基于机器学习混合模型的滑坡易发性评价
2022-06-14邓念东李宇新崔阳阳石辉郭亚雷
邓念东, 李宇新, 崔阳阳, 石辉, 郭亚雷
(西安科技大学地质与环境学院, 西安 710054)
安康市汉滨区地处陕南秦巴山区,坡陡谷深,地质构造复杂,断裂发育,岩体破碎,松散堆积层广布,地质环境与自然生态环境脆弱,加之滥砍乱挖等不合理人为因素,致使地质环境严重恶化,滑坡、崩塌等地质灾害问题十分突出,严重威胁人民群众生命、财产安全,阻碍当地经济发展[1]。为提供该区域防灾减灾的基础依据,现开展汉滨区滑坡易发性评价研究。
自20世纪90年代以来,中外学者展开了大量滑坡易发性评价相关研究,主要集中在评价指标与评价方法的选择。评价指标通常结合研究区地质环境背景分析,目前尚无统一标准[2]。从评价方法上看,主要分为定性和定量模型[3]。定性评价采用专家经验进行指标权重赋值,适用于小区域滑坡易发性评价,但具有较强的主观性[4]。随着研究的深入,研究方法逐步向半定量以及定量模型过渡。许冲等[5]通过分析断层、岩性、高程、坡度、坡向、河流、公路7个因素与汶川地震区滑坡分布的关系采用层次分析法赋予因素权重,结果表明滑坡易发性分区效果较好,高易发区滑坡占比达到60.5%。牛瑞卿等[6]采用粗糙集理论对评价因子进行筛选,通过构建支持向量机模型对三峡库区秭归至巴东段进行滑坡易发性分区,结果表明预测结果与野外调查情况高度吻合,采用支持向量机进行评价预测能力强、效率高。Hong等[7]采用J48决策树进行构建自适应提升算法(adaptive boosting,Adaboost)、装袋算法(bootstrap aggregating,Bagging)及旋转森林模型,对抚州市广昌县滑坡易发性进行对比研究,结果表明三种模型在该区域评价精度均较高,其中旋转森林模型空间预测适用性更好。刘渊博等[8]采用旋转森林模型对三峡库区万州段滑坡易发性进行研究,结果显示滑坡高易发区主要集中在万州主城区和长江及支流两岸,模型预测精度达90.7%,再次体现机器学习模型预测精度高的特点。