京沪高铁列车运行晚点预测方法研究
2022-06-08张红斌陈亚茹
张红斌,李 军,陈亚茹
(1.中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081;2.中国国家铁路集团有限公司 调度指挥中心,北京 100844)
安全、正点是我国铁路的重要目标,而客运列车在运行过程中会受到外部环境、固定设备和移动设施故障、人为操作失误等多种因素影响,出现晚点的情况。快速、准确地掌握列车的运行状态及未来的运行趋势,不仅能为铁路运输调度高效指挥提供保障,且有利于客运部门及时有效地组织车站中转客流,更能方便旅客提前规划行程,减少大面积晚点导致的乘客滞留问题,因此研究列车晚点传播规律意义重大。
现阶段,国内外关于客运列车晚点规律的研究方法可分为传统模型法和数据驱动模型法。传统模型法主要是通过事件图、活动图等传统理论模型研究列车晚点规律[1-3]。数据驱动模型法包含列车初始晚点分布研究[4-5]和晚点传播规律研究,前者是通过建立高速铁路初始晚点不同致因对列车数量影响的分布模型;后者主要利用机器学习、随机森林和循环神经网络(RNN,Recurrent Neural Network)等方法进行研究[6-9]。这些方法多针对单个车站而无法对所有站点进行预测,且由于没有过滤大量的弱晚点数据,干扰了模型的准确率,不利于实际生产的应用。本文在前人研究的基础上,以2020 年北京—上海高速铁路(简称:京沪高铁)列车运行晚点预测为例,采用RNN 全段预测法并过滤了冗余数据,验证了算法的有效性。
1 列车运行晚点影响因素分析
京沪高铁由北京南站至上海虹桥站,全长1 318 km,设24 个车站,设计的最高速度为380 km/h。通过分析2020 年京沪高铁行车数据,共筛选出655 559 条初始晚点数据,其中,初始晚点在1~4 min 范围内的共有642 851 条,占比98.1%;大于4 min 的有12 708 条。铁路部门将1~4 min 范围内的晚点视为列车运行的正常波动,因此本文将研究的重点定位到大于4 min 的列车运行初始晚点。
