基于改进的YOLO v3的遥感图像目标检测
2022-06-14曲振方朱福珍
曲振方, 朱福珍
(黑龙江大学 电子工程学院, 哈尔滨 150080)
0 引 言
目标检测是遥感和计算机视觉领域急需解决的问题,通常将其定义为输入图像中的位置识别目标对象以及对象类别识别。如今,目标检测技术已广泛应用于环境监管、灾难评估、军事调查和城市规划等实际应用中[1-2]。无论是针对人造物体(如车辆、建筑物、道路和桥梁等),还是自然物体(如湖泊、海岸和森林等),目标检测算法都得到了广泛的研究,已经出现了大量算法来检测它们。现有的遥感影像目标检测算法大致可分为四类:(1)基于模板匹配的方法;(2)基于知识的目标检测方法;(3)基于目标分析的目标检测算法;(4)基于机器学习的方法[1]。在上述方法中,基于机器学习的方法由于其强大的鲁棒性而受到了许多学者的青睐,取得了突破性的发展[3-6]。
由于卷积神经网络(Convolutional neural networks, CNN)的出现,基于机器学习的目标检测算法得到了进一步的发展,引起了计算机视觉领域的广泛研究,尤其是在目标检测方向上。CNN模型具有强大的特征提取能力和优越的性能,因此涌现了大量基于CNN的目标检测算法,并将这些算法应用于光学和遥感图像的目标检测。随着基于卷积神经网络的目标检测算法的发展,目标检测算法大致可分为两类:(1)一种方法是两阶段目标检测算法。该样本首先生成一个候选框,然后由卷积神经网络进行处理。 该方法的优点是检测精度高,可以准确定位物体,具有代表性的算法有Fast R-CNN[7]和Faster R-CNN[8];(2)另一种方法称为单阶段检测方法,即将目标边界位置的问题直接转换为回归问题,然后通过卷积神经网络进行处理。该方法具有较快的运算速度,代表有SSD[9]、YOLO[10]、YOLO 9000[11]和YOLO v3[12]等算法。在遥感图像研究领域,国内外学者也已经开始在深度学习的基础上进行研究。尽管基于深度学习的对象检测方法取得了突破,但这些方法仍存在一个亟待解决的问题:对于大规模的遥感图像,某些目标仅占据了几个像素。这些相对较小的目标容易在训练过程中丢失,可能会错过一些关键目标信息。 因此,对于遥感图像目标检测,需要一种对小目标具有高检测精度和快速检测的方法。小目标检测是计算机视觉领域的热门话题,已应用于场景分类[13]和目标检测[14-15]等方向。现有的小目标物体方法被设计用于使用单尺度检测网络对光学图像中的常见物体进行检测(如汽车、自行车和建筑物)。这些共同物体的背景相对简单,而在遥感图像中,要检测的目标通常是在更复杂的场景中,这使得检测小目标更加困难。
当在遥感图像中进行目标检测时,遥感图像的拍摄范围较大,其范围10~30 km,面对如此大的拍摄范围,一些相对较小的物体,如汽车、轮船和飞机等,仅占据图像中的几个像素,导致在检测遥感图像时出现漏检和误检的概率很高。在保证准确性的基础上,还需要保证遥感图像的实时检测。但是,用于遥感图像检测的YOLO网络的性能并不理想。因此,遥感图像目标检测是一个非常具有挑战性的课题。
针对上述问题,提出了一种基于改进的YOLO v3算法的辅助网络来检测遥感图像。首次将带有辅助网络的YOLO v3模型应用到遥感图像目标检测。使用的方法包括两个主要的组成部分:辅助网络和连接辅助网络的SE注意力机制模块,这两个模块的作用旨在增加网络的特征提取能力,使得YOLO v3模型能够检测出更多的目标。整个实验在DOTA数据集中验证,并充分证明了改进之后的网络在性能上有所提高。
