基于出行关系的广告点击率预测模型的研究
2022-05-30郝晓培朱建生单杏花
郝晓培,朱建生,单杏花
(中国铁道科学研究院,北京 100081)
0 引 言
互联网产品的多样化以及智能终端的普及,已促使互联网成为当今社会信息传递最快捷有效的媒介,互联网公司为用户提供服务的同时,也为广告平台的推送带来了极大的便利,在用户享受产品带来的服务的时候,广告平台会为用户推送各种各样的广告,在一定程度上提高了用户对新产品的认知。然而用户基本属性的差异,大量无差别的广告推送不能满足所有用户的个性化需求,不仅会导致用户对互联网产品产生抵触情绪,严重影响用户体验,同时也会降低广告的点击率以及转化率,难以保证公司广告平台的可持续稳定的发展。为了解决数据冗余以及信息过载为用户获取有效信息带来的困扰,以及最大化广告平台的经济收益,基于用户基本特征以及历史行为信息构建个性化推荐系统成为相关领域的研究热点[1]。
文献[2]提出了一种基于在线贝叶斯概率回归模型的点击率评估方法,但是该模型只在确定广告特征的场景取得较好的效果;文献[3]第一次提出了“满意度”的概念,并基于“满意度”构建页面的相关性,最后通过动态贝叶斯网络模型进行评估;文献[4]将梯度增强决策树运用到广告点击率预估,该模型解决了贝叶斯网络中各项特征必须相互独立的缺点,可以学习特征之间的相关性,达到了较好的预估效果。传统的推荐算法中,庞大的用户量以及产品量使得评分矩阵极其稀疏,且存在冷启动的问题,为产品的精准推荐带来了极大的挑战。随着深度学习以及社交网络在电商、资讯、短视频等互联网产品的普及,不同的产品已积累了大量复杂的社交关系数据,为基于社交关系的个性化推荐提供了数据基础。文献[5-6]从社交关系中挖掘信任关系,并将其运用到了推荐算法中,其在推荐精度以及TOP-K推荐能力方面有明显提高。文献[7]提出了Wide&Deep模型,该模型融合了线下逻辑回归以及非线性的神经网络,提高了模型的“记忆性”及“泛化性”,取得了不错的效果,在该模型的基础上越来越多的研究人员开始对此进行改进并运用到生产环境。针对目前广告CTR预估存在的问题,该文综合考虑现有预估模型的特点,设计了一种基于图注意力网络的特征处理,以及Wide&Deep模型的CRT评估模型Wide&Deep-GR,通过图注意力网络将铁路12306互联网售票系统中旅客之间存在的同行关系、购票关系、广告的交互信息以及个体特征相结合生成用户以及广告的特征向量,并将此特征向量作为Wide&Deep的输入进行CRT评估,综合考虑了用户的个体特征以及相关用户特征,提高了推荐算法的准确度。
1 模型设计
相对于传统的机器算法模型,深度学习在个性推荐以及CTR预测中表现出了巨大的潜力。近两年科研高校,互联网公司已经将其作为了研究重点,极大地提高了推荐系统的准确率[8]。
该文在GAT与Wide&Deep两个模型的基础上,构造了两个模块:特征处理,点击通过率预测。其中特征处理包括:用户特征、用户关系、广告特征、用户与广告关系。用户特征采用用户的出行行为特征以及广告点击情况构建完整的用户特征;用户关系主要基于用户同行以及购票关系生成关系网络;广告特征主要通过广告主以及数据分析人员标注生成特征向量;用户针对广告的点击行为生成用户与广告的关系网络,针对构建的关系网络采用图神经网络算法进行预处理,将自身的特征以及相邻节点的特征进行融合,生成最终的个体特征向量表示;最后基于特征处理的用户及广告特征向量进行点击通过率预测。整体结构见图1。

图1 整体结构
2 特征处理
2.1 总体设计
基于图神经网络的特征将个体特征信息以及个体的关系结果数据进行有效的融合,通过聚合个体特征以及邻居节点特征的方式,将多维个体特征以及个体关系嵌入到低维的向量中对个体进行特征提取,得到中心节点的特征向量。
2.2 特征选择
(1)个体特征。
针对广告推荐主要采用两类特征:类别型特征,数值型特征。类别型特征一般不能直接进行预测运算,通常采用one-hot或者multi-hot向量的方式将类别性特征转换成数值型特征,其中对数值型特征进行缺失值、异常值、归一化等处理,将处理后的标签进行拼接生成特征向量,基于旅客的出行行为以及与12306平台的交互行为产生的数据构建的用户特征以及广告特征如表1和表2所示。

