基于辅助任务的BERT中文新闻文本分类研究
2022-06-11崔建青仇测皓
崔建青 仇测皓







摘 要:新闻文本分类是自然语言处理领域中一项重要任务,本文使用新闻标题进行文本分类。随着BERT预训练模型的崛起,BERT模型在多项NLP(Natural Language Processing)任务中都取得了较好的效果,并应用在新闻分类任务中。为了提高新闻分类这一主要任务的效果,本文引入辅助任务判断两个新闻是否是同类新闻,对BERT预训练模型在辅助任务和主要任务上进行微调。在THUCNews数据集上进行实验,实验结果表明,引入辅助任务的BERT新闻分类模型在效果上优于原BERT模型。
关键词:新闻文本分类;BERT;辅助任务
中图分类号:TP391 文献标识码:A
Research on BERT Chinese News Text Classification based on Auxiliary Tasks
CUI Jianqing, QIU Cehao
Abstract: News text classification is an important task in the field of natural language processing. This paper proposes to use news headlines for text classification. With the rise of BERT (Bidirectional Encoder Representation from Transformers) pre-training model, BERT model has achieved good results in many NLP (Natural Language Processing) tasks, and it is also applied to news classification tasks. In order to improve the effect of the main task of news classification, an auxiliary task is introduced to judge whether the two news are similar ones, and the BERT pre-training model is fine-tuned in the auxiliary task and the main task separately. Experiments are carried out on THUCNews data set. The experimental results show that BERT news classification model with auxiliary tasks is better than the original BERT model.
Keywords: news text classification; BERT; auxiliary task
1 引言(Introduction)
近年来,随着互联网的高速发展与普遍接入,每天有大量的文本数据产生,人工方式已无法满足海量数据的处理需求。在这种情况下,对大规模文本数据的自动识别和处理显得尤为重要,而新闻文本是其中非常重要的一类数据,对新闻文本的分类是自然语言处理领域中的一项重要任务。目前,基于传统机器学习方法的文本分类方法已趋于成熟,常见的机器学习分类算法有朴素贝叶斯算法、KNN算法、SVM算法等[1],这些算法在文本分类任务中取得了不错的效果,但是也存在一定的问题,比如在对文本进行特征表示时不能很好地表示语序和语义信息,而且存在数据维度高和稀疏性等问题,这些问题在一定程度上都影响了文本的分类效率。随着深度学习技术的发展,CNN、RNN、LSTM等神经网络模型逐步应用在文本分类任务中,2018 年Google提出了BERT模型[2],BERT预训练模型也被应用在了文本分类技术中。本文基于BERT预训练模型,通过在辅助任务和主要任务(新闻分类任务)上的微调来提升新闻分类模型的效果。
