一种鲁棒的半监督联邦学习系统
2022-06-16王树芬马士尧陈俞强
王树芬,张 哲,马士尧,陈俞强,伍 一
(1.哈尔滨石油学院 信息工程学院,哈尔滨 150028;2.黑龙江大学 数据科学与技术学院,哈尔滨 150080;3.广州航海学院 信息与通信工程学院,广州 510725)
0 概述
联邦学习[1-3](Federated Learning,FL)是隐私计算领域的重要技术,允许多个边缘设备或客户端合作训练共享的全局模型。联邦学习[4]的特点是每个客户端只能私有地访问本地数据,而不能与云中心共享数据[5-6]。现有研究多数要求客户端的数据都带有真实的标签,然而在现实场景下客户端的数据多数是没有标签的。这种标签缺失的现象通常是由于标注成本过高或缺少相关领域的专家知识造成的[7]。因此,如何利用本地客户端上的无标签数据来训练高质量的全局模型对联邦学习而言是一个巨大的挑战。
文献[7-10]设计一种可将半监督学习技术有效地整合到FL 中的半监督联邦学习(Semi-Supervised Federated Learning,SSFL)系统。文献[7]引入一致性损失和已训练的模型,为无标签数据生成伪标签。目前,伪标签和一致正则化方法已广泛应用于半监督领域,但是伪标签主要利用预测值高于置信度阈值的伪标签来实现高精度模型,一致正则化技术通过在同一个无标签数据中分别注入两种不同噪声应保持相同模型输出来训练模型[11]。因此,亟需设计一个通用的联邦半监督学习框架,但设计该框架存在两个主要问题。第一个是传统SSFL 方法[7,12-13]直接将半监督技术(例如一致性损失和伪标签)引入FL 系统,之后使用联邦学习算法来聚合客户端的模型参数。这样将导致模型在利用大量无标签的数据学习后会遗忘从少量标签数据中学习到的知识。文献[10]分解了标签数据和无标签数据的模型参数用于进行分离学习,却忽略了全局模型迭代更新之间的隐式贡献。因此,全局模型将偏向于标签数据(监督模型)或无标签数据(无监督模型)。第二个是统计异质性,即客户端本地的训练数据分布是非独立同分布(not Identically and Independently Distributed,non-IID)的。其主要原因为不同的客户端具有不同的训练数据集,而这些数据集通常没有重叠,甚至是分布不同的。因此,在异构数据的训练过程中,客户端局部最优模型与全局最优模型会出现很大的差异。这将导致标准的联邦学习方法在non-IID 设置下全局模型性能出现显著下降和收敛速度慢的问题。目前,研究人员对此进行了大量研究并在一定程度上缓解了non-IID 问题。例如文献[14]利用局部批处理归一化来减轻平均聚合模型和局部模型之前的特征偏移。然而,此类方法给服务器或客户端增加了额外的计算和通信开销。
