混合动力客车能量管理策略研究
2022-06-10胡树良陆文丽莫锦传
胡树良,黄 伟,陆文丽,莫锦传
(广西大学 机械工程学院,广西 南宁 530004)
0 引言
能量控制策略作为油电混合动力汽车的关键技术,是各车企及车辆院校研究的焦点。根据实现的原理不同,可将混合动力车辆能量管理策略划分为3类,包括基于规则、基于优化和基于智能算法的能量管理策略[1]。
基于规则型能量管理策略(rule-based energy manage system,RB-EMS)是一种实时能量管理策略,其门限规则的制定缺乏数学分析和理论基础,导致很难准确制定。基于优化的能量管理策略分为全局优化和瞬时优化两类。全局优化计算量大且需要知道整个循环工况,所以并不能应用于实车控制,但其仿真结果可在其他控制策略设计时作为参考[2]。全局优化依托的优化方法目前有动态规划(dynamic programming,DP)、粒子群等,其中以DP算法最具有代表性[2-3]。瞬时优化只能求解当前的最优解,或者在滚动预测步长内的最优[4]。为逼近最优解,一般是结合多种优化算法或者采用更智能的算法[5]。如文献[5]针对某功率分流式混合动力汽车,设计了基于粒子群优化算法(Particle swarm optimization,PSO)的具有双层结构的多目标能量管理策略,实现了降低整车油耗和维持电池电量的目标,但是基于瞬时优化方法最终并不一定实现全局最优。
随着AI算法和车联网智能交通技术的发展,越来越多的学者将AI算法,如强化学习,应用到混合动力汽车的能量管理策略的设计,提出适应性更强,控制效果更好的智能能量管理策略[6-10]。研究表明,强化学习算法在混合动力能量管理策略方面的应用具有很好的适用性,经过学习训练可快速自主收敛到全局最优解。文献[9]针对一款插电式混合动力汽车设计了由强化学习框架训练和生成的智能SOC(State of charge)分配策略,研究表明油耗明显低于两种常用的SOC分配策略。自适应动态规划(adapted dynamic programming,ADP)具有DP算法和强化学习两种算法的优势,能在避免“维数灾”的同时使系统自主收敛到一个最优的全局近似解,在无人机控制、航天器控制等研究方向具有广泛的应用[11-12],并取得不错的控制效果。
以国内某双行星排混合动力客车为研究对象,以提高整车燃油经济性和维持SOC平衡为目标,基于Matlab仿真软件,对混合动力客车(HEV)进行整车建模,然后搭建基于ADHDP算法能量控制策略,并在C-WTVC工况下与自适应等效燃油消耗最小控制策略(adapted equivalent consumption minimization strategy,A-ECMS)、基于DP算法控制策略进行仿真对比分析。
1 双行星排混合动力客车建模
1.1 整车结构及参数
基于Matlab仿真软件,对国内某双行星排混合动力客车(HEV)进行整车建模,整车参数见表1。
给定客车车速ua,需求功率Pdem可由下式计算得出:
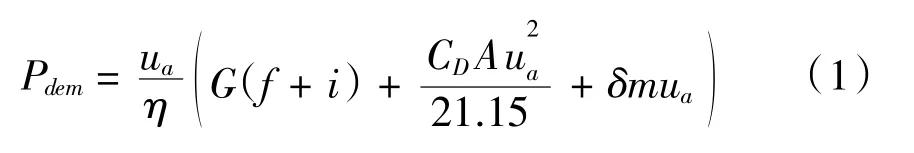
其中,f、i为滚阻系数和道路坡度;CD和A为风阻系数和迎风面积,δ和m为旋转质量系数和整备质量。
1.2 双行星排动力耦合机构分析
整车结构如图1所示,公交车传动系统采用双行星排动力耦合结构,发动机、电机MG1分别与前行星排P1的行星架、太阳轮相连,通过控制b1、b2离合器的开关可实现多种工作模式。电机MG2与后行星排P2的太阳轮相连,后行星排齿圈固定,前行星排P1的齿圈与后行星排P2的行星架相连,经主减速器传递动力至车轮以驱动车辆。

