基于中值预测的四轮嵌入可逆信息隐藏算法
2022-06-16薛斐元姚雪梅
任 方,薛斐元,姚雪梅
(1.西安邮电大学 网络空间安全学院,西安 710121;2.无线网络安全技术国家工程实验室,西安 710121)
0 概述
近年来,随着互联网的快速发展,数据传输的安全性在各个领域受到广泛关注。信息隐藏是指将秘密数据隐藏在多媒体文件(如图像)中,使嵌入的秘密信息不容易被检测出[1],信息隐藏的主要技术有隐写术[2-4]、数字水印[5-7]等。大多数的传统信息隐藏算法可以保证完整的嵌入并提取出秘密数据,但不会考虑数据提取后对原始图像造成的永久性失真,这在某些对原始图像有严格要求的领域是不能接受的。为了解决这一难题,研究人员提出可逆信息隐藏算法[8],该类算法可以在提取秘密数据后无失真地恢复出原始图像,目前已被广泛使用。良好的可逆信息隐藏算法必须具备嵌入容量大、失真率低这2 个重要条件,但这2 个条件之间相互冲突,当嵌入较多数据时会导致更多的像素值发生变化,造成伪装图像高失真,反之亦然。因此,研究在同等嵌入容量下具有较低失真率的可逆信息隐藏技术,具有重要的理论意义和使用价值。
早期的可逆信息隐藏算法主要基于无损压缩[9]来实现,这种算法的嵌入容量有限,且算法性能取决于压缩算法的优劣,应用范围较窄。TIAN[10]在2003 年提出基于差值扩展的可逆信息隐藏算法,该算法通过将2 个相邻的像素产生的差值扩大2 倍,从而嵌入一个数据位,因此,其最大嵌入容量可以达到0.5 bpp。李传目等[11]通过扩展相邻3 个像素值与其均值的差值来嵌入数据,其最大嵌入容量从0.5 bpp提升到0.66 bpp。苏文桂等[12]提出双层差值扩展,其更好地利用了像素之间的相关性,在高嵌入率下可以保证较低的失真率。LI 等[13]提出一种基于预测误差扩展的方法,该方法可以有效降低图像的失真率。与无损压缩相比,差值扩展具有更大的嵌入容量。
NI 等[14]在2006 年提出一种基于直方图平移的可逆信息隐藏算法,该算法移动图像灰度直方图峰值点与零点之间的像素点以留出空余位置,通过修改峰值点像素值进行数据嵌入,由于每个像素值最多变化1,因此其具有较小的失真率。随后,出现了许多基于直方图平移技术的改进算法[15-16]。LEE 等[15]提出利用图像差值直方图进行可逆信息隐藏的方法,与NI 等的灰度直方图移位相比,差值直方图的形状更加陡峭,峰值点较高,因此,能实现更高的嵌入容量。WANG 等[16]提出一种基于多个直方图平移进行数据嵌入的通用框架,使用该框架可以大幅提高嵌入容量。
THODI 等[17]在2007 年提出一种基于预测误差扩展的可逆信息隐藏算法,与普通的误差扩展相比,该算法利用预测误差进行扩展嵌入,更好地利用了相邻像素点之间的局部相关性。随后,研究人员在此基础上做出多方面的改进。TSAI 等[18]将预测误差扩展技术引入到直方图平移算法中,利用相邻像素的相关性预测来解决直方图平移算法嵌入容量低的问题。SACHNEV 等[19]提出菱形预测算法,该算法将图像划分为类似于棋盘格的2 个互不相交的集合,其中一个集合用于预测,另一个集合用于数据嵌入,从而实现双层嵌入,提高了算法的嵌入容量。