本文针对上述第一个问题,提出FedMix 方法,分析全局模型迭代之间的隐式效果,采用对监督模型和无监督模型进行分离学习的模型参数分解策略。针对上述第二个问题,为了缓解客户端之间的non-IID 数据分布对全局模型收敛速度和稳定性的影响,提出FedLoss 聚合方法,通过记录客户端的模型损失来动态调整相应局部模型的权重。此外,在实验中引入Dirchlet 分布函数来模拟客户端数据的non-IID 设置。
1 相关工作
半监督联邦学习试图利用无标签数据进一步提高联邦学习中全局模型的性能[9]。根据标签数据所在的位置,半监督联邦学习分为标签在客户端和标签在服务器两种场景[10]。文献[12]提出FedSemi,该系统在联邦学习设置下统一了基于一致性的半监督学习模型[15]、双模型[16]和平均教师模型[17]。文献[8]提出DS-FL 系统,旨在解决半监督联邦学习中的通信开销问题。文献[18]提出一种研究non-IID数据分布的方法。该方法引入了一个概率距离测量来评估半监督联邦学习中客户端数据分布的差异。与以上方法不同,本文研究了标签数据在服务器上这一场景,同时也解决了联邦学习中non-IID 的问题。
由于每个客户端本地数据集的分布与全局分布相差较大,导致客户端的目标损失函数局部最优与全局最优不一致[19-21],特别是当本地客户端模型参数更新很大时,这种差异会更加明显,因此non-IID的数据分布对FedAvg[1]算法的准确性影响很大。一些研究人员试图设计一种鲁棒的联邦学习算法去解决联邦学习中的non-IID 问题。例如,FedProx[22]通过限制本地模型更新的大小,在局部目标函数中引入一个额外的L2 正则化项来限制局部模型和全局模型之间的距离。然而,不足之处是每个客户端需要单独调整本地的正则化项,以实现良好的模型性能。FedNova[23]在聚合阶段改进了FedAvg,根据客户端本地的训练批次对模型更新进行规范化处理。尽管已有研究在一定程度上缓解了non-IID 问题,但都只是评估了特定non-IID 水平的数据分布,缺少对不同non-IID 场景下的广泛实验验证。因此,本文提出一个更全面的数据分布和数据分区策略,即在实验中引入Dirchlet 分布函数来模拟客户端数据的不同non-IID 水平。
2 相关知识
2.1 联邦学习
联邦学习旨在保护用户隐私的前提下解决数据孤岛问题。FL 要求每个客户端使用本地数据去合作训练一个共享的全局模型ω*。在FL 中,本文假设有一个服务器S和K个客户端,其中每个客户端都存在一个独立同分布(Independently Identical Distribution,IID)或者non-IID 数据集Dk。具体地,客户端使用损失函数l(ω;x)训练样本x,其中ω∈Rd表示模型可训练的参数。本文定义L(ω)=作为服务器上的损失函数。因此,FL需要在服务器端优化如下目标函数:

