基于特征选择和CNN+Bi-RNN模型的小麦抗寒性识别方法
2022-06-12金松林来纯晓郑颖李艳翠霍云凤刘明久4张自阳韩博闫思尧李龙威
金松林 来纯晓 郑颖 李艳翠 霍云凤 刘明久4 张自阳 韩博 闫思尧 李龙威






摘要:针对当前小麦抗寒性识别方法受限、资源消耗严重等问题,以国审小麦品种的文本数据为研究对象,利用特征选择算法和深度学习方法实现小麦抗寒性识别研究。首先,使用集成学习中的自适应增强(adaptive boosting,简称AdaBoost)算法和极端梯度提升(extreme gradient boosting,简称XGBoost)算法进行特征选择;然后,将卷积神经网络(convolutional neural networks,简称CNN)抽取的局部特征和双向循环神经网络(Bi-direction recurrent neural network,简称Bi-RNN)抽取的上下文特征融合,构建基于CNN+Bi-RNN的小麦抗寒性识别模型,通过试验表明选择15个特征时CNN+Bi-RNN方法的准确率、F1值和Kappa系数最高,分别为0.789 8、0.810 2和0.602 7。最后,使用合成少数类过采样技术(synthetic minority over-sampling technique,简称SMOTE)对样本均衡化处理,处理后训练模型的准确率均有所提高,其中CNN+Bi-RNN模型的准确率达到0.829 2。该方法能够较好地识别小麦抗寒性,提高育种效率。
关键词:小麦;抗寒性识别;特征选择;CNN+Bi-RNN;样本均衡化
中图分类号:TP391.4;S126 文献标志码: A
文章编号:1002-1302(2022)10-0201-07
小麦是我国主要的粮食作物和重要的战略储备粮,提高小麦产量对确保国家粮食安全具有重要意义。近年来,倒春寒、寒潮等极端低温天气发生的频率逐年增加、周期逐年缩短[1],黄淮麦区和长江中下游麦区发生的严重倒春寒等低温天气使小麦遭受大范围冻害,严重影响小麦产量[2]。培育出具有抗寒性的优良品种对提高小麦产量有重要作用,抗寒性识别成为小麦育种专家引种、选种和栽培确定的重要依据。
目前,对小麦抗寒性识别的研究主要集中在生化细胞、基因分子和模拟低温环境等方面[3]。生化细胞方法测定技术繁琐、误差较大;基因分子方法测定易受基因型和技术影响,效率偏低;模拟环境的方法需要营造特定环境,耗费人力、物力和财力。近年来,深度学习方法被广泛应用到花型品种识别、农业文本分类、作物病害预测等方面[4]。袁培森等使用端到端的卷积神经网络技术逐层学习特征,获取多层网络提取菊花的特征信息,实现了菊花花型和品种智能识别[5]。金宁等结合双向门控循环单元神经网络和多尺度并行卷积神经网络优化文本表示和文本特征提取,能够准确地对用户提问实现自动分类[6]。张善文等结合知识图谱和双向长短时记忆网络方法对小麦条锈病进行预测,准确率达到93.21%[7]。
针对当前小麦抗寒性识别方法存在的问题,借鉴深度学习技术和特征选择算法在农业和工业研究领域的成功案例[8-16],本研究基于特征选择和深度学习方法对小麦抗寒性识别进行研究。首先使用自适应增强(adaptive boosting,简称AdaBoost)算法和极端梯度提升(extreme gradient boosting,简称XGBoost)算法对小麦数据进行特征选择,然后分别使用卷积神经网络(convolutional neural networks,简称CNN)和循环神经网络(recurrent neural network,简称RNN)提取小麦抗寒性的局部特征和序列特征,对获取的深层语义特征信息进行融合[17-18],构建基于特征选择和CNN+Bi-RNN的小麦抗寒性识别模型,最后通过样本均衡化进一步改善识别模型的性能。本研究的特征选择结果可对抗寒性进行有效特征筛选,为育种工作者培育出抗寒性品种提供更可靠的决策信息,提高育种效率。
