边-云协同下智能制造单元的物联网络协调配置方法
2022-06-10常丰田周光辉李锦涛张超肖忠东
常丰田,周光辉,李锦涛,张超,肖忠东
(1.西安交通大学机械工程学院,710049,西安;2.长安大学工程机械学院,710064,西安;3.西安交通大学管理学院,710049,西安)
工业物联网、无线传感网络、深度学习、云计算、边缘计算等新一代信息技术的迅猛发展和融合促进了制造业的转型和升级,形成了以数据化、网络化和智能化为支撑的具备自感知、自决策、自执行、自适应和自学习的新一代智能制造[1]。为落实和应用智能制造,智能装备、智能单元和智能产线快速发展,网络智能装备数量和产生的数据量急剧增长。然而,传统采用单一的云计算模式,将所有数据通过网络传输到云平台集中式处理的方式已无法满足工业现场实时处理数据的需求,极易造成传输延迟大、宽带压力高、云计算资源消耗严重、不利于隐私保护等问题[2-3]。为弥补云计算的不足,边缘计算得到快速发展。利用边缘计算的就近、实时、短周期数据处理分析能力,结合云计算的全局、长期、海量数据优化管控能力,同时发挥边-云协同价值,已受到企业和学者的广泛关注[4]。
针对离散智能产线/单元,为实现边缘计算和边-云协同,在单元的设备和边缘端往往需要配置大量的感知节点(如传感器、射频识别器(RFID)、超宽频定位器(UWB))和边缘节点,并依赖物联网络采集和传输振动、图像、功率、压力、温度、噪声、电压、电流以及物料位置、状态等信息,同时利用这些信息在边缘侧实现能耗监测、状态评估、物流追踪等实时统计展示和分析处理服务,支撑边-云协同能力的实现[5]。然而,不同的物联网络配置方案,将导致差异化的节点部署结果,从而引起节点间不可靠的数据传输、互联和协同能力。因此,在边-云协同中,考虑网络低时延、高可靠感知、传输和计算的最优配置显得尤为重要。为此:Ma等[6]将消息传输跳数作为影响端到端时延的因素,研究了在跳数约束下基于覆盖的中继节点部署方法;Jiang等[7]研究了基于贪婪策略的最优传感器部署方法;何欣等[8]采用遗传算法确定了最佳节点部署位置,显著降低了网络节点部署成本;Zhu等[9]综合考虑边缘网关的覆盖性、任务计算时延以及网关容量分配等因素,采用改进模拟退火算法对网关部署问题进行了多目标求解;Jiang等[10]综合考虑网络时延、部署成本、空间分布、设备功能、边缘计算能力等因素,采用改进k-means算法获得最优边缘节点部署位置和数量。在这些研究中,时间延迟[9-11]、部署成本[8,10,12]、负载均衡[9,11,13]、网络寿命[14-15]等已成为各学者研究边缘配置的主要因素。然而,大部分研究主要聚焦在基于感知节点的边缘网关配置或整体物联网络的配置等,忽视了感知从节点与边缘主节点间的互相影响和关联协调机制,难以在已有部分节点的基础上,通过对已有节点和扩展节点间的协调配置和部署[16],满足低延迟、低成本和高可靠协同数据的最佳交互,导致物联网络的节点扩展性差,边-云协同能力不足。
针对上述不足,本文以离散智能制造产线的最小生产单元——智能制造单元为研究对象,在提出的边-云协同框架的基础上,构建了边缘物联网络模型。进一步地,利用网络模型,详细研究了基于改进的覆盖的中继节点部署(cover-based relay node placement,CRNP)算法的主节点配置方法和基于贪婪策略的主从节点协调配置方法,为制造单元或企业产线的边-云协同实现或能力提升,提供了节点协调的底层物联配置基础。
1 智能制造单元物联网络模型构建
1.1 智能制造单元系统组成及边-云协同框架
智能制造单元(smart manufacturing cell,SMC)是支持离散智能制造企业实现智能感知、智能决策、智能执行和智能控制等智能生产任务的最小实现单元,同时也是智能制造车间的最小组成单元[17]。典型完备的SMC主要包括加工子系统,物料搬运子系统、仓储子系统、智能采集感知子系统和智能决策云平台系统等软硬件系统。
为充分发挥系统内数控车床、铣床、加工中心、自动导引小车(AGV)和机器人等异构智能装备边缘端生产数据实时、动态、低延时的快速传输、处理、计算、分析和控制能力,同时提升云平台大数据的全局、长期、最优的智能决策和管控能力[18-19],构建设备层、边缘层和云平台层的“端-边-云”3层边-云协同框架,如图1所示。其中:设备层由智能制造单元中的各种物联设备组成,如传感器、摄像头、RFID、数控机床、机器人、AGV等,这些物联设备作为端节点(从节点)通过各种有线网络(如工业以太网、各种现场总线等)或无线网络(如蓝牙、Wi-Fi、RFID等)与边缘层相连接;边缘层由边缘服务器和边缘计算节点构成,边缘层通过物联网络与设备层端节点相连,负责接受、处理和转发获取的设备层数据,并提供协同解析、数据集成、智能感知、隐私保护和实时计算管控等服务;云平台层具备强大的计算和存储能力,对边缘层无法处理的计算任务以及全局信息任务,通过物联网络的收集汇总进行综合地处理、分析以及任务的卸载和下发。
综上可知,为发挥边-云协同效应,充分利用边缘节点的协同计算能力,通过对设备层、边缘层感知和计算节点的最优协调配置,实现物联网络低延迟、高可靠、可互联的最佳部署显得尤为重要。
1.2 边缘物联网络模型构建
基于边-云协同框架,聚焦设备层和边缘层的底层物联网络。首先,将智能制造单元物联网络假设为无线传感网络,网络的节点类型抽象为从节点、主节点和根节点。其中:从节点是设备层配置的传感器和终端设备,负责感知现场设备的实时数据;主节点即边缘计算设备,负责对传感节点数据的预处理及转发,并将数据交付给根节点;根节点即边缘服务器,是整个物联网络的中心,负责控制网络的数据传输及汇总,并与云平台进行数据交互。依据节点类型,给出如下假设。