其中:pk≥0,表示第k个客户端在全局模型中的权重。在FL 中,为了最小化上述目标函数,服务器和客户端需要执行以下步骤:
步骤1初始化。服务器向被选中的客户端发送初始化的全局模型ω0。
步骤2本地训练。客户端在本地数据集Dk上使用优化器(例如SGD、Adam)对初始化的模型进行训练。在训练后,每个客户端向服务器上传本地模型。
步骤3聚合。服务器收集客户端上传的模型并使用聚合方法(例如FedAvg)聚合生成一个新的全局模型,即ωt+1=ωt+。之后服务器将更新后的全局模型ωt+1发送给下一轮被选择参与训练的客户端。
2.2 半监督学习
在现实世界中,例如金融和医疗领域,无标签数据很容易获得而标签数据很难得到。与此同时,标注数据通常耗费大量的人力物力。为此研究人员提出了一种机器学习范式——半监督学习[24-26]。半监督学习可以在混合的数据集(一部分为标签数据,另一部分为无标签数据)上训练得到高精度模型。因此,近些年半监督学习在深度学习领域成为一个热门的研究方向。在本节中,将介绍半监督学习中的一个基本假设和两种常用的半监督学习方法。
假设1(一致性)在机器学习中存在一个基本假设:如果两个无标签样本u1、u2的特征相似,那么相应模型的预测结果y1、y2也应该相似[14],即f(u1)=f(u2),其中f(·)是预测函数。
根据假设1,研究人员一般采用如下两种常用的半监督学习方法:
1)一致性正则化。该方法的主要思想是对于无标签的训练样本,无论是否加入噪声,模型预测结果都应该是相同的[19]。通常使用数据增强(如图像翻转和移位)的方式来给无标签样本添加噪声以增加数据集的多样性。假定一个无标签数据集u=中的无标签样本ui,其扰动形式为,则目标是最小化未标记数据与其扰动输出两者之间的距离,其中fθ(ui)是样本ui在模型θ上的输出。一般地,采用Kullback-Leiber(KL)散度进行距离测量,因此一致性损失计算如下:
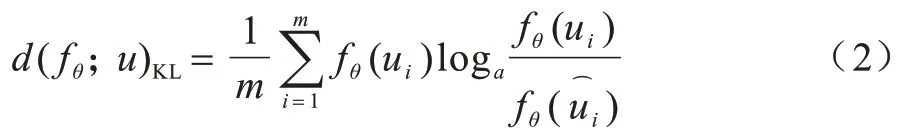
其中:m表示未标记样本的总数;fθ(ui)表示无标签样本在模型θ上的输出。
2)伪标签[15]。该方法利用一些标签样本来训练模型,从而给无标签样本打上伪标签。一般使用Sharpening[15]和argmax[15]方法来设置伪标签,其中前者使模型输出的分布极端化,后者会将模型输出转变为one-hot。伪标签方法也称为自训练方法,具体步骤如下:
步骤1使用少量的标签数据训练模型。
步骤2将无标签数据输入该模型,之后将无标签数据的预测结果进行Sharpening 或argmax 操作,得到无标签数据的伪标签。
步骤3标签数据和伪标签数据共同训练模型。
重复步骤2 和步骤3,直至模型收敛。
3 问题定义