1 数据与方法
1.1 试验数据
本研究试验数据来源于中国种业大数据平台(http://202.127.42.47:6010/SDSite/Home/Index)。利用Python编写爬虫系统爬取1978—2019年间的国审小麦品种信息,共得到3 513个品种的特性、熟性、生育期、幼苗特性、叶色、分叶能力、株型、株高、穗型、芒状、壳色、粒色、籽粒硬度、籽粒饱满度、亩穗数(1亩≈667 m2)、穗粒数、千粒重(指千粒质量)、熟相、抗倒性、抗寒性、抗旱性、粗蛋白质、湿面筋含量、降落指数、沉淀指数、吸水量、面团形成时间、面团稳定时间、弱化度、出粉率、延伸性、最大拉伸能量、最大拉伸面积、最大拉伸阻力、容重、节水指数、节水性37个文本特征信息。针对爬取的文本数据中出现的多词同义、错别字和常量单位不统一等噪声问题,参考Entz等的研究[19]并结合相关专家的建议,采用自动和人工相结合的方式对数据预处理,预处理后的每个特征信息分别按照语义信息统一采用字符串(如冬性、幼苗匍匐、株型紧凑等)和字符串混合数值(如生育期75至85、株高80至85、容重750至770等)2种类型表示,保留特征信息较为完整的3 049条小麦数据作为小麦抗寒性识别的数据集。不同的特征词出现频次及作用不同,根据每个特征词的词频-逆向文件频率(term frequency-inverse document frequency,简称 TF-IDF)的值,由高到低排序生成特征词云分布(图1)。
从图1可以看到,特征词的显示与 TF-IDF 呈正相关关系,在图1中显示较大的特征词对应的 TF-IDF 值也较大,说明对应的特征词对样本区分较为重要。特征词主要集中在穗粒数、亩穗数、熟性、生长期、千粒质量等有關特征描述中,说明这些特征对目标识别的影响较大。试验选取抗寒性为标签,依据文本语义将抗寒性分为抗寒性强、抗寒性中、抗寒性弱、抗寒性未显4类,将试验数据以 6 ∶2 ∶2 的比例分为训练集、验证集、测试集。
1.2 特征选择
特征选择通过评估函数度量特征与目标值之间的相关性,从特征子集中寻找最佳组合,去除原数据中不相关或者冗余的特征。特征选择不仅可以减少数据运算的内存消耗,还可以减少过拟合,提升模型的泛化能力。
AdaBoost算法采用自适应增强方式将训练得到的多个弱分类器加权组成强分类器,实现特征选择。该算法充分考虑每个分类器的权重,具有很高的精度,通过增大错误分类样本权值的方式增强学习,提高分类器的精度,获得特征的重要程度。XGBoost算法采用集成策略方式,依据梯度提升算法和正则项的引入,逐步减小已生成决策树的损失,不断更新最新生成树模型,确保特征重要性程度计算的可靠性。充分发挥XGBoost和AdaBoost 2个集成算法在特征选择过程中的优势,计算与抗寒性相关的各个特征的重要程度(特征值)。2种不同特征选择算法得到的特征值结果见图2。综合分析2种算法计算结果,采用投票原则,分别从前10、15、20、25、30个特征中选择2种算法重要的特征交集,构建不同的特征组合。
1.3 基于CNN+Bi-RNN的试验方法