连志鹏等[9]分别采用信息量、证据权和频率比模型进行五峰县滑坡易发性研究,并通过归一化、主成分分析和优势融合,研究表明多模型混合是一种新的评价思路,其分区结果比单一模型更精确。基于前人研究成果,以随机森林为代表的集成学习模型在滑坡易发性评价中被广泛采用,为进一步验证混合模型在滑坡易发性评价的泛化能力,现选取集成学习中具有代表性的自适应提升与随机森林模型,分别进行单一模型与混合模型评价,采用受试者工作特性曲线(receiver operating characteristic curve,ROC)验证其预测效果,通过随机森林模型降低自适应提升模型训练误差为滑坡易发性评价方法的改进提供新的思路。
1 研究方法
1.1 自适应提升模型
自适应提升模型由Freund和Schapire率先提出,是一种解决二分类问题的集成学习算法,属于经典集成学习算法Boosting算法族种的一类[10]。核心思想是通过一个基分类器得到二分类预测结果,根据分类结果计算加权训练误差,若误差大于0.5,重复在训练集重新生成均匀的权值分布直到误差满足小于0.5。再根据满足误差要求的分类结果对每个训练样本的权值进行调整,使得错误分类样本的权值提高。最终使用加权多数投票规则对基分类器的分类结果进行组合得到各评价单元的滑坡易发性指数(landslide susceptibility index,LSI)。
1.2 随机森林模型
随机森林模型是集成学习Bagging算法族的代表算法[11]。首先,对初始训练集进行多次bootstrap随机抽样。每次bootstrap随机抽样是指对于有放回的随机抽样所组成的新训练样本集与初始一致。通过构建决策树作为基分类器,采用信息增益率在属性集合中随机候选最优分裂属性子集,对每个不同的新训练样本集进行训练,通过样本与分裂节点的多样性,从而提高分类的预测准确率。最终通过简单多数投票原则对各训练样本的结果整合。
2 研究区概况及数据源