目前,针对FL 的研究多数基于标签数据训练模型。然而,缺少标签数据是现实世界中的一种常见现象。同时,在标签数据不足的情况下,现有方法的实验结果较差。半监督学习可以使用无标签数据和少量的标记数据来达到与监督学习几乎相同的模型性能。因此,本文将半监督学习方法应用于联邦学习框架中。在SSFL 系统中,根据标签数据所在的位置,可以分为两种场景:第一种场景是客户端同时具有标签数据和无标签数据的常规情况,即标签在客户端场景;第二种场景是标签数据仅可用在服务器上,即标签在服务器场景。本文针对标签在服务器场景,给出问题定义:当标签数据只在服务器端,客户端仅有无标签数据时,在SSFL 中假设有1 个服务器S和K个客户端。服务器上有1 个标签数据集Ds=,每个客户端均有1 个本地无标签数据集。因此,在这种情况下,对于无标签的训练样本ui,令为第k个客户端的损失函数,具体公式如下:
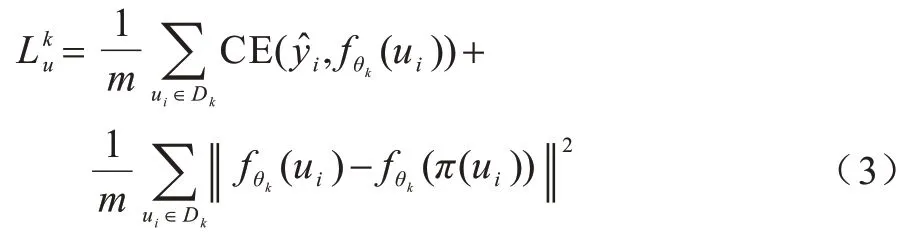
其中:m是无标签样本的数量;π(·)是数据增强函数,例如无标签数据的翻转和平移;是无标签样本ui的伪标签;是样本ui在第k个客户端的模型θk上的输出。对于标签样本xi,令Ls为服务器端的损失函数,具体公式如下:
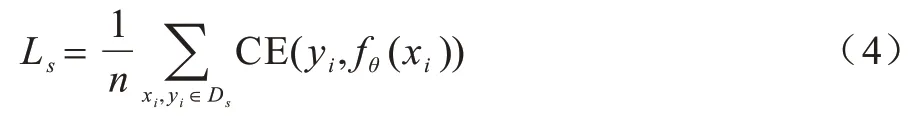
其中:n是标签样本的数量;fθ(xi)是样本xi在模型θ上的输出。因此,在SSFL 中标签在服务器场景中国的目标是将损失函数最小化,具体公式如下:

整个学习过程类似于传统的FL 系统,不同之处在于服务器不仅聚合客户端模型参数,而且还使用标签数据训练模型。
4 系统与方法设计
4.1 半监督联邦学习系统设计
在半监督联邦学习系统(如图1 所示)中,①~⑥表示训练过程,服务器S持有一个标记的数据集Ds=。对于K个客户端,假设第k个客户端拥有本地无标签的数据集。与传统FL 系统类似,SSFL 中的服务器和客户端合作训练高性能的全局模型ω*,目标是优化上述目标函数式(5),但是它们忽略了全局模型迭代之间的隐式贡献,从而导致学习的全局模型不是最佳的。
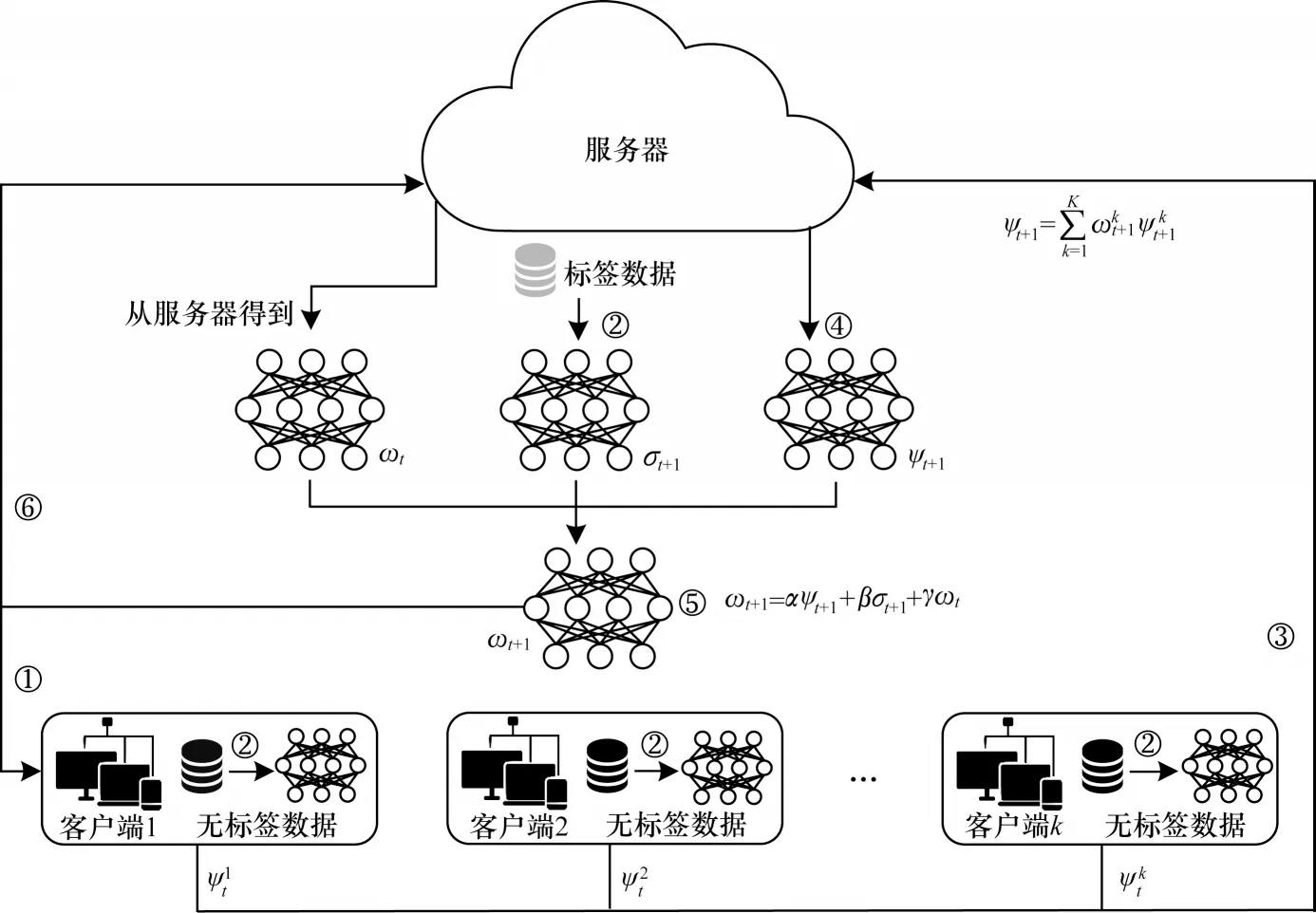
图1 半监督联邦学习系统框架Fig.1 Framework of semi-supervised federated learning system
受此启发,本文提出一种FedMix 方法,该方法以细粒度的方式关注全局模型迭代之间的隐式贡献,将在标记数据集上训练的监督模型定义为σ,在无标签数据集上训练的无监督模型定义为ψ,聚合的全局模型定义为ω。具体而言,本文设计一种参数分解策略,分别将α、β和γ3 个权重分配给无监督模型ψ、监督模型σ和上一轮的全局模型ω。FedMix方法可以通过细粒度的方式捕获全局模型的每次迭代之间的隐式关系,具体步骤如下:
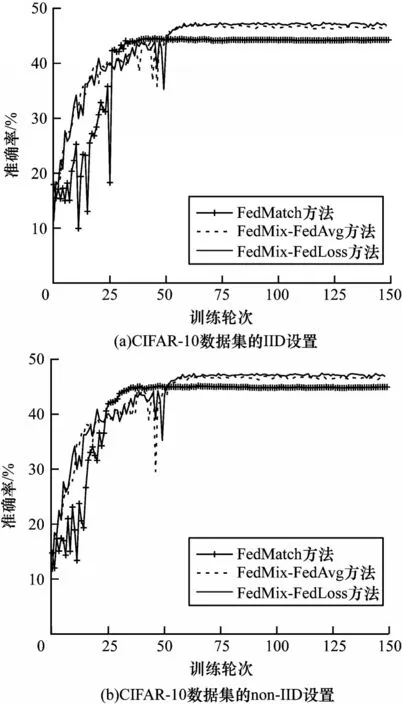