1 方 法
遥感图像的目标检测需要确保其检测的实时性和准确性,但是两阶段基线的检测速度相对较慢,因此选择了在检测性能和速度上适用的YOLO v3算法。遥感图像中的许多目标信息仅占用几个像素,但是YOLO v3 算法在提取特征时容易丢失一些相对较小的图像信息,因此,本文的目的是提高YOLO v3算法在提取遥感图像中相对较小目标信息时的鲁棒性。
1.1 辅助网络
YOLO v3算法的特征提取网络采用的是Darknet-53的网络,它深层的采样采用的是残差结构的形式。残差结构的内部相对来说比较简洁,使得整个网络更加容易被使用,但是特征提取的能力还没有被优化。残差模块的出现能够使得网络的深度变得更深。目前,网络设计的方法通常依赖于更多的网络层去提取目标特征而且去丰富卷积层语义信息以提升检测的准确率。然而对于检测小目标,在图像有限的像素区域,小目标尺寸小,在神经网络中进行多次下采样操作之后,这些区域的特征将会减小,特征的表达能力也会随之下降,会变得更加不容易被网络所学习。针对这一问题,本文采用加入辅助网络的方法改进特征提取网络,改进主干网络的主要方式是整个网络通过“拷贝”的残差模块,通过复制的方式微调(Fine-tune)残差模块的结构。优化网络的结构如图1所示。
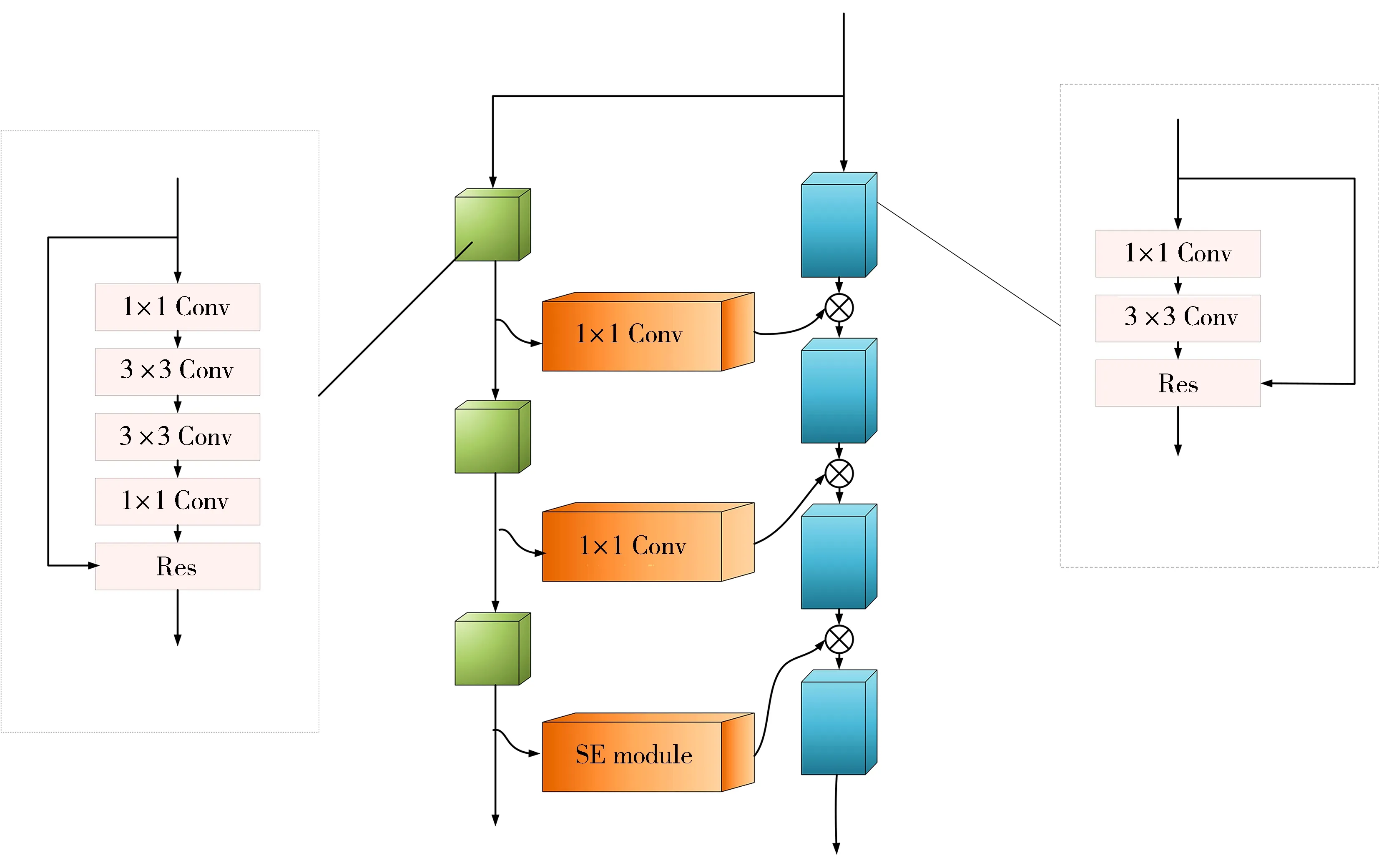
图1 加入辅助网络的特征提取网络
与原始的网络结构相比,本文采用了增加一个特征提取辅助网络,具有比主干网络更小尺寸的网络和在主干网络旁边支路上的多个残差块组成。辅助网络的残差模块是相较于YOLO残差模块的提升。原始的残差模块使用3×3的卷积核去执行特征提取的操作,尽管辅助网络中的残差模块使用的是两个连续的3×3的卷积核去获得一个5×5的感受野,之后提取的特征将会在主干网络中进行合并。在辅助网络中所使用的感受野是5×5。使用一个大的感受野,如5×5的感受野在特征映射上表现全局特征提取,可以获得整个区域的目标特征。辅助网路传送获取的局部特征到主干网络,由主干网络结合目标局部信息所使用的3×3的感受野可以使得经由辅助网络学习目标特征更加准确。辅助网络使整个网络结构在一定程度上更紧密地与高级和低级语义特征相关,这样可以显著提高网络的检测性能。这种增加辅助网络改进特征提取的方法将会产生更多计算量,从而导致运行速度变慢。在改进特征提取网络的基础上,为了兼顾运行速度,仅增加辅助网络到YOLO v3算法三个相关尺度检测的特征提取层。
1.2 SE注意力机制的应用
由于遥感图像中背景占据一张图片中的很大比例,而且往往需要检测的目标很小,为了防止数据冗余,让网络学习到特定目标的特征,故本文引入注意力机制。引用注意力机制连接主干网络和辅助网络的方法分为两步:第一步是辅助网络的输出模块最开始是通过1×1的卷积核触发的,然后传送到主干网络;第二步是在两个网络之间加入注意力机制。当网络到达特定的深度,语义信息可以变得更强烈,辅助网络可以集中于处理和传送有效的特征,而且信道还可以抑制无效的特征。在两个网络之间所使用的注意力机制应用的是SE模块,这个模块非常容易被部署。SE模块注意力机制如图2所示。结构中增加了SE模块的目的是为了校准辅助模块的输出。流程图可以简单地分为压缩和激励两部分,首先特征映射被压缩,然后两个维度的特征信道被平均池化成一维特征映射。此时特征映射的尺寸被转化成1×1×C。