安康市汉滨区位于陕西省南部山区,108°30′E~109°25′E,32°22′N~33°17′N,辖内共34个乡镇(街道),总面积为3 643.5 km2(图1)。研究区地势南北高,中部低,最高点为秦岭佛爷岭,高程2 135 m,最低点为汉江彭家沟,高程134 m,相对高差2 001 m。地处北亚热带湿润季风气候区,具有明显的垂直地带性特征。平均气温15.5 ℃,南北山区气温低,中部河谷与丘陵区气温高。区内降水具有空间和时间分布不均的特点:多年平均降水量799.3 mm,总的趋势为自北向南逐渐递增;降水量年际变化大,70%年内降水集中在7—9月。研究区内河流密集,汉江横贯研究区南部。区内主要出露地层有震旦系白云母石英片岩、寒武系炭质片岩、奥陶系灰岩、志留系千枚岩、泥盆系钙质片岩、新近系细砂岩和第四系粉土。

图1 研究区位置及滑坡编录图Fig.1 Location of study area andlandslide catalog
根据《汉滨区地质灾害详细调查报告》(以下简称《详查报告》)和解译研究区遥感影像,在实地调查的基础上,共圈定509处滑坡。使用地理信息系统(geographic information system,GIS)将滑坡周界转为滑坡点,生成滑坡编目图,区内各行政单元滑坡密度统计如表1所示。滑坡影响因子数据主要由以下方式获取:①通过“地理空间数据云”平台下载研究区30 m分辨率的数字高程模型(digital elevation model,DEM)数据,使用表面分析工具获取坡度、坡向、曲率和地表切割深度因子;②通过矢量化《详查报告》中1∶50 000地质图得到地层岩性、断层数据;③通过清华大学2017年全球地表覆盖监测数据获取研究区土地利用数据;④通过研究区气象站观测数据获取多年平均降雨量数据;⑤通过“Bigemap”地图软件获取研究区行政单元划分、水域及道路矢量化数据。
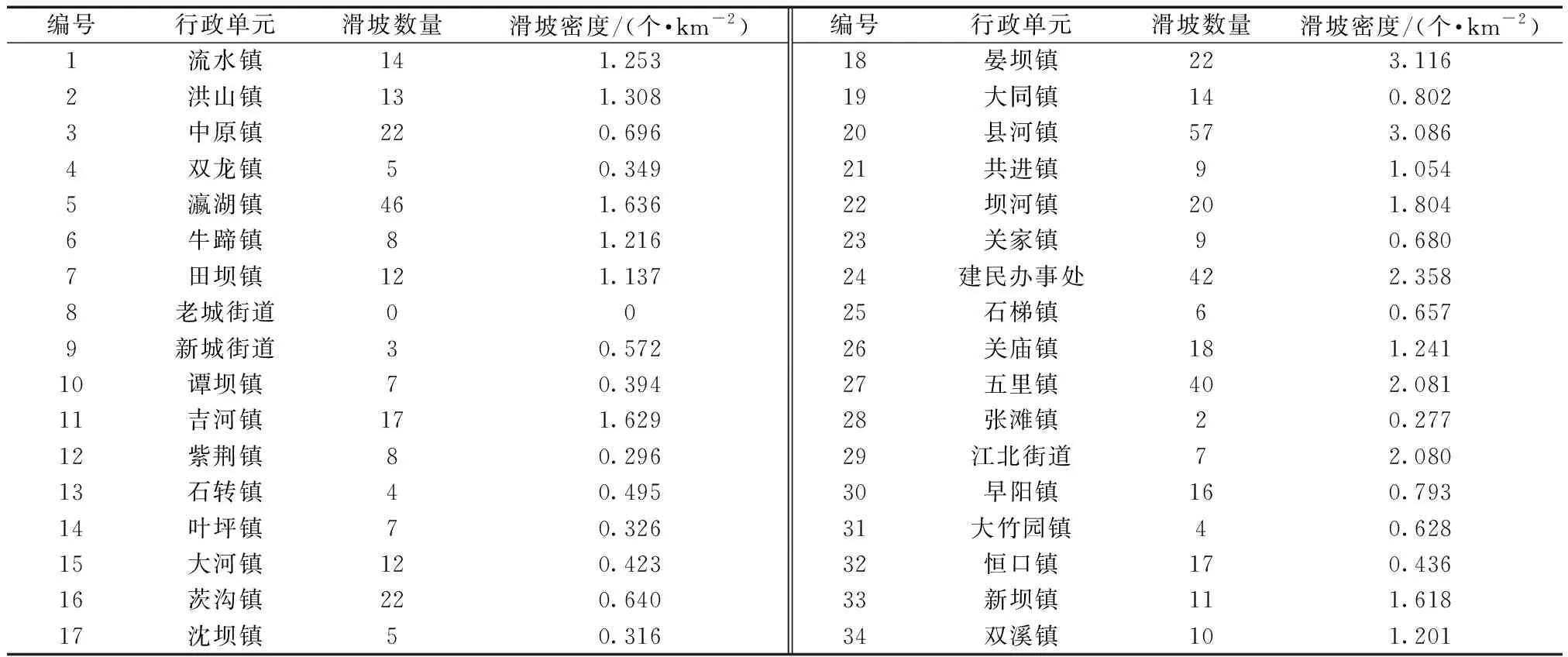
