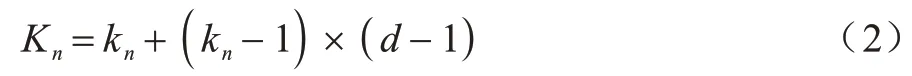
其中:Kn为空洞卷积卷积核大小;kn为真实卷积核大小;d为空洞卷积使用的膨胀率参数。
2.1.2 分组卷积
本文在3×3 卷积层中采用分组卷积减少参数量,使自适应感受野模块更加轻量化。分组卷积首先对输入的特征图进行分组,在每组特征图中再进行卷积操作。假设某层输入特征图的通道数、宽、高、输出通道数分别为C、W、H、K,采用传统标准卷积方式的参数量P1如式(3)所示:

分组卷积将传统标准卷积分为G组,其参数量P2为,如式(4)所示:

2.1.3 通道注意力机制
注意力机制使得网络自适应选择对当前任务更关键的特征信息。在本文提出的自适应感受野模块中,3 条支路分别代表不同大小的感受野特征。本文在模块末端连接通道注意力机制,使每条支路具有不同重要性的权重,从而实现网络自适应选择合适大小感受野特征的目的。通道注意力机制模型如图4 所示。
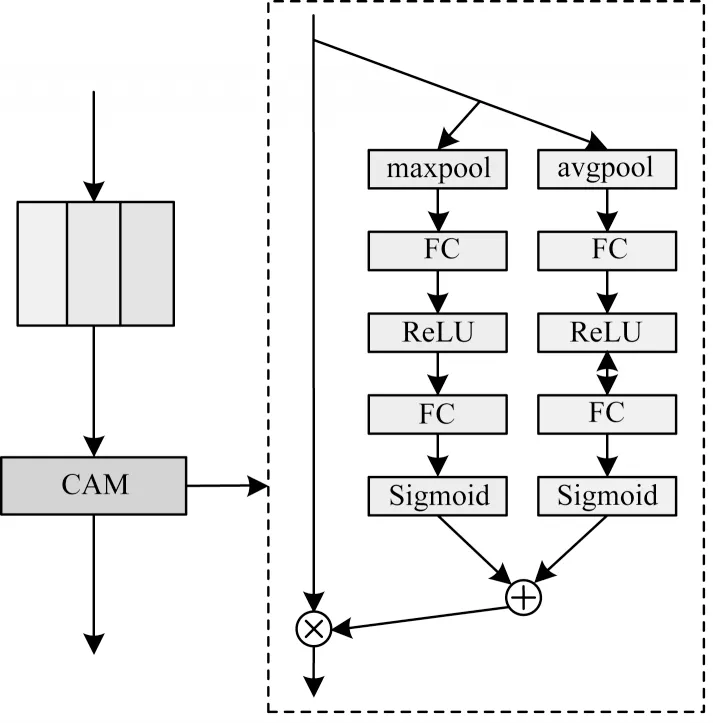
图4 通道注意力机制模型Fig.4 Channel attention mechanism module
首先对输入特征进行压缩,即通过平均池化和最大池化整合各通道的信息,之后通过两层全连接层建模通道间的相关性,获取每条支路的重要性权重,通过Sigmoid 激活函数获取0~1 之间的归一化权重,将两条支路的归一化权重系数相加后加权到各通道特征中,实现网络自适应选择合适大小的感受野特征。注意力权重系数Q如式(5)所示:
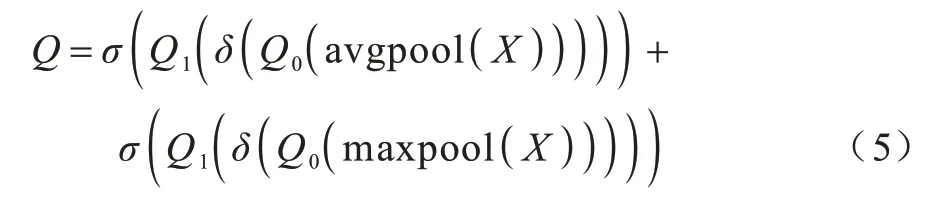
其中:X∈Rc×h×w为上层输出特征;Q0∈、Q1∈Rc×1×1分别为经过第1 层和第2 层FC 层的特征;δ为ReLU 激活函数;σ为Sigmoid 激活函数。
2.2 实例与批量标准化
批量标准化(Batch Normalization,BN)[34]是卷积神经网络中数据归一化常用的方法,BN 对输入每批次的数据进行归一化处理,使每层的输出归一化至均值为0 和方差为1 的分布,确保数据分布的一致性。实例标准化(Instance Normalization,IN)与BN相反,IN 仅作用于单张图片,通过对单张图片的所有像素求均值和标准差,可以降低场景迁移(如背景、光照等变化)时对识别效果产生的影响。本文使用多背景数据集,且光照、角度等条件均不同,利用IN减少外观差异产生的影响,但是IN 在减小同类个体差异的同时也会损失一些有效特征信息。BN 保留较多区分不同个体的特征信息,但是该特征信息受外观影响较大。因此,结合IN 和BN 两者的优点,本文采用文献[35]提出的IBN-Net,一半通道使用IN,剩余通道使用BN。在卷积神经网络中,由外观因素带来的特征差异主要存在于低层中,高层受外观差异产生的影响较小。本文在conv2_x 中每组卷积块的第1 层卷积层之后使用IBN 结构,增强网络识别能力。实例与批量标准化结构如图5 所示。