图1 双行星排式混合动力公交车整车结构
不计行星齿轮耦合机构的内部摩擦和转动惯量,根据发动机、电机MG1、电机MG2与前后行星排的连接方式,可推算出输出转速转矩的关系:
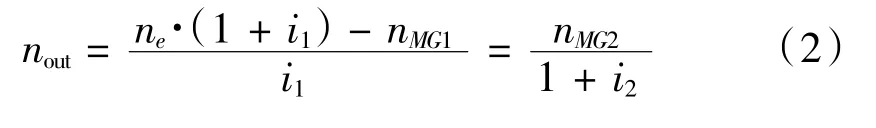

式中,uout、Tout分别为双行星排输出轴的转速和转矩;ne、nMG、nMG2分别为发动机、电机MG1和电机MG2的转速;Te、TMG2分别为发动机、电机MG2的转矩。行星排参数见表1。
1.3 发动机、电机、电池模型
发动机的参数见表1,基于发动机台架数据,通过数值建模得到发动机准静态模型,如图2所示。

图2 发动机燃油消耗率map图
电机参数(表1),MG1和MG2模型也通过数值模型建立,如图3所示。

图3 电机2效率map图
电机转矩为正时处于驱动状态,电机转矩为负时处于发电状态。驱动和发电的电机功率计算分别为:

式中,nm、Tm为电机的转速和转矩,η为电机效率,Pm_dis为电机处于驱动状态时的功率,Pm_chg为电机放电时提供的功率。
电池模型选用电池内阻模型,电池功率计算式为:
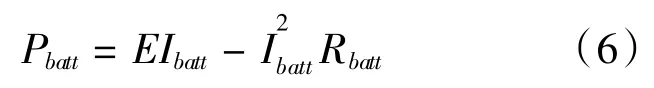
式中,Pbatt为电池功率;E为电池开路电压;Ibatt为电池电流;Rbatt为电池总内阻。E与电池的荷电状态SOC有关,如图4所示。
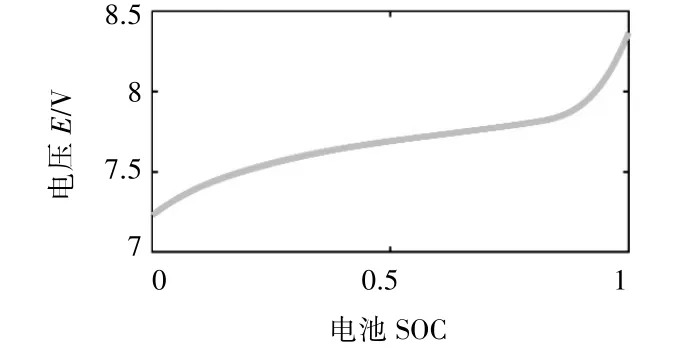
图4 电池模型
由此求得电池电流

则电池SOC可由下式计算:

式中,SOC(t)为电池经过充放电时间t后的S OC;SOC0为电池的起始S OC;CAh为电池容量。
2 控制策略的设计
2.1 动态规划
DP算法是由美国数学家R.E.Bellman等人基于最优性原理提出。应用解决多阶段决策问题的一般步骤为:首先需要对所研究的多阶段决策问题进行阶段的划分;其次需要确定优化过程中的状态变量、控制变量与状态转移方程;最后须确定单个阶段成本函数和全过程的最优目标函数,从而建立动态规划基本方程。

