基于Stacking模型融合的店铺销量预测
2022-06-15王鹏曹丽惠阮冬茹
王鹏 曹丽惠 阮冬茹

摘 要:为了实现企业产品销量预估,提高生产供应的准确性与效率,提出了基于Stacking模型的融合算法进行销量预测。算法设计了两层堆叠的模型结构,初级学习器采用随机森林、支持向量回归、差分整合移动平均自回归、轻量级梯度提升机器和门控循环单元5种单模型,将分类与回归树作为次级学习器构成Stacking融合模型,并对数据进行了预测。预测结果显示,使用Stacking模型融合后得到了较好的预测结果,比单模型中效果最好的模型的均方根误差更小,平均绝对误差更小,决定系数值更大,表明Stacking融合模型的预测准确率更高。所设计模型可用于对企业店铺的产品销量进行预测,帮助企业更好地安排生产、营销活动,为减少库存、缩短生产销售周期提供数据支持,对企业生产决策有一定的参考价值。
关键词:计算机决策支持系统;销量预测;Stacking;模型融合;初级学习器;次级学习器
中图分类号:TP311.13 文献标识码:A
DOI: 10.7535/hbgykj.2022yx03004
Store sales forecast based on Stacking model fusion
WANG Peng1,CAO Lihui2,RUAN Dongru1
(1.School of Information Science and Engineering,Hebei University of Science and Technology,Shijiazhuang,Hebei 050018,China;2.The 54th Research Institute of CETC,Shijiazhuang,Hebei 050081,China)
Abstract:In order to realize the sales volume prediction in modern enterprises and achieve the accuracy and efficiency of production and supply,a fusion algorithm based on Stacking model was proposed for sales volume prediction.The algorithm designed a two-layer stacked model structure.The primary learner adopted five single models: RF(random forest),SVR(support vector regression),ARIMA(autoregressive integrated moving average),LGBM(light gradient boosting machine),GRU (gated recurrent unit),CART (classification and regression tree) was