基于SVM的自密实水泥土强度预测模型研究
2022-06-11邵应峰张子阳
王 响, 邵应峰, 沈 霞, 张 燚, 张子阳
(1.河海大学岩土力学与堤坝工程教育部重点实验室,南京 210098; 2.河海大学岩土工程科学研究所,南京 210098)
随着经济的发展和社会的进步,我国城市化发展进程加快. 在进行城市排水管网建设过程中,由于施工条件复杂,经常出现沟槽部两边的纵向裂缝及沟槽部位的明显凹槽现象. 出现这些现象,是因为沟槽宽度过小,难以使用重型压实机械压实,导致沟槽回填土压实度达不到设计要求[1]. 另外,在进行沟槽开挖过程中,会产生大量废弃土,这些弃土由于缺乏有效监管,容易造成占用土地、破环城市市容并恶化城市环境卫生等方面的危害[2];自密实水泥土是为解决上述难题而研究出来的一种新技术,充分利用开挖的废弃土,用水泥改良后,可以形成具有自密实性质且强度可调的一种新型填筑材料[3],不仅可以解决沟槽回填压实度问题,还可以减少弃土的运输费用[4].
管道沟槽回填土的设计主要有强度[5]和渗透性[6],水泥土作为一种复合材料,其强度主要受配合比的影响,在配合比设计中通常考虑的影响因素有含水率、水泥掺入比、外掺剂等[7]. 贾坚[8]通过室内试验发现,综合含水量和水泥掺入比是影响水泥土强度的关键因素,因此,本文选用水泥掺入比和含水量这两个影响因素预测水泥土强度. 当水泥土强度和影响因素之间的关系为线性[9]、指数[10]、和对数[11]等简单情况下,可以通过函数拟合得到水泥土和影响因素之间的函数表达式. 由于水泥土和水泥掺入比、含水量之间存在复杂关系,同时机器学习在处理复杂关系时具有较大优势[12],因此,可以用这种方法预测水泥土的强度.
利用机器学习进行预测,本质是对数据的回归分析,常用的具有回归分析功能的机器学习方法主要包括神经网络[13]和支持向量机[14](Support Vector Machine,SVM)等. 神经网络虽然可以处理非线性问题,但也存在收敛速度慢、过学习和局部极值等问题,而且需要的样本数量大[15];由于支持向量机的训练模式采用优化技术及数学方式,因此在小样本、高维、非线性预测领域具有很好的应用效果[16],尤其适合水泥土的小样本、非线性问题. 目前,吴张中等[17]利用支持向量机建立钻孔后注浆水泥土强度的SVM回归模型,该模型描述了泥浆、水泥土比重参数与水泥土强度之间的映射关系;魏良针等[18]把均方误差作为预测模型的适应度函数,并通过网格搜索法、粒子群算法优化SVM模型参数,建立了地表沉降预测模型. 因此,本文利用支持向量机的方法得到水泥土强度和影响因素的关系,并预测特定配合比下的水泥土强度.
1 自密实水泥土的配合比试验
1.1 试验材料
试验采用的原料土为南通现场开挖弃土,土的物理力学指标如表1,固化剂为P·O 42.5 普通硅酸盐水泥,水为自来水.
1.2 试验方法
将土样风干碾碎,过2 mm筛,密封保存备用. 试样制作时,先将水泥和水混合,形成水泥浆液,再将干土加入,放入搅拌机中充分搅拌,搅拌均匀后,在标准圆柱试模中制作直径50 mm,高度100 mm 的试样,成型1 d 后放入标准养护箱中养护,养护温度为(20±2)℃,相对湿度为95%,在龄期28 d 时进行无侧限抗压强度试验,取3个平行试样的算术平均值作为该组的无侧限抗压强度值,当试样的测值与平均值之差超过平均值的±15%时,剔除该数据,余下试样的测值计算平均值. 如一组试样不足两个,需重做[11].
1.3 试验结果
为了研究并验证自密实水泥土强度、和水泥掺入比(水泥质量/干土质量×100%)、含水量(所有水质量/干土质量)的非线性关系,本文按不同水泥掺入比(5%、7.5%、10%、12.5%、15%)和不同含水量(0.52、0.55、0.58、0.61、0.64)采取正交试验,共制作水泥土试块25组,试块压试速率为1 mm/min,试验结果如表2所示.

