耦合注意力机制DNN的PM2.5估算及时空特征分析
2022-06-09陈镔捷叶扬林溢游诗雪邓劲松杨武王珂
陈镔捷,叶扬,林溢,游诗雪,邓劲松,3,4,杨武,4,王珂
1.浙江大学环境与资源学院,杭州310058;
2.浙江工业大学环境学院,杭州310014;
3.浙江生态文明研究院,安吉313300;
4.浙江大学智慧生态与绿色发展研发中心,杭州310058
1 引言
PM2.5是指悬浮于空气中的空气动力学直径小于等于2.5 μm 的细颗粒物干质量浓度。有大量研究表明,由于PM2.5能够进入到人体呼吸道深处,同时极易附着大量有毒有害物质,长期暴露在较高PM2.5环境中,会导致人类寿命的缩短,以及各种呼吸疾病、心血管疾病的发生(Dockery 等,1993)。在最新全球疾病负担(Global Burden of Disease Study)调查中,PM2.5造成的死亡人数及其影响位列所有环境和职业风险因子中的首位(GBD 2019 Risk Factors Collaborators,2020)。此外,PM2.5也是造成灰霾的主要原因,是最直观反映环境质量的要素之一。
自改革开放以来,中国经济发展迅速,快速工业化和城镇化进程中不可避免地对环境造成了污染。尽管自2013年以来政府出台了一系列相关政策来控制与监测空气质量,地面监测站的覆盖范围也越来越大,但是这些地面固定站点更多分布于城市中,对于全方位监测空气质量还是过于稀疏。卫星遥感技术的蓬勃发展,使得对空气站点缺失区域的空气质量监测成为可能,为环境空气质量的大面积同步监测提供了全新的技术手段。利用卫星遥感获得的气溶胶光学厚度(AOD)产品,构建AOD-PM2.5的模型来估算全域PM2.5,可以有效弥补地面站点相对稀疏的缺陷,获得更大范围时空连续的空气质量数据。目前,常用的AOD产品有:中分辨率成像光谱仪(MODIS)、先进的葵花成像仪(AHI)、可见光红外成像辐射仪(VIIRS)的气溶胶产品,空间分辨率在1 km 左右;也有学者利用Landsat、高分一号等卫星获取高空间分辨率的AOD产品,但其重返周期较长,应用相对受限。而MODIS 卫星自2000年起即有观测数据,同时能够提供每日的全球覆盖数据,因此其AOD产品被广泛应用于空气质量的估算研究中。MODIS 卫星提供的AOD 产品经过较长时间的发展,已经从最初的MOD04 暗像元算法产品,发展到最新的多角度大气校正算法(MAIAC)AOD 产品,精度提升的同时空间分辨率也从10 km提升至1 km(Lyapustin等,2018)。
准确构建AOD 与PM2.5的关系模型是估算空气质量的关键。初期,学者尝试基于物理机理进行关系的构建,包括对AOD 的湿度、标高及细模态粒子比例的订正等,建立具备严密逻辑的物理关系方程(Li 等,2016;Lin 等,2015;张莹和李正强,2013)。但由于物理机理过程复杂,模型中大量参数难以获得,只能依靠近似的计算,存在较大的不确定性,精度一般较低。随着地面PM2.5观测数据的日渐增多,越来越多的学者利用高效的统计模型,同时结合大量辅助因子来建立AOD 与PM2.5的关系。多元线性回归模型最先被用于AODPM2.5关系的构建,但由于AOD 与PM2.5呈非线性关系,关系较为复杂,简单的线性回归模型无法很好地拟合这一关系(Liu等,2007)。马宗伟(2015)、Just 等(2015)、杨立娟等(2018)利用线性混合效应模型(LME)和广义加和模型(GAM),并结合气象要素、土地利用类型等参数建立更为复杂的非线性模型,估算得到的PM2.5浓度精度大幅提升。He 和Huang(2018)利用地理加权回归(GWR)及其改进版本模型,开展了PM2.5浓度模拟研究,同样取得了优于简单空间插值与线性回归的结果。近年来,机器学习算法得到了快速发展,相比于传统的统计模型,机器学习模型有更强大的非线性拟合能力,因此也被广泛应用于大气环境质量研究中。Zang 等(2019)利用广义回归神经网络结合AOD、气象要素、高程(DEM)、归一化植被指数(NDVI)等因子模型估算了全国PM1.0的浓度。Wei等(2020)构建时空极端回归树模型估算得到全国长时序的PM2.5空间分布产品,同样用到了大量的辅助因子数据。