used as secondary learners to form a Stacking fusion model,and the data were predicted.The prediction results show that there are better prediction results in the relevant data after using the Stacking model fusion.Compared with the model with the best effect in the single model,the RMSE (root mean square error) is smaller,the MAE (mean absolute error) is smaller,and the R2 (coefficient of determination) value is larger,indicating that the prediction accuracy of the Stacking fusion model is higher.This model can be used to predict the product sales and other relevant data of enterprise stores,help enterprises better arrange production and marketing,provide reference data for reducing inventory and shortening production and sales cycle,and have a certain reference value for enterprise production decision-making.
Keywords:
computer decision support system;sales forecast;Stacking;model fusion;primary learner;secondary learner
銷量预测是根据企业过去的经营状况和相关资料,对其在一定时期内的销售数量进行预计和推测。现如今,食品类零售企业大多采取以销定产的策略,由市场销售人员根据订单和销售经验预测未来一段时间的销量,分销点逐级汇报汇总编制下一周期的经营计划,生产部门安排生产进度。这种传统的生产计划方式随着市场环境变化、影响产品销售因素增多等暴露出明显的不足,时常发生因个人主观判断失误造成库存积压导致亏损等情况,而在店铺数量增加,生产成本和物流成本也增多的情况下,亏损程度更是成倍增长。同时如果店铺订货过于保守,出现缺货、少货的现象,也会大大降低客户体验度,损害品牌形象。比如某肉类零售企业所面临的以销定产问题,肉类食品保质期短,全程冷链物流,运输成本高,若临期低价销售,则会影响市场售价平衡,若过期返厂统一销毁,则会增加二次运输成本,因此准确预测销售数量成为这类企业的重要工作内容。