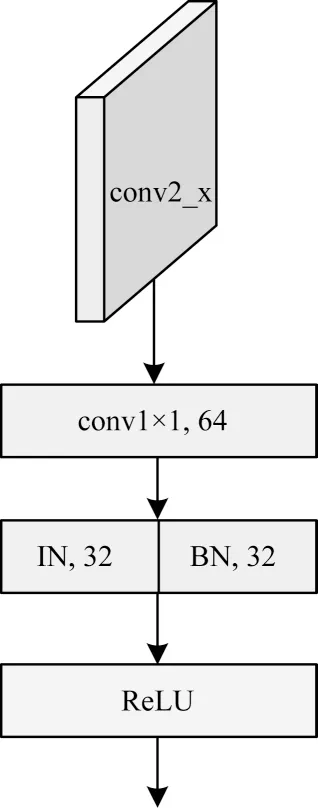
图5 实例与批量标准化结构Fig.5 Structure of instance and batch normalization
2.3 多支路特征融合模型
本文提出的多支路特征融合模型能够充分利用浅层特征和深层特征,通过特征融合方式弥补神经网络无法充分利用有效特征进行识别的不足。在卷积神经网络中,卷积层提取的特征各不相同,浅层特征一般是纹理、边缘等细节特征信息,深层特征通常是高级语义特征。深层特征虽然具有语义表达能力,但是如果网络单独使用深层特征会损失图像细节信息,从而影响鞋型识别性能。本文选择ResNet50 网络中的conv2_x、conv3_x、conv5_x 这3 个模块的输出特征,以充分利用有效特征,以conv5_x 输出特征为主,conv2_x、conv3_x 输出特征为辅进行特征融合,舍弃conv4_x 模块的原因是conv4_x 的语义特征没有conv5_x 模块明显,其细节等特征信息没有conv2_x 和conv3_x 模块显著。首先Branch 1 引出conv2_x 模块的输出,获得与conv5_x 相同大小的输出特征图,经过全局平均池化得到大小为4×4×256 的特征FBranch1;同理,Branch 2 将conv3_x 模块的输出引出,经过全局平均池化得到大小为4×4×512 的特征FBranch2;Branch 3 直接将conv5_x 的输出引出,得到大小为4×4×2 048 的特征FBranch3。将经过统一尺寸的特征FBranch1、FBranch2、FBranch3融合之后得到大小为4×4×2 816 的特征F。本文在特征F之后加入降维模块(Dimensionality Reduction Module,DRM),以降低维度和增加特征F的非线性特性,从而增强网络表达能力。多支路特征融合模型如图6 所示。
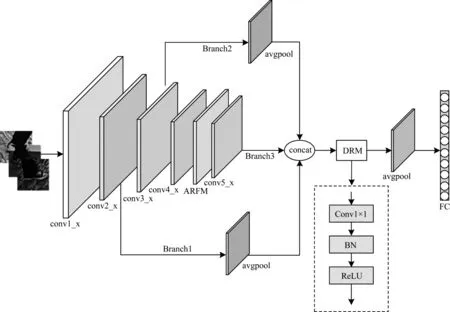
图6 多支路特征融合模型Fig.6 Multi-branch feature fusion model
2.4 损失函数
本文数据集中鞋类较多,且相似度较高,在训练过程中存在类间差距不明显、类内差距较大等问题。因此,在增大类间差距的同时缩小类内差距,提高模型的识别精度,使样本达到更好的聚类效果。
传统的Softmax 损失函数将整个空间按照类别个数进行划分,在分类任务中具有较优的效果,但是Softmax 函数并没有强调类间分离和类内紧凑。基于此,本文提出联合Center Loss 训练的方法。Center Loss 作为一种辅助训练损失函数,能够有效缩小类内差距并保持类间差异,Center Loss 函数如式(6)所示:

其中:m为批次大小;xi为全连接层之前的特征;为第yi个类别的特征中心。本文在Softmax 损失函数中加入LS(Label Smoothing),通过在输出中引入噪声,降低网络训练过拟合现象的发生及网络对真实标签的依赖性,以提高模型的泛化能力。本文最终采用的损失函数L如式(7)所示:

其中:LLabel为加入Label Smoothing 的Softmax 损失函数;Lc为Center Loss 函数;λ为Center Loss 函数的权重,本文λ取值0.000 1。
3 实验与结果分析
3.1 实验设置
本文实验操作系统为Linux 3.10.0,是基于PyTorch 深度学习框架展开的算法研究。CPU 为Intel®Xeon®CPU E5-2650 v4 2.20 GHz,显卡设置为NVIDIA TITAN X(Pascal),显存12 GHz,深度学习平台为PyTorch1.2.0,编译环境为Python3.5.6。输入图像尺寸为120×120 像素,采用随机裁剪、水平翻转方式进行数据增强处理,采用Adam 作为优化器,初始学习率设置为0.000 1。
3.2 数据集
为验证本文方法的有效性,本文在构建的多背景数据集上进行测试。数据集是由3 个不同视角的监控摄像头在中国人民公安大学足迹实验室采集的图像,300 类鞋共35 300 张低分辨率鞋子图像。鞋子图像由人工手动标注完成,训练集包含150 双鞋30 000 张鞋子图像。测试集包含150 双鞋300 张鞋子图像。鞋样数据库包含5 000 张混淆样本和300 张样本鞋子图像。多背景数据集的部分数据样式如图7 所示。

图7 多背景数据集的部分数据Fig.7 Partial data of multi-background datasets
3.3 评价指标
为评估模型性能,本文将均值平均精度(mean Average Precision,mAP)和Rank-1 作为评价指标。Rank-1 反映识别排序结果第一位的匹配正确率;mAP 反映模型的整体性能,如下:

其中:TTP为预测正确的正样本数;FFP为预测错误的正样本数;N为类别总数。
3.4 实验结果分析
3.4.1 自适应感受野模块对识别精度的影响
为验证自适应感受野模块(ARFM)对网络识别精度的影响,在多背景鞋子数据集上,本文将对引入自适应感受野模块的ResNet50 网络进行测试,实验结果如表1 所示。

表1 分组卷积和标准卷积对识别精度的影响Table 1 Influence of group convolution and standard convolution on recognition accuracy %
从表1 可以看出,自适应感受野模块能够有效提高网络识别性能,本文采用标准卷积的精度相比于分组卷积的精度略微下降,在ResNet50 网络中加入ARFM 之后,相比ResNet50,ResNet50+ARFM(分组卷积)的Rank-1 和mAP 精度分别提高2.34 和0.88 个百分点,能够有效提高识别精度。ARFM 在不降低目标分辨率的同时,使网络自适应选择合适大小的感受野特征进行学习,从而提高鞋型识别精度,实验结果充分验证自适应感受野模块的有效性。
分组卷积和标准卷积对网络复杂性的影响如表2 所示。本文将ARFM 模块中的分组卷积替换成标准卷积。从表2 可以看出,相比ResNet50,当使用标准卷积时,自适应感受野模块参数量增大8.66×106,且网络浮点运算量增加了0.61×109;当使用分组卷积时,自适应感受野模块参数量仅增大了2.14×106,浮点运算量增大0.2×109。实验结果表明,在自适应感受野模块中采用分组卷积能够大幅降低参数量和运算量,从而提升网络训练效率。