尽管这些模型都取得了不错的效果,但由于大气环境的时空异质性较强,参数固定的机器学习模型难以捕获AOD 与PM2.5随时空变化的关系(Fang 等,2016),一定程度上限制了机器学习模型的可推广性。注意力机制是一种广泛应用于自然语言处理,计算机视觉任务中的结构,其目的为使模型能够动态地将注意力放在感兴趣的区域,即动态识别更重要的因子,进而增强模型的鲁棒性与解释性(Vaswani 等,2017;朱均安,2020)。为解决参数固定的机器模型无法考虑时空异质性的问题,本研究提出一种结合注意力机制的深度神经网络模型(DNN)来构建AOD-PM2.5的关系,模型中的注意力机制能够在时空动态中识别对于建模影响更为重要的因子,从而估算得到更可靠的PM2.5浓度。此外,本研究选取的辅助因子除了常规的DEM、NDVI 和气象要素等因子外,还加入了针对于中国人民生产生活习惯的农历日因子。最后利用这些数据构建得到AOD-PM2.5的关系模型,估算长三角区域2015年—2020年PM2.5浓度的时空分布,探索长三角区域空气质量的时空变化特征。
2 研究区和数据
2.1 研究区概况
研究区为长三角地区包括“三省一市”,即江苏省、浙江省、安徽省和上海市,其作为一带一路和长江经济带的交汇地带,是中国经济最为发达的区域之一,同时也是空气污染相对严重的区域之一。随着城市区域的不断扩张和人口的不断聚集,长三角区域高密度人口更易受到空气污染的影响,因此也对空气污染的监测提出了更高的要求。利用卫星遥感手段对长三角区域空气质量进行全域估算,能够弥补地面站点的缺陷,从而更科学地指导长三角地区空气污染防治政策的制定,分析空气污染对人体健康的影响。研究区地理空间范围与PM2.5监测站点分布如图1所示。

图1 研究区范围与PM2.5监测站点分布Fig.1 Study area and distribution of PM2.5 monitoring sites
2.2 AOD数据
本研究采用MODIS 卫星最新的MAIAC 气溶胶产品,相比于此前版本的MOD04 气溶胶产品,MAIAC AOD 具有更高的空间分辨率(1 km),更高的数据质量与更广的覆盖范围,能更好地用于PM2.5的估算。覆盖长三角区域自2015-01-01—2020-12-31 的每日MAIAC 数据从NASA 网站下载获得(https://ladsweb.modaps.eosdis.nasa.gov/[2021-05-30]),通过重投影和裁剪操作,提取获得研究区范围内的AOD 值。由于已经有大量研究验证了MAIAC AOD 在长三角区域的精度,本研究不再对其精度进行验证(Xiao等,2017)。
2.3 地面PM2.5监测数据
2015-01-01—2020-12-30 每日的逐小时地面PM2.5监测数据来源于国家生态环境部的“全国城市空气质量实时发布平台”(http://www.cnemc.cn/[2021-05-30]),选取研究区范围及周边共计352 个国控空气质量监测站点作为本研究的地面观测PM2.5浓度数据来源(图1)。
2.4 其他辅助数据
气象条件对PM2.5的形成与扩散有重要的影响,本研究所用气象数据来源于欧洲中期天气预报中心ECMWF(https://cds.climate.copernicus.eu/,[2021-05-30])最新发布的第五代全球气候再分析数据集ERA5,从中提取2015年—2020年每日的地表2 m处气温(T2M)、地表10 m 处东西向风速(WU)、南北向风速(WV)、相对湿度(RH)、行星边界层高度(PBLH)、地表气压(SP)作为构建AOD与PM2.5关系模型的气象参数,空间分辨率为0.125°。此外,数字高程模型(DEM)从地理空间数据云(http://www.gscloud.cn/[2021-05-30])上获得,空间分辨率30 m。2015年—2020年每月的1 km分辨率NDVI同AOD数据从NASA网站下载获得。