常用预测方法有时间序列算法和因果分析算法两类。在实际研究中人们会根据具体模型进行优化达到改进目标,或者对多种算法进行集成融合从而获得一种模型所不具有的更好性能。集成的好处是不同的模型可以学习到数据的不同特征,经过融合后的结果往往能取长补短,有更好的表现。因此将多个单模型融合的方式在目前是被使用较多的,可以达到比较好的预测效果。在众多的模型融合算法中,Stacking模型融合算法凭借其强大的预测性能,不但在数据挖掘比赛中屡获佳绩,而且在实际应用中也颇受好评,受到了众多学者的青睐[1]。
张宁[2]把BP神经网络、SVR(support vector regression,支持向量回归)和DBN(deep belief network,深度置信网络)相结合,建立了一种新的回归预测组合预测模型,并基于该模型设计实现了便利店销量预测系统。常炳国等[3]分别采用SVR和ELM(extreme learning machine,极限学习机),对时序模型中非线性误差进行预测并进行误差补偿,提高了商品销量的预测精度。DUAN等[4]选择多种手机特征作为输入变量,以不同的手机销售前景等级作为输出变量,基于SVR,BP神经网络和KNN(K-Nearest Neighbor,K最近邻),建立组合模型并预测各种销售情景,预测值与市场上多种手机的实际销售情况基本吻合。梁超[5]基于工程机械设备大数据,结合XGBoost[6],RF(random forest,随机森林),LGBM[7] (light gradient boosting machine)等多種机器学习模型,多维度探究影响机械核心部件寿命的机器学习模型效果,建立Stacking模型融合的部件寿命预测模型,并在核心部件数据上验证模型预测有效性,从而减少设备非计划停机时间,推进智能制造和预测性维护的进步。杨荣新等[8]构建了多个机器学习算法嵌入的Stacking模型融合光伏发电功率预测模型,该融合模型相较于单模型,预测精度显著提升。范红星[9]使用ID3[10],CART[11] (classification and regression tree,分类与回归树)和RF相结合,构建了基于特征选择和Stacking模型融合的学生学业水平预测模型,极大地提高了模型的准确率,增强了模型的泛化能力。邓威等[12]集成KNN,SVM(support vector machines,支持向量机),RF,GBDT(gradient boosting decision tree,梯度下降树),MLP(multilayer perceptron,多层感知机)5种模型[13],构建了一种基于特征选择和Stacking模型融合的配电网网损预测方法,较好地挖掘了网损数据规律,提升网损预测精度和鲁棒性。王辉等[14]提出一种在多机器学习模型融合下基于Stacking模型融合的销售预测方法,模型在零售企业的库存管理、经营管理、供应链管理中有较高的应用价值。张雷东[15]利用Stacking算法把XGBoost,SVR,GRU[16] (gated recurrent unit,门控循环单元)作为基础模型,将LGBM作为最终的预测模型,大大提高了模型的预测性能,更加接近真实的销量数据,为回归预测提供了一种新的预测方法,并应用到具体应用系统中。