表1 用户特征列

表2 广告特征列表

续表2
(2)关系特征。
关系特征主要包括三类:购票关系、同行关系、交互关系。关系特征采用图学习方式可以同时聚合与目标用户相关的邻居用户以及邻居产品的特征生成目标用户的特征向量。
购票关系如图2所示。

图2 用户购票关系
用Gbuying=
同行关系如图3所示。

图3 用户同行关系
用Gpeers=
交互关系如图4所示。

图4 交互关系
用Gclick=
2.3 特征处理
铁路12306互联网售票系统作为线上唯一的铁路售票渠道,通过PC端、手机端等进行票务交易,在交易过程中与其他旅客产生了购票关系以及同行关系,随着网络的发展以及研究,发现相对陌生人,用户更愿意接收具有信任关系的人的建议和推荐,同时其特征更接近于其有信任关系的用户,故特征处理主要是将邻居节点的特征与当前节点的特征通过特征融合生成当前节点的特征向量。
(1)邻居节点采样。
铁路客运用户量大,且存在部分异常账户,导致个别节点同行关系,购票关系复杂,每个节点的相邻节点数量相差较多,为了提高模型的训练效率,需要针对邻居节点多的用户节点的邻居节点进行抽样。假设相邻节点个数为N,抽样规则如下:
若N≤20,将所有节点作为关系网络节点;

(2)注意力机制。
图神经网络主要将个体特征以及关系网络作为入参,将其转换为低维的特征向量,常见的图神经网络算法通常采用采样和聚合构建的Inductive learning框架,比如:GraphSAGE[9]。在构建购票关系、同行关系、交互关系等图的过程中用购票次数、同行次数、点击次数等表示节点之间的关联程度,但是综合分析相邻节点特征相似度,发现关系数据包含的噪音影响了节点之间边的可靠性,同时相邻节点的特征也存在较大的差异。综合考虑多方面因素,该文主要采用GAT[10](图注意力网络)进行处理,在图表示算法中引入“注意力”机制,从空间上综合考虑目前节点与其他节点的关系网络,能够自适应的对图中邻居节点进行聚合并。
注意力机制的核心思想是:在考虑现有次数权重的基础上,基于相似性对给定的信息进行权重分配,对权重高的信息进行重点加工,其定义如下:
Attention(Query,Source)=
(1)
其中,Source表示信息源,通常包含多种信息,用Key-Value的形式进行表示,Query表示先验信息或者某种条件,Attentionvalue是在给定Query的情况下,采用注意力机制从信息源提取到的信息,similarity(Query,Keyi)表示采用向量内积的方式
(3)特征向量计算。
图注意力层就是将注意力机制应用到图神经网络聚合邻居节点特征的操作过程中,其输入是节点的个体特征以及关系特征,输出是节点新的特征向量。
假设目标节点为V2,其包含多个邻居节点Vi,基于注意力机制原理,通过节点特征相似度计算可以得到节点之间的相似度rij,并进行SoftMax归一化处理,生成最终的注意力系数mij。
其中,α表示节点相关度计算函数,W表示节点特征维度相互转化的权重参数矩阵,L为激活函数LeakyReLu。
同时结合注意力系数,权重矩阵以及相邻节点的特征值进行加权求和(公式3),生成最终的特征向量。
(3)
3 CTR预估
CTR预估模型主要包括单层的Wide模块以及多层的Deep模块,其中Wide模块主要提取一维或者二维的低维特征交互信息,使模型具有了较强的“记忆能力”,Deep模块通过数据集中特征的多次组合,自动学习高位交互特征,发掘出特征中潜在的模式,使稀疏的特征向量获得稳定平滑的推荐概率,提高了模型的“泛化能力”[11]。
如图5所示,该模型主要分为4层:输入层、Embedding层、多隐层、输出层。