2.5 数据预处理
由于AOD 受云等干扰存在大量缺失现象,导致无法获得全域覆盖的结果,为解决这一问题,本研究利用ECMWF 的再分析数据中的550 nm AOD 与现有每日MAIAC AOD 建立线性关系模型,进而插补得到每日完整的MAIAC AOD 数据,再进行后续AOD-PM2.5建模。将AOD 插补结果与AERONET 地面站点进行验证,结果显示插补前二者相关系数(R)为0.85,均方根误差(RMSE)为0.17,插补后R为0.76,RMSE 为0.28,尽管精度略有下降,但仍可以满足后续使用要求。由于气象数据、DEM、AOD与NDVI空间分辨率各不相同,而模型的构建需要这些数据一一对应,因此将所有栅格数据统一利用双线性插值法重采样至与MAIAC AOD 相同的1 km 分辨率。地面监测的PM2.5数据可能存在由于设备故障导致的数据缺失,为保证数据精度,剔除每日观测数小于12 个小时的数据,再对剩余的数据进行日均值的计算。由于1 个1 km 栅格内可能存在多个地面站点,计算这些站点的均值作为该栅格最终地面实测PM2.5日均浓度。将所有预处理完的数据,进行时空匹配,即根据每日PM2.5站点数据,提取其所在栅格的包括气象数据,DEM,AOD 与NDVI的对应数据结果,构建模型所需数据集。最后对数据集进行Z-score 标准化处理,使得每个因子的均值为0,标准差为1。
3 研究方法
本研究基于DNN 加入注意力机制构建了自适应深度神经网络模型SADNN(Self-Adaptive DNN)对AOD-PM2.5的关系进行建模。DNN属于机器学习模型的一种,由一个输入层,多个隐藏层和一个输出层构成,每一层又由不同个数的神经元构成,层内神经元互不连接,层间神经元通过全连接与激活函数的组合,对数据进行非线性的变换(LeCun等,2015)。DNN 的这种结构可以使模型学习到数据的多层次抽象特征,拥有强大的非线性拟合能力,从而表达复杂的模式,其基本原理可表示为
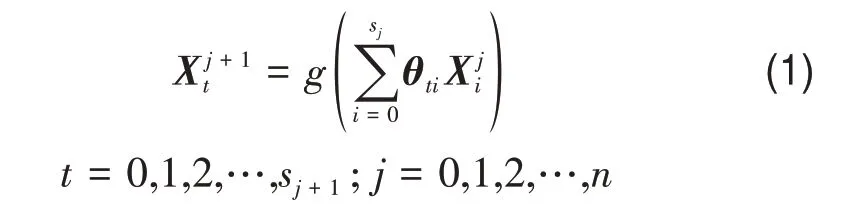
DNN 模型的训练通过后向传播更新神经元间的权重实现,早期的激活函数(如Sigmoid)和后向传播算法(如随机梯度下降)容易出现梯度消失或弥散的情况,导致深度模型难以训练,因此只能训练浅层模型,如人工神经网络(ANN)。将整流线性单元(ReLu)作为激活函数,利用均方根传播(RMSProp)算法进行后向传播的计算可以有效地缓解这一现象,同时加快训练速度,使得DNN 的训练成为可能(Reddy 等,2018;Nair 和Hinton,2010)。因此本研究激活函数选用ReLU,后向传播算法选择RMSProp。
注意力机制最早被提出应用于自然语言处理任务上,它能够自动识别上下文的依赖关系,进而提升模型的准确性,同时使得用户能够了解模型识别了哪些关键词语来理解整个句子,增强了模型的可解释性(Vaswani 等,2017)。在语音情感识别(Speech emotion recognition)研究中,注意力机制能够在一大段语音中识别目标情感的关键区域,提取关键情感特征(Li 等,2021)。随后注意力机制也被广泛迁移至计算机视觉任务中,注意力机制在计算机视觉中可分为空间注意力和通道注意力,空间注意力能够寻找图片中对于结果最重要的部位,通道注意力机制的本质在于构建不同通道特征之间的重要性的模型,对输入进行特征分配,选择对任务更有用的特征(Fu 等,2019;朱均安,2020)。此外,在遥感应用上,Ye等(2019)结合了空间注意力和通道注意力对遥感影像中的建筑物进行了高精度提取;Mou 和Zhu(2020)提出光谱注意力模块,对超光谱数据的各个波段进行校正,对重要的波段赋予较大权重,不重要的波段赋予较小权重,以获得更好的地物分类精度。注意力机制的原理为首先通过全连接层识别因子间的相互关系,然后通过一定的变化函数如Sigmoid 函数计算得到每个因子的重要性,最后将原始因子与重要性相乘即得到校正后的特征,Sigmoid表示如下:

式中,g(z)为变量z的Sigmoid 函数,e 代表自然常数。