CHEN 等[20]提出一种非对称直方图平移的可逆信息隐藏算法,该算法减少了无效移位点个数,降低了伪装图像的失真率。WENG 等[21]提出像素值排序的可逆信息隐藏算法,该算法首先对图像进行分块,然后对块中剩余像素作排序,选择3 个最大以及最小的像素值点进行数据嵌入,最高可在每2 个像素点中嵌入一位数据,提高了嵌入容量。HUANG 等[22]在生成误差直方图后首先将大于峰值点的像素向右移位,当嵌入数据后再次生成误差直方图并向左移位,从而实现了双层嵌入,改善了嵌入容量不足的问题。
本文提出一种基于预测误差直方图平移的可逆信息隐藏算法,该算法利用中值预测生成预测误差直方图,在嵌入数据时采用四轮嵌入的模型提高算法的嵌入容量。在平移预测误差直方图时,基于每个像素点的复杂度对预测误差进行排序,优先在图像平滑区域嵌入数据,减少只用于移位而不进行嵌入的无效移位像素点的个数,从而解决图像失真的问题。
1 基础理论
本节以NI 等[14]和TSAI 等[18]所提算法为例,详细阐述基于灰度直方图平移与基于预测误差直方图平移进行数据嵌入的过程。
1.1 灰度直方图平移算法
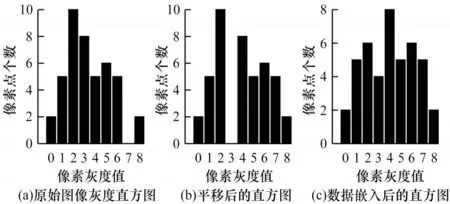
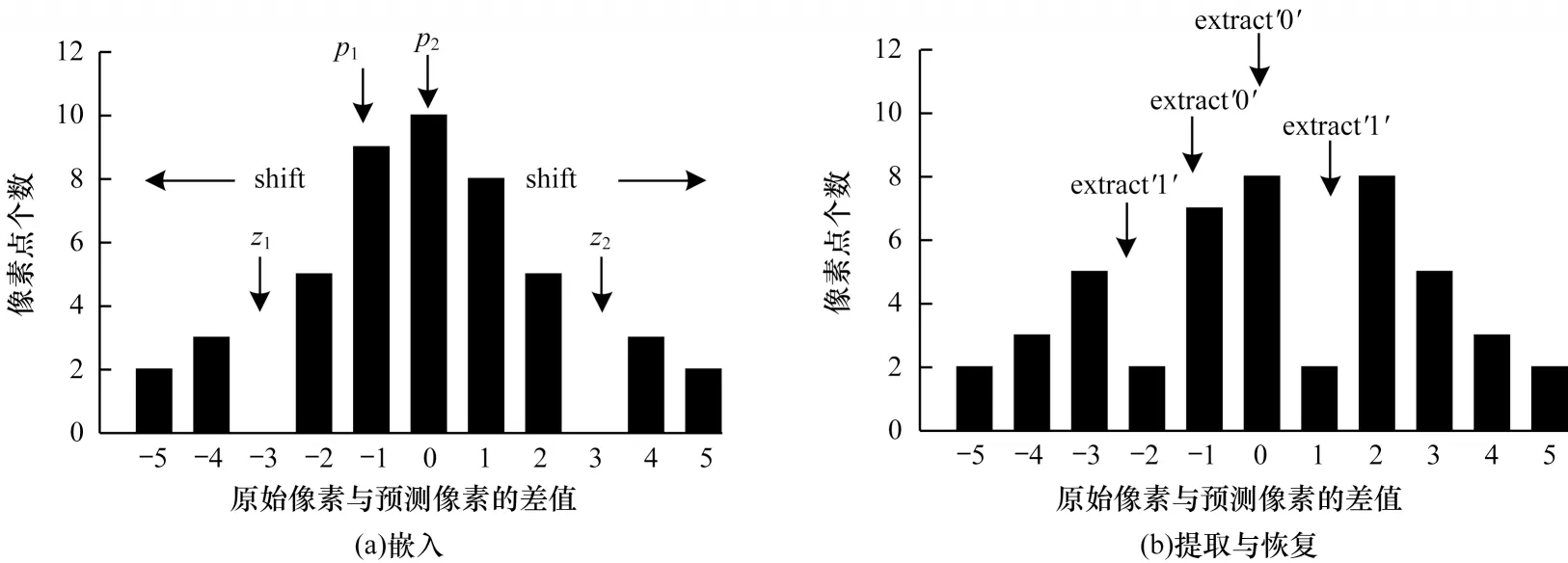
灰度直方图平移算法首先扫描整幅图像生成像素灰度直方图,然后在直方图中找到一对峰值点与零点,在数据嵌入时,将峰值点与零点之间的像素平移一个单位以留出空位,当要嵌入的数据位是“1”时,峰值点像素平移一个单位,当要嵌入的数据位是“0”时,峰值点像素保持不变。设a、b分别为峰值点与零点,且a 其中:x(i,j)是原始载体图像的像素值;y(i,j)是移位后的伪装图像像素值;m∈{0,1}为待嵌入的秘密数据。 图1(a)所示为原始图像灰度直方图,其中,a=2,b=7;图1(b)与图1(c)分别是平移与数据嵌入后的直方图。从中可以看出,最坏情况下每个像素点的灰度值变化1 个单位,即均方误差最大为1,对于一幅512×512 像素的灰度图,可以计算出峰值信噪比(PSNR)最小为48.13 dB,因此,在数据嵌入后可以得到与原始载体图像视觉效果相近的伪装图像。此外,在提取端只需将灰度直方图按照相反的位置移位,即可恢复原始图像。 图1 灰度直方图的平移与嵌入过程Fig.1 Translation and embedding process of gray histogram 对于一副尺寸为M×N的灰度图像I,将其划分为大小为m×n的图像块,在每个图像块中用多个像素点线性预测一个像素点的像素值,具体嵌入过程如下: 1)对于每个图像块,用原始像素值减去预测像素值来计算预测误差。通过收集所有的预测误差e∈[−255,255],可以构造出图像的预测误差直方图h(e)。 2)在得到预测误差直方图h(e)后,先将其按照正负划分为h(e+)、h(e−)2 个部分,其中,e+∈(0,255),e−∈(−255,−1),然后在2 个区间内各找出一对峰值点和零点(p+,z+)、(p−,z−)。 3)将(p+,z+)区域内的预测误差向右移,(p−,z−)区域内的预测误差向左移,留出空余位置,然后根据秘密数据b∈{0,1}在峰值点进行数据嵌入。 