表1 研究区各镇(街道)滑坡统计Table 1 Landslide statistics of towns (streets) in the study area
3 评价因子的选取
3.1 影响因子选取
参照《详查报告》中研究区地质环境背景与地质灾害形成条件,区内滑坡主要取决于地质环境条件内外力因素共同作用,包括地形的控制、断层活动的地形改造、低强度的破碎岩石及地表水的侧蚀等。从上述数据源中初步选取高程、坡度、坡向、年均降雨量、地层岩性、平面曲率、剖面曲率、土地利用、地表粗糙度、地表切割深度、地形湿度指数(topographic wetness index,TWI)、距断层距离、距道路距离和距水系距离,在ArcGIS中采用自然间断法生成研究区影响因子专题图(图2)。
3.2 影响因子分析
进一步定量分析研究区滑坡影响因素,可削弱无关因子对评价的不利影响,亦对区内滑坡调查具有借鉴意义。信息增益比是统计学进行特征不确定性选择的方法,本文用来分析所选因子的重要性[12](图3)。结果显示,所选影响因子与研究区孕灾均有一定关联,其中土地利用、高程、地表切割深度、粗糙度、坡度以及地层岩性对滑坡产生更加密切。频率比分析显示区内滑坡主要分布在耕地与林地、高程介于134~737 m、地表切割深度介于2.65~83.83 m、粗糙度介于1~1.05、坡度介于10.1°~25.6°及地层为志留系云母石英片岩的区域。
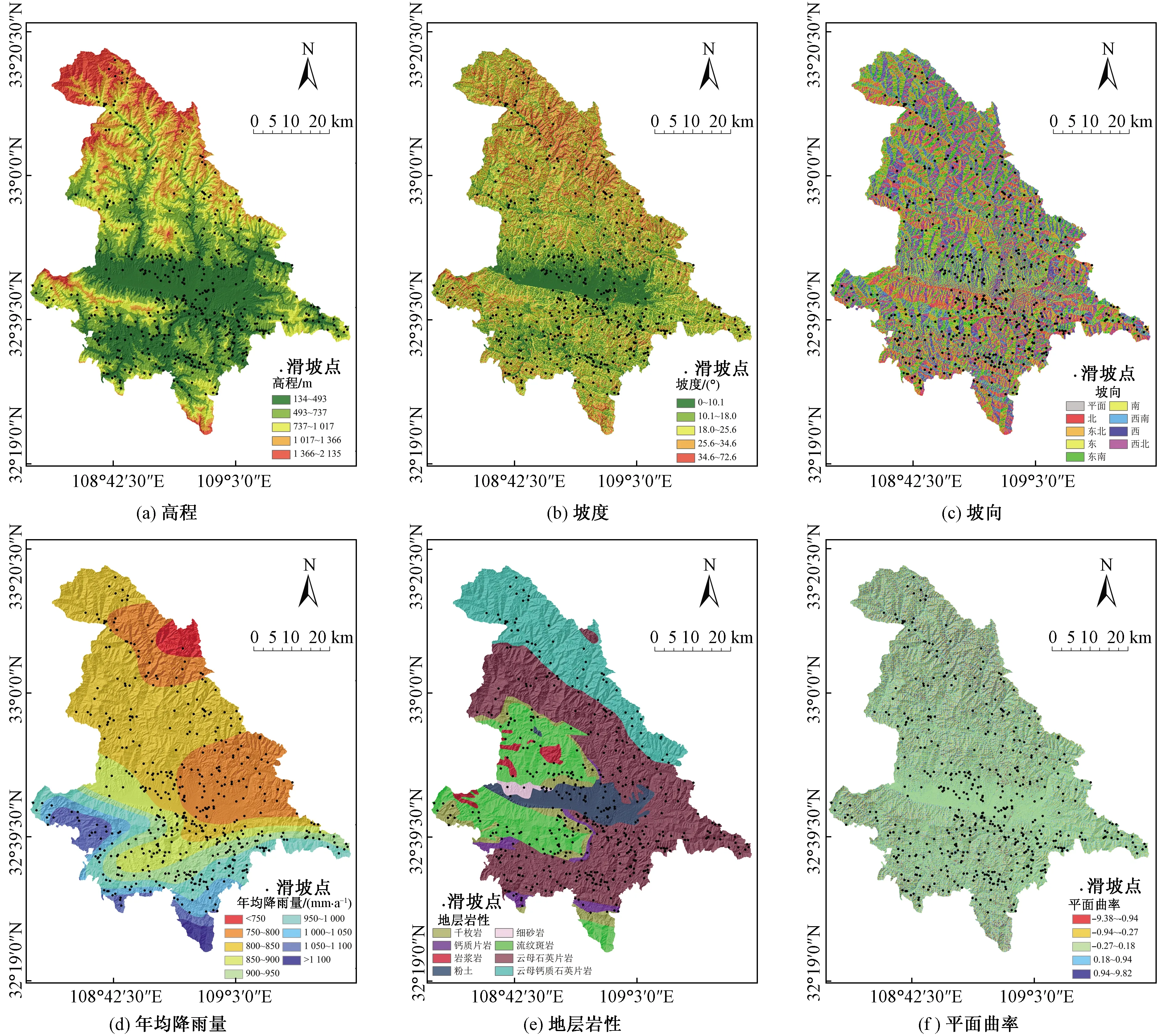

图2 研究区因子专题图Fig.2 Study area factor thematic map
机器学习模型对样本数据集有一定共线性要求,数据间的共线性易造成模型训练精度下降[13]。通过SPSS软件进行方差膨胀因子分析(variance inflation factor,VIF)。当VIF大于10时,表示数据间存在严重的共线性,需要进行剔除。分析结果如表2所示,剔除粗糙度属性(VIF为10.966),最终采用剩余13类因子进行评价。