式中,x为状态变量,u为控制变量,L(x0,u0)为单步成本函数,J[x]为系统的总代价函数。
将电池SOC作为优化过程中的状态变量,发动机转速作为控制变量,设计单步成本函数:

fue l(xk,uk)为第k步等效油耗,SOC(k)为电池荷电状态,λ为油电转换系数,则通过递归求解,可获得全局最优的控制变量和电池SOC的最优轨迹。
2.2 基于自适应动态规划算法能量控制策略
2.2.1 基于自适应动态规划算法能量控制策略结构
自适应动态规划(ADP)源于向前动态规划,最早由Werbos首先提出[12],其将执行网(Action)和评价网(Critic)组成一个智能体,Action作用于系统后,基于贝尔曼原理,通过环境在不同阶段产生奖励/惩罚来更新Critic的参数。自适应动态规划具有DP算法和强化学习两种算法的优势,能在避免“维数灾”的同时使系统自主收敛到一个最优的全局近似解。强化学习所研究的是智能体和环境的序贯决策过程,在数学上其规范为一个马尔科夫决策过程(Markov Decision Process,MDP)。一个马尔科夫过程由一个五元组(S,A,P{s|a},γ,R)构成,S表示状态集,A表示一组动作,P{s|a}表示状态转移概率,γ表示折扣因子,R为回报函数。
定义状态集S的三个分量为电池SOC、需求车速ua和需求功率Pdem,并将这三个分量作为执行网的输入,如图所示。定义发动机的转速ne作为系统采取的动作,即为执行网的输出。回报函数R为L(k)函数的期望,如下:
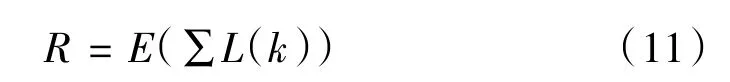
将系统状态集和执行网的输出作为评价网的输入,其输出为系统总代价函数的估计J^,采取TD方法对评价网网络权值进行更新,TD的误差可通过拟合动态规划基本方程获得,该方程为:

式中,EC为TD误差,J^(k)为评价网的输出,即总代价函数的估计值,L(k)为单步成本函数。
根据最优性原理,最优控制应满足一阶微分必要条件,故执行网可通过策略梯度实现网络权值更新。如图5所示。

图5 ADP算法能量控制策略结构
2.2.2 ADP求解过程
基于在“策略改进程序”和“值确定运算”之间循环,ADP算法的求解原理如下:
(1)策略改进程序
策略改进在“执行网”进行,给定一个控制律ui,可计算系统下一个状态转移xk+1和对应的代价Ji(xk+1,ui),则依据下式改进控制律:

式中,ui+1为改进的控制律;L(xk,ui)为系统的效用函数;J(xk+1,ui)为系统在控制律ui作用下从状态xk转移至xk+1的累计成本。
(2)值确定运算
值运算在“评价网”进行,给定一个控制律ui,则代价函数可依据下式更新:

当循环产生两个相同的控制律或着连续的两个控制律相差在一定精度范围内,算法终止。
求解过程应在发动机、电机允许工作的转速、转矩范围之内进行计算:

式中,ne、Te为发动机的转速和转矩;nm、Tm为MG2的转速和转矩;ng、Tg为MG1的转速和转矩。
为了避免出现电池过充过放等不利于电池长期使用的现象和提高电池的充放电效率,需要限制电池始终保持工作在最大充电功率与最大放电功率区间内,同时限定电池的SOC工作区间。
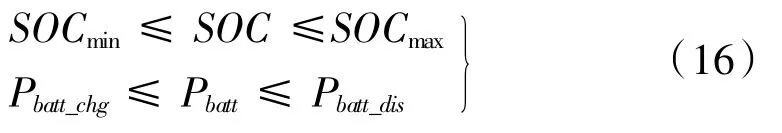
式中,SOC为电池荷电状态;Pbatt为电池功率。
3 仿真分析
在Matlab软件平台下基于C-WTVC工况,对ADP控制策略进行仿真;并将仿真结果与自适应等效燃油消耗最小控制策略(A-ECMS)、DP控制策略的仿真结果进行对比分析。
从图6中可以看出,值确定误差经过1000次训练后,评价网误差稳定在设计2×10-3范围,表明ADP控制策略具有良好的适应性。

