基于密集连接与特征增强的遥感图像检测
2022-06-16王道累杜文斌刘易腾张天宇孙嘉珺李明山
王道累,杜文斌,刘易腾,张天宇,孙嘉珺,李明山
(上海电力大学能源与机械工程学院,上海 200090)
0 概述
随着遥感技术的快速发展,高分辨率光学遥感图像以其观察面积大、范围广、不受国界和地理条件限制等特点而受到国内外学者的广泛关注。在森林防护、交通监测、电力检修、资源勘探、城建规划等领域,遥感图像检测发挥着十分重要的作用,例如,通过检测车辆目标来进行交通秩序管理,通过检测建筑房屋等目标来为城市规划提供依据,通过检测受灾房屋、道路、桥梁等目标来评估受灾情况等[1]。传统的遥感图像检测方法主要利用人工设计特征的方式提取特征信息然后训练分类器,通过滑动窗口获取图像区域,由分类器输出预测结果[2]。这种检测方法不仅消耗较多资源,检测速度与准确性往往也无法达到要求。
近年来,随着计算机硬件与人工智能技术的不断发展,基于深度学习的目标检测算法因其适用性强、检测效率高等优点而得到广泛应用。基于深度学习的目标检测算法主要分为两类:第一类为双阶段目标检测算法,以Faster R-CNN[3]、Mask R-CNN[4]等为代表;第二类为单阶段目标检测算法,以SSD[5]、YOLO[6]、YOLO9000[7]、YOLOv3[8]等为代表。目前,深度学习在遥感图像检测应用[9]中主要存在以下问题:遥感图像分辨率较高,被检目标信息少,背景噪声影响较大,使得一般的目标检测算法无法准确提取原始图像的特征信息,造成分类和定位困难;遥感图像中的目标普遍小而密集,尺寸较小的目标在网络学习过程中极易被忽略,导致网络对小目标的学习不足,降低了检测的准确率。
为解决上述问题,本文对YOLOv3 算法进行改进,建立一种基于密集连接与特征增强的目标检测模型。该模型使用改进的密集连接网络作为主干网络,同时基于Inception[10]与RFB(Receptive Field Block)[11]扩大卷积感受野,并引入特征增强模块和新型特征金字塔结构,从而增强浅层特征图语义并改善模型对小目标的检测性能。
1 基于密集连接与特征增强的检测算法
1.1 YOLOv3 算法
YOLOv3 是REDMON 等在2018 年提出的一种单阶段目标检测算法,是目前应用最广泛的目标检测算法之一[8]。YOLOv3 的检测框架如图1 所示,其主要包括2 个部分:第一部分为基础网络,采用DarkNet53,网络包含5 个残差块(ResBlock),每个残差块由多个残差结构(Residual Structure)组成;第二部分为借鉴FPN(Feature Pyramid Networks)[12]设置的特征金字塔网络结构,其通过卷积和上采样产生3 个具有丰富语义信息的特征图,大小分别为13×13、26×26、52×52。在训练阶段,网络将图像划分为N×N个网格单元,每个网格单元输出预测框的信息以及分类置信度从而完成检测。
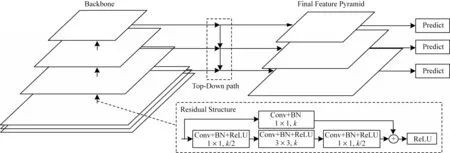
图1 原始YOLOv3 框架Fig.1 Original YOLOv3 framework