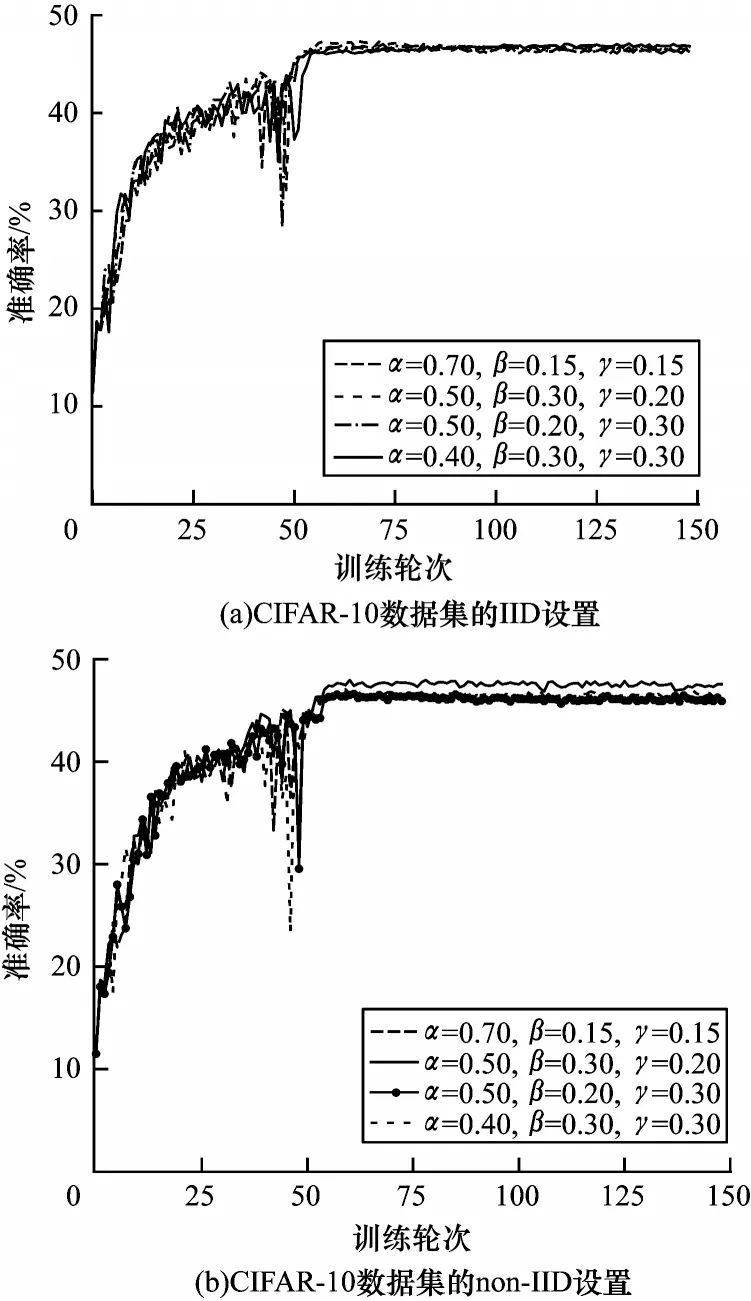
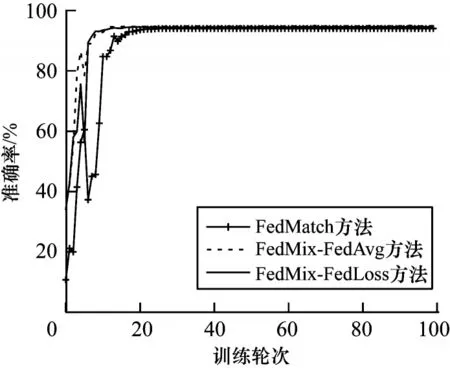
步骤1初始化。服务器从所有本地客户端中随机选择一定比例F(0 步骤2服务器训练。与FL 不同,在本文SSFL系统中,服务器不仅聚合客户端上传的模型,而且在标签数据集Ds上训练监督模型σt(σt←ωt)。因此,服务器在标记的数据集Ds上使用本地优化器来训练监督模型σt。目标函数的最小化定义如下: 其中:λs是超参数;x和y来自标签数据集Ds;表示在第t轮训练中标签样本在监督模型σt上的输出。 步骤3本地训练。第k个客户端使用本地无标签的数据来训练接收到的全局模型,获得无监督的模型。因此,定义以下目标函数: 其中:λ1、λ2是控制损失项之间比率的超参数;是第k个客户端在第t轮的无监督模型;u来自无标签的数据集Dk;π(·)是扰动的形式,即π1是移位数据增强,π2是翻转数据增强;是通过使用本文提出的Sharpening 方法(如图2 所示)获得的伪标签。 图2 Sharpening 方法流程Fig.2 Procedure of Sharpening method Sharpening 方法的定义如下: 步骤4聚合。首先,服务器使用FedLoss 方法来聚合客户端上传的无监督模型,得到全局的无监督模型,即ψt+1=,其中是第k个客户端在第t+1 次训练轮次中的无监督模型,是第k个客户端的权重。然后,服务器将第t+1 轮的全局无监督模型ψt+1、监督模型σt+1和上一轮的全局模型ωt聚合得到新的全局模型ωt+1,如式(10)所示: 其中:α、β和γ是这3 个模型对应的权重,(α,β,γ)∈{α+β+γ=1且α,β,γ≥0}。 重复上述步骤,直到全局模型收敛。 FedLoss 聚合方法可以根据客户端模型训练的损失值调整相应局部模型的权重,用于提高聚合的全局模型的性能。原因是有些客户端模型在本地训练后性能较好,那么这些客户端就应该对全局模型做出更多的贡献。本文的目标是增大客户端性能好的本地模型对全局模型的影响,以提高模型的性能。因此,FedLoss聚合方法的定义如下: 其中:F是客户端参与率;K是客户端的总数;是第k个客户端在第t+1 轮训练的模型损失值;St+1是第t+1 轮中服务器选择的客户端集合。 为更好地评估本文所设计的系统对non-IID 数据的鲁棒性,引入Dirchlet 分布函数[27-28]来调整本地客户端数据的non-IID 水平。具体而言,通过调整Dirchlet 分布函数的参数(即μ)来生成不同non-IID水平的数据分布。假设第k个客户端的本地数据集Dk有c个类,因此Dirichlet 分布函数的定义如下: 其中:Θ是从Dirichlet 函数中随机选取的样本集,Θ={φ1,φ2,…,φc}且Θ~Dir(μ1,μ2,…,μc);μ,μ1,μ2,…,μc是Dirichlet 分布函数的参数,μ=μ1=μ2=…=μc;pk(φc)表示第c类数据占客户端所有数据的比例。