2 相关研究(Related research)
随着深度学习在自然语言处理中的广泛应用,相关技术和研究算法也被应用在文本分类任务中。2014 年,KIM[3]针对CNN(Convolutional Neural Network)的输入层做了一些变形,提出了文本分类模型textCNN,该模型基于卷积神经网络,关注的是文本的局部信息,无法获取上下文信息,限制了对文本语义的理解。万圣贤等人[4]为了解决LSTM(Long Short-Term Memory)只能获取整个句子表达而不能获取文本局部特征的问题,提出了局部化双向LSTM模型,通过对LSTM模型的中间表示进行卷积和最大池化操作,获取局部的文本特征,再进行分类,但由于LSTM在进行序列化处理时需要依赖上一时刻的计算结果,因此存在计算效率低的问题。2017 年,VASWANI等人[5]提出了Transformer模型,通过引入自注意力机制实现计算的并行化,从而可以在更大的数据上训练更大的模型。从2018 年开始,涌现出了一系列基于Transformer的预训练模型,BERT就是其中被广泛使用的一个预训练模型,它通过掩码语言模型和下一句预测两个预训练任务得到预训练模型,并在文本分类任务上进行微调,得到适用于文本分类的模型,并取得了当时的最优效果。林德萍等人[6]在新闻分类任务上,通过对比基于BERT的分类模型和基于LSTM的分類模型,得到BERT模型在新闻分类上准确率更高的结果。YU等人[7]提出了BERT4TC模型,该模型通过构造辅助句子来提升模型性能,它将单句分类任务转换成句子对形式的分类任务进行处理,旨在解决有限的数据问题和任务感知问题。张小为等人[8]将BERT当作嵌入层接入CNN模型中进行中文新闻文本分类。付静等人[9]通过将BERT输出的语义特征和word2vec词向量与LDA(Latent Dirichlet Allocation)模型融合得到的主题扩展特征进行拼接来进行新闻短文本的分类。本文通过构建辅助任务判断两个新闻语句是否是同类新闻,对BERT预训练模型先在辅助任务上进行微调,再在主要任务(新闻文本分类任务)上进行微调,并进行效果验证。
3 研究方法(Research method)
3.1 BERT模型
3.1.1 BERT模型结构
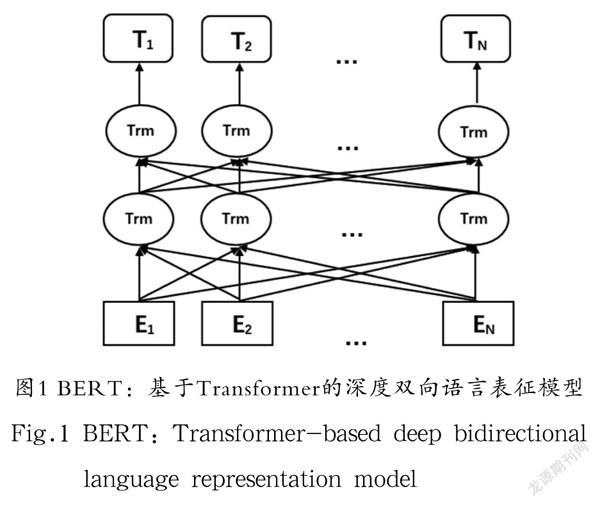
如图1所示,BERT是基于Transformer的深度双向语言表征模型。BERT利用Transformer编码器构造了一个多层双向的网络,由多层Transformer编码器堆叠而成,每一层编码器由一个多头自注意力子层和一个前馈神经网络子层组成。多头自注意力子层帮助编码器在对每个单词进行编码时关注输入句子的其他单词。
3.1.2 BERT输入
BERT的输入序列既可以是一个单一的句子,也可以是由两个句子组合成的句子对。BERT输入中有几个有特殊作用的符号:
[CLS]:BERT输入序列以[CLS]符号开始,其经过BERT模型得到的隐藏向量可以作为整个句子的表征向量,从而用于后续的分类任务。
[SEP]:此符号用于分开两个输入句子,例如输入句子A和B,要在句子A和句子B后面都增加一个符号[SEP],用来区分这两个句子。
本文使用输入为字粒度的BERT模型。假设有句子A,它由N 个字符A1、A2、…、AN按顺序组成;有句子B,它由M 个字符B1、B2、…、BM按顺序组成。当输入的是单个句子A时,其对应的BERT输入序列为:“[CLS] A1 A2 … AN”;当输入的是由A、B组合成的句子对时,其对应的BERT输入序列为:“[CLS] A1 A2 … AN [SEP] B1 B2 … BM [SEP]”。