1.1 停站时长对晚点的影响
图1 统计了2020 年的京沪高铁列车运行在发生晚点的情况下,在不同的停站时长下,晚点的吸收、增加和平移的概率。从图1 可以看出,随着停站时间的增加,晚点吸收的比率在上升,平移和增加的概率在减少,因此停站时间越大,越容易吸收晚点。

图1 不同停站时长晚点吸收规律
1.2 初始晚点对传播车站数的影响
将列车运行初始晚点时间按照1~4 min、5~10 min、11~30 min 分为3 类,分别统计每种类别初始晚点的传播长度,如图2 所示。可以看出,在初始晚点为1~4 min 时,晚点传播车站数量为2~3 个;初始晚点为5~10 min 时,传播车站数量主要范围在3~9 个;对于较大的初始晚点,传播车站数量主要范围在6~15 个。由此得出,随着初始晚点时间的增加,晚点传播的车站数量也在增加。
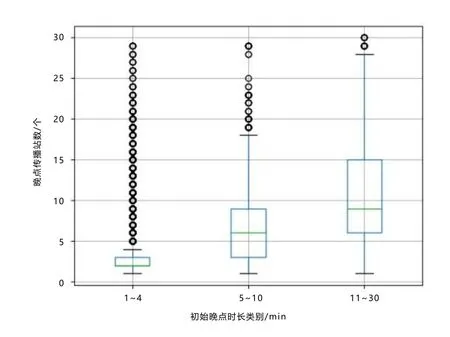
图2 不同初始晚点传播车站数箱线图
2 算法设计
2.1 RNN 全段预测方法
RNN 是在普通多层反向传播神经网络基础上,增加了隐藏层各单元间的横向联系,通过一个权重矩阵,可实现将上一个时间序列神经单元的值传递至当前的神经单元,从而使神经网络具备了记忆功能,对于处理有上下文联系的自然语言问题或有关时间序列的机器学习问题有较好的应用性。
全段预测中的“全段”指的是列车晚点传播的范围,这个范围指的是从列车发生初始晚点的车站至晚点消失车站或终到站。因此,全段预测是指对于列车晚点传播范围与传播强度的预测。
2.1.1 多对多模式的RNN 模型