表2 自密实水泥土28 d无侧限抗压强度结果Tab.2 Results of unconfined compressive strength of self-compacting cement soil for 28 d
2 SVM建模
2.1 SVM回归基本原理
SVM一般分为分类和回归两大问题. 其中SVM回归基本思路:对于给定训练样本集Y={ }(xi,yi) ,通过非线性映射ϕ(x),将输入量x映射到高维空间,然后用函数f(x)=ω∙ϕ(x)+b对数据进行拟合. 拟合的本质是寻找最优参数ω和b使f(x)逼近y. 考虑到允许拟合误差问题,引入松弛因子ξ和ξ*,由此得到待优化函数:

式中:ω为权重;C为惩罚因子,其作用可以控制拟合误差;ξ和ξ*是松弛因子,当预测存在误差时都大于0,否则等于0;x为自变量;y为因变量;b为常数;ε为一个大于0且很小的数. 再引用Lagrange方程,解决对偶优化问题:

其中:α、α*、η、η*≥0,为Lagrange乘子,且L对α、α*、η、η*的偏导等于零,再引入径向基核函数:

式中:g为核函数参数,可以影响样本空间到特征空间的映射;xi和xj都为自变量. 该函数将高维空间转为低维空间,就可以得到非线性拟合函数f(x)的表达式:

2.2 样本数据划分
在利用SVM 建立预测模型时,通常会将样本按2∶1 的比例划分训练集和测试集,故将含水量为0.52、0.61、0.64的15组数据划分为训练集,通过这15组数据,利用SVM建立yi={28 d无侧限抗压强度}与xi={水泥掺入比,含水量}之间的回归模型,分析水泥掺入比、含水量和28 d抗压强度的关系,并用SVM建立强度预测模型,最后将剩下的10组数据划分为测试集,然后用该模型输出这10组配合比的预测强度,并和真实强度进行比对.
3 SVM模型参数优化
根据式(1)和式(4)可以看出,参数g和C是SVM 中重要参数,g的取值影响样本空间到特征空间的映射,C可以控制拟合误差.因此,可以通过特定的算法调整参数的值,从而获得更优的预测模型. 本文通过网格寻优算法、粒子群算法和模拟退火算法寻找该模型参数的最优值.
首先,将15组训练集中的数据归一化并代入支持向量机预测模型中训练,将g和C两个参数范围设置在[0,10]内,为了准确评估参数变化时模型的预测性能,提出了均方误差(Mean Squared Error,MSE),当MSE越小时,表示预测模型的误差越小,如式(6)所示:

式中:yi为预测数据实际值;y为预测值;N为样本数.
网格寻优算法的本质是将所有情况遍历一遍[19],因此设置每个参数的步长为0.01,将式(6)作为适应度函数,计算每一种情况的适应度值(MSE),优化结果如图1所示,当g=6.6、C=8.6 时,适应度值最小,对应的MSE 为0.003 8 MPa.

图1 网格寻优算法结果Fig.1 Results of grid optimization algorithm
粒子群优化算法通过随机生成粒子群,将每一个粒子抽象为一只鸟,待优化参数的个数代表粒子的维度空间的层数,它可以在d维空间中以一定的速度飞行,通过设计的适应度函数判断所得到的位置是否合适,每次迭代,粒子会根据前期飞行经验,动态调整速度并更新位置,直至找到最佳位置,即问题的最优解[20]. 粒子群的规模不宜太大,设置为20;加速常数c1、c2通常取0~2 之间的数,均设置为2;最大迭代次数为100;将式(6)作为适应度函数. 每次迭代,计算每个粒子的适应度值(MSE).优化结果见图2,当迭代次数超过40次时,计算结果收敛于0.005 5附近,计算速度较快. 最终,当g=3.76、C=8.6时,适应度值最小,对应的MSE为0.005 3 MPa.