表2 分组卷积和标准卷积对网络复杂性的影响Table 2 Influence of group convolution and standard convolution on network complexity
3.4.2 实例与批量标准化对识别精度的影响
在多背景鞋子数据集上,本文对加入实例与批量标准化IBN 的ResNet50 网络进行测试,自适应感受野模块与IBN 整体对网络识别精度的影响如表3所示。
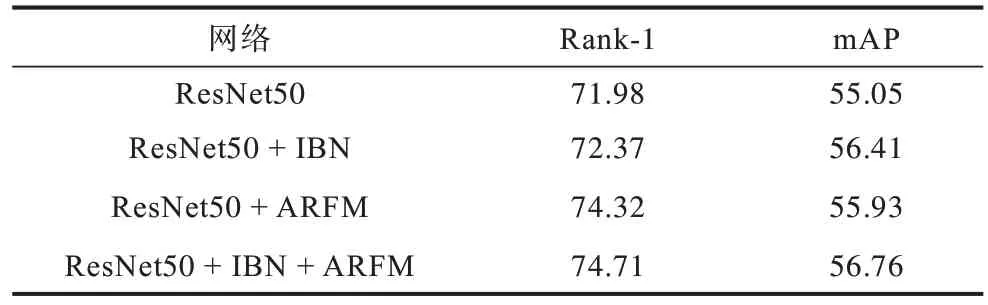
表3 IBN 和自适应感受野模块对识别精度的影响Table 3 Influence of instance and batch normalization and adaptive receptive field module on recognition accuracy %
从表3 可以看出,相比ResNet50 网络,在ResNet50 网络中加入IBN 的Rank-1 和mAP 精度分别提高了0.39 和1.36 个百分点,在ResNet50 网络中同时使用IBN 和ARFM,Rank-1 和mAP 精度分别提高2.73 和1.71 个百分点。因此,IBN 能够有效缩小目标差异,在ResNet50 网络conv2_x 中,每组卷积块的第一层卷积层之后使用IBN 结构,能够提高网络的识别能力,并验证IBN 结构的有效性。
3.4.3 多支路特征融合模型对识别精度的影响
本文算法是在IBN 和ARFM 的ResNet50 网络基线上引入Branch 1+Branch 2+Branch 3 融合特征进行识别。为验证多支路特征融合模型的有效性,本文按照相同的融合方式测试Branch 1+Branch 3、Branch 2+Branch 3、Branch 4+Branch 3、Branch 2+Branch 4+Branch 3、Branch 1+Branch 4+Branch 3、Branch 1+Branch 2+Branch 3这6种方法的识别精度,其中Branch 4是conv4_x 引出的分支。多支路特征融合模型的精度对比如表4所示。多支路特征融合模型的Rank-1、Rank-5、Rank-10 对比如图8 所示。
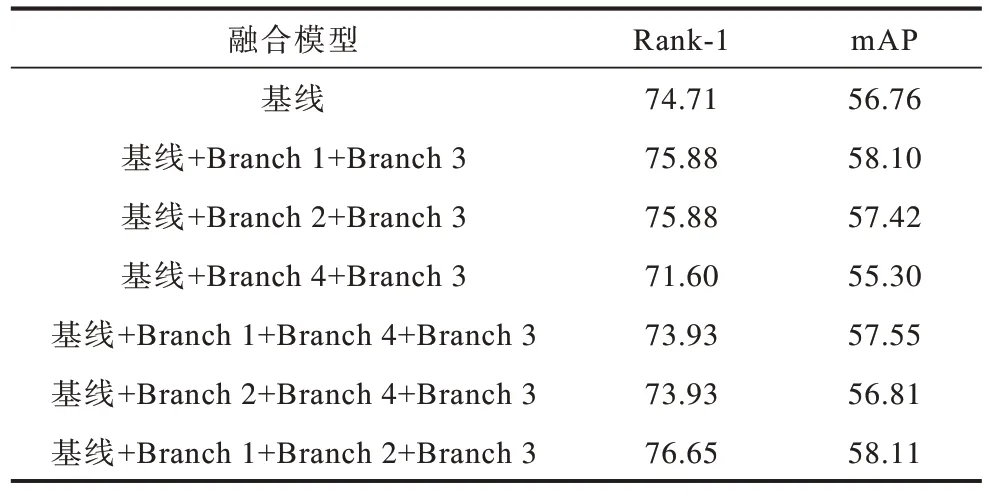
表4 多支路特征融合模型的精度对比Table 4 Accuracy comparison among multi-branch feature fusion models %
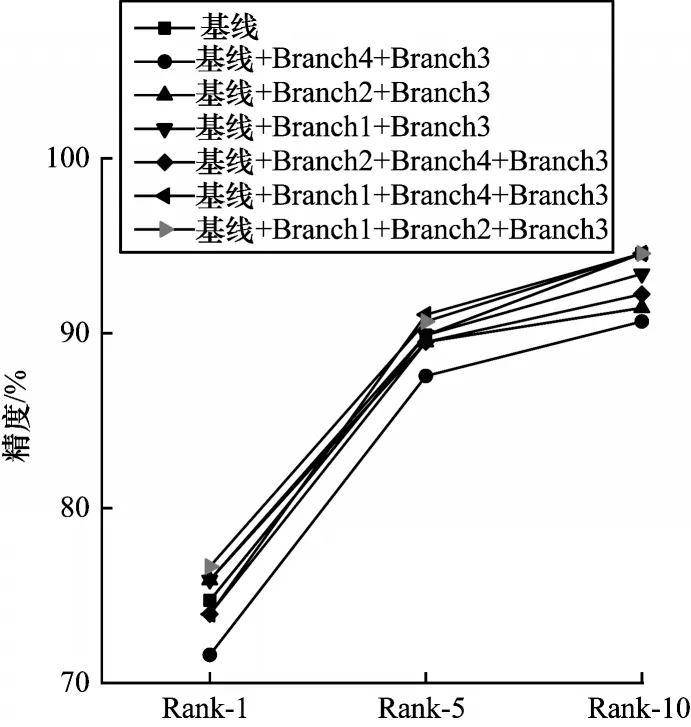
图8 多支路特征融合模型的Rank-1、Rank-5、Rank-10 对比Fig.8 Rank-1,Rank-5,Rank-10 comparison among multi-branch feature fusion models
从表4 和图8 可以看出,多支路特征融合模型对网络识别性能的提升具有显著效果,在加入IBN 和ARFM 的ResNet50 基线上,将Branch 1、Branch 2 和Branch 3 特征融合之后Rank-1 精度相比基线提高了1.94 个百分点,mAP 精度提高1.35 个百分点,识别精度具有显著提升。在卷积神经网络中,单独使用深层高级语义特征会丢失图像细节信息,从而影响鞋型识别性能,将神经网络中浅层纹理、边缘等细节特征与深层高级语义特征相融合,使得网络利用鲁棒性较优的鞋型特征进行鞋型识别,从而提升识别精度,进一步验证本文特征融合模型的有效性。
3.4.4 损失函数对识别精度的影响
在多背景鞋子数据集上,本文验证Center Loss函数和LS(Label Smoothing)函数对识别精度的影响,实验结果如表5 所示。本文算法加入Center Loss函数和LS 函数的Rank-1 和mAP 分别为78.21%和60.98%。在Softmax 损失函数的基础上,本文联合Center Loss 函数训练网络在增大类间距离的同时缩小类内差距,使样本实现更优的聚类效果;在Softmax 损失函数中加入LS 函数能够有效增强模型泛化性能,避免出现训练过拟合现象,提高鞋型识别精度。