图5 Wide&Deep模型
其将Wide部分与Deep层(由Embedding层与多隐层组成)相互组合最终输入到输出层。其中Wide部分主要处理系数特征,Deep部分主要利用神经网络表达能力强的特点,进行特征交叉计算,挖掘隐藏的数据模型,最终在输出层利用逻辑回归将Wide层的结果以及Deep层的结果进行数据整合,形成最终的CTR预估模型。
文中Deep部分输入主要包括用户的特征与经过图注意力网络进行Embedding处理的特征向量拼接的全量用户特征向量,Wide部分的数据包括用户与广告的历史交互特征以及待曝光的广告特征,通过对有交互的广告与待曝光广告特征的交叉积转化,充分发挥Wide部分“记忆能力”强的优势。
4 实例验证
4.1 样本选择
在广告平台收集了2020年下半年的广告点击数据以及近三年(2018年-2020年)的用户出行数据,构建用户个体特征及关系网络,对样本数据进行离线化、缺失值处理、异常值处理等数据预处理及特征选择以降低模型的计算难度,最后生成了包括64 925个用户以及6条广告物料在内所生成的72 088条交互信息,151 264条同行关系以及132 423条购票关系数据,按照9∶1随机生成训练样本以及测试样本。
数据主要包括5类特征:用户个体特征、广告物料属性、购票关系、同行关系、交互行为。
4.2 模型评估
将预测精度、AUC以及对数损失函数作为评价指标对模型进行评估。预测精度表示真正例除以(真正例+假正例)的和,假正例指的是模型将实际上是反例的样本误判为正例的情况;AUC[12](公式4)用以评估模型性能问题;对数损失函数[13](公式5)计算预测分数与实际值之间的距离。
(4)
其中,rankinsi表示第i个样本的序号,M、N分别表示正样本和负样本的个数。
(5)

4.3 实 验
为了证明Wide&Deep-GR模型的整体性能,分别采用协同过滤[14]、FM算法[7]、Wide&Deep模型以及Wide&Deep-GR模型进行比较,实验结果如图6所示。
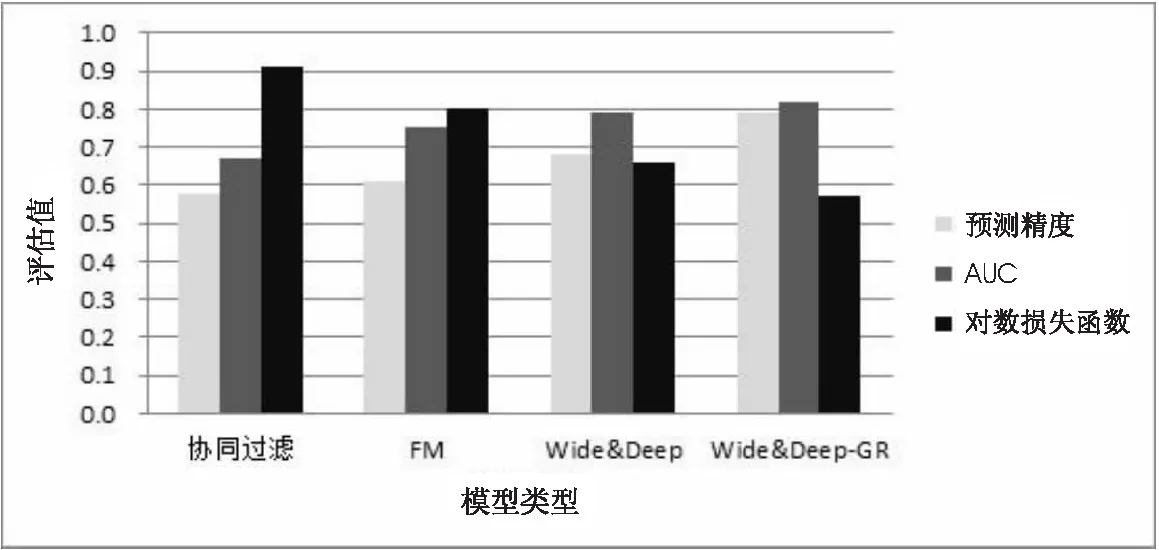
图6 基于不同模型的预测结果
如图6所示,在预测精度,AUC以及对数损失函数这三个性能指标方面,Wide&Deep模型明显优于协同过滤以及FM算法,当将用户的购票关系、同行关系以及与广告的交互关系网络融入Wide&Deep-GR模型的特征模型时,发现其性能相对Wide&Deep提升不少,在算法复杂度方面,由于Wide&Deep-GR模型增加了关系网络的构建,基于图注意力机制的个体特征的Embedding,相对于Wide&Deep模型提高了计算复杂度,不适用于在线的广告CTR预测,适合用于离线的运算。
5 结束语
广告精准投放是提升用户体验以及平台收益的重要技术,深度学习以及社交网络已经广泛应用到了CTR预测中,并取得了客观的效果。该文在深入研究深度学习模型以及铁路12306互联网售票系统广告平台数据结构的基础上,以Wide&Deep模型为基础,综合考虑个体特征以及关系网络,利用图注意力网络融合相邻节点的特征构建完整的个体特征向量,丰富个体特征的同时解决数据稀疏性的问题,并将其作为CTR评估模型的输入,实现了广告点击预估。最后基于广告平台半年的真实数据集验证了该模型的准确度。