CNN采用局部感知结构,通过局部连接和权值共享的方式提取训练数据的局部特征,以减少神经网络的参数,缓解模型的过拟合问题;Bi-RNN采用引入记忆单元的方式,提取输入特征在2个方向上的序列信息。为了进一步提升小麦抗寒性识别的性能,将局部上下文特征信息和序列特征信息融合,构建了CNN与Bi-RNN的混合模型CNN+Bi-RNN。首先,使用词向量工具Word2vec将输入的特征信息映射为特征向量;然后,分别使用CNN和Bi-RNN提取能够表示抗寒性的局部特征信息和序列特征信息;最后,使用向量拼接的方法将提取的局部特征和序列特征信息拼接,完成特征的提取。基于CNN+Bi-RNN的小麦抗寒性识别模型的整体结构见图3。
CNN+Bi-RNN模型依次为词向量嵌入层、CNN、Bi-RNN、特征融合层、全连接层与输出层。词向量嵌入层使用Word2vec将预处理后小麦的特征词映射到100维的向量空间,然后嵌入到神经网络中。嵌入小麦样本的特征向量W=RL×100,其中R表示样本集,L表示输入特征组合中的特征数目。
CNN使用大小为R3×100的卷积核,对输入文本W向量 进行卷积计算,获得输入小麦文本的局部特征信息。设定卷积核数目为64,卷积步长为1,卷积计算后的特征向量C=R(L-2)×64。为了缩减模型复杂度,提高模型计算速度和提取特征的鲁棒性,使用池化层对卷积层提取的局部特征进行2次提取,采用最大池化操作获取最能代表输入特征的重要信息,设定池化窗口为2,仅保留输入特征信息在局部区域的最大值,池化操作后的特征向量P=RL-12×64。
利用过去输入特征词和后面输入特征词采用Bi-RNN提取输入特征词之间的序列信息。Bi-RNN依据输入长度的变化而动态调整自身的网络状态,实现对嵌入小麦特征词向量W的序列特征信息提取,此网络不仅解决了输入小麦特征词文本之间的长序依赖问题,而且能够从正向RNN与反向RNN 2个方向提取序列数据特征。设定隐藏神经元个数为32,获取的序列特征向量S=R64。
采用向量拼接的方法进行特征融合,将CNN提取的局部特征向量P和Bi-RNN提取的序列特征向量S进行拼接,融合后的特征向量F=R128。该方法能够强化深度学习网络模型的特征学习能力,提升特征的表示强度。
使用全连接层将前一层网络融合后特征信息由高维转为低维,同时映射到各个隐语义节点。全连接可以实现对输入信息的维度变换和隐含语义表达,此时网络中的每个神经元都和前一层的所有神经元进行全连接,将前一层提取到的高维小麦特征信息映射为一维向量D=R32。
最后,使用Softmax分类器将多个神经元的输出映射到(0,1)区间内,得到所属4个类别的概率,输出概率值最大的类别实现最终的分类目标。
1.4 基于训练数据均衡化的CNN+Bi-RNN试验方法
不均衡样本构建的分类模型在训练过程中会降低对少数类样本的关注程度,分类的结果会更倾向于多数类样本,从而在整体上影响分类模型对小麦抗寒性的正确鉴定。针对本研究数据集中不同抗寒性类别的样本数量存在的训练数据不均衡问题,采用合成少数类过采样技术[20-22]对样本进行均衡化处理,使用默认参数对抗寒性适中和较弱的样本进行过采样,合成训练集中2种标签的样本,使不同类别的抗寒性样本趋于均衡化。合成少数类过采样技术(synthetic minority over sampling technique,简称SMOTE)样本均衡通过插值的方式加入近邻的数据点,扩充少数类的样本数目。样本均衡通过随机改变样本,不仅可以改善抗寒性识别的性能,而且可以降低对某些属性的依赖,从而提高模型的泛化能力。
2 结果与分析
以构建的小麦特征文本数据集为研究对象,利用AdaBoost和XGBoost算法进行特征选择,去除数据中的冗余特征,选择最佳特征进行组合,然后利用构建的CNN+Bi-RNN模型实现小麦抗寒性识别,最后将训练数据进行均衡化,有效改善小麦抗寒性模型的识别性能。