BERT的输入嵌入由三部分相加构成。标记嵌入(Token Embedding)是单词本身的词向量,位置嵌入(Position Embedding)表示单词位置信息,片段嵌入(Segment Embedding)用于区分两个句子。由于注意力层并不会捕获词与词之间的序列信息,因此需要添加位置嵌入提供词间的位置信息。
3.1.3 BERT预训练
BERT预训练过程由两个无监督任务构成:掩码语言模型(Masked LM)任务和下一句预测任务(Next Sentence Prediction)。
掩码语言模型随机替换输入序列中15%的标记(Token),被替换的标记有80%的概率被替换成符号[MASK],有10%的概率被替换为其他任意一个标记,有10%的概率保持原词。与完形填空题类似,BERT这样做使得模型被迫从上下文中猜测被遮掩的詞是什么,从而捕获文本的深层含义。
在下一句预测任务中,输入为两个句子A和B,其中有50%的概率句子B是句子A的下一个句子,有50%的概率句子B是从语料中随机选取的句子。模型的目标是判断句子B是否是句子A的下一个句子,使用输入序列开始的符号[CLS]经过BERT后对应输出的编码向量C进行预测。此任务的训练使得BERT模型可以理解句子之间的关系。
3.2 基于BERT的分类任务训练
预训练得到的BERT模型可以用于后续的NLP任务中,通过对BERT模型进行微调,BERT模型可以适用于多种不同的NLP任务。本文中文新闻文本分类就是通过在分类任务上对BERT模型进行微调实现的。本文使用新浪新闻的THUCNews中文新闻数据集,使用新闻标题这样的短文本进行分类。本文除了进行新闻主题多分类这一主要任务,还加入了辅助任务,即判断两个新闻标题是否是同一类新闻的二分类任务。本文使用新闻主题分类数据构建同类和不同类的新闻标题语句对,从而进行二分类任务的训练,这样既可以通过数据重构有效利用现有的有限的标注数据,又可以通过对此二分类任务的训练,让BERT模型学习到更好的类别特征,帮助BERT模型更好地进行主题多分类任务的学习。本文在BERT微调阶段,先进行新闻标题语句对二分类(同类/不同类)的训练,再进行新闻主题多分类任务的训练,下面就这两个任务进行详细阐述。
3.2.1 二分类任务微调
(1)数据的构建
对于任意一个新闻标题,随机选取另一个同类的新闻标题构建同类新闻语句对;等概率选取一个不同类别,从中随机选取一条新闻标题构建不同类新闻语句对。这样就构建好了二分类任务的训练数据。
(2)网络结构
如图2所示,使用构建好的新闻语句对作为输入,比如有新闻标题“异动股点评”和“两市几乎平开”,那么输入的符号序列为“ [CLS] 异 动 股 点 评 [SEP] 两 市 几 乎 平 开 [SEP] ”。此符号序列经过嵌入层,分别得到对应的标记嵌入、位置嵌入和片段嵌入,将这三个嵌入相加得到最终的嵌入并传入BERT预训练模型中,经过BERT模型,得到此语句对的表征向量,再将表征向量经过全连接层对此二分类任务进行学习,最后经过Softmax层得到分类的概率,进而得到分类结果。
3.2.2 主题多分类任务微调
本文对新闻进行主题分类,共分为十个类别,分别是金融、房地产、股票、教育、科技、社会、政治、体育、游戏和娱乐。在新闻主题多分类任务中,输入是新闻标题,输入序列通过嵌入层得到嵌入表示,再使用上面二分类任务中微调得到的BERT模型,将得到的嵌入表示输入上述微调后的BERT模型中并得到其表示,再经过全连接网络和Softmax层,得到十分类的概率值,取概率最高的类别就是模型预测的分类结果。
4 实验与结果(Experiments and results)
4.1 实验目的