现有一些研究人员将YOLOv3 应用于遥感图像检测领域。李昕等[13]将空间变换网络(SpatialTransformer Networks,STN)融入YOLOv3 算法中,以提升遥感图像中油罐的检测精度。郑海生等[14]通过替换主干结构和激活函数将YOLOv3 的参数量缩小为原始的1/15,实现了轻量级的遥感图像检测。沈丰毅[15]在原始YOLOv3 算法中引入压缩激励结构,通过权重差异提升模型对遥感图像特征的敏感度。上述研究通过不同方法改进YOLOv3 模型,使其具有更好的表现,但是都未能很好地解决遥感图像中特征提取困难以及目标尺度小的问题,这是由于YOLOv3 对小尺度目标的检测主要依赖位于浅层的特征图,浅层特征图的分辨率较高,空间位置信息丰富,但由于其处于网络的浅层位置,没有经过足够的处理,因此语义信息较少,特征表达能力不足。此外,YOLOv3 的主干网络DarkNet53 在遥感图像中无法取得较好的表现,特征提取能力不足,导致检测效果较差。
1.2 改进的YOLOv3 算法
1.2.1 主干网络改进
本文依据DenseNet121[16]提出一种新型的密集连接主干网络,网络由阀杆模块(Stem Block)和4 个密集连接块(Dense Block)组成。阀杆模块借鉴Inception v4 和DSOD(Deeply Supervised Object Detectors)[17]的思想,结构如图2 所示,该模块可以有效提升特征表达能力,同时不会增加过多的计算成本,与DenseNet121 中的原始设计(首先是大小为7、步长为2 的卷积层,然后是大小为3、步长为2 的最大池化层)相比,多分支的处理可以大幅减少输入图像在下采样过程中的信息损失。
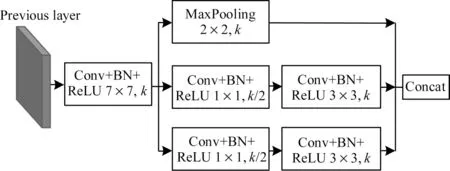
图2 阀杆模块结构Fig.2 Stem block structure
密集连接块的基本组成为密集连接结构(Dense Structure),其最显著的特点是跨通道的特征连接方式,通过每一层与前面所有层建立连接,使误差信号快速传播到较浅层,加强整个网络对特征信息的传播,在提升特征提取能力的同时大幅降低网络参数量。密集连接块的计算可表示为:其中:xl表示第l层的输出;Hl(·)表示非线性操作组合,包括BN 层、ReLU 和卷积层;δ[·]表示Concatenation 特征融合操作。

网络的输入大小为448×448 像素,在训练阶段,输入图像首先经过阀杆模块处理,通过大尺度卷积与多分支处理以缓解图像下采样时尺度变化所带来的损失,之后经过密集连接块得到4 个不同尺度的特征图,其下采样倍数分别为4、8、16、32。图3所示为DarkNet、原始DenseNet 与本文改进主干网络的结构对比,其中,原始DarkNet53 输入大小为416×416 像素,使用下采样倍数为8、16、32 的特征图预测,原始DenseNet121 作为主干网络,输入大小为224×224 像素,使用下采样倍数为8、16、32 的特征图预测,改进的密集连接网络输入大小为448×448 像素,使用下采样倍数为4、8、16、32 的特征图预测。从图3 可以看出,相较原始的DenseNet121,本文改进的主干网络的输入分辨率与预测特征图分辨率更高,并通过阀杆模块缓解了原始网络输入时信息损失过大的问题。同时,本文采用4 种预测尺度,最大尺度为112×112,最小尺度为14×14,在保证小目标检测精度的同时提升了对大尺度目标的检测效果。