RNN 模型的多对多模式可分为间隔多对多和同步多对多2 种模式,如图3 所示,水平箭头方向为列车行车方向,北京南站为列车运行初始晚点发生站,后续各站为晚点吸收/扩散站,晚点项为到发晚点时间。本文在初始晚点段预测场景中,输入的数据是初始晚点段所有站点的特征信息,要求输出的数据是所有站点的正晚点情况,其天然的序列性符合RNN 模型的间隔多对多和同步多对多2 种模式。但间隔多对多模式下,模型无法利用列车将要运行站点的特征,因此,本次建模选取具有同步多对多模式的RNN 模型作为基础模型结构。
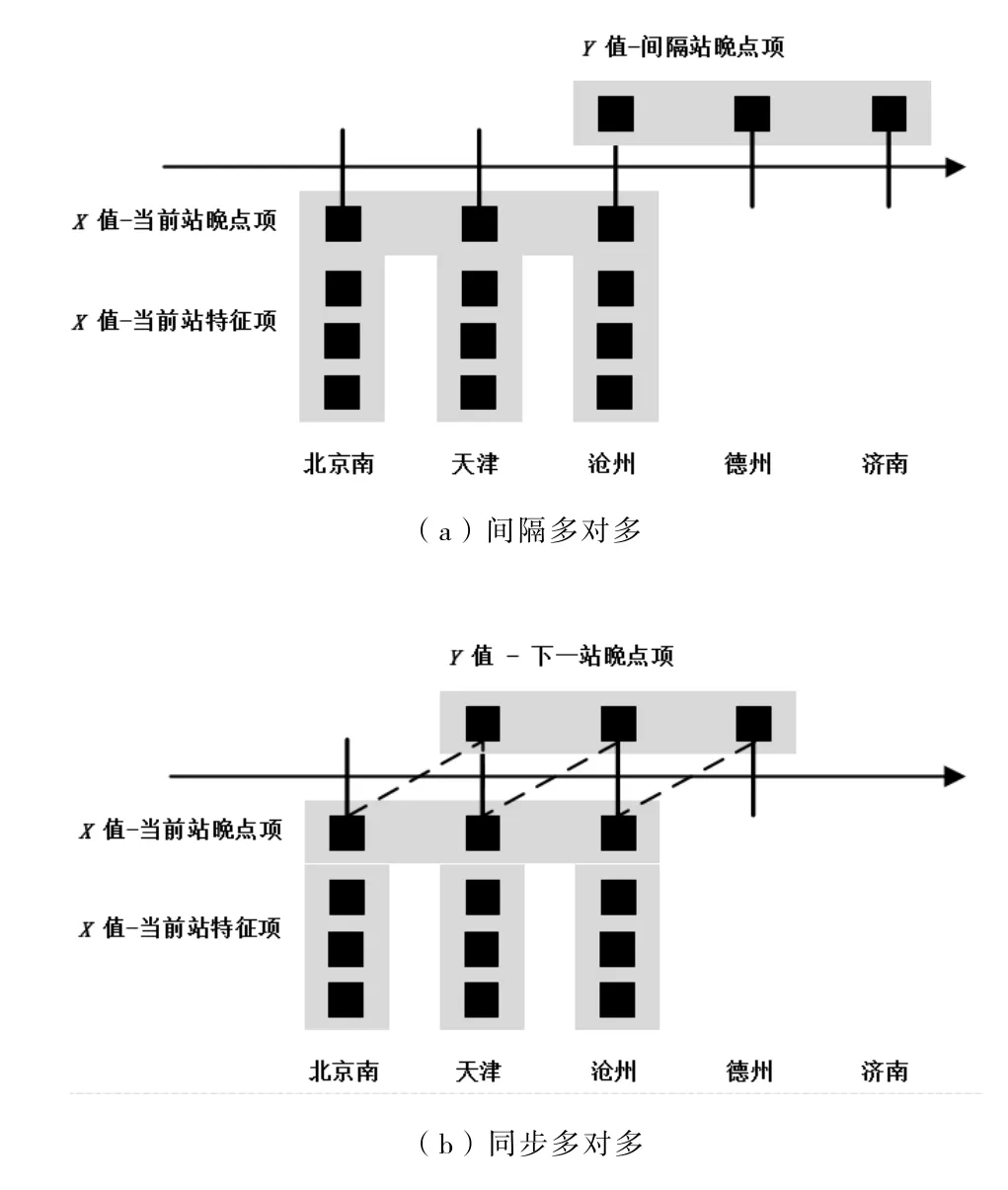
图3 多对多模式对比
在同步多对多RNN 模型中,所有站点对应的Y值都是下一站的晚点项。实际应用中,发生初始晚点后的晚点恢复情况是未知的、需要预测的,因此,建立模型特征序列时,除初始晚点发生站外,其他所有站点的晚点项需置0 后作为特征项进入模型。
2.1.2 LSTM-RNN 模型
利用RNN 模型处理时间序列数据具有先天优势,但在长序列的训练模式下仍存在梯度消失问题。本文选取的2020 年京沪线高铁列车运行初始晚点段预测场景中,序列平均长度为8 个车站,最长可达22个车站。若直接使用传统RNN 模型会导致梯度消失严重且模型参数更新缓慢,因此本文引入RNN 的变体结构长短期记忆网络(LSTM,Long Short-Term Memory)来促使模型更好地学习长期特征。
LSTM 作为一种循环神经网络的变形结构,是在普通 RNN 基础上,隐藏层各神经单元中增加记忆单元,从而使时间序列上的记忆信息可控,每次在隐藏层各单元间传递时通过“门”来控制丢弃/增加信息,从而实现遗忘或记忆的功能。
为方便描述,下文将多对多模式下的LSTMRNN 模型统称为RNN 模型。
2.2 评价指标
本文采用平均绝对误差损失(MAE,Mean Absolute Error)作为评价函数。其计算公式为
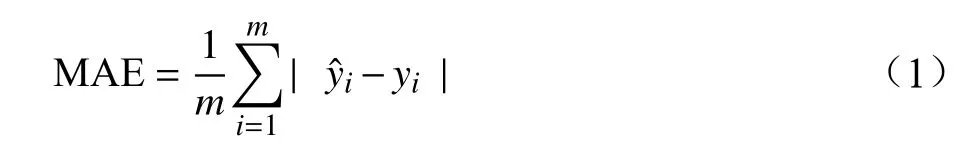
其中,y表示实际值;表示预测值。实际值与预测值之间的误差越小,说明模型的预测效果越好。