本次实验使用BERT预训练模型首先进行辅助任务的微调训练,其次对经过微调训练后的模型进行新闻文本分类任务训练,下面用BERT+AUX表示此模型,探究其效果是否优于直接使用BERT预训练模型进行新闻文本分类。
4.2 实验数据集
深度神经网络模型的学习高度依赖数据集,一个好的数据集对模型的优劣起决定性作用。我们使用THUCNews大型新闻语料库,它是根据新浪新闻RSS订阅频道2005 年到2011 年的历史数据筛选过滤生成的,包含74万篇新闻文档(2.19 GB),均为UTF-8纯文本格式。本次实验使用该语料库中的十个类别,即金融、房地产、股票、教育、科技、社会、政治、体育、游戏和娱乐,每个类别包含两万条数据,共20万条带类别标签的新闻标题数据,从中抽取18万条作为训练数据集,1万条作为测试集,1万条作为验证集。
对于二分类微调任务,使用上述20万条新闻数据,对其进行正采样和负采样,得到训练数据。对于任意一条新闻数据,正采样是从同类数据中随机抽取一个样本组成二分类任务的一个正样本,负采样是等概率从其他类数据中随机抽取一个样本组成二分类任务的一个负样本。通过此方式,我们得到36万个新闻语句对作为训练数据集,两万个新闻语句对作为测试集,两万个新闻语句对作为验证集。
4.3 实验环境
实验采用Intel 酷睿i5 8300H四核八线程CPU,显卡使用4 GB NVIDIA GTX 1050Ti,编程语言使用Python 3.7,深度学习框架使用Pytorch 1.7.1+cu101。本次实验使用BERT开源库Pytorch Transformers,预训练模型使用谷歌发布的BERT中文预训练模型。为了避免训练结果产生过拟合现象,本次实验使用提前终止技术。
实验超参数如下:迭代次数Epoch设为5,批量大小batch size设为16,学习率learning rate设为2e-5,梯度裁剪max grad norm设为10,提前终止批量大小设为1000。
4.4 评估指标
采用分类任务中常用的评估指标:准确率Acc(Accuracy)、精确率P(Precision)、召回率R(Recall)和F1。四种指标的计算方法如下:
(1)
(2)
(3)
(4)
其中,TP表示实际为正,被预测为正的样本数量;TN表示实际为负,被预测为负的样本数量;FN表示实际为正,被预测为负的样本数量;FP表示实际为负,被预测为正的样本数量。
4.5 实验结果与分析
4.5.1 实验结果
在测试集上对模型效果进行验证,表1显示BERT模型分类准确率为94.53%,我们的模型BERT+AUX分类准确率为94.76%,是优于BERT模型的。
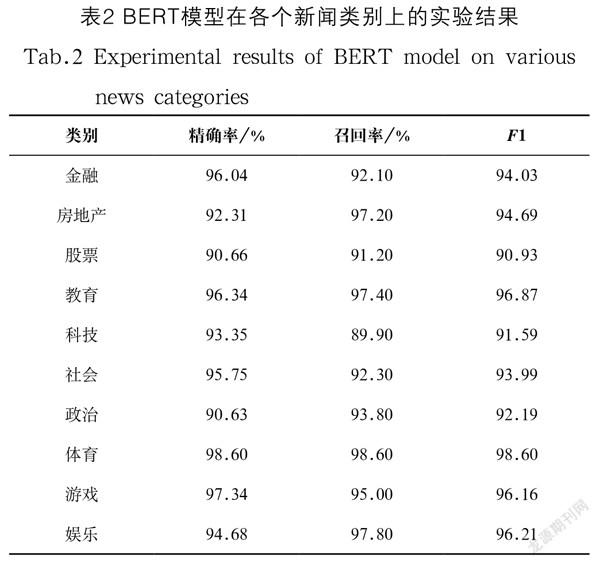
表2是BERT模型在新闻分类各类别上的精确率、召回率和F1值,表3是我们的模型BERT+AUX在新闻分类各类别上的精确率、召回率和F1值。从中可以看出,BERT+AUX模型在金融、房地产、股票、科技、政治、体育、游戏、娱乐八个类别上的F1值均高于直接使用BERT模型进行新闻分类的效果。
4.5.2 实验分析
本次实验结果证明,先使用BERT预训练模型进行两个新闻标题是否为同一类新闻的微调训练,然后再对经过微调训练后的模型进行新闻文本分类的训练,要优于直接使用BERT预训练模型进行新闻文本分类。由表1可以看出,BERT+AUX模型比BERT模型分类准确率高0.23%;由表2、表3对比可以看出,BERT+AUX模型在多个类别上是明显优于BERT模型的。
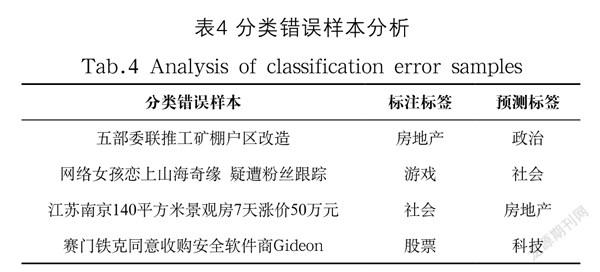
通过分析预测错误的样本,我们发现,预测错误的样本很多都是可以被标注为多类别的。其中一些分类错误的样本如表4所示,比如新闻:“江苏南京140平方米景观房7天涨价50万元”,标注的类别是“社会”,而模型预测的类别是“房地产”,因为这个新闻既可以是“社会”类新闻,又可以是“房地产”类新闻。