本研究将注意力机制融入到DNN 中,构建SADNN 模型,其目的就在于识别对于PM2.5的估算更重要的特征,进而更好地构建AOD-PM2.5关系。输入的因子首先经过注意力机制的校正,对原始因子中重要的部分赋予一个较高的权重,不重要的部分赋予一个较低的权重,随后输入因子与其对应的权重相乘得到校正后的因子,再输入到后续网络中。这样模型即可以自适应地时空动态校正各输入因子,从而捕获AOD-PM2.5关系的时空异质性。模型结构采用启发式搜索确定,将隐藏层的层数设为1,并以1 为步长进行迭代训练验证,隐藏层神经元从16个开始,每次增加1倍。最终综合考虑模型精度与效率,确定为包含4个隐藏层,每层1024个神经元的结构,整个SADNN模型结构如图2。
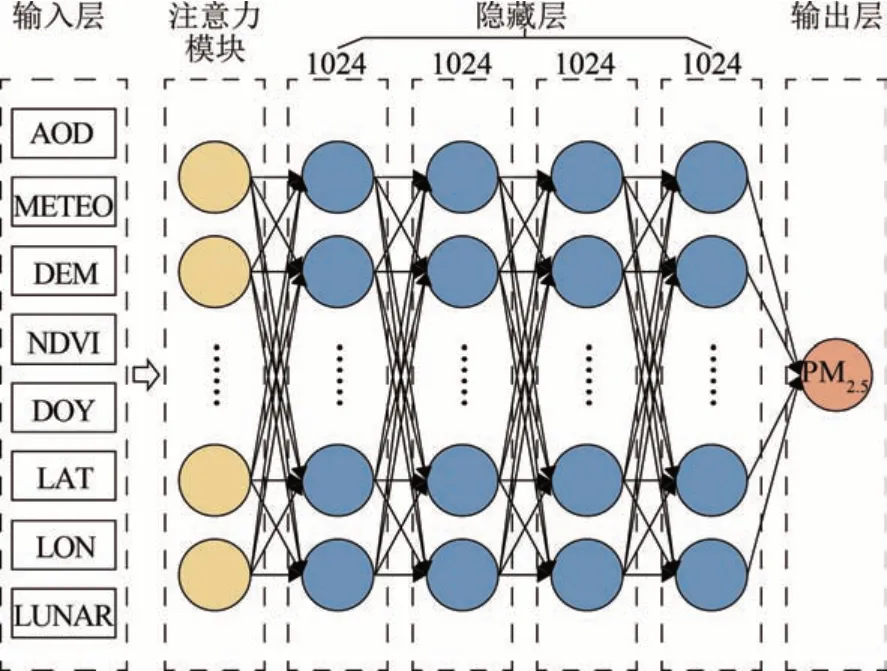
图2 SADNN模型结构Fig.2 The structure of SADNN model
模型的输入因子除了AOD、DEM、NDVI 和上述提到的气象因子外,还加入了积日(DOY)、经度(LON)和纬度(LAT),此外还加入了针对于中国人民生产生活习惯的农历日(LUNAR)作为一个因子,来更好地体现人为活动对PM2.5浓度的影响。农历作为中国传统历法,根据月相变化进行编排,既能反映季节变化,又指导着物候和农事。此外,中国许多法定节假日根据农历安排,影响着人们的生活习惯,例如大年三十与正月初一,中国普遍存在集体燃放烟花爆竹的习俗,会对大气环境造成严重的影响。模型可表示为

式中,PM2.5st表示栅格s在时间t时的日均PM2.5浓度,METEO表示气象因子,包括前文提到的T2M、WV、WD、RH、PBLH和SP。
此外本研究利用上述相同因子,构建多元线性回归模型与随机森林模型进行对比分析。多元线性回归模型是构建AOD-PM2.5关系的最基础模型(Liu等,2007),可表示为

式中,α为截距,β1,β2,…,β8为每个因子的斜率。
随机森林是近年最为流行的机器学习模型之一,它通过集合多个决策树的结果,以有放回抽样的方式进行训练,能够快速准确地学习数据模式,进行回归或分类,被广大学者用于PM2.5浓度的估算中(Hu等,2017)。其作为非参数模型,公式表达同式(3)。
模型精度的定量评价选取决定系数(R2)、均方根相对误差(RMSRE)、均方根误差(RMSE)和平均绝对误差(MAE)作为指标,公式如下

式中,n代表数据个数,yi,Meas代表第i条实测PM2.5值,yi,Esti代表第i条估算的PM2.5值,--- -----y,Meas代表所有实测PM2.5的平均值。
模型的验证采用5折交叉验证:将整个数据集随机平均分为5 份,轮流选取其中1 份作为验证集,剩余4份作为训练集进行模型的训练,最后将5 次结果进行整合得到最终的模型精度。通过不同模型的比较,选取验证精度相对最优的模型,作为最终确定的模型。再利用完整的数据集,对确定的模型进行训练,应用于后续长三角区域PM2.5的估算,得到研究区域的PM2.5时空分布。
4 结果和分析
4.1 模型精度验证
将2015-01-01—2020-12-31 研究区范围内所有数据清理整合,最终得到有效匹配数据共341768 条用于模型的训练、验证与比较,结果如图3所示。本研究提出的SADNN 模型交叉验证结果R2高达0.85,RMSE 为12.77 μg/m3,RMSRE 为0.35,MAE 仅8.22 μg/m3。作为流行的机器学习模型,随机森林也达到了一个不错的验证结果,R2为0.82,RMSRE 为0.36,但其拟合线的斜率(0.74)相比于SADNN 的0.86 要低不少,说明随机森林模型更易低估PM2.5高值,其估算能力相对较弱。传统的多元线性回归模型表现最差,不能很好地对AOD-PM2.5关系进行建模,R2仅为0.30,RMSRE 与RMSE 分别高达0.78 与27.25 μg/m3。由此可见,本研究提出的SADNN 模型利用注意力机制与深层网络模型结构,通过对大规模数据模式的学习,对于估算PM2.5的浓度相较随机森林和多元线性回归模型更为精准,误差更小,有更高的应用与推广潜力。