2.3 损失函数和优化器
本文选取 SmoothL1算法作为模型的损失函数(Loss Function),公式如下

其中,x表示模型的预测值yˆ 与实际值y之间的差距。该算法下的梯度稳定,不易产生梯度爆炸问题。
使用Adam 优化器,其本质是通过一阶矩估计的动量项和二阶矩估计的自适应项对梯度和各参数的学习率进行动态调整。该优化器的优点在于,在偏移校正之后,确定每个迭代学习速率在固定范围内,可减少迭代过程的震荡,从而平滑地改变神经网络参数。
2.4 列车运行晚点预测模型
列车运行初始晚点段预测模型建立步骤如下。
(1)确立目标数据集:本次实验选取了2020年全年京沪高铁列车运行数据作为目标数据集数据。
(2)数据清洗及筛选:针对目标数据集进行缺失数据补全、重复数据/异常数据删除等操作。
(3)序列提取:提取初始晚点序列作为入模数据。
(4)特征构建:结合列车运行数据特点和运力、时间、线路等多个角度构建特征。
(5)数据分割:将入模数据按7:3 的比例切分为训练集和验证集。
(6)建立RNN 模型:选择隐藏层层数及输入层、隐藏层、输出层神经单元数。
(7)模型调参:设置不同的网络参数和模型训练参数,调整输入特征,反复在验证集上根据评价指标对实验模型进行评估,直至找到最优参数。
3 实例验证
3.1 数据预处理
结合前文晚点分析及算法设计,将目标数据集数据进行如下处理。
3.1.1 数据清洗
(1)删除重复样本;
(2)删除小于3 站的行程;
(3)删除车站名缺失的行程;
(4)删除运行时间或计划时间异常的行程;
(5)删除区间吸收异常或车站吸收异常的行程。
3.1.2 晚点序列提取
全段预测的序列样本,从各个单独的行程采集而来,序列长度不一,需满足如下几个条件:
(1)从初始晚点开始采集,后续站一直采集到晚点吸收为止;
(2)序列采集的长度需要在3 个站及以上;
(3)在全段预测场景下,只采集当前站的特征值,后续车站的晚点数据设置为0。