4)每个块都以相同的方式进行处理,在处理完所有块后,利用修改过的预测误差加预测像素值得到伪装图像。 在提取与恢复阶段,只需将预测误差直方图按照相反的位置移位,即可恢复原始图像。该算法分别在h(e+)和h(e−)中找到峰值点和零点进行嵌入,因此,在不考虑位置信息的情况下,其嵌入容量等于p++p−。 上述2 种算法均存在2 个缺陷:其一是没有充分考虑相邻像素的相关性,直方图的峰值点像素较少,算法嵌入容量较低;其二是按照像素的空间位置进行顺序嵌入,没有考虑图像的局部平滑度,导致无效移位点(即只进行移位而不进行数据嵌入的像素点)过多,灰度值变化的像素点较多,均方误差较大,图像失真较高。如果能优先在图像的平滑区域嵌入数据,伪装图像与原始图像之间的差异就会减小,因为平滑区域有较少的无效移位点。因此,合理设计预测方式,同时根据像素复杂度优先在平滑区域嵌入数据,对于增大嵌入容量和减小伪装图像失真率都会有一定的改善效果。 如前文所述,嵌入容量与预测误差直方图峰值点处的像素点数目密切相关,当直方图越趋近于陡峭时,意味着峰值点越多,嵌入容量也越大。为了改善预测误差直方图平移算法的性能,本文充分考虑相邻像素的相关性,提出一种基于中值预测误差的四轮嵌入算法。该算法采用图像划分集合和中值预测的方法进行像素值预测,其中,划分的集合互不相交,预测时集合之间互不影响,可以无损地恢复原始图像。中值预测的优势在于利用相邻像素点的灰度值对中心点像素进行预测,预测值更为准确,生成的预测误差直方图峰值点个数更多,增大了嵌入容量,由于图像像素总数是固定的,因此减少了无效移位像素点。上述2 种方法相结合,利用中值预测方法计算当前集合中像素点的预测值时,使用的像素点来自其他集合,与当前集合的其他点无关,方便进行无损恢复。此外,本文算法还根据每个像素点的复杂度对预测误差进行排序,优先在图像平滑区域嵌入数据,从而进一步减少无效移位像素点,降低由于数据嵌入所导致的均方误差以及伪装图像的失真率,从而实现更好的嵌入效果。 本文算法将图像中的所有像素点分为4 个互不相交的集合,记为A、B、C、D,如图2 所示。嵌入过程分为四轮进行,每一轮使用其中一个像素点集合嵌入秘密信息的1/4,具体预测过程为:使用邻近的8 个像素点预测中心点像素,如预测A集合的点xi,j时使用相邻的B、C、D集合的点。该方法的优势在于充分考虑了邻近像素之间的相关性,使预测值更为准确,生成的预测误差直方图可以在误差较小的点处聚集大量像素,大幅提升了嵌入容量,如图3 所示。 图2 四轮嵌入模型Fig.2 Four-round embedded model 图3 本文算法的预测误差直方图Fig.3 The prediction error histogram of this algorithm 目前大多数预测误差直方图平移算法都是按照固定顺序来扫描像素从而进行秘密数据嵌入,并没有考虑图像的纹理信息。本文为图像中的每个像素点定义复杂度,按照像素点复杂度进行排序,从复杂度低的点处开始嵌入数据,该方法优先在图像平滑区域嵌入信息,使原始图像与伪装图像的差异更小,从而减少了无效移位像素点个数。 