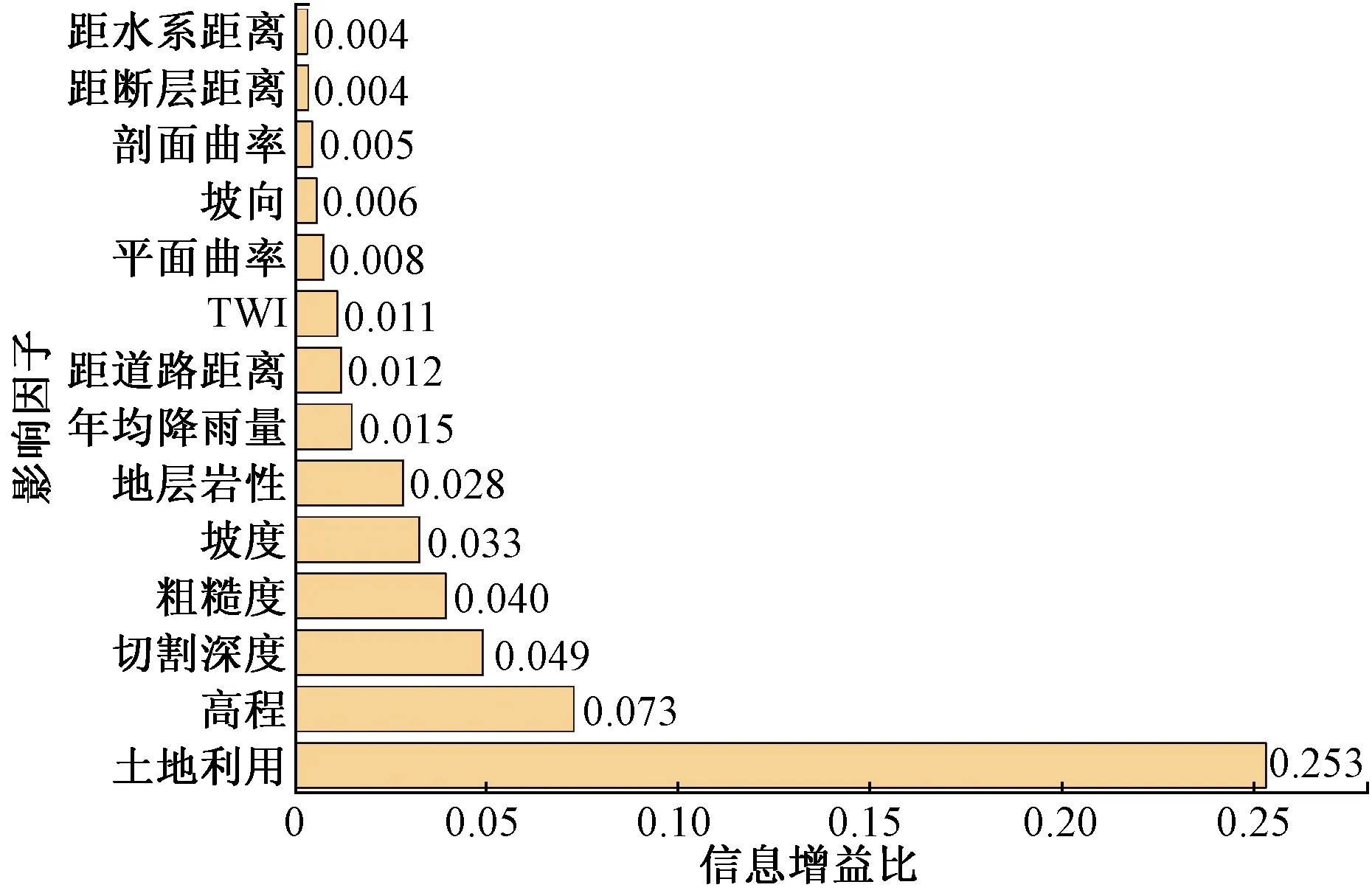
图3 影响因子信息增益比Fig.3 Impact factor information gain ratio
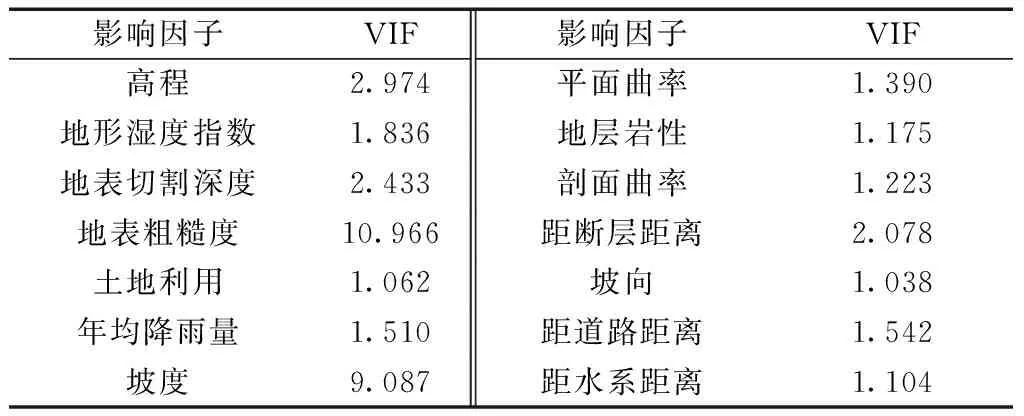
表2 影响因子共线性分析Table 2 Collinearity analysis of impact factors
4 滑坡易发性评价
采用30 m×30 m栅格作为评价单元[14],研究区共被划分为4 049 150个单元。在滑坡范围外随机提取等量的非滑坡数据,与滑坡数据组建样本数据库[15-16],随机选择70%(712处)作为训练集,其余30%(356处)作为验证集,将研究区所有栅格数据作为验证集。怀卡托智能分析环境(waikato environment for knowledge analysis,WEKA)是集数据处理、学习算法与评估方法为一体的数据挖掘工具,本文研究借助该软件构建自适应提升、随机森林模型以及基于两者的混合模型。
4.1 基于自适应提升模型的滑坡易发性评价
使用AdaboostM1算法构建自适应提升模型,基分类器选择C4.5决策树,它基于最大化标准化信息增益的属性的选择构造决策树,树进行修剪并且置信因子设置为0.25。模型迭代次数为10次,训练集正确率为76.9%,验证集预测率为75.3%,代入验证集得到基于自适应提升的LSI。采用自然间断法分为低易发区(0~0.258)、中等易发区(0.258~0.738)和高易发区(0.738~1),得到基于自适应提升模型的滑坡易发性图,如图4(a)所示。
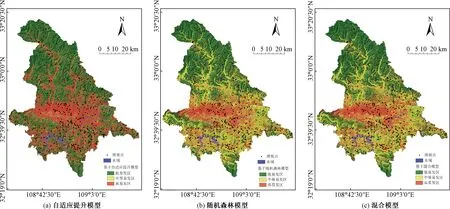
图4 基于三种模型的滑坡易发性图Fig.4 Landslide susceptibility mapping based on three models
4.2 基于随机森林模型的滑坡易发性评价