图2 SE注意力机制
通过池化把二维特征映射转化成一维特征映射的目的是更好地展示这一层每一个信道的特征值的分布。特征映射压缩完成之后,一维的特征将会被激励,计算公式如下:
Sc=Fex(Z,W)=σ(g(Z,W))=σ(W2σ(W1Z))
(1)
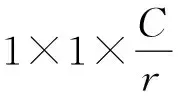
Sc是连接模型的关键,常被用来表明辅助网络输出信道的权重。Sc是经由S函数激活,取值范围0~1,表明每一个信道的重要程度。用Sc和Uc的结果去获得最后的重定向特征图,计算公式为:
Xc=FScale(Uc,Sc)=Sc·Uc
(2)
通过多个不同信道的不同权重,集中注意力于可以增加对关键通道域的关注。辅助残差模块通过SE模块重定向,然后进入骨干网络以完成特征融合。
2 评价指标
本文测试所依据的评价指标主要包括准确率、回召率、mAP(mean Average precision)、AMC(Average minimum confidence)和 Loss(Missed detection rate)。在这些评价指标中,平均最小置信度常常被用于评估一个特定的多类别目标算法的分类性能,误检率常常被用于测试与检测目标框架有关的算法的性能。评价指标的公式为:
(3)
(4)
式中:TP代表正样本被正确的分类;FP代表正样本被错误分类;FN代表负样本被错误的分类。
(5)
(6)
式中:Nc代表目标的类别;N代表图片的数量。
(7)
式中MC代表在一张图片里一个确定的目标被正确检测的最低置信度。
(8)
式中:NB代表在图片里所有目标的数量;NM代表未被检测到的目标数量。
3 实验数据结果分析
所有实验均在计算机上实现,该计算机采用2.40GHz@IntelXeon© CPU E5-2640 v4,两块NVIDIA GeForce RTX 2080 Ti和32 GB内存。本实验中使用的DOTA数据集包含2 806个遥感图像,并包含15个类别中的188和282个实例。标记方法是由4个点确定的任何形状和方向的四边形(不同于传统平行边界框)。 共有15个图像类别,其中包括14个主要类别。数据集分为1/6验证集、1/3测试集和1/2训练集。300个样本被用于测试,并且同原始的YOLO v3算法、带有辅助网络的YOLO v3算法在DOTA数据集进行横向比较。原始的YOLO v3算法及本文所改进的YOLO v3算法比较结果如表1所示。通过比较表1得到的数据可知,所使用的YOLO v3优化算法比起原始的YOLO v3算法在准确率上和回召率上都有所提升。