通过序列提取,本次建模仅选取初始晚点在5~30 min 的序列,序列数为 4 182 个。
3.2 特征提取
本文选择Captum 工具对提取的特征进行筛选。利用集成梯度算法,全变量模型训练完成后,输入 1个批次的数据进行前向传播,计算此批次中每条元素的每个属性值(特征项值)的积分梯度,再将批次中所有元素的积分梯度求和,当作该属性的集成梯度。梯度值越高,表明该属性就越显著。
假设常规归因下某个属性x有一个基线值x′,神经网络的输出为函数f,则积分梯度(IG,Integrated Gradients)的计算公式为
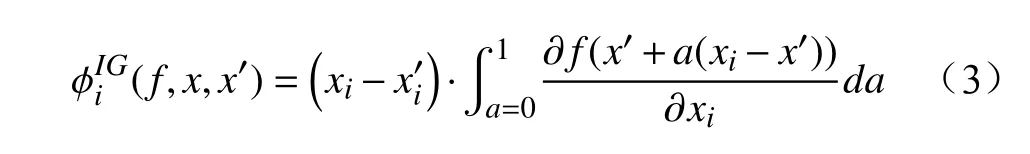
上述公式是训练批次中单条记录对属性x的打分值,集成梯度是多条记录积分梯度的加总,将所有属性的集成梯度做归一化,得到最终的结果,如图4 所示。
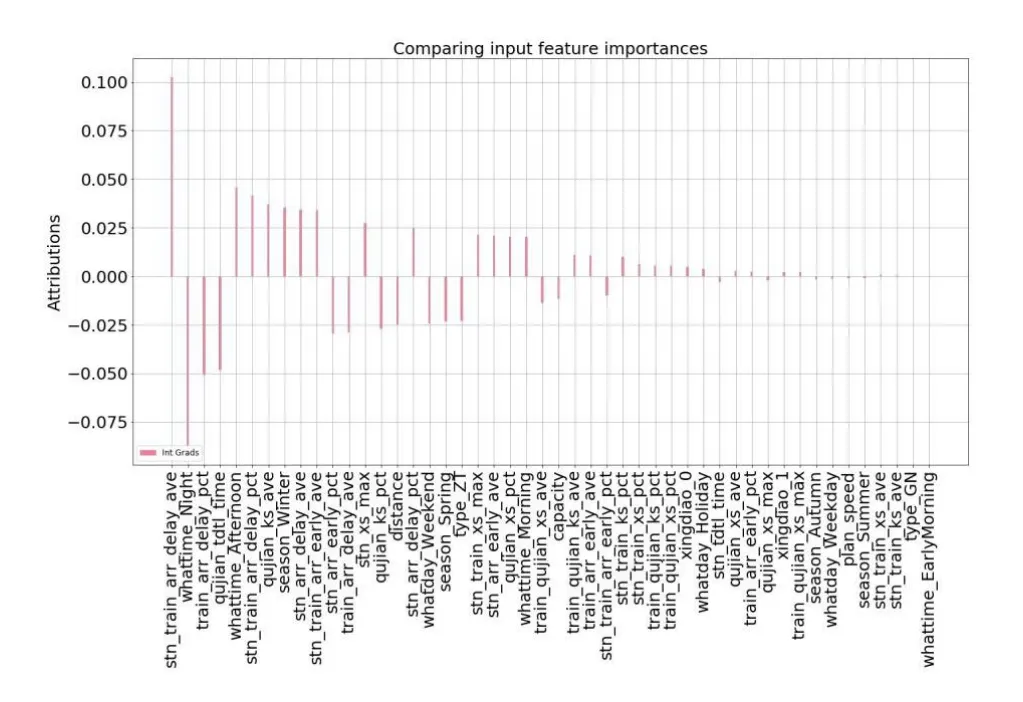
图4 特征值集成梯度归一化得分
基于铁路正晚点的业务场景,一共提取了38 项特征,其中,存在很多不相关或冗余项,根据集成梯度对所有特征项的打分,最终选择12 个最显著的特征作为模型自变量,如表1 所示。

表1 12 个最显著的特征值
3.3 模型训练与参数设置
本文使用pytorch 深度学习框架,将提取后的晚点数据按照7:3 的比例分割为训练集和验证集,进行模型训练。Epoch 表示所有训练样本在神经网络中都进行了一次正向传播和一次反向传播。合适的Epoch 次数,是神经网络能准确预测的基础,训练次数过小,误差较大;训练次数过大,会导致过拟合。
通过损失(Loss)测试和MAE 测试,在100 个Epoch 的训练过程中,训练集的Loss 和MAE 始终保持下降趋势,说明模型拟合能力较好,如图5 和图6所示。
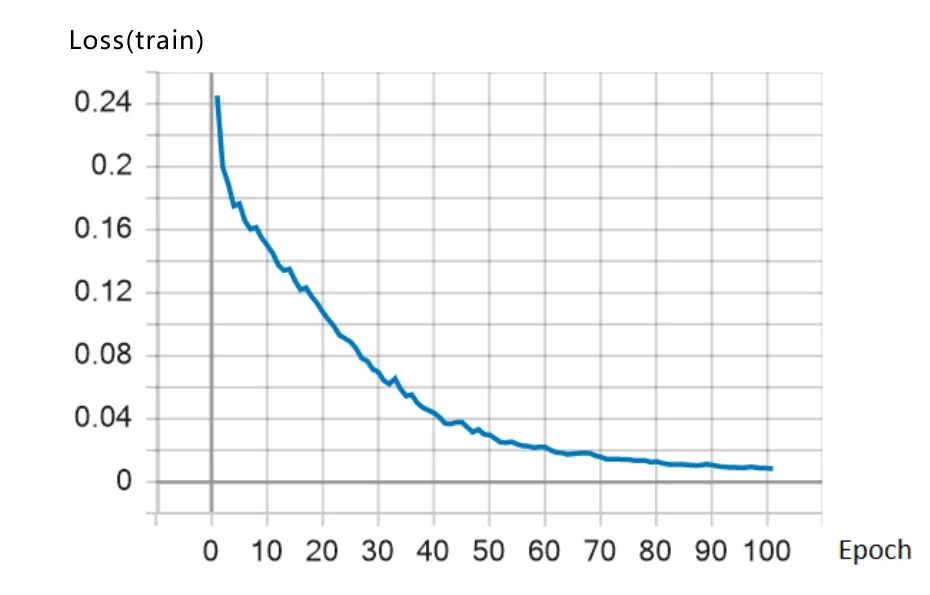