对于一个尺寸为M×N的图像,首先将其分为4 个互不相交的集合,然后进行中值预测,具体预测过程如图4 所示。 图4 中值预测过程Fig.4 Median prediction process 在不考虑边界上的像素时,每个集合的预测方式是相同的,以集合A为例,在第一次嵌入数据时,集合A用于数据嵌入,剩余3 个集合用于对集合A进行预测。具体步骤如下: 1)分别抽取除中心点像素xi,j外的8 个邻近像素(xi−1,j−1,xi−1,j,xi−1,j+1,xi,j−1,xi,j+1,xi+1,j−1,xi+1,j,xi+1,j+1),并将其按照升序排列为。 2)对于xi,j,其预测值为该序列最中间2 个像素值的平均值med: 预测误差为: 3)按照上述步骤对图像剩余的集合A像素点进行处理。 根据预测误差直方图可以将像素点分为嵌入点和平移点2 个部分。只进行平移的点是无效移位点,它不会影响实际嵌入容量的大小,但当其数量较多时会导致PSNR 降低,原始图像与伪装图像的差异过大。因此,根据图像平滑程度对每个像素点定义复杂度,根据复杂度对预测误差进行排序,在低嵌入率下可以减少无效移位点的个数,提升PSNR 值。不同的复杂度判断标准会对低嵌入率下的PSNR 产生一定影响,本文给出一种复杂度计算方法。为了完整恢复原始图像,像素点复杂度应具备如下2 个特征: 1)该值不能在嵌入数据后发生变化。 2)当像素点复杂度较小时,预测误差绝对值也应该较小,反之亦然。 本文算法中的4 个集合是相互独立的,意味着一组集合中的像素值变化不会影响到另一组集合,反之亦然。预测集合A中的点xi,j使用了其余3 个集合的灰度,这些灰度在嵌入前后不发生变化,因此,复杂度也应该由它们进行计算。本文根据相邻像素之间的相关性将它们各自的局部差值定义为像素xi,j的复杂度,当该复杂度较小时,预测误差一般也较小。将中心点与邻近8 个像素点做灰度差,然后计算这些灰度差与平均灰度差的偏离程度并将其作为中心点的复杂度,复杂度越小,中心点邻域的灰度值变化越小,图像局部区域越平滑,反之则越粗糙。复杂度的具体计算公式如下: 其中: 嵌入过程具体如下: 1)根据B、C、D这3 个集合获取集合A中所有像素的复杂度和预测误差,将复杂度按升序排序以获得序列(fA1(i,j),fA2(i,j),fA3(i,j),…),并通过复杂度中的顺序对预测误差进行排序,得到(eA1(i,j),eA2(i,j),eA3(i,j),…)。 2)生成预测误差直方图,找出2 对峰值点与零点(p1,z1)、(p2,z2)(这里的零点是指误差值出现次数为0 的点),p1、p2分布在直方图中间区域,z1、z2分布在直方图两端区域。 3)将1/4 的秘密数据分配给集合A。依次扫描预测误差序列(eA1(i,j),eA2(i,j),eA3(i,j),…)并按照式(5)修改预测误差,实现数据嵌入。 其中:b是要嵌入的秘密数据,b∈{0,1};为修改后的预测误差。因此,伪装图像的像素值可由下式计算: 其中:yi,j为伪装图像的像素值。 4)根据上述步骤完成集合A的数据嵌入,以同样的方式分别进行集合B、C、D的数据嵌入。 提取与恢复是嵌入的逆向过程,在嵌入时是从集合A到集合D,在提取和恢复时则需要从集合D开始。