图3 不同模型交叉验证结果Fig.3 Cross-validation results for different models
为进一步说明注意力机制与农历日因子的有效性,同时验证SADNN 模型对历史逐日PM2.5浓度估算的能力,选取2016-02-06—2016-02-08(腊月廿八、除夕与春节)3 d 的不同模型估算结果进行对比分析,模型包括SADNN、不含农历日因子的SADNN(SADNN-noLunar)、不含注意力的SADNN(SADNN-noAtt)(图4)。与地面站点的对比验证显示,腊月廿八、除夕与春节SADNN 的R2分别为0.78,0.73,0.68;SADNN-noLunar 的R2分别为0.72,0.73,0.60;SADNN-noAtt 的R2分别为0.75,0.73,0.64。可以看到,3日中除了除夕3 个模型站点验证结果不相上下外,其余二日SADNN 模型的结果要明显更优,加入农历日因子后二日R2有0.06 和0.08 的提升,加入注意力后二日R2提升了0.03 和0.04。除夕深夜与春节凌晨中国有燃放烟花爆竹的习俗,极易导致春节白天空气质量的显著下降,加入农历日因子的模型更好地捕捉了这一特征。从空间分布趋势来看,SADNN 模型在腊月廿八成功估算了浙江北部的高值区域,另外两个模型估算的高值区域明显偏小。除夕当日江苏省空气污染严重,地面监测站大部分都超过80 μg/m3,尽管3 个模型与地面站点验证结果表现不相上下,SADNN 对江苏省高值区域的估算要明显优于另外两个模型。春节当日,SADNN-noAtt在安徽西南山区有错误的高估,而SADNN-noLunar对研究区北部的高值区域有明显的低估。综上所述,农历日因子和注意力的加入能够对模型起到一定程度的优化作用,尤其是在PM2.5的高值区域和空间细节方面,同时模型在单日PM2.5的空间估算上与地面站点有较强的一致性,能够较为精准地估算研究区范围每日PM2.5的浓度。


图4 不同模型对2016年典型日期的PM2.5估算Fig.4 PM2.5 estimation for different models at typical days in 2016
4.2 年际PM2.5浓度时空分布特征
基于SADNN 模型估算得到的每日PM2.5浓度数据,计算长三角区域2015年—2020年每年的PM2.5浓度均值时空分布,结果如图5所示。估算的PM2.5浓度空间分布上与地面观测站点保持一致,整体呈现北高南低的趋势,安徽省与江苏省空气污染更为严重。2015年—2020年估算得到的长三角区域PM2.5均值分别为:44.88 μg/m3、40.91 μg/m3、41.27 μg/m3、39.34 μg/m3、37.64 μg/m3、34.07 μg/m3,除2017年较2016年有小幅反弹外,整体空气质量在逐年改善。2015年,研究区内除黄山区域和浙江南部山区PM2.5浓度低于国家二级标准所规定的35 μg/m3外,其余内陆地区都远超这一标准,空气质量不容乐观。2016年PM2.5浓度整体下降约4 μg/m3,其中以杭嘉湖及其周边区域最为明显。2017年年均PM2.5浓度的小幅反弹主要由于安徽省空气质量变差导致了整个研究区平均浓度的上升(王学梅,2020)。随着2018年《打赢蓝天保卫战三年行动计划》的发布,长三角地区作为全国重点区域之一,大力推进产业绿色发展,优化能源结构,严格管控措施,2018年—2020年空气质量改善明显,2020年长三角区域PM2.5浓度年均值已低于国家二级标准,治理成效显著(http://www.mee.gov.cn/zcwj/gwywj/201807/t20180704_446068.shtml[2021-05-30])。
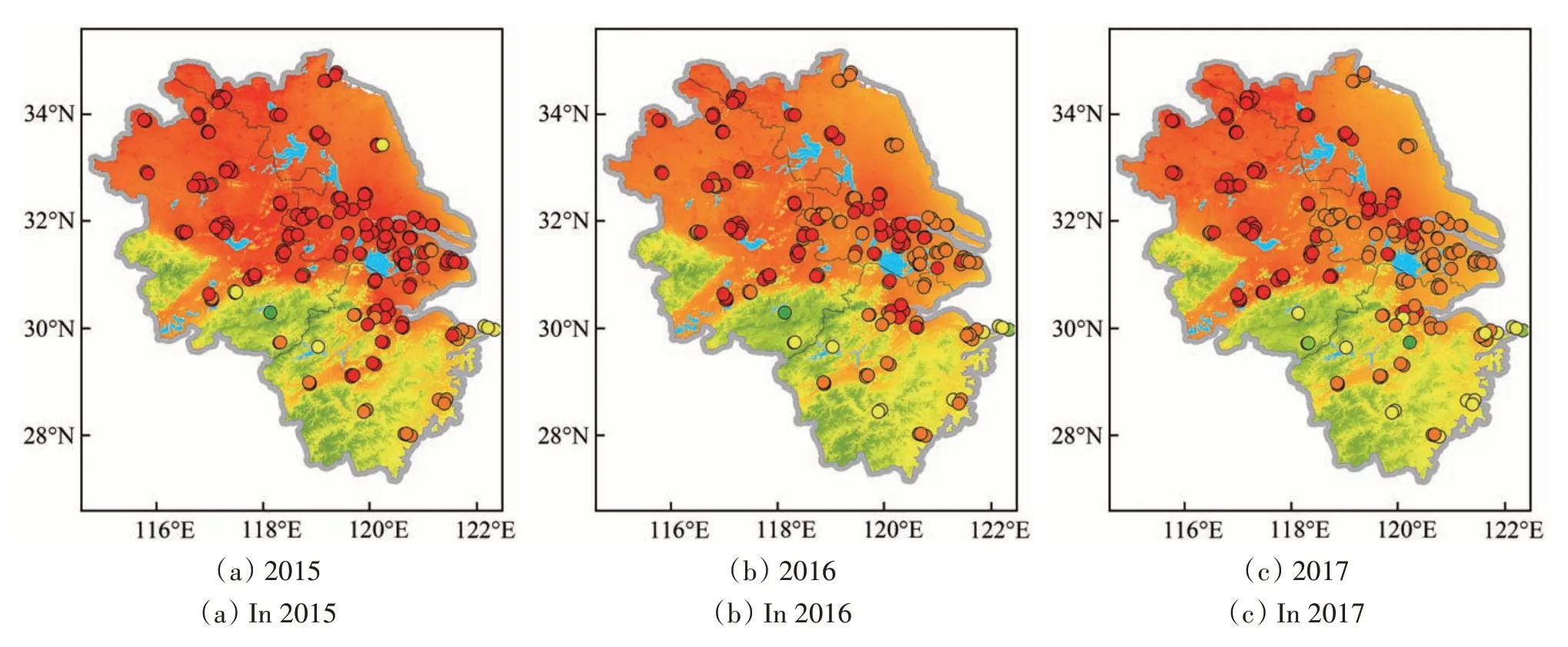

图5 长三角区域PM2.5浓度年际分布Fig.5 Annual PM2.5 concentration in the Yangtze River Delta.