2.1 特征选择结果与分析
分别使用算法AdaBoost和XGBoost分析各个特征对小麦抗寒性的重要性。将2种算法计算出的特征重要程度进行对比分析,从前10、15、20、25、30个特征中进行选择,选出2个特征选择算法计算出重要性均较高的特征组合。试验选择范围、选择特征组和选出相同特征个数情况见表1。
2种特征选择算法生成最优特征子集的计算策略不同,因此2种算法所得的特征重要性程度也有差异。通过表1可以发现,依据2个特征选择算法计算的特征重要性程度,从前10、15、20、25、30个特征中进行选择,分别有5、10、15、19、27个特征对2个模型的重要性相同。按照综合分析选出的特征數目,共组合成5种特征子集,分别命名为Group1(即选择特征个数为5)、Group2、Group3、Group4、Group5,将全部特征命名为Group6。最后利用本研究构建的模型对选择的特征组合性能进行验证。
2.2 基于CNN+Bi-RNN的试验结果与分析
试验采用网格搜索方式,设置批量训练的大小和迭代次数。以16为步长,评估10~300的不同批次大小的试验结果。每次训练批次大小选定为32,即每批次处理32个小麦样本数据,设置模型训练的迭代次数为280。为了防止模型训练过程中神经网络参数增多产生过拟合,在卷积神经网络层和双向循环神经网络层之后,添加丢弃率为0.2的Dropout层,随机删除部分神经元。试验选择Adam为优化器,学习速率为0.001。在划分的训练集上构建试验模型,然后在验证集上调整优化模型参数,最后在测试集上验证模型的整体性能。
为验证选出特征组合和抗寒性识别模型的有效性,試验选取CNN、Bi-RNN与本研究构建的CNN+Bi-RNN模型进行对比试验,对比模型试验的训练批次设定为32,采用Early-stopping的方式监控验证集的loss值,当验证集的loss值连续10轮没有下降则终止训练。试验以准确率(accuracy)、F1-值(F1-score)和一致性检验系数(Kappa系数)作为模型的评价标准。不同特征组与模型在测试集上的试验结果对比如表2所示。
从表2可知,特征组为Group1时,CNN模型的试验结果明显高于Bi-RNN模型。特征组为Group2,CNN模型的性能仍优于Bi-RNN,但是优势不太明显。特征组选择为Group3、Group4、Group5、Group6时,Bi-RNN模型的性能要优于CNN模型,并且当特征组为Group3,即特征选择个数为15时,Bi-RNN模型的准确率、F1值和Kappa系数要比Group1时的CNN模型分别高出0.077 2、0.078 8、0.172 1。结果表明,CNN提取小麦文本的上下文特征和Bi-RNN提取的特征词之间的序列信息,均可用于小麦抗寒性鉴定。选取特征个数较少(特征选择个数为5和10)时,CNN获取的局部特征信息更加有利于模型做出正确的抗寒性分类识别;随着特征选择个数的增加,Bi-RNN获取的序列特征信息有效地改善了分类识别的性能。
另外,特征组为Group1,CNN+Bi-RNN模型的性能欠佳,低于CNN模型与Bi-RNN模型;特征组为Group2、Group3、Group4、Group、Group6,CNN+Bi-RNN模型的性能高于CNN模型和Bi-RNN模型,在Group3中,CNN+Bi-RNN模型对小麦的抗寒性识别的准确率、F1值、Kappa系数达到了最高,分别为0.789 8、0.810 2、0.602 7。结果表明,特征选择个数较少会导致模型中的参数个数较少,进而影响模型的性能;特征选择个数较多,增加了模型中的参数个数,但是增加的冗余特征会引起模型的性能下降;特征组Group3结合CNN+Bi-RNN模型对小麦抗寒性识别的性能上表现最优,说明Group3中的15个特征在小麦抗寒性识别试验中有重要作用。