如图3所示,μ越小,每个客户端数据分布的non-IID 水平越高;否则,客户端的数据分布倾向于IID 设置。 图3 不同μ 时的Dirichlet 数据分布Fig.3 Dirichlet data distribution with different μ 针对标签在服务器场景,将本文所提出的FedMix-FedLoss 方法与FedMatch 方法[10]在2 个数据集的3 个不同任务上进行比较。对于2 个真实世界的数据集(即CIFAR-10 和Fashion-MNIST),实验在配置为Intel®CoreTMi9-9900K CPU @3.60 GHz 和NVIDIA GeForce RTX 2080Ti GPU 的本地计算机(1 台服务器和K个客户端)上模拟联邦学习设置。 数据集1 为IID 和non-IID 的CIFAR-10。将CIFAR-10 数据集(包括56 000 个训练样本和2 000 个测试样本)分为IID 和non-IID 这2 种设置用作实验的验证数据集。训练集包括55 000 个无标签的样本和1 000 个标签的样本,分别分布在100 个客户端和1 个服务器上。IID 设置每个客户端有550 个样本,即每个类别有55 个样本,总共10 个类别。non-IID的设置引入了Dirchlet 分布函数来调整客户端数据的non-IID 水平。对于所有的non-IID 实验,均设置μ=0.1 用于模拟极端的non-IID 场景,即每个客户端数据的数量和类别都是不平衡的。1 000 个标签的样本位于服务器上,其中每个类别有100 个样本。同时,实验设置客户端参与率F=5%,即在每一轮中服务器随机选择5 个客户端进行训练。 数据集2 为流式non-IID 的Fashion-MNIST。使用包括64 000 个训练样本和2 000 个测试样本的Fashion-MNIST 数据集作为验证数据集。训练集包括63 000 个无标签的样本和1 000 个标签的样本,其中前者不平衡地分布在10 个客户端上,后者分布在服务器上。实验同样引入Dirchlet分布函数且参数μ=0.1。每个客户端的数据被平均分为10 份,每轮训练只使用其中的一份,训练10 轮为1 个周期。将此设置称为流式non-IID。同时,实验设定客户端参与率F=100%,即在每一轮中服务器选择所有客户端进行训练。 本文使用FedMatch 基线方法,其使用客户端间一致性损失和模型参数分解。在训练过程中,本文方法和基线方法均使用随机梯度下降(Stochastic Gradient Descent,SGD)来优化初始学习率为η=1e-3 的ResNet-9 神经网络。