4.3 季节PM2.5浓度时空分布特征
为分析长三角区域PM2.5浓度在不同季节的时空分布特征,本研究采用四季分类法将3、4、5月作为春季,6、7、8月作为夏季,9、10、11月作为秋季,12、1、2月作为冬季,对上述估算得到的2015年—2020年每日PM2.5数据进行整合,得到四季的PM2.5浓度均值(图6),与地面站点也同样具有较高的一致性。长三角区域季节PM2.5浓度整体上为冬季最高(58.35 μg/m3),春季次之(40.18 μg/m3),其后为秋季(36.32 μg/m3),夏季浓度最低(25.37 μg/m3)。地面站点季节趋势相同,PM2.5浓度均值分别为:冬季最高(68.58 μg/m3),春季次之(46.42 μg/m3),其后为秋季(41.44 μg/m3),夏季浓度最低(31.23 μg/m3)。冬季由于华北地区污染物传输、不利的气象条件和供暖因素,从而导致空气质量变差(马宗伟,2015;Xie 等,2015)。长三角区域夏季对流天气强,雨水丰富,污染物沉降和扩散条件较好,因此夏季PM2.5浓度在四季中最低(Kim 等,2007)。空间分布上每个季节都类似,均为北高南低,安徽省和江苏省污染最为严重,上海市次之,浙江省空气质量相对最优,与上一节结果相同。
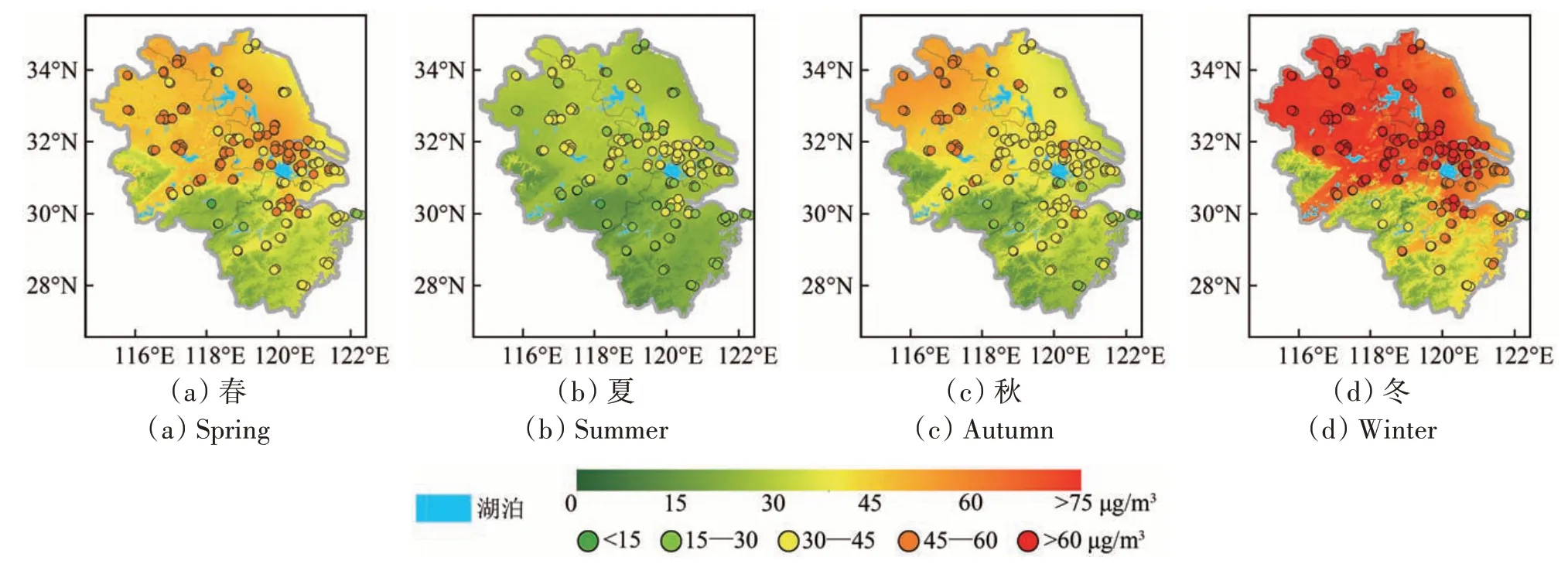
图6 长三角区域PM2.5浓度季节分布Fig.6 Seasonal PM2.5 concentration in the Yangtze River Delta
4.4 各省市PM2.5浓度分析
为进一步分析长三角内部各省市的PM2.5污染情况,绘制各省市每月PM2.5浓度箱线图并计算其变化趋势如图7。所有省市PM2.5浓度总体趋势都在好转,但估算结果的下降速率与站点结果有所差异,同时估算结果的月际波动幅度较站点结果也更小。出现这种差异的主要原因是由于地面观测站点大都分布于PM2.5浓度较高的城市区域,其总体浓度较全域均值都偏高,而本研究估算的PM2.5浓度还包括山区等地,反映的是全域整体情况。此外,PM2.5浓度的月度变化趋势呈现显著的周期性,并且各省市的趋势都相似:冬季月份高,夏季月份低,春秋过渡。