图6 评价网误差均值
由图7~11可以看出,三种控制策略在低速工况均倾向于选择纯电动模式,在市区和公路循环的工作模式差别不大;而在高速循环工况下,ADP与DP的选择模式更接近,即更倾向于混动模式,有利于维持SOC的稳定。同时在ADP控制策略下的发动机工作点与DP的也更接近。

图7 DP电机MG2工作点

图8 ADP电机MG2工作点
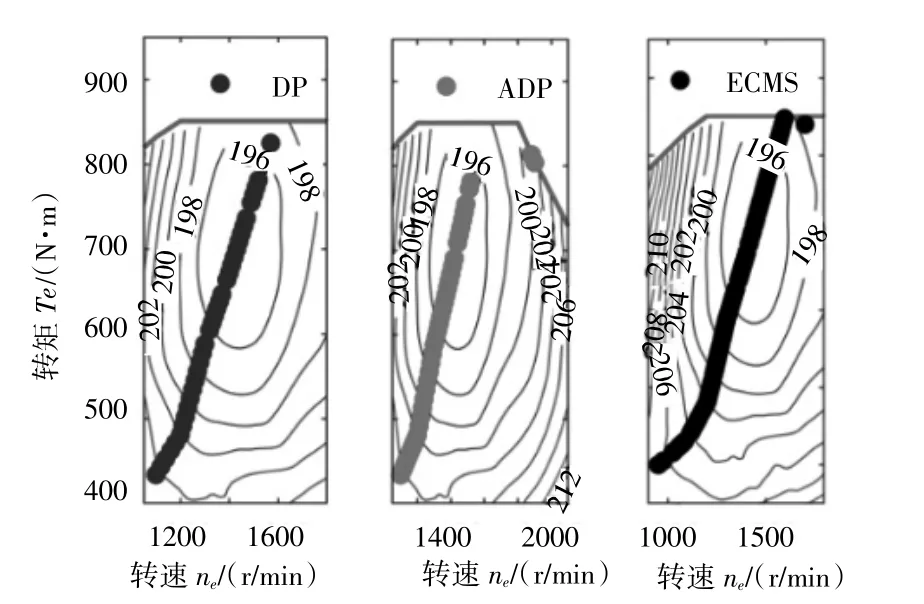
图9 发动机工作点

图10 混动模式占比

图11 仿真电池SOC轨迹
通过分别统计混动模式和纯电动模式在驱动模式的占比可以看出,三种控制策略的混动模式占比均达到47%以上,差距不大(表2)。从原理上分析,深度混动的驱动能量的来源最终是来源于发动机,合理减少纯电动驱动次数,在维持电机对发动机的工作点的调节所需的能量的前提下,可减少能量转换,从而减少能量损失,提升整车燃油经济性。

表2 驱动模式
从表3仿真结果可以看出,ADP和DP在维持SOC平衡方面要优于A-ECMS,虽然电池SOC值均能回到初始值60%附近,但是仿真过程A-ECMS的SOC波动更大。在油耗方面,尽管DP具有优异的表现,百公里油耗仅为15.89 L,但是仿真时长达到了1 h15 min,并不合适于实车控制;而ADP在仿真时间仅需25 s的同时百公里油耗仅为18.12 L,较DP算法控制策略的差距仅为10.77%,展现了其可应用于实车控制的良好前景。

表3 仿真结果
4 结语
(1)经过训练,ADP能量管理策略可快速到全局最优解,展现了ADP算法具有良好的适应性。
(2)三种控制策略在低速工况均倾向于选择纯电动模式,而在高速循环工况下,ADP与DP的选择模式比较接近,即更倾向于混动模式。
(3)ADP控制策略达到了维持SOC平衡的目标的同时,百公里油耗与DP算法控制策略的差距仅为10.77%,具有较好的燃油经济性,拥有可应用于实车控制的良好前景。