1 销量预测的Stacking模型
Stacking是机器学习中集成学习的一种方法。Stacking就是将一系列模型(初级学习器)的输出结果作为新特征输入到其他模型(次级学习器),这种方法实现了模型的层叠,即第1层的模型输出作为第2层模型的输入,第2层模型的输出作为第3层模型的输入,依次类推,最后一层模型输出的结果作为最终结果。
根据Stacking模型的特点,初级学习器一般选择预测效果好的强模型,而且模型之间差异性越大,预测效果越好,简单而言就是要“好而不同”。研究目前成果中使用的预测方案,本文先选取RF,SVR,ARIMA(autoregressive integrated moving average,差分整合移动平均自回归)3种预测效果较好的单模型作为初级学习器,随后又将LGBM和XGBoost模型加入对比,结果显示LGBM运行速度较快,节省时间,且预测效果相当,遂选取LGBM加入初级学习器;实验中还发现GRU相较于LSTM参数少,容易收敛,运行速度快,预测效果却差别不大,于是选取GRU加入初级学习器,最终确定以两层Stacking建立模型。为了防止过拟合,Stacking第2层模型相对简单,作为次级学习器,具体过程如下。
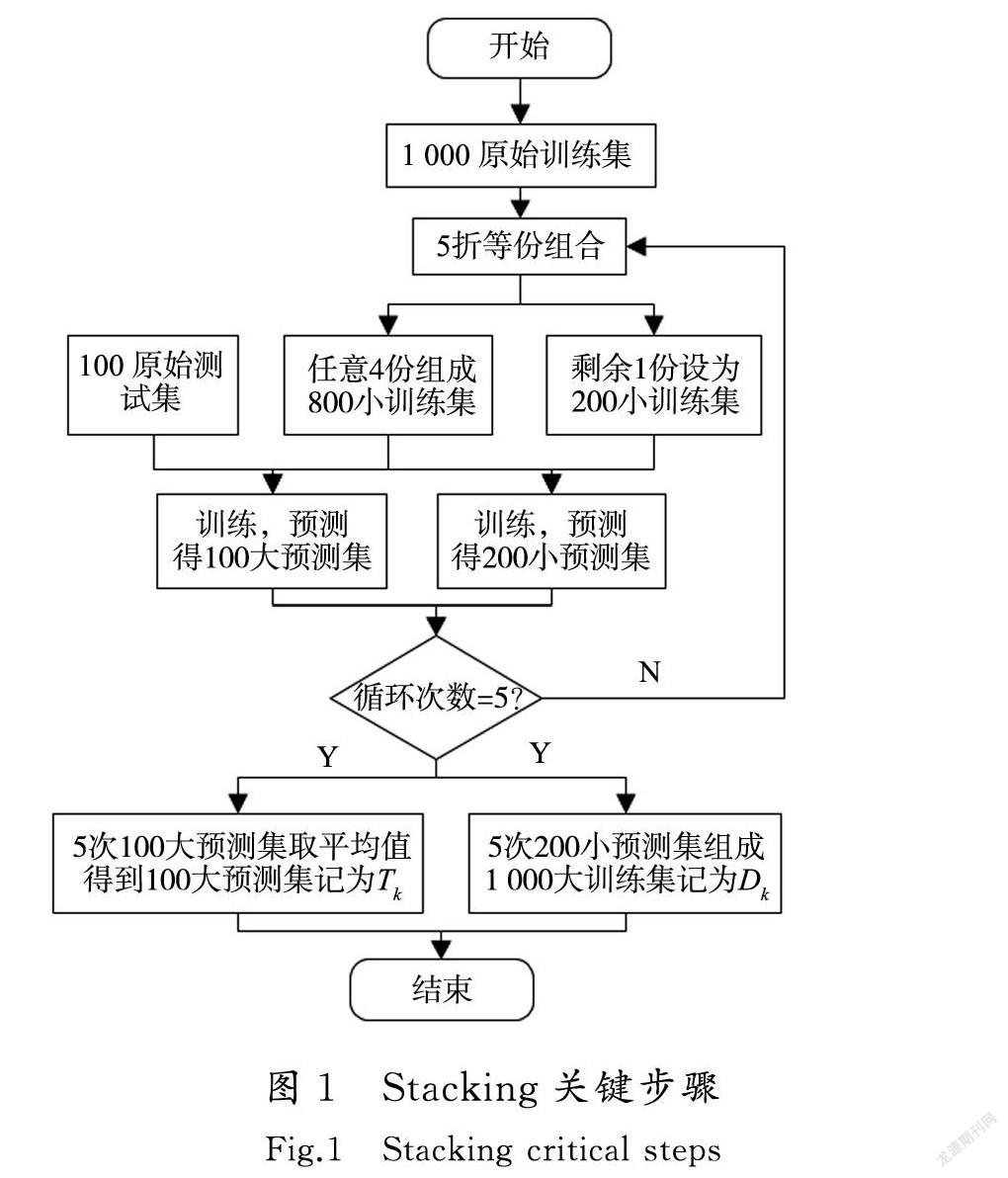
1)将原始数据集划分为两部分:原始训练集D和原始测试集T。
2)对初级学习器进行K折交叉验证:将原始训练集D随机分成K等份(d1,d2,…,dk),每个初级学习器将其中的1份作为K折测试集,剩下的K-1份作为K折训练集。使用K折训练集训练每个初级学习器,并对K折测试集进行预测,合并每个初级学习器的预测结果,作为次级学习器的训练集Dk。
3)每个初级学习器对原始测试集T进行预测,将K次预测结果求平均值,得到集合(t1,t2,…,tk),把该集合作为次级学习器的测试集Tk。
4)次级学习器从初级学习器中得到生成的新数据集:训练集D′(D1,D2,…,Dk)和测试集T′(T1,T2,…,Tk),开始学习训练,输出最终的预测结果。
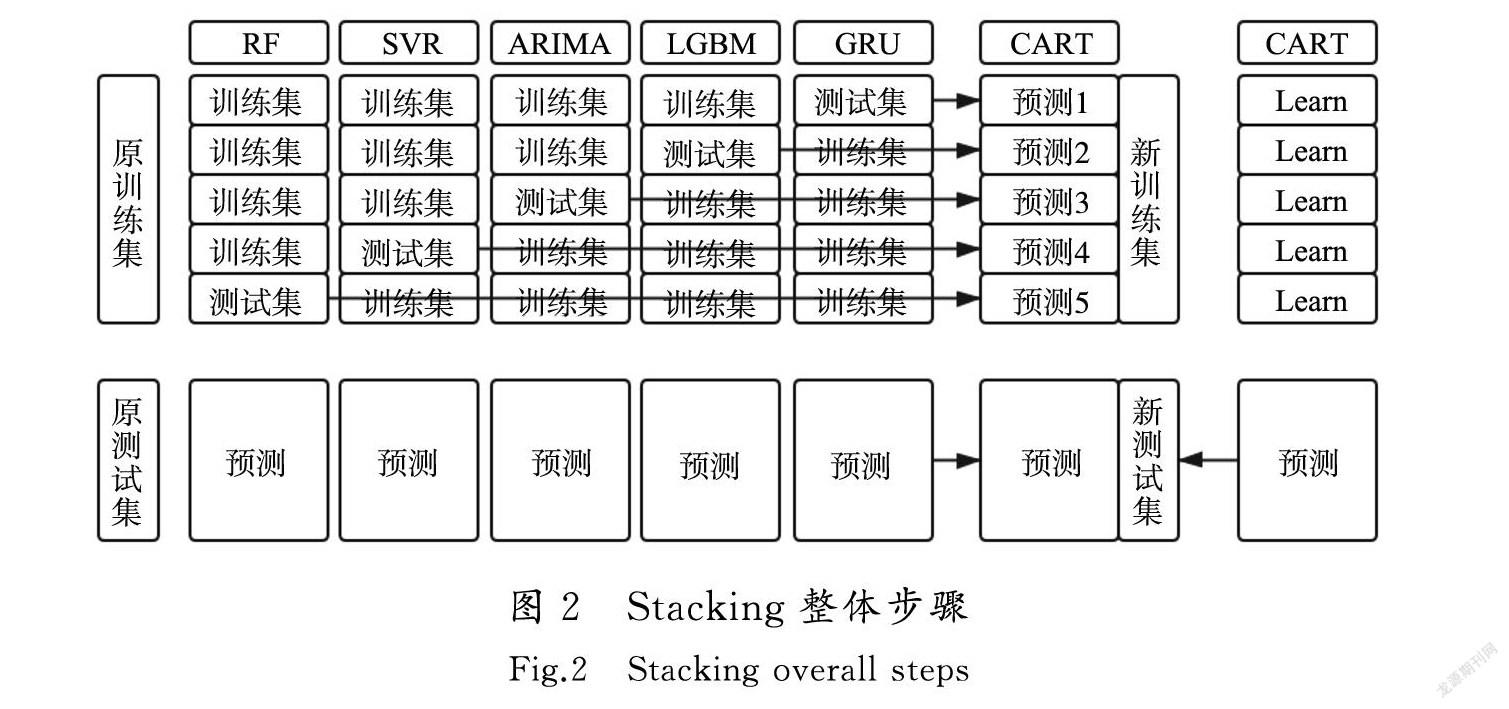
图1示例了Stacking算法关键步骤1)—3)的执行过程,即单模型的初级学习过程及数据分配情况。假设原始训练集有数据1 000条,原始测试集数据100条,算法如图1所示。
得到的初级学习器输出结果作为输入进入次级学习器CART。本方案的Stacking模型执行过程的整体步骤如图2所示。
2 实验方案设计
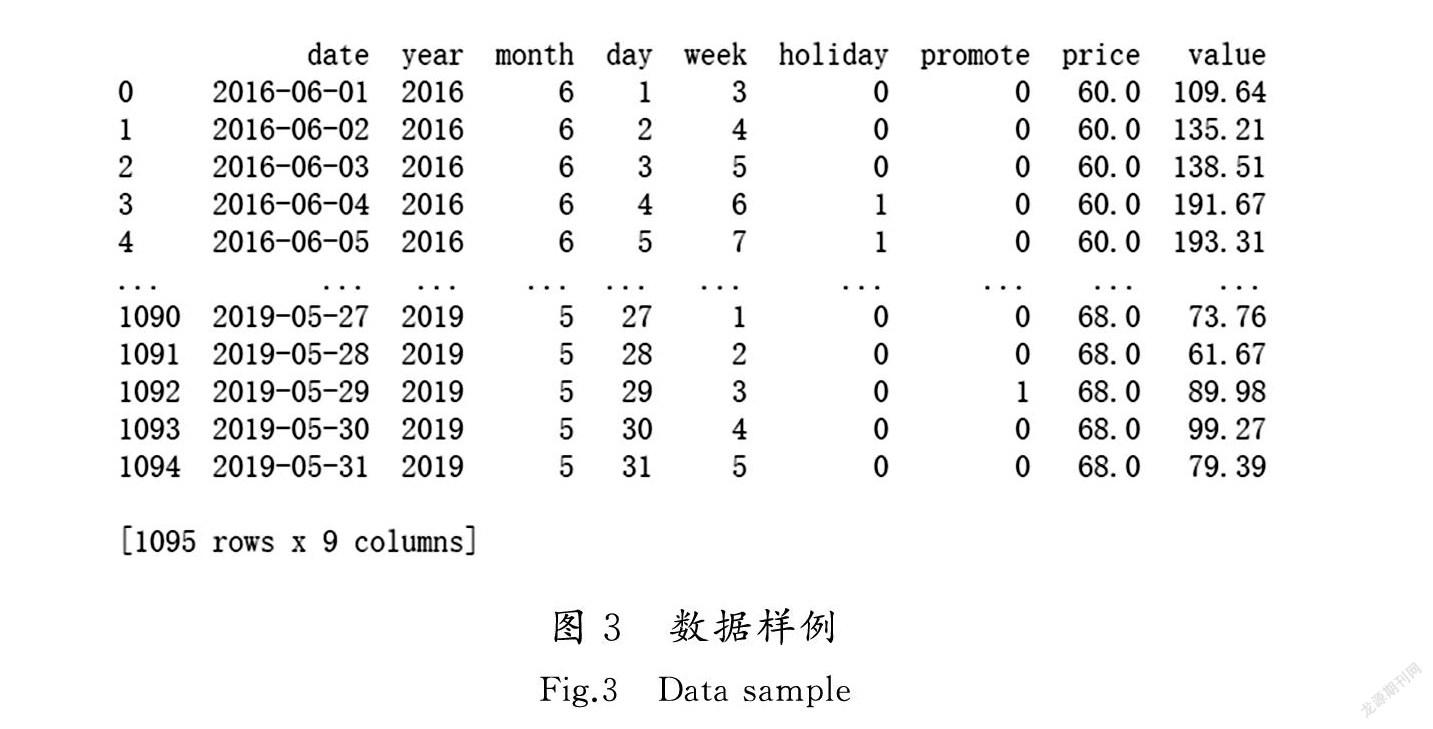
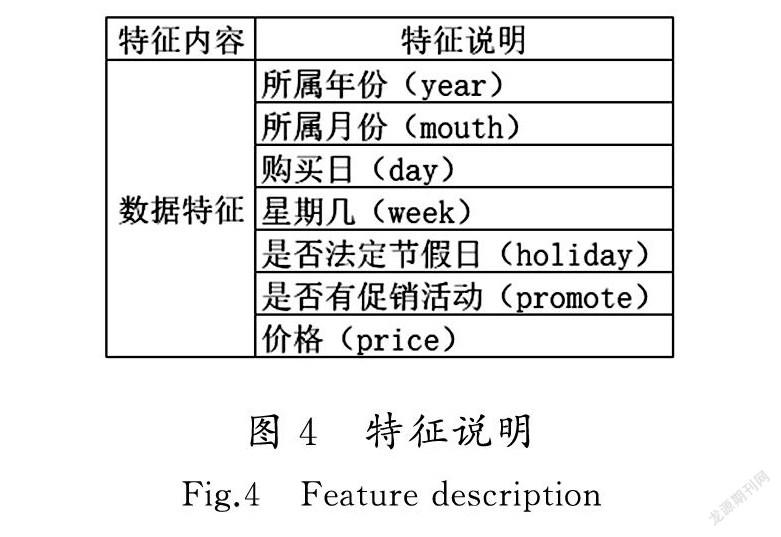