(1)为满足制造单元的可扩展性,网络的通信方式采用多对一的方式[20],即同级节点不进行通信。
(2)物联网络基于树状网络拓扑搭建,其中根节点作为数据汇入的中心。
(3)由于设备供电以及禁放区域限制,节点的部署位置只能通过预定义的候选部署位置(candidate deployment location,CDL)确定[21]。
(4)制造单元设备间距近,网络传输延迟主要依赖数据从设备节点到边缘服务器的转发次数。
1.2.1 物联网络节点通信建模
Vadj(u)={∀v|cover(u,v)},u,v∈V
(1)
式中cover(u,v)表示u、v节点为近邻节点。
若u、v节点不近邻,要实现两节点的数据通信,就必须要求存在一个V的子集Vcon,Vcon中的节点可以通过两两相邻的方式建立一条u到v的数据通道p(u,v),即
(2)
式中:padj(ri,ri+1)是近邻节点ri与ri+1之间的网络数据通路;Vcon是u到v的节点集合(包含u、v);k是Vcon中u到v的数据通道数。
1.2.2 物联网络传输延迟建模
网络传输延迟是指从数据发送节点到接收节点的网络传输延迟时间,由跳数(转发次数)和单跳转发延迟确定,即
τuv=γuvτ0
(3)
式中:τuv是节点u到v的传输延迟时间;γuv是u到v的跳数;τ0代表单跳传输延迟。
基于数据通信模型,节点转发所经历的跳数可由数据的转发次数表达,而转发次数依赖数据通道p(u,v),即
γuv=H(p(u,v))
(4)
式中H(·)代表数据通道内数据转发所经过的节点数。
依据假设,在制造单元内,传输延迟主要由数据的转发跳数决定。因此,为保证设备间数据通信的延迟最小,可选取转发次数最小(最短路径)的通道pmin(u,v),记为
pmin(u,v)=arg minH(p(u,v))
(5)
1.2.3 物联网络传输可靠性建模
数据传输的可靠性主要依赖于数据包接收率[22],即在发送节点传输范围内,能成功接收来自发送节点数据包的节点数量百分比,其大小主要与节点间的距离有关,故相邻节点u和v间的数据包接收率ψuv可定义为
(6)
式中:duv是节点u、v之间的欧式距离;d0是节点参考距离;B是传输比特总数;η是路径衰减指数;PL(d0)是参考距离下的功率衰减。
在计算实际的数据包接受率时,往往需要依赖于一条完整的数据转发链路,而每一次的数据转发都可能伴随着部分数据的丢失。因此,在路径p(u,v)中数据包接收率的定义为
(7)
式中:ψ(p(u,v))表示u、v节点间整条通信通道的数据包接收率;ψ(ri,ri+1)是通道p(u,v)中某相邻节点间的数据包接收率。
2 基于改进CRNP算法的主节点配置
基于智能制造单元物联网络模型,为实现边-云协同的节点配置,首先需要求配置的主节点在实现所有从节点与根节点数据互联互通的基础上,保证整个网络的时延与通信质量达到指定的标准。依据假设,所有主节点的位置需要从预定义的候选部署位置集合Lm中进行选取。
CRNP算法[6]主要用于解决跳数约束下的中继节点部署问题[23],即:当数据的转发次数受到限制的情况下,通过合理的中继节点布局,可以解决整个网络的连通性问题。为此,本文基于CRNP算法,结合制造单元物联网络特点和节点通信质量约束,在解决整个网络连通性问题的基础上,尽可能地降低传输延迟,提高通信质量,实现网络的优化配置。本文算法的具体步骤如下。
步骤1判断原始网络连通性。建立根节点到各从节点的直接通路,此时对于每一个从节点,其跳数为最小值1,满足跳数约束。如果存在从节点不在根节点的通信范围内或不满足通信质量的条件约束,那么判定原始网络在不添加任何主节点的基础上无法解决各节点间的连通性问题。否则,证明目前的网络已经在满足约束条件的情况实现各从节点与根节点的数据互通,原始网络满足优化配置需求。
步骤2建立连通网络。连通网络的建立是一个迭代的过程,每一次迭代都是建立节点与邻接节点间的数据通信,最终构成所有节点的数据通路。节点的通路选择有最大转发跳数和单跳通信质量要求两个约束限制,其中转发跳数由通信路径内的转发次数确定,单跳通信质量由数据包接收率确定。
针对最大跳数限制,约束条件为
H(pmin(v,vr))≤γmax(u)-1;u∈Vadj(v)
(8)
式中:H(pmin(v,vr))是任一节点v到根节点vr(vr∈Vr)的最短路径的转发跳数;γmax(u)是节点u的最大转发跳数,其中u是v的某一邻接节点。
针对单跳通信质量,约束条件为
ψuv≥ψmin;v∈Vadj(u)
(9)
式中ψmin是u到邻近节点v的最小数据包接收率。
在满足上述约束条件的基础上,连通网络的建立步骤为:
(1)在候选部署位置集Lm中,找到与各从节点最近的主节点位置,配置主节点,建立连接;
(2)进入迭代过程,每一次迭代在上一次迭代的基础上找到一个与主节点最相邻的点建立连接,要求节点间的连接建立需要满足通信质量约束;
(3)迭代完成后,建立从与根之间的数据通路,此时需要进行最大跳数的验证,若超过最大跳数,跳至第(2)步,重新进行路径的选择;
(4)完成连通网络的建立。
步骤3冗余节点优化。在连通网络的建立过程中,只考虑连通性的要求,可能会导致冗余节点的出现,增加额外的网络配置成本。因此,需要对冗余节点进行优化,主要流程如下:
(1)遍历整个连通网络,找到主节点集合Vm;
(2)选择任一个节点u(u∈Vm),将该节点去除,在去除该节点的基础上,验证网络是否依然满足质量约束与连通性准则;
(3)如果满足,则去除该节点,否则对该节点进行还原;
(4)重复第(2)(3)步,直到对所有的节点完成检测,从而去除所有冗余节点。
基于上述步骤,本文提出的改进CRNP算法的整体流程如图2所示。