首先,从集合D中提取嵌入的秘密数据并恢复D,然后分别在C、B、A上做同样的操作。由于4 个集合互不相交,在恢复原始图像像素值时使用的预测值与嵌入时使用的预测值完全一样,因此可以无损恢复出原始图像。提取与恢复的具体流程如下: 1)计算伪装图像中集合D所有像素的预测误差和复杂度。注意到集合D中像素的复杂度是基于嵌入后的集合A、B、C而计算的,它的值与嵌入D之前相同,因此,升序排列后的复杂度序列和预测误差序列的顺序与嵌入时相同。 2)提取秘密信息。按照式(7)依次从预测误差序列(eD1(i,j),eD2(i,j),eD3(i,j),…)中提取嵌入的秘密数据: 这里的两对峰值点和零点(p1,z1)、(p2,z2)与嵌入时相同。 3)恢复原始图像。在提取所嵌入的秘密数据的过程中,原始图像的恢复如下: 相应地,原始像素值可由式(9)恢复: 4)在集合D提取和恢复完成后,以D为基础,利用同样的操作完成集合C、B、A的提取和恢复,直至整个原始图像完全恢复。 当p1>p2、z1>z2时,预测误差直方图的移位情况如图5 所示。 图5 本文算法的嵌入、提取与恢复过程Fig.5 The embedding,extraction and recovery process of the algorithm in this paper 在预测误差直方图的移位过程中可能存在上溢或下溢的问题,导致原始图像的部分点恢复不具备可逆性,因此,需要对原始图像进行预处理。首先,由于本文使用四轮嵌入模型,因此边界位置的像素值(即图像边界上、下、左、右4 列)不在考虑范围之内;其次,对于像素值为0 或255 的点,左移或右移会导致原始图像永久性失真,因此,需要将其记录下来,在嵌入时不使用这些点,将其位置信息作为附加信息并与秘密信息一起进行嵌入。在恢复时,首先根据附加信息找到那些未使用的点,然后将其排除在外,在提取秘密信息和恢复载体时不对这些点进行操作。 本次实验选用6 张来自USC-SIPI图像数据库且尺寸为512×512 像素的标准测试图像,分别为Lena、Baboon、Airplane、Boat、Elaine、Man,如图6所示。从PSNR和嵌入能力2个方面,将本文算法与非对称直方图算法[20]、像素值排序算法[21]以及误差直方图移位算法[22]进行比较。此外,为了降低随机选择测试图像所造成的影响,分别对该数据库中的30幅灰度图像进行平均结果测试。 图6 测试图像1Fig.6 Test images 1 由于4 种对比算法本质上都是利用预测误差直方图在峰值点嵌入数据,因此在不考虑附加信息的情况下,嵌入数据的位数等于峰值点像素个数。本文以嵌入率EEC作为衡量标准,EEC表示每个像素点最多可以嵌入多少位数据。对于一幅尺寸为512×512 像素的测试图像,最大嵌入率的计算公式如下: 其中:pmax为预测误差直方图中峰值点像素个数。由于本文使用四轮嵌入的模型,因此最大嵌入率为: 图7 所示为4 种算法在6 幅测试图像中的最大嵌入容量情况。从图7 可以看出,本文算法具有较高的嵌入能力。在测试图像Lena 中,本文算法最多可嵌入63 832 位数据,嵌入率高达0.24 bpp,比其他3 种算法分别高出0.08 bpp、0.02 bpp、0.11 bpp。