实验环境为CPU(i7-7700)、内存(16 GB)、显卡(GTX-1050Ti)、Python3.6和MySQL8。实验数据使用的是某企业零售190家店铺从2017-06-01至2019-05-31三年的销售数据,总共1 489 380条。使用MySQL数据库对异常值进行处理,最终去掉了期间关闭的店铺,最后剩余店铺69家。随机选取某款热销商品A在店铺1和店铺2的销售数据作为实验样例,总共2 190条数据,预测商品A在店铺1的销量和商品A在店铺2的销量。数据样例如图3所示。数据特征解释说明如图4特征说明所示。数据特征的重要性分析如图5所示。
在数据特征重要性分析中发现:数据主要特征有7个,其中受节假日(holiday)影响最大,对促销特征(promote)不敏感。
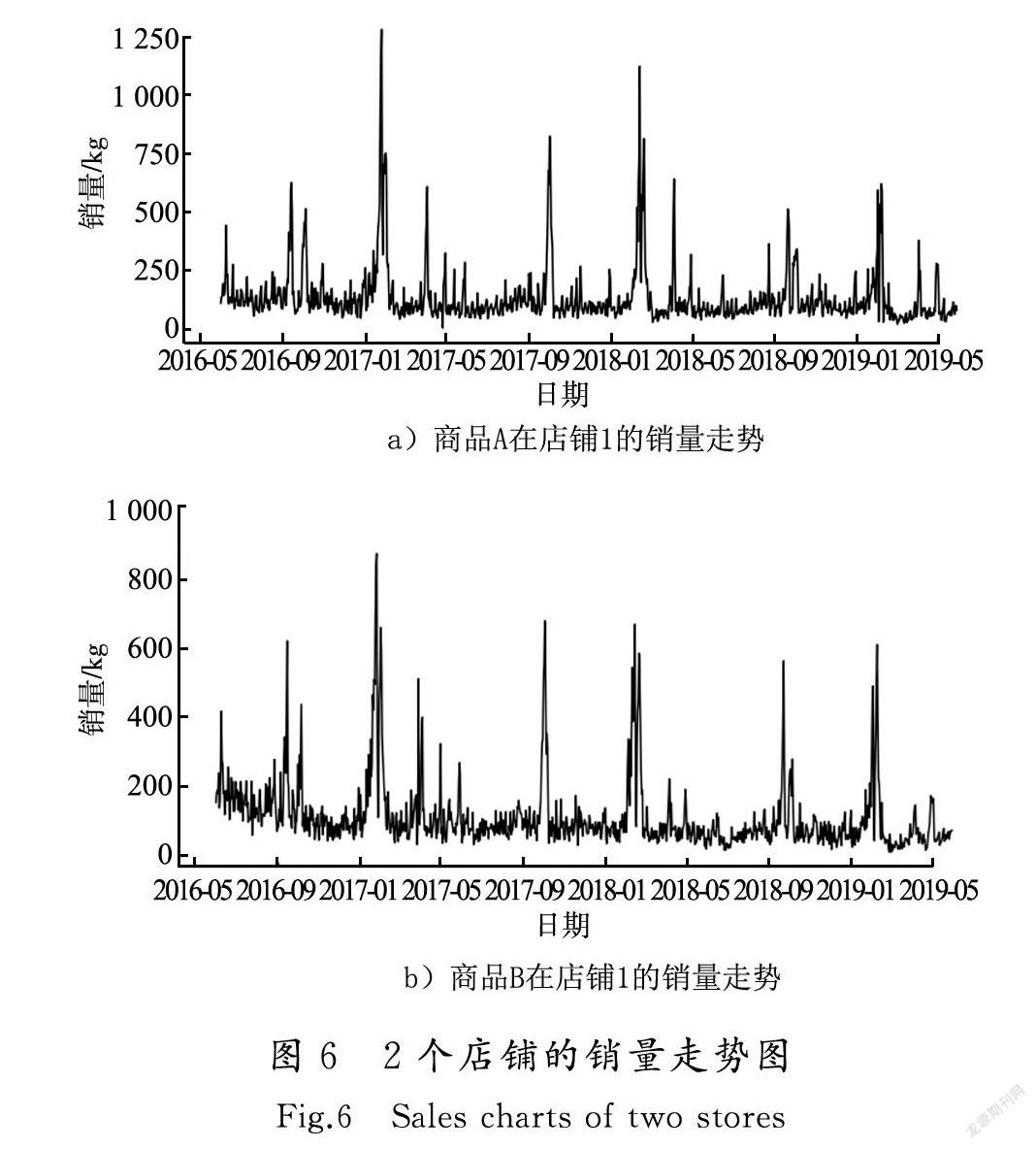
商品A在店铺1和店铺2的销量走势如图6所示。可以看出2个店铺的销量是有周期性变化的,而且具有较高的相似度。例如9月份与1月份销量相对较高,但是因为该实验数据所选取的产品礼品属性较强,而时间适逢临近中秋和春节2个传统节日,这个结果即使预测准确也会因企业产能不足等原因无法实现,即对销量的提升影响甚微,目前对这2个时段暂不预测。因此提高其余月份的销量预测准确率,才是目前企业亟需解决的问题。
3 实验结果及分析
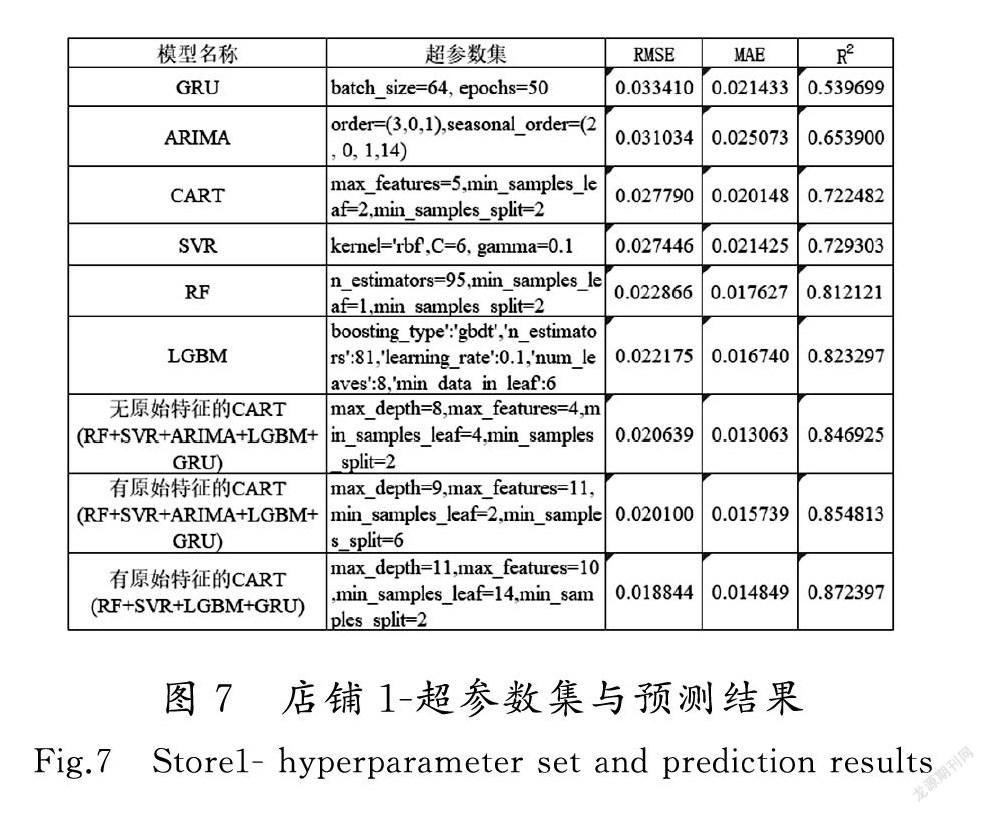
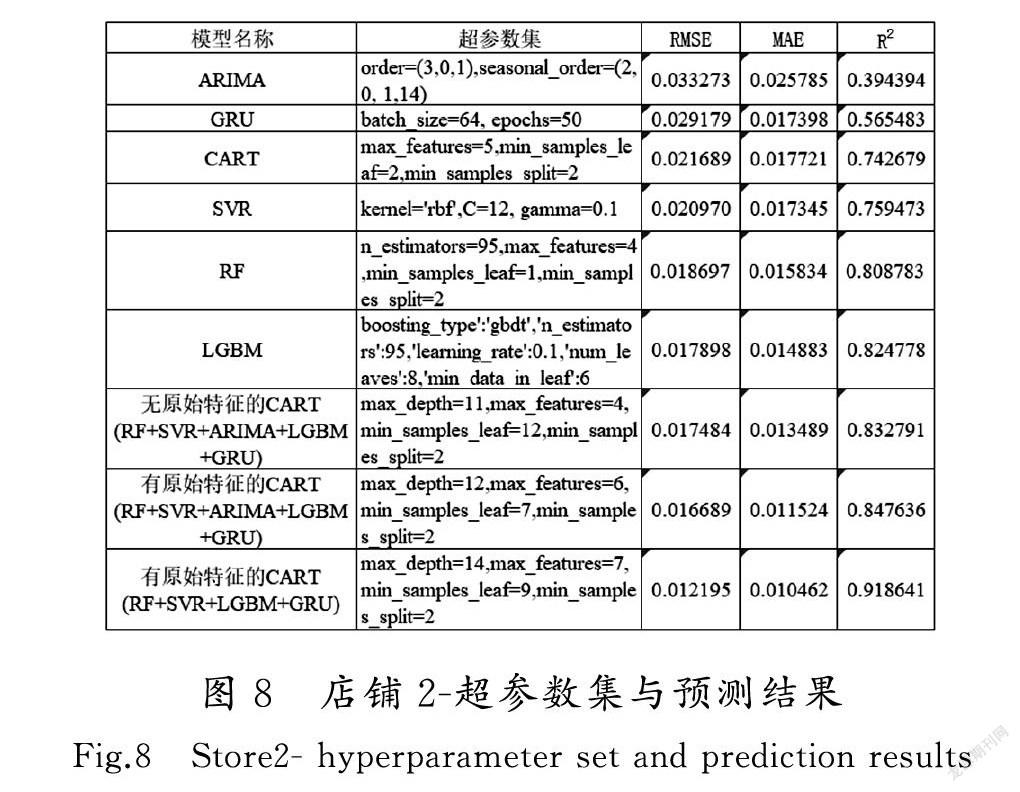
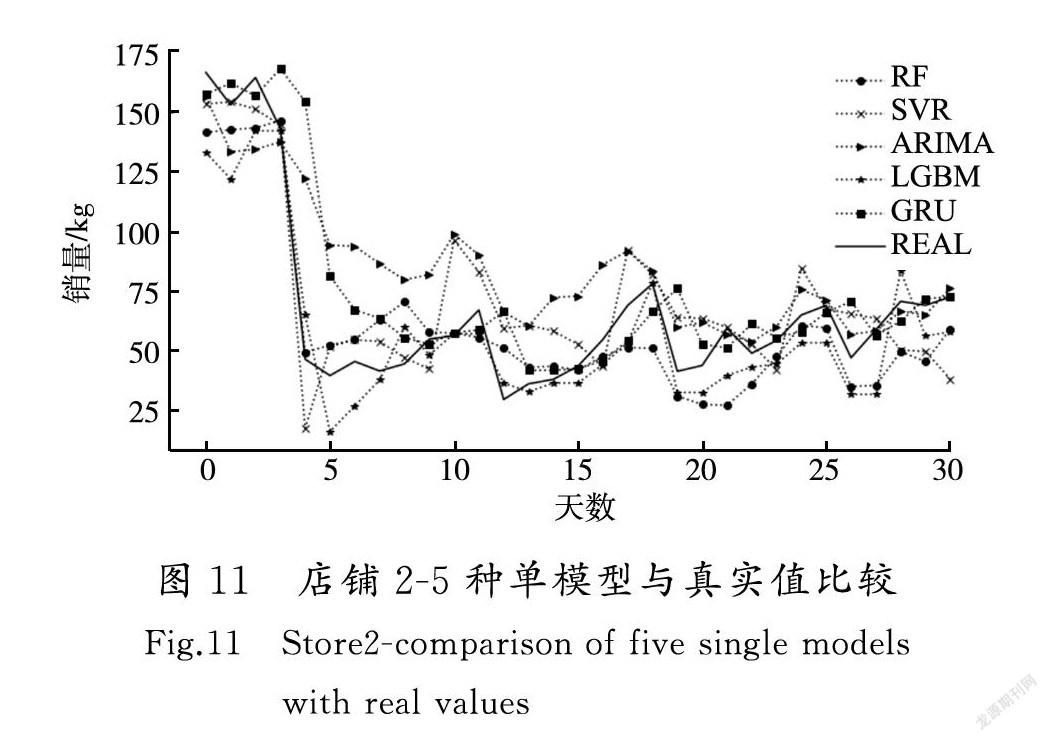
按照Stacking算法设计的实验步骤,分别用RF,SVR,ARIMA,LGBM,GRU模型作为初级学习器进行5折交叉验证,训练5种初级学习器并输出预测结果,组合生成新的数据集作为5个新特征。然后采用旧数据集加入5个新特征作为新数据集,用决策树模型作为次级学习器,对新数据集进行训练,输出最终预测结果。另外去掉预测效果较差的ARIMA模型的结果特征集,多次进行实验,利用sklearn的网格搜索(GridSearchCV)函数和随机搜索(RandomizedSearchCV)函数进行超参数集搜索,最后给出RMSE,MAE和R2对模型的评估结果。店铺1和店铺2实验模型的超参数集和预测结果评估指标分别如图7和图8所示。
对比各种组合下的预测结果,并结合店铺1和店铺2的实验结果可以看出,单模型预测结果均不如Stacking模型融合之后的预测结果好,说明单模型预测信息捕捉有遗漏,而Stacking模型融合了多个单模型信息捕捉能力,能够较好地弥补单模型特征抽取不足的问题。
其中,CART(原始特征+RF+SVR+LGBM+GRU)模型的预测效果最好,CART(原始特征+RF+SVR+ARIMA+LGBM+GRU)模型的预测结果次之,CART(无原始特征+RF+SVR+ARIMA+LGBM+GRU)的预测结果再次之,该模型预测效果比单模型效果最好的LGBM模型稍好,然后加入原始特征,模型预测效果又得到一定的提升,最后处理中去掉效果最差的ARIMA特征之后,模型预测效果又一次得到提升。
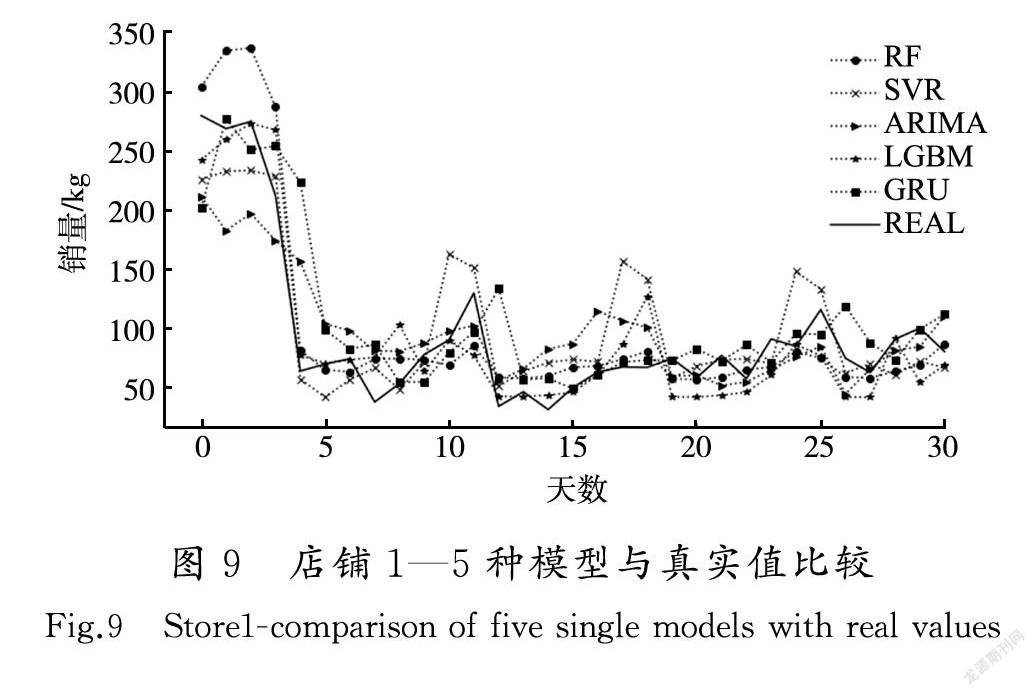