图5 训练集Loss 训练过程
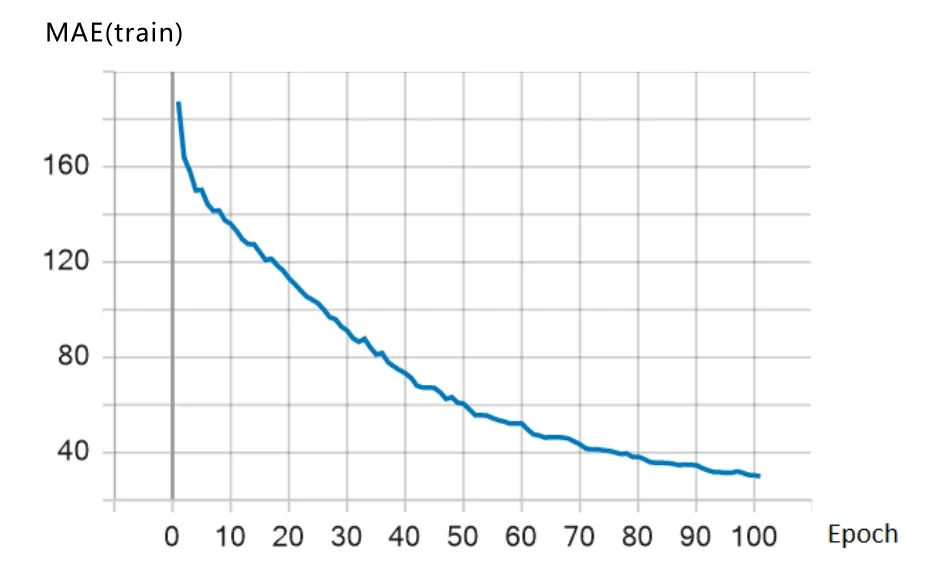
图6 训练集MAE 训练过程
准确率(ACC,Accuracy)是指模型使用验证集进行验证预测,预测结果正确(满足规定的误差)的样本数占总样本个数的比例。从验证集看,预测ACC 在21 个Epoch 时已达到最优,同时MAE 在21个Epoch 时也达到了较优的数值,意味训练在21 个Epoch 时,模型达到了最优,如图7 和图8 所示。

图7 验证集MAE 训练过程
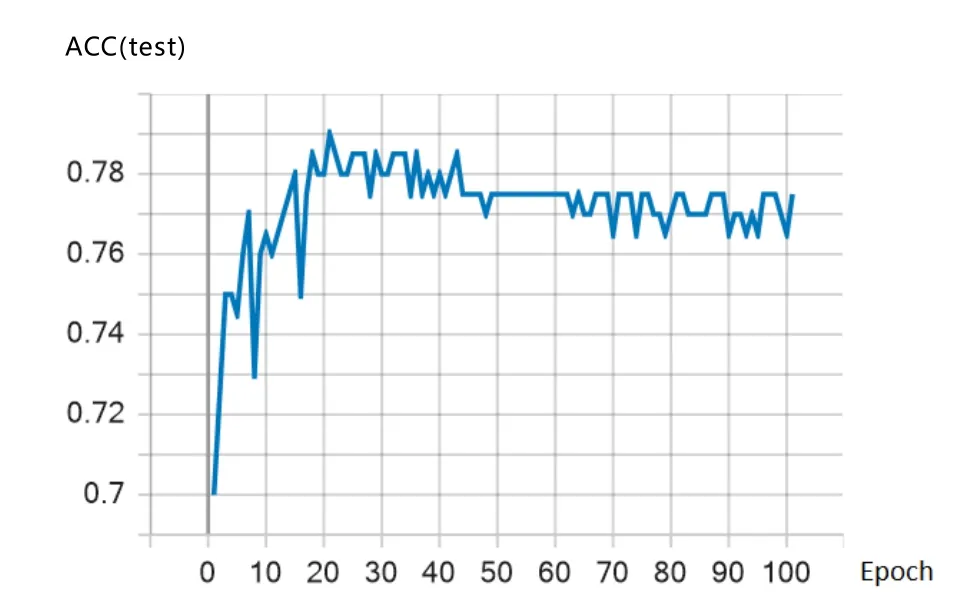
图8 验证集ACC(误差3 min)训练过程
经大量对比试验,本文最终设置的RNN 模型网络结构参数及训练相关参数如表2 所示。
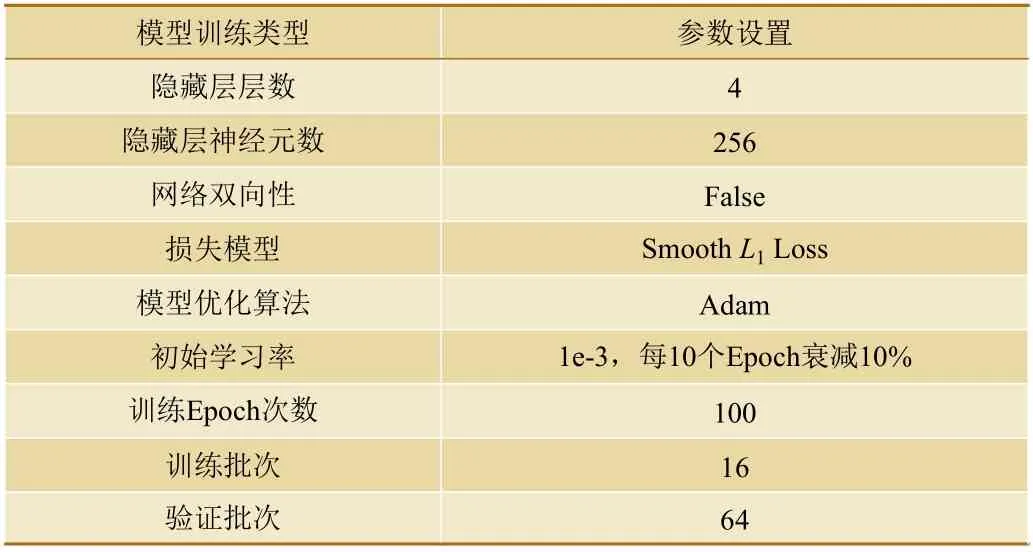
表2 模型训练参数
3.4 预测结果分析
由上文可知,Epoch 为21 时,验证集准确率达到最优,因此选择此时的模型作为表现最佳模型。验证集预测误差在3~9 min 不同情况下的准确率如表3 所示,预测平均误差为152.2 s。

表3 验证集的准确率
由表3 可知,按表2 参数设置模型,预测误差在5 min 范围内的准确率可以达到89%,能够实现京沪高铁晚点时间的高精度估算。
4 结束语
本文通过分析京沪高铁列车历史运行数据,提取了时间、铁路网运力、运行线路、历史运行规律等较为显著的特征向量,在过滤弱晚点的基础上,设计了基于循环神经网络的全段预测方法,以期实现对高铁列车的全段预测。经验证,模型的准确率较高,可以满足实际生产的需要。
本文设计列车运行晚点预测模型还存在不足之处,如仅给出预测的列车晚点时间,而未给出列车晚点时间对应的概率,这是由于晚点预测模型选用RNN 回归模型导致的。后续可尝试将晚点时间当作类别变量建模,同时预测晚点时间及其发生概率。