在纹理相对粗糙的图像Baboon 中,本文算法的嵌入率为0.07 bpp,虽然相较其他图像下降了很多,但是仍然分别高出其他3 种算法0.018 bpp、0.020 bpp、0.010 bpp。在纹理相对平滑的图像Airplane中,本文算法嵌入率高达0.36 bpp,远高于其他3 种算法。本文采用四轮嵌入的模型,用中心点像素周围的8 个像素点做预测,预测值较3 种对比算法更为准确,峰值点像素更多。此外可以看出,非对称直方图算法在部分图像中的嵌入容量和本文算法之间差距很小,这是因为该算法采用不对称预测误差直方图将直方图分成正、负2 个部分,可以实现双层嵌入。 图7 4 种算法的最高嵌入率对比Fig.7 Comparison of highest embedding rate of four algorithms PSNR 通常用来衡量图像质量,其能反映原始图像与伪装图像之间的相似程度,PSNR 值越高,说明伪装图像与原始图像之间越相似。在计算PSNR时,首先要计算图像的均方误差,用MSE 表示原始图像与伪装图像之间的均方误差。对于一副尺寸为512×512 像素的测试图像,MSE 定义为: 其中:xi,j为原始图像像素值;yi,j为伪装图像像素值。PSNR 的计算公式为: 图8所示为同等嵌入容量下各算法的PSNR对比。 图8 同等嵌入容量下的PSNR 对比Fig.8 Comparison of PSNR under the same embedding capacity 从图8 可以看出,在同等嵌入容量的情况下,本文算法PSNR 性能明显高于另外3 种算法。在纹理相对粗糙的测试图像Baboon 中,当嵌入容量是5 000 bit 时,本文算法的PSNR 为60.08 dB,比3 种对比算法分别高出0.12 dB、0.92 dB、0.62 dB。在纹理相对平滑的测试图像Airplane 中,3 种对比算法的PSNR 虽然都很高,但是本文算法仍然优于3 种算法,如在嵌入容量为5 000 bit 时,本文算法的PSNR可达65.78 dB。本文使用中心像素邻近8 个像素的中位数进行预测,预测值更为精准,此外,在嵌入端根据每个像素点的复杂度对预测误差序列进行排序,在图像相对平滑的区域优先嵌入数据,在同等的嵌入容量下大幅减少了无效移位的像素点个数,降低了均方误差,提高了PSNR,因此,本文算法的嵌入质量明显高于3 种对比算法。 如图9 所示,本文分别对USC-SIPI 图像数据库中的30 幅尺寸为512×512 的灰度图像进行平均结果测试,其中,最大嵌入率及对应的PSNR 值如表1 所示,当嵌入容量为0.1 bpp 时的PSNR 如表2 所示。从表1可以看出,本文算法的平均最大嵌入率为0.30 bpp,而其他3 种算法的平均最大嵌入率分别为0.15 bpp、0.16 bpp、0.13 bpp,本文算法分别提高了0.15 bpp、0.14 bpp、0.17 bpp。从表2 可以看出,本文算法在嵌入率为0.1 bpp 时PSNR 平均值为55.15 dB,相较非对称直方图算法提高了0.61%,相较误差直方图平移算法提高了0.7%,相较像素值排序算法提高了0.62%。 