在WEKA中选择随机森林算法,迭代次数为100次,通过十倍交叉验证进行训练,正确率为83.0%,验证集预测率为80.1%。得到基于随机森林的LSI值后,重分类为低易发区(0~0.316)、中等易发区(0.316~0.656)和高易发区(0.656~1),从而生成基于随机森林模型的滑坡易发性图,如图4(b)所示。
4.3 基于混合模型的滑坡易发性评价
将随机森林模型作为自适应提升模型的基分类器,调整上述参数,以此构建混合模型。同样代入训练集进行十倍交叉验证训练,正确率为82.6%,验证集预测率为80.8%。将LSI值分为低易发区(0~0.316)、中等易发区(0.316~0.656)和高易发区(0.656~1),生成基于混合模型的滑坡易发性图,如图4(c)所示。
对比三种模型的滑坡易发性图,自适应提升模型的分区结果较为极端,受权值调整影响主要集中分为低易发区和高易发区,中易发区较少。随机森林与混合模型的易发区分布规律基本一致。
(1)高易发区主要集中在区内中部恒口镇、大同镇、五里镇、建民办事处、江北街道及关庙镇6处区域,该区域出露地层为志留系千枚岩与新近系细砂岩,岩质软弱,节理裂隙发育。坡体覆盖第四系破残积土及粉土,结构松散,平缓处均开发为耕地,人类活动强烈,道路工程与房屋修建密集。
(2)中易发区主要位于区内北部、中南部中山及低山丘陵区。北部包括大河镇、谭坝镇、双溪镇等,该区域沟谷纵横,多呈V形,滑坡沿道路与水系发育。中南部包括瀛湖镇、县河镇、关家镇等,主要地层为震旦系云母石英片岩、流纹斑岩及志留系千枚岩,岩性弱、易风化,道路与水系密集,为孕灾提供了基础条件。
(3)低易发区主要分布于区内南北端及东南端,包括叶坪镇、中原镇、紫荆镇、早阳镇、双龙镇等地区。该区域地势较高,降水充沛,主要用地为林地,人口分布较少,滑坡发生频率少。
对上述三种区划结果进行易发性等级统计(图5),三种模型的滑坡密度随之易发性等级的提升而增加,证明分区结果符合历史滑坡分布。其中混合模型的滑坡密度在高易发区达到1.94,同比高于自适应提升模型(1.68)和随机森林模型(1.86),说明混合模型较单一模型对研究区滑坡预测更加敏感,也体现出对单一模型进行混合提高了预测能力。
