满足差分隐私的一种频繁序列挖掘算法
2022-05-30李玉伟
李玉伟,杨 庚,2
(1.南京邮电大学 计算机学院、软件学院、网络空间安全学院,江苏 南京 210023;2.江苏省大数据安全与智能处理重点实验室,江苏 南京 210023)
0 引 言
频繁模式挖掘在数据处理方面具有重要意义,频繁模式挖掘最早由Agrawal等人[1]提出,在他们的研究中,频繁模式被定义为频繁项集,其目的是在事务数据库中挖掘出消费者的购买习惯,通过分析消费者已经购买的商品中不同物品之间的联系,观察者可以制定出更优的市场策略。频繁模式挖掘算法目前在网络信息安全、金融预测、地震监测和营销策略等领域均得到了广泛应用。频繁模式算法的范围随着研究的不断深入也已经从最初的频繁项集挖掘,扩展至挖掘更复杂的模式,比如频繁子图挖掘[2]、频繁序列挖掘[3]等等。
频繁序列挖掘算法的目的就是在以序列形式储存的数据集中挖掘出频繁的序列事务。对于序列而言,某一序列中可以多次出现相同项,这是其与项集的差别。因此序列的长度就能突破字符种类上限的限制,序列的种类也会随序列的大小增加呈指数级增长。序列模式和序列数据,如轨迹或DNA序列,在许多应用中被广泛使用。例如,从主要道路收集的交通数据可用于确定出行最多的地区和预测交通拥堵。然而频繁序列模式的内容和支持度的计数都会导致用户信息的安全得不到保障[4]。为了解决该问题,Dwork等人[5]在2006年提出了差分隐私模型。该模型在挖掘过程和发布数据中对支持度添加扰动噪音,为数据隐私提供了强有力的、可证明的保障。差分隐私保护模型的隐私保护手段是可量化并且严格的,其隐私保护强度与入侵者持有的信息无关。由于该模型在挖掘过程中对数据进行噪音扰动,可以达到在原数据集中改变序列记录并不会导致挖掘结果出现较大波动的目的。
目前已经有了一些具有差分隐私保护的序列挖掘算法,但这些挖掘算法大多是缺乏交互性的非渐进式的算法。在选择了数据集和确定了最小阈值之后,用户启动算法(比如PrefixSpan算法),在算法停止之前,中间的过程中不会得到任何回应。这样的延迟对于数据挖掘的生产力有很大的影响,因此将操作者对于挖掘信息的即时判断处理加入到整体的挖掘过程中十分有必要。Sacha等人提出的Prosecco算法[6]就是一种渐进式的、满足交互性的频繁序列挖掘算法。但此算法同样存在隐私泄露的问题。该文在Prosecco算法的基础上,采用差分隐私保护技术对其进行安全性保障,设计了一种满足差分隐私保护的序列挖掘算法ProSVT。主要贡献如下:
(1)针对交互式、渐进式的序列挖掘算法添加差分隐私保护机制。ProSVT周期性地返回给用户高度近似的频繁序列结果。这种渐进式的过程体现在根据用户定义的对数据集分块(blocks)的基础下逐渐分析挖掘的过程。
(2)运用并改善了添加噪音的机制,即双层拉普拉斯噪音稀疏向量算法。稀疏向量法[7]是满足差分隐私保护的一种添加拉普拉斯噪音的方法,该文将其运用于挖掘频繁序列的算法中,并且在添加阈值噪音的位置做了改变,使添加噪音后算法挖掘结果更精确和稳定。
1 相关工作
在目前的隐私保护模型方法中,k-匿名模型[8]已经得到了广泛的研究并应用于各领域,而后续研究表明,信息入侵者持有的信息量在很大程度上会影响模型的安全性,而且k-匿名模型的隐私保护水平并未得到有效且严格的证明。针对这些问题,Dwork提出的差分隐私保护模型(2006)可以抵挡各类对数据信息的攻击,并且同时可以设定隐私参数来决定其隐私保护水平。Dwork证明了在背景知识存在的情况下,绝对隐私保护是不可能的,由此产生了基于不可区分性的差分隐私概念。差分隐私要求任何计算对单个记录的更改不敏感,也就是说,针对任意一条记录,数据库包含或者不包含该条记录不影响最后计算的结果。因此,这意味着掌握某条记录的攻击者不能根据对数据库的操作得到关于该条记录的任何有价值信息。实现该模型的噪音机制一般分为两种情况,如果数据为非数值型采用指数机制,反之则采用拉普拉斯机制。