设置训练轮次t=150,在服务器上的标签样本数为Ns=1 000,客户端每轮的训练次数为Eclient=1,客户端每轮的训批次为Bclient=64,服务器每轮的训练次数Eserver=1,服务器每轮的训批次为Bserver=64。在Sharpening 方法中,设置A=5 和置信度阈值τ=0.80。 基线方法包括:1)SL,全部标签数据在服务器端执行监督学习,客户端不参与训练;2)FedMatch,采用客户端之间一致性损失的半监督联邦学习方法。本文方法包括:1)FedMix,无监督模型、监督模型以及上一轮的全局模型在相同权重设置下的半监督联邦学习方法,即α=β=λ=0.33;2)FedMix-FedAvg,在最优模型权重设置下,结合半监督联邦学习系统框架与FedAvg 聚合规则的方法;3)FedMix-FedLoss,在最优模型权重设置下,结合半监督联邦学习系统加FedLoss聚合规则的方法。由表1 可知:只使用标签数据的监督学习模型的准确率仅为19.3%,明显低于半监督联邦学习的组合方法,并且在相同模型权重聚合下也低于不同权重的组合方法。 表1 不同方法的准确率比较Table 1 Accuracy comparison of different methods % 本文对CIFAR-10 和Fashion-MNIST 数据集在IID和non-IID 设置下的性能进行比较。图4 给出了IID 和non-IID 设置下,不同组合方法的FedMix 和基线方法的准确率对比。实验结果表明,本文FedMix 方法的性能均比基线方法好。例如,在IID 和non-IID 设置下,本文方法的最大收敛准确率均比基线准确率高约3 个百分点。这是由于本文全局模型为无监督模型、监督模型以及上一轮的全局模型三者最优权重的聚合。但在non-IID 情况下,在模型训练的中期,出现了性能大幅波动的现象。这是由于客户端non-IID 设置影响了聚合的全局模型的性能。 图4 IID 与non-IID 设置下不同方法的性能比较Fig.4 Performance comparison of different methods under IID and non-IID settings 图5 给出了在IID 和non-IID 设置下FedMix-FedLoss 方法取不同权重值时的性能比较。从图5(a)可以看出,当这3 个参数在IID 设置下相对接近时更容易达到更好的性能。从图5(b)可以看出,在non-IID 设置下,随着α的减小,准确率变得不稳定,在α=0.5、β=0.3、γ=0.2 时,FedMix-FedLoss 方法的性能最好。 