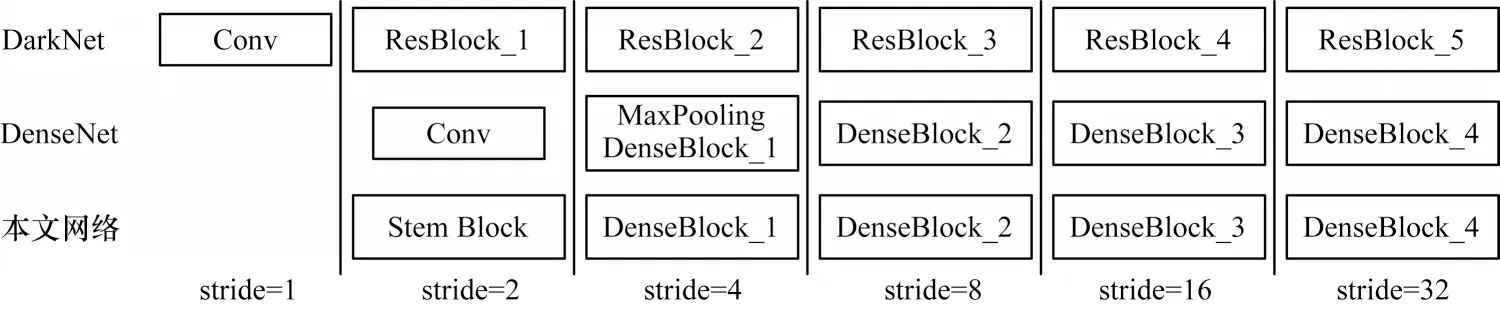
图3 3 种网络的结构对比Fig.3 Structure comparison of three networks
1.2.2 特征增强模块
在本文主干网络中,由于预测所用的特征图分辨率较大,浅层特征图没有经过充分处理可能会导致特征中的语义信息不足,因此,本文提出一种特征增强模块,针对浅层特征图语义信息少、感受野不足的问题,使用多分支处理和空洞卷积来提高浅层特征图的语义信息,从而改善网络对小尺度目标的适应能力。本文模型结构如图4 所示,提取出下采样倍数分别为4、8、16、32 的特征图用于预测,对浅层特征图(下采样倍数为4 和8)进行特征增强处理,对深层特征图(下采样倍数为16 和32)使用SPP(Spatial Pyramid Pooling)[18]进行处理,SPP 结构如图5 所示。

图4 改进的YOLOv3 框架Fig.4 Improved YOLOv3 framework

图5 SPP 结构Fig.5 SPP structure
特征增强模块借鉴RFB 感受野原理,通过增加网络的宽度与感受野来提高模型的特征提取能力,增加特征图的语义信息,其结构如图6 所示,共有4 条支路,其中1 条支路为残差网络结构中的残差支路(Shortcut Connection),只进行1×1 的卷积操作,另外3 条支路由1×1 与3×3 的卷积级联而成,并在3×3的卷积后加入不同膨胀率的空洞卷积层。多个3×3的卷积级联在扩大感受野的同时也减少了参数量,使网络的训练与推理速度更快,网络中的每个卷积层后都加入了BN 层,旨在通过数据的归一化处理来加快模型收敛。

图6 特征增强模块结构Fig.6 Structure of feature enhancement module
特征增强模块的计算可表示为:

其中:Xj表示输入特征图;P表示由1×1 卷积层、BN 层和ReLU 层组成的非线性操作组合;Hi表示进行i次由3×3 卷积层、BN 层和ReLU 层组成的非线性操作组合;Qi表示i次卷积操作后的特征图;Ri表示空洞卷积,i=1,2,3 时空洞卷积的膨胀率分别为1,3,5;Zj表示融合后的新特征图。
经过特征增强模块的处理,网络对小目标的敏感度更高,在复杂背景下依然可以准确提取小目标的特征信息,从而提升网络的检测精度。
1.2.3 特征金字塔结构
本文使用重复的自浅而深(Double Bottom-up path)的特征金字塔结构,如图4 所示,使用经特征增强模块和SPP 处理的特征图作为特征金字塔结构的输入,输入的特征图被分为2 个分支:一支在进行下采样与卷积操作后与下一层特征图相累加;另一支同样进行下采样操作并与累加后的特征相结合,使网络中的信息由浅层向深层传输。通常在网络训练过程中,目标的像素不断减小,若小目标的信息在主干网络的最后一层已经消失,则在上采样操作后无法恢复小目标的信息,在浅层特征与深层特征相结合时便会出现混淆,降低了网络的检测精度。通过本文的特征金字塔结构处理,网络不会因上采样操作而丢失小目标信息,避免了网络因小目标信息丢失所造成的精度损失。