2.3 基于训练数据均衡化的CNN+Bi-RNN试验结果与分析
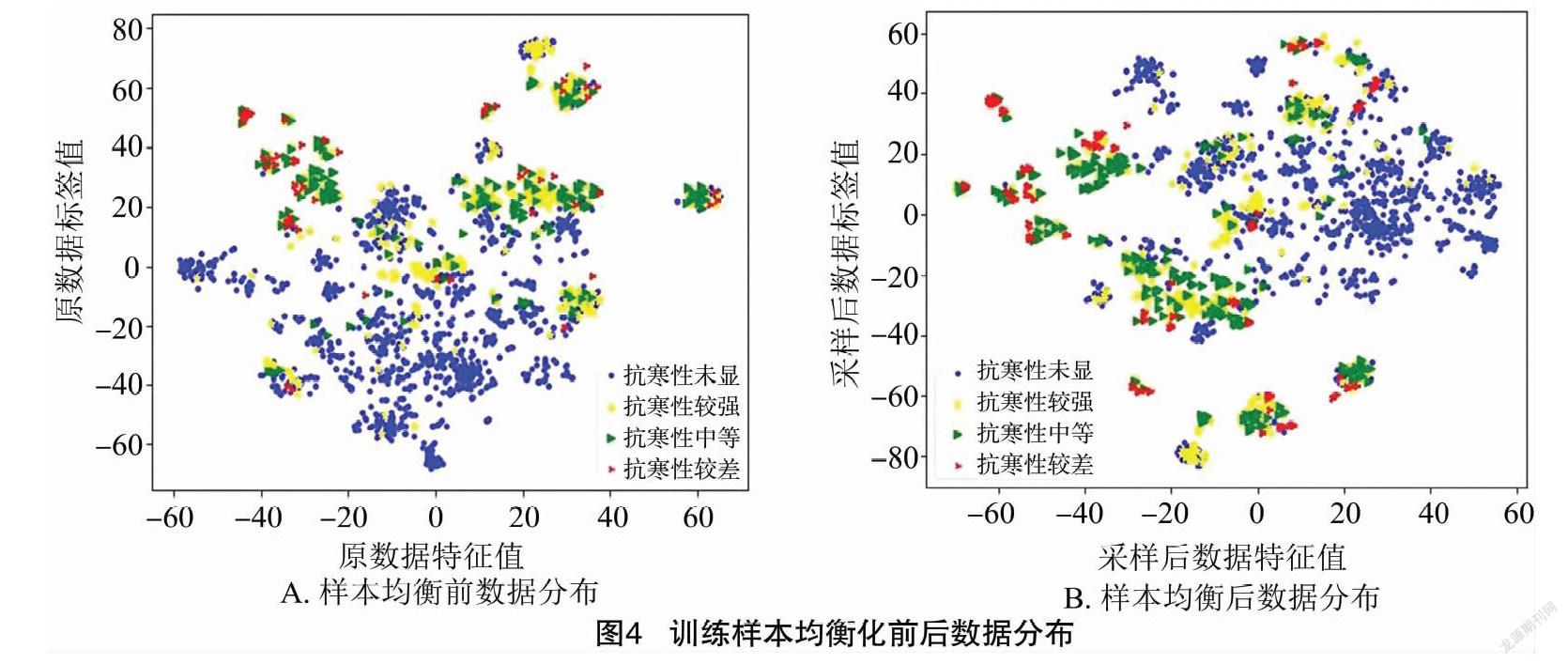
在小麦抗寒性识别训练数据集中,抗寒性未显的样本个数为1 218,抗寒性强的样本个数为360,抗寒性中的样本个数为202,抗寒性弱的样本个数为49。训练样本的数据存在不均衡,采用SMOTE随机过采样技术合成训练集中样本数目较少的类别,使各个类别的样本趋于均衡化。训练样本均衡化前后数据分布见图4。
样本均衡化之后,小麦抗寒性识别训练数据集中,抗寒性未显的样本个数为1 218,抗寒性强的样本个数为360,抗寒性中的样本个数为360,抗寒性弱的样本个数为360。从图4可以看到,样本均衡化之后抗寒性适中和较弱的分类样本数增多,各个分类样本的分布较均衡化前更为清晰,但是也出现多个分类样本重合的现象。试验结果表明,在对训练集样本均衡化之后,模型训练过程中出现了较为明显的过拟合现象,本研究通过增大Dropout层的丢弃率至0.4,改善模型的过拟合,提升模型在测试集上的泛化能力。
为了进一步验证样本均衡化后小麦抗寒性识别的效果,在相同条件下使用Group3特征组对不同模型进行样本均衡化,试验结果对比见图5。
由图5可知,样本均衡化后3种不同模型在测试集上的性能均有提升,其中,CNN模型与CNN+Bi-RNN的改善效果较为明显。CNN+Bi-RNN模型的准确率和F1值分别提高了0.039 4、0.013 3,Kappa系数达到了0.641 2。样本均衡化处理通过人工合成少数类别样本,不仅改善数据不平衡的问题,并且增加对少数类别样本的关注程度。试验结果表明,样本均衡化不仅可提高试验预测的准确率,而且能改善小麦抗寒性识别的一致性检验性能。
3 讨论与结论
本研究提出了一种融合特征选择与深度学习的小麦抗寒性识别方法。首先对收集整理的国审小麦品种特征文本数据集预处理,然后构建CNN+Bi-RNN小麦抗寒性识别模型,最后采用样本均衡化处理的训练集,检验本研究方法的性能。通过试验得到以下结论:(1)采用CNN+Bi-RNN模型可以有效解决小麦抗寒性识别问题。将输入的文本特征词训练为高维的词向量,使用CNN充分挖掘特征词上下文之间的局部信息;使用Bi-RNN从前后2个方向上提取整个输入特征文本序列信息。通过试验验证表明,采用将捕获的局部特征信息和序列特征信息进行组合的方法对小麦抗寒性识别的准确度和Kappa系数均高于其他对比模型。(2)提出融合特征选择和深度学习的方法,将选出的特征组与构建的CNN+Bi-RNN模型相结合,试验结果表明特征选择为亩穗数、熟性、品种特性、吸水量、抗倒性、株高、熟相、分叶能力、穗粒数、幼苗特性、叶色、拉伸面积、生长期、株型、抗旱性15个特征时,小麦的抗寒性识别模型结果最优,这15个特征对小麦的抗寒性影响较大。(3)使用SMOTE随机过采样技术可以解决样本不均衡问题。训练数据集样本均衡化后,试验方法的准确度和Kappa系数均有提高,说明通过增加数目较少的标签数量可以有效缓解少数类样本被忽略的问题,从而改善小麦抗寒性识别的性能。
本研究提出的小麦抗寒性识别方法能够指导育种专家在育种选择时更具有针对性地选择地抗寒品种,为小麦信息化育种提供决策辅助。下一步工作将继续优化特征选取方法,找到更优的特征子集,进一步提高抗寒性识别的准确率。
参考文献:
[1]张淑娟,宋国琦,高 洁,等. 小麦春季抗寒性研究进展[J]. 山东农业科学,2017,49(6):157-162.