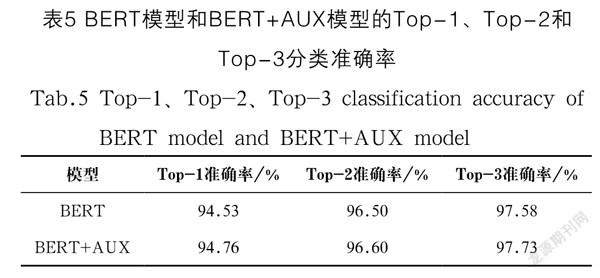
由于新闻存在多类别的情况,我们除了考虑模型的Top-1准确率外,继续考虑模型的Top-2准确率和Top-3准确率。表5就是BERT模型和BERT+AUX模型的Top-1、Top-2、Top-3准确率对比。从表5中可以看到,我们的模型BERT+AUX在Top-1、Top-2和Top-3上的准确率均高于BERT模型,并且Top-3准确率可以达到97.73%。
5 结论(Conclusion)
本文针对中文新闻文本分类问题,在使用BERT预训练模型进行文本表示的基础上,首先借助辅助任务进行微调,再使用通过辅助任务微调得到的BERT模型对新闻分类任务进行训练。通过引入辅助任务,帮助BERT模型学习到更多的类别特征,同时辅助任务使用的数据是基于新闻分类数据重构得到的,更加充分利用了有限的标注数据。实验结果表明,基于輔助任务的BERT分类模型效果更好。本文使用新闻标题进行文本分类存在信息量少的问题,后续可以考虑在其中加入更多的特征和知识以便更好地进行短文本分类。
参考文献(References)
[1] 高洁,吉根林.文本分类技术研究[J].计算机应用研究,2004
(07):28-30,34.
[2] DEVLIN J, CHANG M W, LEE K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[C]// BURSTEIN J, DORAN C, SOLORIO T. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019. Minneapolis MN USA: ACL, 2019:4171-4186.
[3] KIM Y. Convolutional neural networks for sentence classification[C]// MOSCHITTI A, PANG B, DAELEMANS W.
Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha, Qatar: ACL, 2014:
1746-1751.
[4] 万圣贤,兰艳艳,郭嘉丰,等.用于文本分类的局部化双向长短时记忆[J].中文信息学报,2017,31(3):62-68.
[5] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// GUYON I, LUXBURG U V, BENGIO S, et al. Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017. Long Beach, CA, USA: NIPS, 2017:5998-6008.
[6] 林德萍,汪红娟.基于BERT和RNN的新闻文本分类对比[J].北京印刷学院学报,2021,29(11):156-162.
[7] YU S S, SU J D, LUO D. Improving BERT-based text classification with auxiliary sentence and domain knowledge[J]. IEEE Access, 2019, 7:176600-176612.
[8] 张小为,邵剑飞.基于改进的BERT-CNN模型的新聞文本分类研究[J].电视技术,2021,45(07):146-150.
[9] 付静,龚永罡,廉小亲,等.基于BERT-LDA的新闻短文本分类方法[J].信息技术与信息化,2021(2):127-129.
作者简介:
崔建青(1989-),女,硕士,助教.研究领域:自然语言处理,人工智能.
仇测皓(2000-),男,本科生.研究领域:自然语言处理.