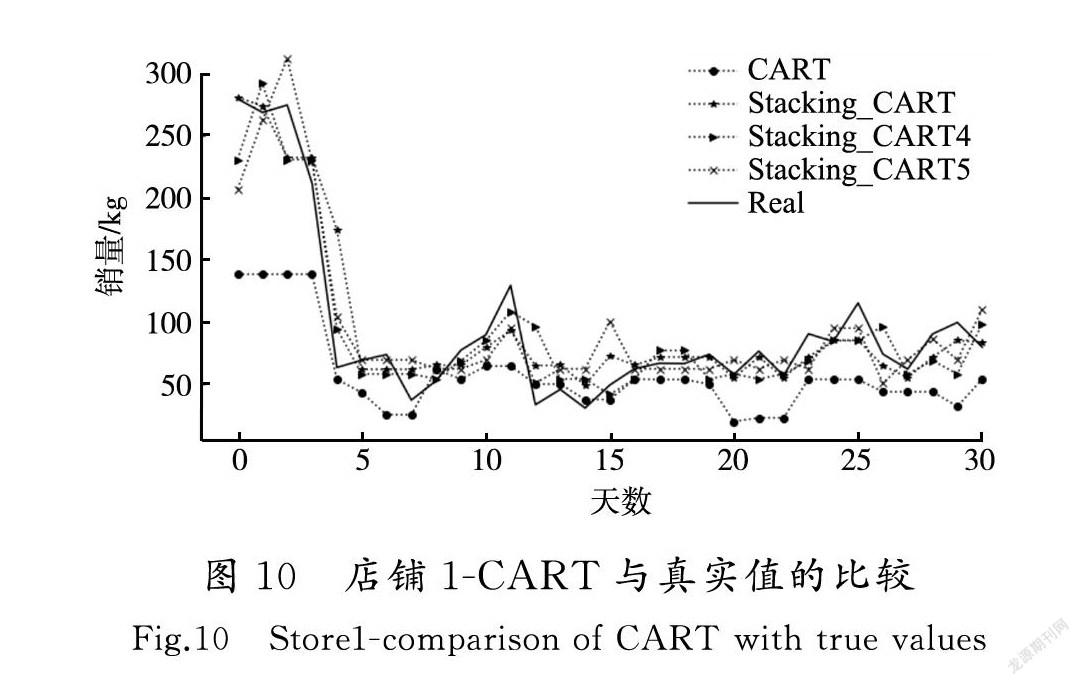
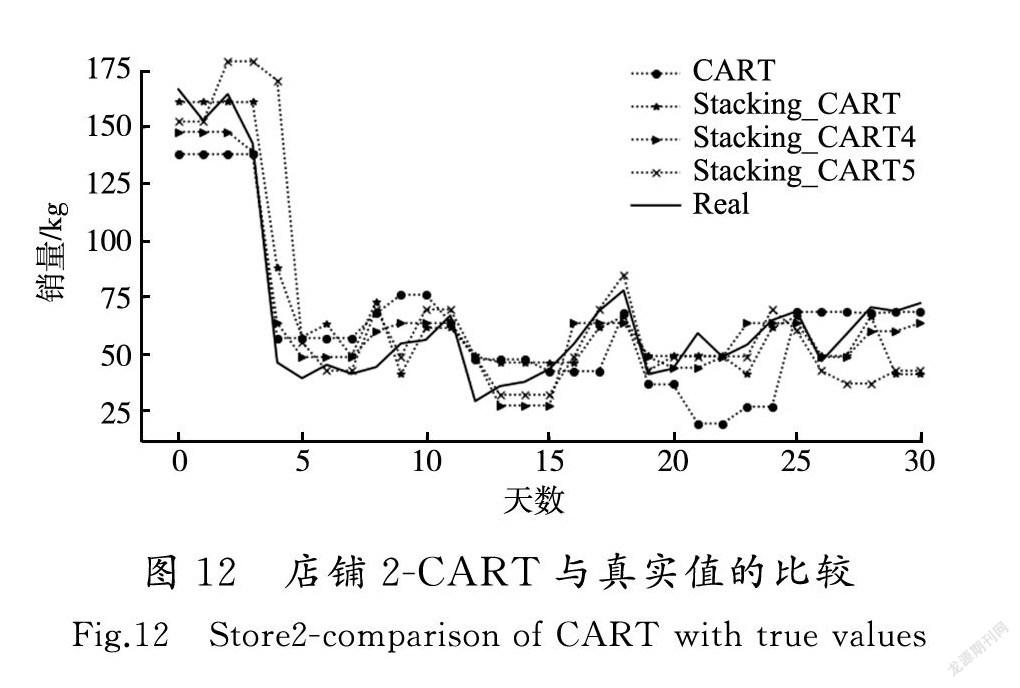
店铺1和店铺2的各种单模型和Stacking融合模型与真实值的差异对比如图9—图12所示。
从实验结果可以看到,Stacking融合模型整体上比单一模型预测结果更好,对一些波动较大点的预测,也比单一模型处理得更好,对于时间较长的预测点,比单一模型更准确。RMSE,MAE和R2的评估结果都分别优于任何单模型的评估结果。
CART(原始特征+RF+SVR+LGBM+GRU)模型的預测效果最好,说明Stacking融合模型适用于单模型预测效果较好的模型之间的组合,单模型预测效果差的模型,会影响Stacking融合模型最终的预测效果,选择合适的预测模型是Stacking融合模型预测效果好坏的关键。为了提升融合模型的效率,节省时间,Stacking融合模型并不是越多越好。实验结果显示:一味地增加融合模型的数量,对预测结果的提升非常有限,当融合模型提升效果不大的时候,为了提升模型预测效果,应该采取的措施是搜集更加精确的原始特征,而不应该再将精力放在融合更多的模型上。
4 结 语
现代企业中销量预测是货物供应的核心环节,对于合理控制生产成本,安排商品的生产计划,以及调整商品库存至关重要,是营销、物流、生产等环节的重要参考。本文设计了一个两层堆叠融合的销量预测模型来解决食品行业销量预测问题。模型第1层采用RF,SVR,ARIMA,LGBM,GRU 5种初级学习器, 模型将第1层5个初级学习器学习到的不同特征作为第2层的输入。CART作为次级学习器,使得Stacking模型预测准确性有了进一步提升。实验结果表明该模型在保证较高鲁棒性和泛化能力的同时,取得了比单一模型更好的预测结果。
在模型确定过程中对数据特征的计算也能帮助企业对产品特征的分析更加精细和准确。通过不同学习器对数据的处理可以进一步提炼原始数据的有效特征,为后续预测模型的完善提供支持。可以考虑在进一步研究中实验更多的方案来提炼更加有效的数据特征。目前特征较少是大部分企业在销量预测中面临的最大问题,如何采集更多准确、实用的特征是未来销量预测在实际应用中的重点。本文的Stacking模型融合使用多模型对数据进行分析,形成新特征加入到Stacking次级学习器之中,较好地弥补了原始数据集特征不足的问题。
为了提高预测准确率,下一步的研究工作将通过采取收集更多有效特征的方式,提高单模型的预测准确度,进而提高Stacking融合模型的预测效果。
参考文献/References:
[1] WOLPERT D H.Stacked generalization[J].Neural Networks,1992,5(2):241-259.
[2] 张宁.基于深度学习的连锁便利店销量预测的研究与应用[D].北京:北京工业大学,2019.