[2]赵 虹,王西成,胡卫国,等. 黄淮南片麦区小麦倒春寒冻害成因及预防措施[J]. 河南农业科学,2014,43(8):34-38.
[3]赵瑞玲,赵 勇,易腾飞,等. 小麦种质资源的抗寒性鉴定及品種筛选[J]. 山东农业大学学报(自然科学版),2019,50(1):25-30.
[4]吕盛坪,李灯辉,冼荣亨. 深度学习在我国农业中的应用研究现状[J]. 计算机工程与应用,2019,55(20):24-33,51.
[5]袁培森,黎 薇,任守纲,等. 基于卷积神经网络的菊花花型和品种识别[J]. 农业工程学报,2018,34(5):152-158.
[6]金 宁,赵春江,吴华瑞,等. 基于BiGRU_MulCNN的农业问答问句分类技术研究[J]. 农业机械学报,2020,51(5):199-206.
[7]张善文,王 振,王祖良. 结合知识图谱与双向长短时记忆网络的小麦条锈病预测[J]. 农业工程学报,2020,36(12):172-178.
[8]Chen T Q,Guestrin C. XGBoost:a scalable tree boosting system[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York:ACM,2016:785-794.
[9]李占山,刘兆赓. 基于XGBoost的特征选择算法[J]. 通信学报,2019,40(10):101-108.
[10]姜少飞,邬天骥,彭 翔,等. 基于XGBoost特征提取的数据驱动故障诊断方法[J]. 中国机械工程,2020,31(10):1232-1239.
[11]傅隆生,冯亚利,Elkamil Tola,等. 基于卷积神经网络的田间多簇猕猴桃图像识别方法[J]. 农业工程学报,2018,34(2):205-211.
[12]郑 诚,薛满意,洪彤彤,等. 用于短文本分类的DC-BiGRU_CNN模型[J]. 计算机科学,2019,46(11):186-192.
[13]Yang F,Zhang J H,Liu G S,et al. Five-stroke based CNN-BiRNN-CRF network for Chinese named entity recognition[C]//Natural Language Processing and Chinese Computing.Switzerland:Springer,2018:184-195.
[14]佃松宜,程 鹏,王 凯,等. 基于双向循环神经网络的跌倒行为识别[J]. 计算机工程与设计,2020,41(7):2019-2024.
[15]Al-shaibani M S,Alyafeai Z,Ahmad I. Meter classification of Arabic poems using deep bidirectional recurrent neural networks[J]. Pattern Recognition Letters,2020,136:1-7.
[16]Li Z,Zhu J P,Xu X J,et al. RDense:a protein-RNA binding prediction model based on bidirectional recurrent neural network and densely connected convolutional networks[J]. IEEE Access,2019,8:14588-14605.
[17]曹建荣,吕俊杰,武欣莹,等. 融合运动特征和深度学习的跌倒检测算法[J]. 计算机应用,2021,41(2):583-589.
[18]杨朝强,邵党国,杨志豪,等. 多特征融合的中文短文本分类模型[J]. 小型微型计算机系统,2020,41(7):1421-1426.
[19]Entz M H,Kirk A P,Carkner M,et al. Evaluation of lines from a farmer participatory organic wheat breeding program[J]. Crop Science,2018,58(6):2433-2443.
[20]刘云鹏,和家慧,许自强,等. 基于SVM SMOTE的电力变压器故障样本均衡化方法[J]. 高电压技术,2020,46(7):2522-2529.
[21]石洪波,陈雨文,陈 鑫. SMOTE过采样及其改进算法研究综述[J]. 智能系统学报,2019,14(6):1073-1083.
[22]Chawla N V,Bowyer K W,Hall L O,et al. SMOTE:synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research,2002,16:321-357.