图2 基于改进CRNP算法的主节点配置流程Fig.2 Master node configuration flow chart based on improved CRNP algorithm
3 基于贪婪策略的主从节点协调配置
基于已有主节点的配置结果,为实现对已有节点和扩展节点的协调配置,提出基于贪婪策略的主从节点协调配置方法,即先通过CRNP算法求解主节点位置,再通过贪婪策略对扩展从节点和补充主节点的协调配置。贪婪策略的主要思路为:①确定问题的最优子结构;②设计迭代方式;③在每一次迭代时,选择局部的最优解;④通过迭代,将局部最优解演化为全局最优解。基于该思路,算法的输入为:需要扩展部署的从节点数量ns,目前已有的物联网络节点集合Vs,Vm和Vr以及从节点的预部署节点位置集合Ls。具体配置要求满足:①不能更改原有节点的位置;②尽可能少地引入新的主节点。
为尽可能减少数据通信延迟,需减少数据传输过程中的转发次数。显然,如果在与根节点最近主节点的近邻区域部署从节点,则新部署的从节点会具有最小的数据转发次数。因此,每一次从节点的部署需要选择到根节点具有最小跳数的主节点,再从这些被选中节点中,挑选一个满足通信质量要求的近邻位置(从Ls中选择)来部署从节点。
到根节点跳数最小的主节点集合可表示为
Vmmin={∀vm:Vm|arg minH(p(vm,vr))}
(10)
式中H(vm,vr)是vm到vr的数据转发跳数。
从节点的整个部署过程是一个迭代过程,令Vsnew(i)为第i次迭代的新部署从节点集合,则
(11)