表5 损失函数对识别精度的影响Table 5 Influence of loss function on recognition accuracy %
Re-ranking 是图像检索领域常用的测试技巧,通过对检索结果重新排序,提升模型识别性能。本文在测试最终模型性能时加入Re-ranking,实验结果如表6 所示。

表6 Re-ranking 测试实验结果Table 6 Experimental results of Re-ranking test %
从表6 可以看出,本文算法具有较优的识别性能,引入Re-ranking 的Rank-1 和mAP 精度分别达到79.77%和62.18%,相比ResNet50 基础网络,其Rank-1和mAP 精度分别提高7.79 和7.13 个百分点。
3.4.5 结果可视化
为更加直接展现ARFM、特征融合的有效性,本文在ResNet50、ARFM、特征融合模型上进行部分数据测试,并对Rank-5 结果进行可视化,左侧图像是待查询图像,右侧5 张图像是从库中返回的查询结果。其中带有√标志的代表正确的查询结果。不同算法的识别结果如图9 所示。从图9 可以看出,原始ResNet50 网络识别效果较差,错误结果较多,但是在ResNet50 网络基础上融合ARFM 和多层特征后,其识别效果显著提升,同时验证了本文提出的自适应感受野模块和多层特征融合模型的有效性。

图9 不同算法的识别结果Fig.9 Recognition results comparison among different algorithms
4 结束语
本文提出基于自适应感受野与多支路特征融合的鞋型识别算法。设计一种轻量级自适应感受野模块,实现自适应选择合适大小感受野特征,提升识别精度,同时融合神经网络浅层特征和深层特征,在Softmax 损失函数中加入Label Smoothing 并联合Center Loss 函数对网络进行训练。实验结果表明,本文算法具有较高的识别精度和较强的实用性。在公安实战中,受监控摄像头分辨率、天气等因素的影响,鞋子影像存在极度模糊和色彩、亮度发生变化的情况。因此,下一步将对数据集进行研究,探究超分辨率重建、数据增强等方法对鞋型识别效果的影响,使算法适用于公安实战工作。