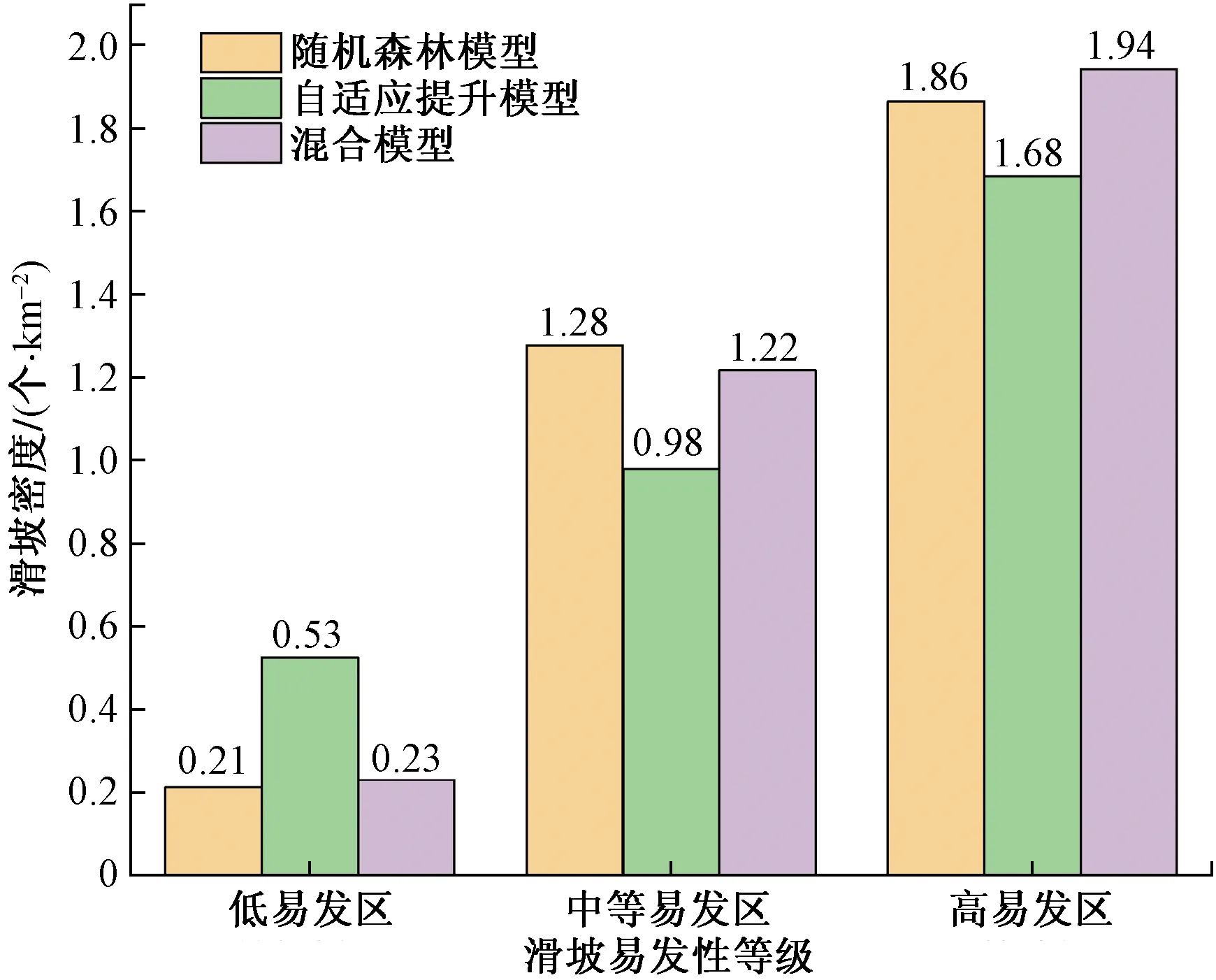
图5 各模型滑坡易发性等级统计Fig.5 Landslide susceptibility grade statistics of each model
4.4 模型精度比较
接受者操作特性曲线(receiver operating characteristic,ROC)被广泛应用于模型对比评价,其线下面积(area under curve,AUC)取值介于0~1,值越大代表预测精度越高[17-18]。通过统计各模型的敏感度(即预测为滑坡的滑坡样本)和1-特异性(即预测为滑坡的非滑坡样本)生成ROC曲线(图6)。由表3可以看出,混合模型的训练集与验证集AUC值均高于单一的自适应提升模型和随机森林模型,95%置信区间结果与AUC值一致,说明混合模型预测精度最高,其区划结果可靠性高。

图6 各模型ROC曲线对比Fig.6 Comparison of ROC curves of each model
4.5 典型滑坡验证
在模型评价与统计的基础上,针对混合模型的区划结果,选择区内檬树垭滑坡、李典前房后滑坡以及桑树埫滑坡共三处滑坡进行对比验证[19],如图7所示。
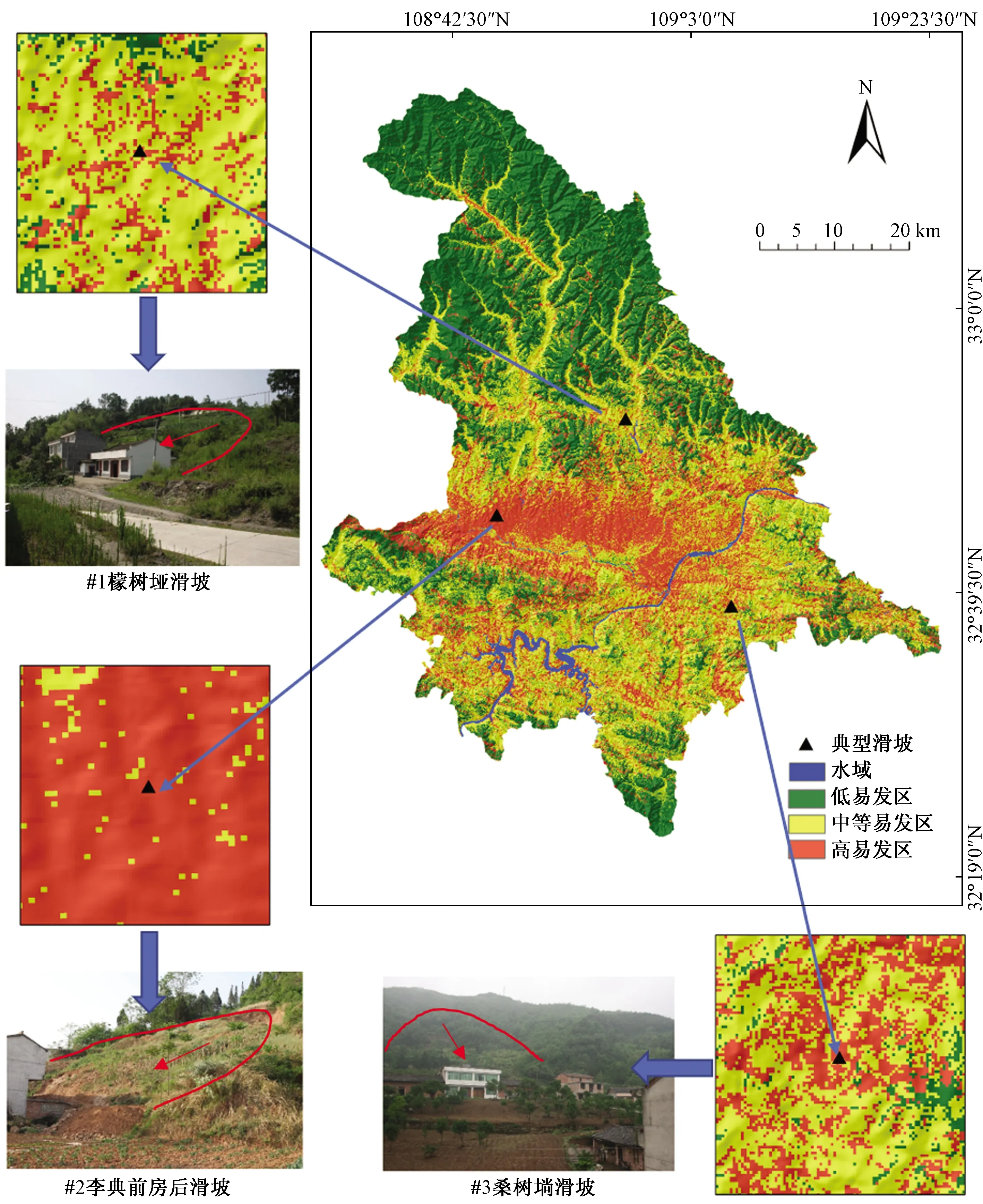
图7 典型滑坡验证Fig.7 Typical landslide verification
檬树垭滑坡位于谭坝镇后沟村1组,属基岩顺层滑坡,滑体长200 m,宽100 m,平均厚10 m,体积约2×105m3,规模为中型,滑向30°;滑面为片岩层,呈弧型;滑体为残坡积层和志留系强风化片岩,产状30°∠50°,滑坡后壁高约5 m,坡体整体滑动可能性较大。