(12)

(13)
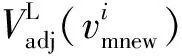
综上,新部署从节点的迭代求解过程为
(14)
基于上述算法模型,构建基于贪婪策略的主从节点协调配置流程图,如图3所示。
图3 基于贪婪策略的主从协调配置流程Fig.3 Master-slave node coordination configuration flow chart based on greedy strategy
基于贪婪策略的主从节点协调配置流程具体如下。
步骤1输入需要部署的从节点数量ns、当前网络节点集合Vs、Vm和Vr以及从节点的预部署节点位置集合Ls。
步骤2对Vm中的所有节点按照到跟节点的跳数大小进行分组,并按照升序排序。
步骤3依次从跳数最小的分组中选择主节点,在选中的主节点附近搜索与之近邻且满足通信质量要求的CDL位置,选择这个位置进行从节点的部署。
步骤4检测是否完成所有从节点的部署,如果完成,则跳至步骤7,否则跳至步骤5。
步骤5检测现有的主节点是否还有近邻的CDL,如果有,则跳至步骤2进行下一次迭代,否则跳至步骤6。

步骤7算法结束,输出新部署的主节点集合和从节点集合的所有位置。
4 案例研究
本文以中国西部科技创新港智能制造创新中心的智能制造单元——数字孪生制造单元(DTMC)[17,24]为应用对象进行案例验证。该单元主要用于微型涡喷发动机叶轮等复杂零件的智能加工,由数控加工中心、数控铣床、工业机器人、工业AGV、仓储货架、边缘服务器等装备以及数字孪生系统等构成。该单元通过对边缘感知节点、计算节点和物联网络的部署和计算,利用边-云协同实现加工过程的视频监测、零件加工状态追踪、能耗统计、产量统计以及虚实同步等。制造单元的主要设备布局如图4所示。以单元的边缘服务器为原点,建立物联网络坐标系,测量得到相关设备的具体位置坐标,如表1所示。依据该坐标,可以明确传感器等从节点和边缘计算主节点的可部署区域和禁止部署区域,从而确定预定义的候选部署位置集合Lm。

图4 数字孪生制造单元主要设备布局Fig.4 Equipment layout for DTMC
4.1 数字孪生制造单元边缘主节点配置实例
为保证主节点电源供应,且考虑到制造单元的部署区域,只能在预定义节点集中选择满足要求的位置部署相应的主节点。依据表1,制造单元的设备布局位置、禁止部署区域(红色)、可部署区域(绿色)如图5所示。禁止部署区域主要考虑机床占用,可部署区域主要考虑电源供应。

表1 制造单元设备坐标信息

图5 数字孪生制造单元主节点可部署区域示意Fig.5 Deployable area of master nodes in DTMC
为保证通信质量和时延,限制设备的最小接收率ψmin为93%、数据转发的最大跳数为5,其他参数如表2所示。CDL位置可在部署区域内进行随机选择,每个区域的CDL节点数目设置为100。
经测试,制造单元现场设备的单跳网络传输延迟τ0约为1.5 ms,则网络最大传输延迟限制为τmax=γmaxτ0=7.5 ms。进行20组实验,得到主节点物联配置的测试结果,如图6所示。同时,为验证配置的合理性和有效性,将本文提出的改进的CRNP算法与最小路径树(shortest path tree,SPT)算法[25]、传统CRNP算法进行比对。SPT算法主要是通过确定数据转发的最小跳数在设备节点与跟节点间形成数据通路,在节点选择的过程中,不考虑其他约束条件。传统CRNP算法仅考虑了跳数约束,未综合考虑通信质量等约束。各算法的对比结果如图6所示。可以看出:在主节点部署上,SPT、CRNP和改进CRNP的平均值部署数量分别为11.1、4.2和5.1个主节点;在传输延迟上,三者的平均传输延迟为4.69、6.35和6.22 ms;在数据包接收率方面,三者的平均接收率为91.6%、91.7%和94.2%。