ZHANG Ning.Research and Application about the Forecasting for the Convenience-store Chain′s Sales Based on Deep Learning[D].Beijing:Beijing University of Technology,2019.
[3] 常炳国,臧虹颖,廖春雷,等.基于选择性集成ARMA组合模型的零售业销量预测[J].计算机测量与控制,2018,26(5):132-135.
CHANG Bingguo,ZANG Hongying,LIAO Chunlei,et al.Retail sales combination forecasting model based on selective ensembled ARMA[J].Computer Measurement & Control,2018,26(5):132-135.
[4] DUAN Zekun,LIU Yanqiu,HUANG Kunyuan.Mobile phone sales forecast based on support vector machine[J].Journal of Physics-Conference Series,2019,1229(1):012061.
[5] 梁超.基于Stacking模型融合的工程机械核心部件寿命预测研究[J].软件工程,2019,22(12):1-4.
LIANG Chao.Life prediction of construction machinery core components based on Stacking model fusion[J].Software Engineering,2019,22(12):1-4.
[6] CHEN Tianqi,GUESTRIN C.XGBoost:A scalable tree boosting system[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:Association for Computing Machinery,2016:785-794.
[7] KE Guolin,MENG Qi,FINLEY T,et al.LightGBM:A highly efficient gradient boosting decision tree[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems.Red Hook:Curran Associates Inc,2017:3149-3157.
[8] 杨荣新,孙朝云,徐磊.基于Stacking模型融合的光伏发电功率预测[J].计算机系统应用,2020,29(5):36-45.
YANG Rongxin,SUN Zhaoyun,XU Lei.Photovoltaic power prediction based on Stacking model fusion[J].Computer Systems & Applications,2020,29(5):36-45.