图2 粒子群算法结果Fig.2 Results of particle swarm algorithm
模拟退火算法是一种通用概率算法,用来在一个大的搜寻空间内寻找命题的最优解. 由于引入了随机因素,它能以一定的概率接受一个比当前解要差的解,因此,有可能跳出局部的最优解以致达到全局的最优解[21]. 它来源于固体退火原理,本质上是将待优化问题类比为退火过程中能量的最低状态,也就是温度达到最低点时,概率分布中具有最大概率的状态. 假设初始温度T0=10 ℃,迭代次数为100,按Tf=0.01 ℃更新温度,温度设定的阈值为0.99,最终优化结果见图3. 当第一次迭代,适应度值就接近最小值,但并没有一直收敛于该值附近,而是跳出这个范围,继续搜寻全局最优值,保证了结果的可靠性. 当g=10.27、C=7.16 时,适应度值最小,对应的MSE为0.003 8 MPa.
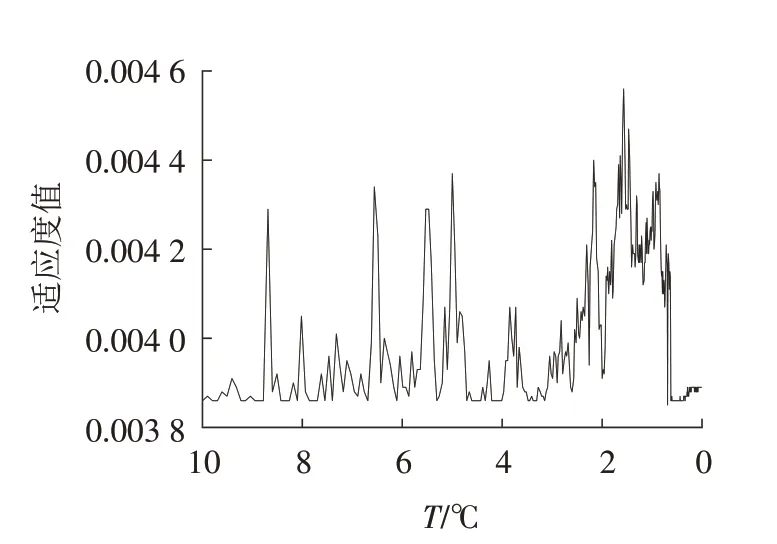
图3 模拟退火算法结果Fig.3 Results of simulated annealing algorithm
4 SVM预测模型评价
为了选择最优的预测模型,首先,利用三种不同算法改进的SVM 预测模型输出测试集中的10 组预测值,然后将真实值和预测值表示在同一坐标轴上,如图4. 可以看出,这三种预测模型输出的预测值和真实值误差都很小,且增长趋势一致,可以模拟试样的无侧限抗压强度随水泥掺入比和含水量的非线性变化过程.
由于三种预测模型的预测值和真实值的误差都很小,所以,不能直接从图4 中直接选择最优的预测模型. 分别计算三种预测模型在测试集中的预测值和真实值的平方损失(MSE)及绝对损失(MAE),当这两个值越小时,模型的预测效果越好,计算结果见表3.

图4 测试集中预测值和真实值对比图Fig.4 Comparison chart of predicted values and true values in the test set
从表3 可以看出,GS_SVM 预测模型和SA_SVM 预测模型结果一样,但GS_SVM 计算时,需要把所有的结果都遍历一遍,计算量大,所以SA_SVM 预测模型的计算速度更快;PSO_SVM预测模型相较于SA_SVM预测模型,少了一次内部的迭代循环,计算更快,但容易得到局部最优解. 结果表明,SA_SVM 预测模型为最优预测模型,计算速度更快,结果更准确.

表3 测试集中不同预测模型的预测结果Tab.3 Prediction results of different forecast models in the test set
5 总结
本文将机器学习中SVM应用到自密实水泥土最佳配合比预测中,可以根据水泥掺入比和含水量预测特定的强度,从而确定最佳配合比,显著降低了试验的成本,为配合设计提供重要参考意义,并得到以下结论:1)自密实水泥土28 d无侧限抗压强度随灰土比增大而增大,随水土比增大而减小.2)自密实水泥土SVM预测模型能够根据小样本进行非线性建模并预测.