2 实验结果与分析
2.1 实验平台与数据集
本文实验平台设置:使用Ubuntu16.04 操作系统,NVIDIA Tesla T4(16 GB 显存),Python 编程语言,深度学习框架为Tensorflow。
本文实验所用数据来自RSOD 和NWPU NHR-10[19]数据集,针对原始图像进行筛选,剔除质量较差的图片,并核验标注信息,对错标、漏标的样本进行重新标注,最终得到包括不同场景的图片共计1 620 张,检测目标包括飞机、船舶、储油罐、棒球场、网球场、篮球场、田径场、海港、桥梁和车辆,图片分辨率为(600~1 000)×(600~1 000)像素。
图7 所示为本文数据集中目标真实框的尺寸分布情况,目标真实框总共11 296 个,主要集中于小尺度范围,绝大多数目标分布在100×100 像素点以内,其中,16×16 像素大小的目标占比为41.79%,低于32×32 像素的目标占比达到约92%。

图7 目标尺度分布Fig.7 Target scale distribution
2.2 模型训练及评价指标
数据增强采用随机裁剪、随机旋转、缩放等操作,初始学习率设置为0.01,采用随机梯度下降法对总损失函数进行优化训练,训练批次设置为4。
本文使用的评价指标为平均准确率(mAP)。通过衡量预测标签框与真实标签框的交并比(IOU)得到每个类别的精确度(Precision,P)和召回率(Recall,R),由精确度和召回率所绘制的曲线面积即为准确率均值(AP),多个类别的AP 平均值即为平均准确率,其计算可表示为:

2.3 对比实验结果分析
利用所整理的数据集对本文算法性能进行验证,将其与原始YOLOv3 算法、SSD 算法、EfficientDet 算法[20]、CenterNet 算法[21]、YOLOv4 算法[22]、Faster R-CNN 算法得到的结果进行客观比较,结果如表1 所示,其中,mAPlarge、mAPmedium、mAPsmall分别代表大目标、中目标、小目标的平均准确率。从表1 可以看出,本文改进YOLOv3 算法的平均准确率高于其他算法,达到74.56%,相比原始YOLOv3 算法提高了9.45 个百分点,尤其在小尺度目标检测上,比原始算法提高了11.03 个百分点,并且参数量也低于原始YOLOv3 算法。与YOLOv4 算法相比,本文算法的大目标检测精度与其相差0.69 个百分点,但在中、小目标的检测精度上均高于YOLOv4 算法,与双阶段目标检测算法Faster R-CNN 相比,本文算法也取得了更优的检测效果。
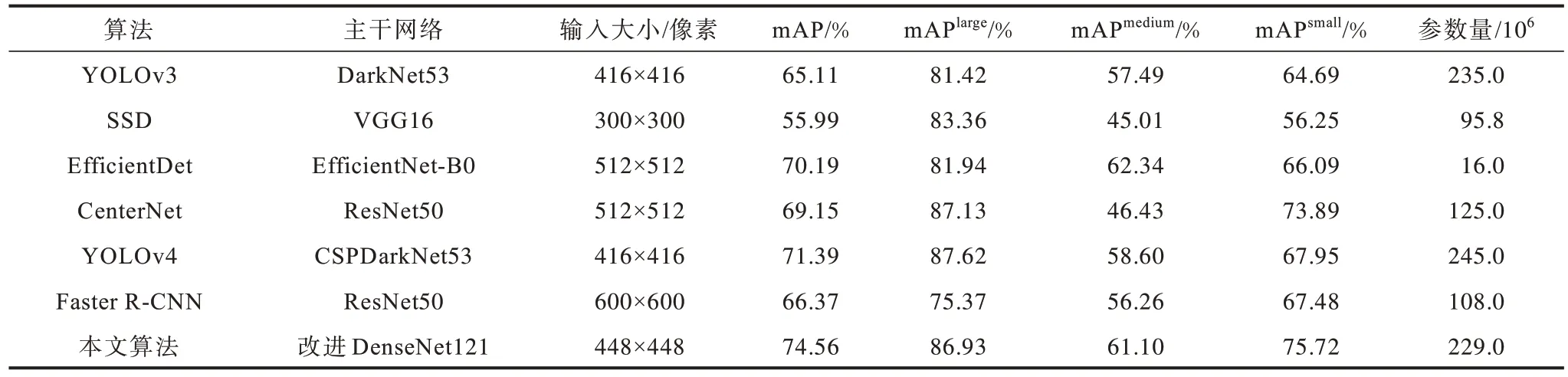
表1 对比实验结果Table 1 Results of comparative experiment