李典前房后滑坡位于恒口镇青龙村7组,属低山丘陵地貌,滑体为下新近系砂岩与泥岩互层,及其上覆厚约2 m的第四系中下更新统冲洪积含砾砂质黏土,基岩产状180°∠20°;坡上为坡耕地,坡度30°,坡高约30 m,为基岩顺层滑坡;因建房开挖坡脚形成高约1.5 m陡坎,滑体下滑,水平移动约15 m。

表3 模型精度评价Table 3 Evaluation of model accuracy
桑树埫滑坡位于县河镇红霞村1组,地处低山地貌、浅凹槽地形,坡体上陡下缓,坡度约35°,上部陡坡树木茂密,下部为坡耕地,住户紧邻坡脚,房前为大面积平缓坡地。滑体为残坡积层,下伏基岩为志留系千枚岩,产状90°∠45°。后缘坡体高陡,局部下错明显,残坡积层从上往下依次变厚,前缘临空面较大,住户紧邻坡脚,坡体滑动可能性大。
对比图4(c),三处历史滑坡均位于区划图中高易发性区域,再次验证基于该混合模型区划结果的可靠性,其结果可作为相关部门进行区域滑坡防治的借鉴。
5 结论
提出了基于自适应提升-随机森林混合模型进行滑坡易发性评价,主要有以下结论。
(1)结合研究区地质环境背景与地质灾害形成条件选取高程、坡度、坡向等13类影响因子。采用信息增益比进行因子重要度分析,结果显示土地利用、高程、地表切割深度、粗糙度、坡度以及地层岩性与研究区滑坡发生更密切,主要分布在耕地与林地、高程介于134~737 m、地表切割深度介于2.65~83.83 m、粗糙度介于1~1.05、坡度介于10.1°~25.6°及地层为志留系云母石英片岩的区域。
(2)采用WEKA软件分别构建自适应提升、随机森林以及混合模型。ROC曲线表明,三种模型预测分类拟合程度较好,正确率均较高,其中自适应提升-随机森林混合模型的训练正确率和验证预测率均高于单一模型,进一步验证混合模型较单一模型具有更高的泛化能力,为滑坡易发性评价模型的选择提供了新方法。
(3)通过对比各易发性等级的滑坡密度,混合模型高易发区滑坡密度最高;同时通过研究区三处滑坡对混合模型的易发性区划结果进行验证,表明其评价结果可靠性高,易发性区划图可作为当地相关部门进行防灾减灾的参考依据。