[9] 范红星.基于特征选择和Stacking框架的学生学业水平预测研究[D].长春:吉林大学,2020.
FAN Hongxing.Prediction of Students' Academic Level Based on Feature Selection and Stacking Framework[D].Changchun:Jilin University,2020.
[10]QUINLAN J R.Induction of decision trees[J].Machine Learning,1986,1(1):81-106.
[11]BREIMAN L.Classification and Regression Trees[M].Belmont:Wadsworth International Group,1984.
[12]邓威,郭钇秀,李勇,等.基于特征选择和Stacking集成学习的配电网网损预测[J].电力系统保护与控制,2020,48(15):108-115.
DENG Wei,GUO Yixiu,LI Yong,et al.Power losses prediction based on feature selection and Stacking integrated learning[J].Power System Protection and Control,2020,48(15):108-115.
[13]周志华.机器学习[M].北京:清华大学出版社,2016.
[14]王辉,李昌刚.Stacking集成学习方法在销售预测中的应用[J].计算机应用与软件,2020,37(8):85-90.
WANG Hui,LI Changgang.Application of Stacking integrated learning method in sales forecasting[J].Computer Applications and Software,2020,37(8):85-90.
[15]張雷东.氨纶产品销量预测技术的研究与应用[D].沈阳:中国科学院大学(中国科学院沈阳计算技术研究所),2020.
ZHANG Leidong.Research and Application of Spandex Product Sales Forecast Technology[D].Shenyang:University of Chinese Academy of Sciences(Shenyang Institute of Computing Technology,Chinese Academy of Sciences),2020.
[16]CHO K,VAN MERRIENBOER B,GULCEHRE C,et al.Learning phrase representations using rnn encoder-decoder for statistical machine translation[DB/OL].(2014-06-03).https://arxiv.org/abs/1406.1078.