箱线图也直观的指示了除夏季的6、7、8月外,各省市其余月份都有超过75%的日子PM2.5日均浓度无法达到国家一级标准(日均35 μg/m3),而冬季月份(12、1、2月)除浙江省外有超半数的天数超过国家二级标准(日均75 μg/m3)。本研究估算PM2.5的结果显示,四省市中以上海市下降趋势最为明显(下降速率=-3.30 μg/(m3·a))。上海市在前4 a出现PM2.5浓度异常高值的情况最为频繁,最高的几天接近200 μg/m3,近2 a 有所好转,出现极端污染的情况明显减少,极值也下降了近一半。地面站点趋势与本研究估算结果类似,下降速率为4.06 μg/(m3·a)。地面站点结果中下降速率最快的为浙江省,达4.09 μg/(m3·a),然而本研究结果显示浙江省下降趋势最为平稳,下降速率仅为1.79 μg/(m3·a)。其原因为浙江省大部分为山区,6年来山区PM2.5浓度一直保持在较低水平,而地面观测站点不包含这些区域,导致其结果浓度偏高。同时站点结果与本研究估算结果的差异也说明了浙江省在城市地区PM2.5的控制方面做到了较高水平,值得其余地区学习借鉴。江苏省地处平原,全域PM2.5浓度空间异质性较低,因此其估算结果与地面站点结果差异相对较小,下降速率分别为2.65 μg/(m3·a)和3.69 μg/(m3·a)。江苏省在2018年以前月间PM2.5浓度波动变化较大,夏冬差距明显;2018年以后冬季重污染天气减少,空气质量改善,月间变化变缓。安徽省由于黄山等山区的存在,其总体下降速率的差异同浙江省类似,估算结果为1.72 μg/(m3·a),相对较低,地面站点结果为3.37 μg/(m3·a),同样为长三角区域最缓。但安徽省PM2.5浓度较浙江省高,月季变化幅度也较大,因此仍有较大改善空间,是后续更需要政府关注的重点区域。
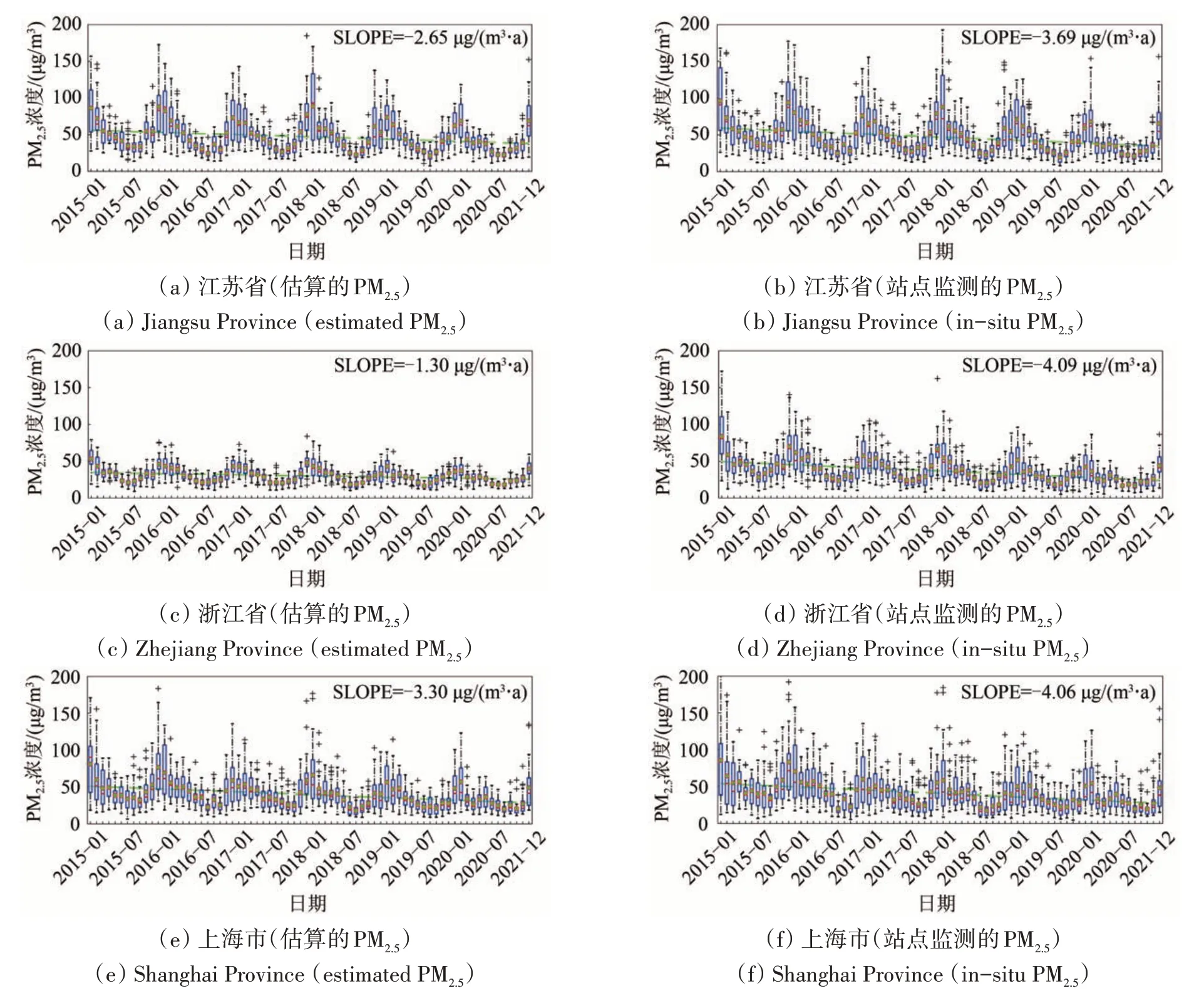

图7 长三角区域各省市2015年—2020年PM2.5浓度趋势Fig.7 Provincial trend of PM2.5 concentration from 2015 to 2020 in the Yangtze River Delta