表2 物联网络参数列表

(a)主节点数量

(b)传输延迟

(c)数据包接收率

(d)改进CRNP的综合评价指标图6 主节点物联配置实验测试结果及对比分析Fig.6 Experimental test results and comparison analysis of master nodes configuration
由以上测试结果可知:在主节点数量上,CRNP算法和改进CRNP算法由于考虑了冗余节点的去除,主节点配置数量明显比SPT算法的结果更少(分别减少了7和6个主节点),网络部署成本更小;在网络传输上,SPT算法的时延较小,但CRNP算法和改进CRNP算法遵循了最大跳数限制,满足时间延迟7.5 ms的实际要求;在数据包接收率上,改进CRNP算法由于考虑最低接收率93%的限制,会得到较大的数据包接收率(分别比SPT算法和CRNP算法提升2.6%和2.5%)。综合来看,相比SPT和CRNP算法,本文提出的改进CRNP算法可以在满足传输时间限制的条件下,得到具有较少主节点个数和较大数据包接收率的配置结果。同时,在改进的CRNP算法中,为获取最小部署成本、最小时延和最大数据包接收率,选取综合评价指标φ作为评估标准,即
(15)
式中:ψ是配置网络最大数据包接收率;τ是配置网络最大传输延迟;nm是主节点数量。
依据图6(d),选取具有φ最大值的第3组实验(nm=5,τ=6.0 ms,ψ=94.5%)作为最终配置结果,此时各主节点的坐标及实际部署结果如图7所示。