图9 测试图像2Fig.9 Test images 2 表1 最大嵌入率及对应的PSNRTable 1 Maximum embedding rate and its corresponding PSNR 表2 嵌入率为0.1 bpp 时的PSNRTable 2 PSNR at embedding rate of 0.1 bpp dB 根据上述实验结果可以得出,本文算法对于典型灰度图像具有较好的效果,能够在完整提取秘密信息后无失真地恢复原始图像,且具有较高的嵌入容量和伪装性,这是因为本文算法采用了四轮嵌入的模型,每一次都使用中心像素周围的8 个像素灰度值排序后进行中值预测,由于这些像素点位置相邻,因此灰度值具有较强的相关性,得到的预测值较其他算法更为准确,预测误差直方图的峰值点像素更多,在嵌入率方面有较大优势。同时,这种精确的预测方法也使嵌入数据时需要进行无效移位的像素点个数大幅减少,从而提升了PSNR 值。 本文算法的另一个优势是对每个像素点定义了复杂度,根据复杂度高低来扫描预测误差,优先在图像平滑区域嵌入数据,有效降低了伪装图像的失真率,进一步提升了PSNR 值,得到的伪装图像视觉质量更好。此外,本文算法虽然是四轮嵌入,但是对于每个像素点只需进行一次预测,且预测的主要过程是少量相邻像素值排序,耗时较小,算法的执行效率较高。与其他算法相比,本文算法的计算复杂度没有明显提高,因此,具有较强的实用性和适用性。 为了增大嵌入容量并提升伪装图像的视觉质量,本文提出一种基于中值预测的可逆信息隐藏算法。该算法将图像划分为4 个互不相交的集合并分层嵌入数据,在利用某一集合进行嵌入时,通过其他3 个集合的像素点中值进行预测,由于图像各个像素点之间具有一定的相关性,因此生成的预测误差直方图更加陡峭,可以实现较高的嵌入容量。此外,本文在嵌入数据时,根据每个像素点的复杂度对预测误差进行排序,优先在像素平滑区域嵌入数据,从而大幅减少无效移位像素点,降低由于数据嵌入所导致的均方误差,最终提高峰值信噪比。实验结果表明,本文算法具有较大的嵌入容量,且在同等嵌入容量下,其PSNR 较对比算法更高。本文算法在一定程度上提升了可逆信息隐藏性能,但仅限于以灰度图像作为载体的情况。彩色图像三通道之间同样存在较强的相关性,充分利用彩色图像自身的特点设计一种比传统算法更优的可逆信息隐藏算法,将是本文下一步的研究方向。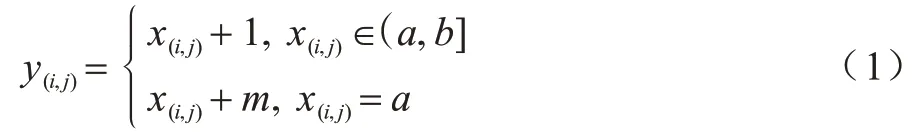
1.2 预测误差直方图平移算法
2 本文算法
2.1 算法思想


2.2 中值预测



2.3 复杂度计算

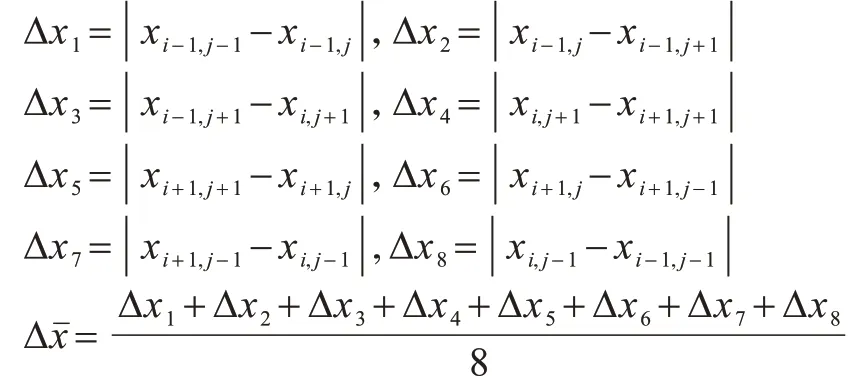
2.4 嵌入过程
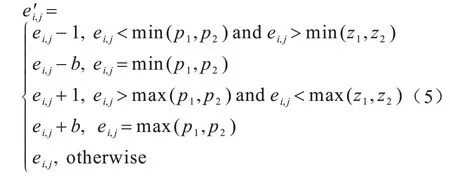

2.5 提取与恢复过程
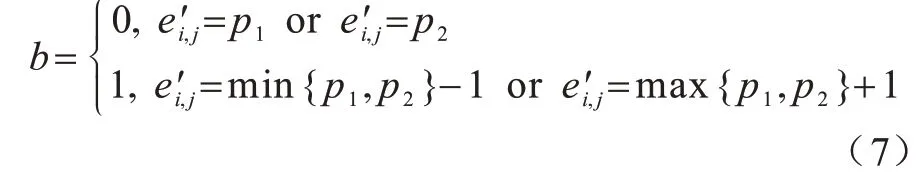


2.6 上溢和下溢问题处理
3 实验结果及分析

3.1 嵌入容量对比



3.2 PSNR 对比






3.3 结果分析
4 结束语