表1 优化的YOLO v3和原始的YOLO v3模型 / %
从表2可以看出,与传统的YOLO v3算法相比,所提出的方法在总精确度上有着更好的效果(90.55%)。相比传统的YOLO v3算法提高了8.68%。从单类别看,本方法在飞机、船、集装箱、桥梁、汽车和直升机等几类小目标检测中表现更好,对于网球场、棒球场等几类相对较大目标,传统YOLO v3算法表现更好,但相差不大。

表2 DOTA数据集上各类别目标检测精度 / %

BridgeLarge-VehicleSmall-VehicleHelicopterRoundaboutSoccer ball filedBasketball courtmAPYOLO v370.2479.1768.2378.6769.8990.5492.2981.87OUR-YOLO v390.3689.2585.4189.4782.4991.8395.1290.55
将改进的网络和一些典型的One-stage和Two-stage网络进行比较,使用DOTA数据集进行测试,来比较它们的准确率和检测时间,结果如表3所示。

表3 和常见网络之间的速度和准确率的比较 / %
PFP-Net和SINPER-Net网络都是近年来表现较好的网络,PFP-Net属于One-stage的网络。从结果上来看,改进的YOLO算法比PFP-Net有着更高的准确率和时间,其速度是近乎相同的。尽管SINPER-Net是一个Two-stage的网络,改进之后的YOLO v3算法准确率只比其低了0.78%,但是检测速度更快了,表明改进之后的YOLO v3算法在检测准确率和性能上获得了很好的提升。
4 实验效果对比分析
在DOTA数据集上进行了大量实验,针对原始YOLO v3算法和改进后的YOLO v3算法进行效果对比。选取图片如图3~图5所示,其中图3(a)、4(a)和5(a)所示为原始YOLO v3算法的检测结果,图3(b)、4(b)和5(b)所示为本文算法的检测结果。
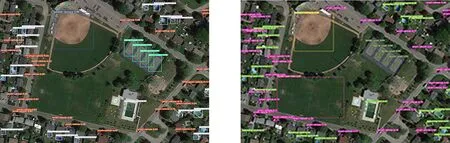
(a) 原始YOLO v3算法检测结果 (b) 改进的YOLO v3算法检测结果

(a) 原始YOLO v3算法检测结果 (b) 改进的YOLO v3算法检测结果

(a) 原始YOLO v3算法检测结果 (b) 改进YOLO v3算法检测结果
对图3~图5的检测结果进行对比分析,可以看出,原始的YOLO v3算法对目标漏检情况严重,但本文所使用的方法可以很好地检测出原始YOLO v3算法所不能检测出的目标。在复杂的场景下,改进的YOLO v3算法仍然可以准确检测出目标。从以上数据分析及效果图可以看出,改进的YOLO v3算法比原始的YOLO v3算法准确率更高,预测的Bounding boxes位置比原始的YOLO v3算法更准确,证明使用辅助的特征提取网络的方法可以帮助学习和定位特征,使得网络的鲁棒性更强。
5 结 论
介绍了基于改进的YOLO v3算法的遥感图像目标检测,针对原始YOLO v3算法在遥感图像上效果不好的问题进行了改进。基于YOLO v3的模型,使用了双重的特征提取网络,在主干网络配置了不同感受野的特征提取辅助网络,采用注意力机制用于主干网络和辅助网络之间的信息融合。它集中注意力于有效的特征信道,抑制无效的特征信道,提升网络处理的有效性。在DOTA数据集上,充分验证了本方法,相较于原始的YOLO v3 mAP增加了8.68%,而且相较于一些比较出名的网络结构,有着速度与准确率上的双重优势。