(a)单元主节点配置坐标示意

(b)单元主节点部署结果示意图7 基于第3组的主节点配置坐标和部署结果Fig.7 Configuration coordinates and actual deployment results from the 3rd experiment
4.2 数字孪生制造单元主从节点协调配置实例
为获取AGV实时位置、追踪工件状态、监测设备能耗,在制造单元内需扩展4个UWB位置传感器、2个RFID传感器和4个能耗监测传感器。各传感器节点作为物联网络从节点,由于所在设备和功能区域部署空间限制,需要在指定的区域内进行部署,故设定RFID、UWB和能耗传感器的部署半径分别为60、30和40 cm,具体可部署区域如表3所示。
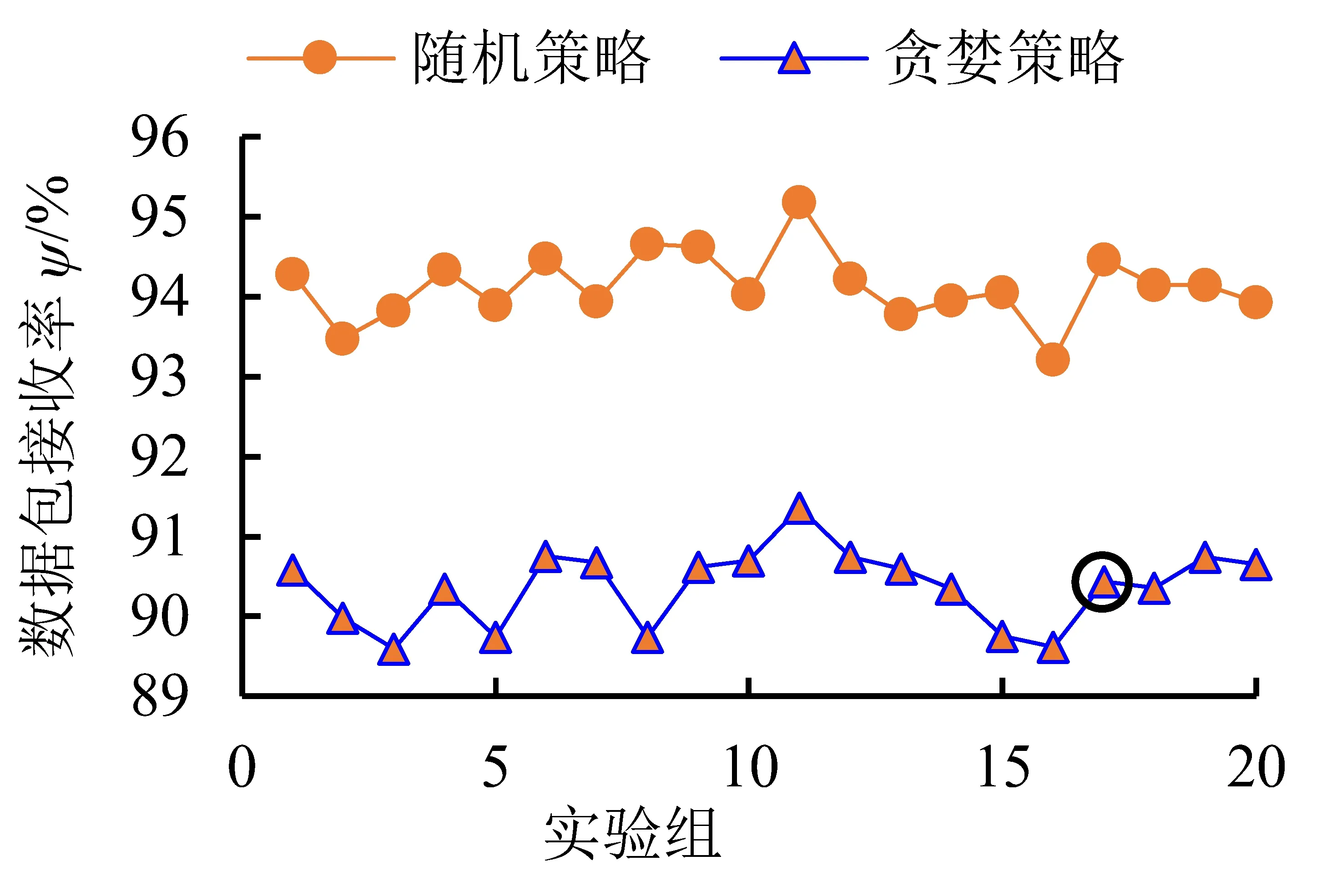
为验证方法的有效性,使用贪婪策略和随机策略两种方法进行对比。在贪婪策略中,首先按照改进CRNP算法进行初始主节点配置,再使用基于贪婪策略的配置算法进行主从节点的协调配置;在随机策略中,首先在区域内随机选择位置部署从节点,再由改进CRNP算法进行主节点的物联配置。两组方法共用同一组的CDL节点集,其网络参数与表2保持一致。实验测试结果如图8所示。
从图8可以看出:在主节点部署数量上,随机策略和贪婪策略平均为6.95和5.7;在传输延迟上,二者的平均传输延迟分别为6.01和5.2 ms;在数据包接收率方面,二者的平均值为94.1%和90.4%。由于贪婪策略更充分地运用了网络中已有的边缘设备,因此在配置数量方面相比于随机策略可以配置更少的主节点(少部署1.25个主节点)。同时,由于贪婪策略优先选择离根节点最近的主节点进行配置,因此链路的传输延迟更低(比随机策略低0.9 ms)。但是,相比于随机策略,贪婪策略因主节点数量少和节点间密度较低,导致协调配置的网络通信质量(数据包接收率)相对较低。在贪婪策略下,依据图8(d)中φ的计算结果,选取具有φ最大值的第17组实验(nm=5,τ=5.16 ms,ψ=90.44%)作为最终结果,各从节点在网络中的配置坐标和部署结果如图9所示。

表3 数字孪生制造单元从节点可部署区域位置

(a)主节点部署数量

(b)传输延迟
(c)数据包接收成功率

(d)改进CRNP的综合评价指标图8 从节点配置实验测试结果及对比分析Fig.8 Experimental test results and comparison analysis of slave node configuration

(a)单元主从节点协调配置坐标示意

(b)主从节点协调部署结果示意图9 基于第17组的主从节点协调配置坐标和部署结果Fig.9 Coordinated configuration coordinates and actual deployment results from the 17th experiment
5 结 论
本文以智能制造单元为研究对象,结合边-云协同框架构建了边缘物联网络模型,提出了基于改进CRNP算法的边缘主节点配置方法和基于贪婪策略的主从节点协调配置方法,结果表明:
(1)对已有从节点的主节点配置、改进CRNP算法的配置方法可以在满足时延约束的前提下减少主节点数量,提升数据包接收率;
(2)对已有主节点的主从节点进行扩展性配置,结合CRNP和贪婪策略的协调配置方法,可以减少主节点配置数量,降低传输延迟;
(3)在物联网络多节点配置中,改进CRNP算法和贪婪策略的提出和引入可以提供低成本、低时延和高可靠性的底层物联配置方案,从而为智能制造产线/单元边-云协同的实现或改进提供基础支撑。