图8 所示为2 种算法的检测效果对比,第1 行为原始YOLOv3 算法的检测结果,第2 行为本文算法的检测结果。第1 列、第2 列背景为机场与港口,是典型的遥感图像场景,从中可以看出,原始YOLOv3 算法在这种具有复杂背景的图片下存在漏检现象,部分目标如飞机、油罐等无法检出,而本文算法漏检现象则大幅减少;第3 列、第4 列为道路背景图片,待检目标的尺寸较小,原始YOLOv3 算法无法有效检出目标车辆,而本文算法在高分辨率下对小目标仍有较好的检测效果;第5 列~第7 列为森林、海域背景图片,可以明显看出,当待检目标距离较近时,原始YOLOv3 算法会出现漏检现象,而本文算法的检测效果得到有效提升。

图8 2 种算法的检测效果对比Fig.8 Comparison of detection effects of two algorithms
2.4 消融实验结果分析
本节通过消融实验以探究各部分改进对模型的性能影响。
第1 组对比实验分析替换主干网络对模型精度的影响,本次实验设置3 组模型进行对比,分别为原始 YOLOv3 模型,对比模型 1(使用原始DenseNet121 的YOLOv3 模型)以及对比模型2(使用本文主干网络的YOLOv3 模型),3 组实验分别使用不同的主干网络,其他参数相同,实验结果如表2所示。从表2 可以看出,使用原始DenseNet121 作为主干网络时mAP 的提升并不明显,这是由于较低的分辨率输入以及原始DenseNet121 在下采样时损失过多特征信息所导致,而使用本文改进的主干网络时,mAP 提高了6.76 个百分点,在大、中目标上的检测精度均高于原始模型,且在小目标上的检测精度提升最为显著。由于遥感图像中的目标尺度集中分布在小尺寸范围内,因此本文所提主干网络更适用于遥感图像检测。
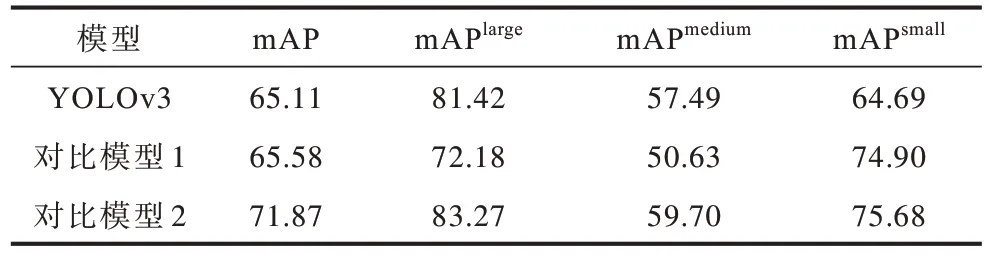
表2 主干网络消融实验结果Table 2 Experimental results of backbone network ablation %
第2 组对比实验分析特征增强模块与特征金字塔结构对模型的影响,设置4 组模型进行对比,实验结果如表3 所示。从表3 可以看出,使用特征增强模块的模型mAP 提升显著,而单独使用改进特征金字塔结构时则效果不明显,这是由于原始YOLOv3 模型中特征未经强化处理,语义信息过少,使改进后的特征金字塔效果较差,而当2 项改进共同使用时,检测精度达到最高。
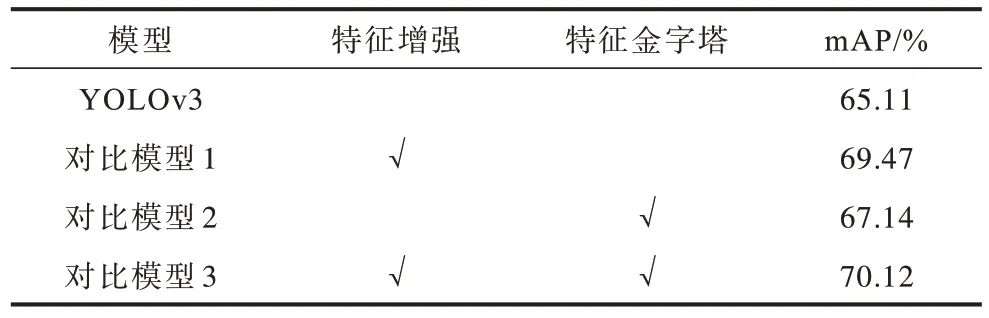
表3 特征增强模块与特征金字塔消融实验结果Table 3 Experimental results of feature enhancement module and feature pyramid ablation
3 结束语
本文针对遥感图像背景干扰大、目标尺度小等问题,提出一种基于改进YOLOv3 的遥感图像目标检测算法。将密集连接网络与YOLOv3 相结合,通过由多分支结构与空洞卷积所组成的特征增强模块来加强特征的语义信息,使用新型的特征金字塔结构减少对小目标的检测精度损失。在遥感图像数据集上的实验结果验证了该算法在目标检测任务中的有效性,尤其在小目标检测上优势明显。后续将结合本文算法进一步探究密集连接网络与感受野原理对遥感图像检测的影响,以实现更高的检测精度。