图5 IID 和non-IID 设置下FedMix-FedLoss 方法在不同权重时的性能比较Fig.5 Performance comparison of FedMix-FedLoss method with different weights under IID and non-IID settings 图6 给出了FedMix-FedLoss 方法在CIFAR-10 数据集上及在不同non-IID 设置下的性能比较。在此实验中,μ=0.1 表示客户端数据的最高non-IID 水平。随着μ值增加,本地客户端数据分布将更接近IID 设置。从实验结果可以看出,对于不同的non-IID设置,FedMix-FedLoss 方法均可以达到稳定的准确率且模型收敛准确率相差不超过1 个百分点。因此,FedMix-FedLoss方法对不同non-IID 设置的客户端数据分布不敏感,即对不同设置的数据分布具有鲁棒性。 图6 不同non-IID 设置下FedMix-FedLoss 方法的性能比较Fig.6 Performance comparison of FedMix-FedLoss method under different non-IID l settings 图7 给出了在服务器端使用不同数量的标签样本时,FedMix-FedLos 方法的准确率比较结果。由图7 可以看出,FedMix-FedLos 方法在800 个标签的样本设置下,在训练轮次为150 时的收敛准确率为47%,相比FedMatch 方法使用1 000 个标签样本时的最大收敛准确率高出2个百分点。但是当标签样本数减少到700个时,FedMix-FedLos 方法的准确率会大幅下降。 图8 给出了Fashion-MNIST 数据集流式non-IID设置下不同方法的性能比较。从图8 可以看出,本文方法的最高收敛准确率与基线方法基本相同,并且快于基线方法10 轮达到最高收敛准确率,同时减少了一半的通信开销。 图8 Fashion-MNIST 数据集流式non-IID 设置下不同方法的性能比较Fig.8 Performance comparison of different methods under streaming non-IID settings on Fashion-MNIST dataset 本文针对SSFL 中标签数据位于服务器上的场景,设计鲁棒的SSFL 系统。使用FedMix 方法实现高精度半监督联邦学习,解决了FL 系统中缺少标签数据的问题。采用基于客户端训练模型损失值的FedLoss 聚合方法,实现SSFL 系统在不同non-IID 设置下的稳定收敛。实验结果表明,在使用少量标签数据的情况下,本文SSFL 系统的性能明显优于主流的联邦学习系统。下一步将通过半监督学习算法改进无监督模型的训练方法,高效利用无标签数据提升全局模型性能。




4.2 FedLoss 聚合方法

4.3 Dirchlet 数据分布函数


5 实验验证
5.1 实验设置
5.2 实验结果


6 结束语