5 结论
(1)针对现有机器学习模型不能很好地捕获AOD-PM2.5关系的时空异质性问题,本研究构建了一种结合注意力机制的自适应深度神经网络模型(SADNN),在拥有复杂非线性建模能力的同时,对输入因子动态校正,以识别其时空异质性。模型交叉验证结果指示所提出的模型相比多元线性回归和随机森林拥有更高的估算性能,R2达0.85,RMSRE为0.35,能更准确地估算逐日PM2.5浓度。
(2)在输入因子的选取方面,除了常规的AOD、气象因子、DEM、NDVI、DOY和经纬度外,加入了针对于中国人民生产生活习惯的农历日因子。实验结果表明农历日因子的加入能够一定程度上校正AOD-PM2.5的关系,使得估算结果在空间分布上更为精确。
(3)利用该模型进一步估算长三角区域2015年—2020年的PM2.5浓度发现:PM2.5浓度在空间分布上整体呈现北高南低的趋势,安徽省与江苏省空气污染最为严重,浙江省浓度最低。时间尺度上长三角区域2015年—2020年整体PM2.5浓度除2017年外,每年都在下降;季节差异同样十分显著,呈冬季>春季>秋季>夏季的规律。分省市分析结果表明:上海市PM2.5浓度下降最快,下降速率为3.30 μg/(m3·a),江苏省次之(2.65 μg/(m3·a)),安徽省与浙江省变化速度相近,均不到2 μg/(m3·a),但安徽省整体浓度远高于浙江省,改善空间较大,需要更多的关注。
(4)利用本研究提出的模型能够较好地估算全域逐日PM2.5浓度,估算结果与地面观测有较好的一致性,同时由于地面站点只分布于城市等PM2.5浓度相对较高区域,本研究结果可以弥补地面观测在空间分布上的不足。然而现阶段模型的辅助因子以气象为主,缺少具有时空特征的人为活动排放清单这类因子。未来期望再加入这类因子到模型中,同时累积更多的地面观测数据进行模型的训练,得到更为精确的PM2.5浓度时空分布,为流行病学研究和中国生态文明建设提供更为可靠的数据与理论支撑。
志 谢本研究所用MODIS 系列卫星数据由NASA 提供,ERA5 气象数据与AOD 再分析数据由欧洲中期天气预报中心提供,PM2.5数据由国家生态环境部提供,地面AOD 监测数据由AERONET提供,在此表示衷心的感谢!