该领域的研究现状在文献[9]中已经得到了非常详尽的介绍。满足差分隐私保护的频繁模式挖掘的研究,最早从频繁项集挖掘相关算法开始。文献[4]定义了一个新的效用概念top-k用来量化频繁项集挖掘算法的输出精度,即返回数据集中前k个最频繁的项集作为输出结果,该算法将模式长度大于lmax的事务截断,然后添加Laplace噪音对支持度进行扰动以达到安全性,但当参数k和lmax较大时,算法不能保证其挖掘性能。文献[10]提出的PrivBasis算法利用了一种称为θ-基的新概念,θ-基集具有频率大于θ的项集是某个基集的子集的性质,该算法采用的top-k频繁项集挖掘可以看作是通过降维的方式来处理高维数据。文献[11]中提出的DP-topkP算法通过后置处理噪音支持度的方式使结果满足一致性约束,同时也增强了其可用性。由于较长的数据事务会使数据集的敏感度提高,文献[12]提出了一种截断长事务的方法,并且将截断引发的错误与噪音引发的错误进行权衡,该top-k算法在k不是很小的情况下能获得较好可用性的挖掘结果。和频繁项集挖掘相比,频繁序列挖掘存在高维和序列性的特点,因此这些算法尚不能应用于挖掘频繁序列。
文献[13]提出的基于混合粒度前缀树结果算法首次实现了发布轨迹数据(频繁序列挖掘)中的差分隐私保护。该算法在构建前缀树的过程中使用Laplace噪音对数据进行扰动,使其发布的数据结果满足差分隐私保护,但是算法存在前缀树高度增长导致发布数据的效用大大降低的问题。文献[14]采用变长n-gram来提取序列数据库的基本信息,利用了前缀搜索树结果和一组基于马尔可夫假设的新技术来降低噪音量,使算法在挖掘的过程中满足差分隐私保护。该算法在短序列为主的数据集下有较好的表现,当存在较多高维数据时挖掘结果的可用性得不到保证。PT-Sample算法[15]利用数据的统计特性来构造一个基于模型的前缀树,用于挖掘前缀和子串模式的候选集,但是该算法并不适用于挖掘非字符类型的数据。文献[16]提出的DPFSM算法,设计了一种打分函数来区分不同候选序列的优先权,然后通过阈值修正策略来减少截断误差与传播错误,但尚未考虑到隐私预算的分配问题。以上算法都各自有其适用的方向并且都还存在一些问题,因此如何通过设计一种算法使频繁序列挖掘的结果可用性与差分隐私保护的安全性达到较好的平衡是现在研究的重点和难点。
2 理论基础
2.1 差分隐私
差分隐私是通过在挖掘过程中或者输出结果中添加噪音对数据进行扰动来保证数据的安全性,使得在数据集中改变一条记录(移除或者添加一条记录)之后,任何查询的输出结果都不会改变。差分隐私的定义如下:
定义1:对于相邻数据库D1和D2(D1和D2之间只相差一条记录),给定算法A,算法A可能输出的结果集合为S,若算法A在数据库D1中输出S的概率与算法A在数据库D2中输出S的概率的比值小于常数值eε,称算法A满足ε-差分隐私保护, 即:
Pr[A(D1)∈S]≤eε×Pr[A(D2)∈S]
(1)
隐私预算参数ε可以衡量算法的隐私保护强度,ε值越小表示安全性(隐私强度)越高,但是同时也会使数据的可用性降低。
实现差分隐私保护主要依靠对数据的支持度添加噪音的机制,主要包括Laplace机制和指数机制,前者针对实数型数据,后者针对字符型数据。噪音量的大小取决于隐私参数和全局敏感度,隐私参数是用户自己设定的,敏感度是数据集在算法下的属性,函数的敏感度为数据库中改变一条事务之后函数输出结果的最大改变量,其数学的定义如下:
定义2:对于任意一个函数f,D→Rd,函数f的敏感度Δf定义为:
(2)
其中,f的查询维度为d,R为f映射的实数空间。
该文的数据集为实数型数据,因此采用Laplace机制。为了使算法满足差分隐私保护,Laplace机制在算法输出结果中加入服从Laplace分布的随机噪音。Laplace机制的定义如下:
定理1:对于敏感度为Δf的函数f,算法
A(D)=f(D)+Lap(λ)
(3)
满足ε-差分隐私保护,其中Lap(λ)是服从λ=Δf/ε的Laplace分布,Laplace分布的概率密度函数为:
Pr[x|λ]=(1/2λ)e-|x|/λ
(4)
参数λ是根据隐私参数ε和函数敏感度Δf共同决定的。
由于处理的问题有时比较复杂,单个差分隐私保护算法不能解决问题,通常需要将用户在算法中指定的隐私参数进行合理分配并采用多个满足差分隐私保护的安全性算法。
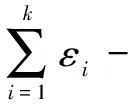
定理3(并行性质):假设A1,A2,…,Ak为k个满足差分隐私保护的算法,其中,每个算法Ai依次满足εi-差分隐私保护(1≤i≤k)。那么,当算法A1,A2,…,Ak分别作用于数据库D1,D2,…,Dk(所有数据库均不相交)时,这些算法构成的组合算法A满足max{εi}-差分隐私保护。
由差分隐私保护算法的串行性质和并行性质可以推出如下结论:当存在多个满足差分隐私保护的算法A1,A2,…,Ak,对于其构成的组合算法A的隐私预算总和,根据需要处理的数据库彼此是否相交有不同的结果,前者为所有算法的隐私预算之和,后者为所有算法中隐私预算的最大值。
2.2 频繁序列挖掘
多条序列记录构成了频繁序列挖掘的数据集,每一条用户序列记录都可能包含该用户的涉及隐私安全的信息。在频繁序列挖掘中,对于某一条序列,其在数据集中出现的次数被定义为该序列的支持度,支持度与数据集中所有序列记录的数量的比值被定义为该序列的频率。类似地,阈值也分别被定义为绝对阈值和相对阈值,对应于支持度和频率。如果某一序列的支持度大于绝对阈值或者其频率大于相对阈值,就可以将该序列加入所要输出的频繁序列集合之中。如果未经特殊说明,文章中的阈值一般指绝对阈值。
已知I={i1,i2,…,in}为序列数据集中项的集合(即字母表)。在频繁序列挖掘中,字母表中任意项的一个非空集组合就构成了一条用户序列,例如S=a1a2…a|s|表示长度为|S|的序列(a1,a2,…,a|s|∈I)。对于一条序列S,如果|S|=k,称S为一个长度为k的序列(即一个k-序列)。频繁序列挖掘的目的是要发现序列数据库中的所有频繁子序列,并且计算每个频繁序列的支持度。
3 ProSVT算法
本节详细描述所提出的用于挖掘频繁序列的ProSVT(Prosecco-SVT)算法。
3.1 概 述
基于Prosecco算法,设计了一种具有隐私保护功能的序列挖掘算法,Prosecco算法首先将数据集分成数量为b的子集块,b为用户指定的参数。在挖掘过程中,当分析完第i个子集块后,算法输出一个满足αi-近似的中间结果。中间结果在不断更新,用户可以根据当前结果的价值来决定是否继续挖掘,因此整个挖掘过程中得到的数据具有交互性质。
一种挖掘频繁序列的流算法采用了一种用户相关的降低阈值(ξ<θ)的方法,并且在所有的子集块中都使用相同的降低后的阈值,这种策略不足以保证中间结果的有效性,因为在某些块中有的序列支持度低于ξ,于是就会被忽略,导致结果不准确,从而误导用户。Prosecco为了避免这种隐患,使用了块相关的降低阈值的方法。这个过程是根据统计学中的相关定理确定了每个子集块的特定参数,结合用户先前设定的错误概率,共同决定误差参数,即阈值下降的幅度。随着挖掘过程的继续,该幅度越来越小,最终收敛于0,阈值也收敛于标准阈值,算法输出精确挖掘结果。
在挖掘频繁序列的部分使用双噪音(改善过的SVT)来为候选序列添加拉普拉斯噪音,即在序列支持度和阈值上同时添加噪音并控制噪音大小。此前的SVT法是在每个查询序列上添加不同的随机噪音,而在阈值上添加统一的一个噪音,这种做法存在弊端,如果阈值噪音过大就会导致整体比较结果,因此将统一的阈值噪音改为在每一次对查询序列操作时在阈值上添加的不同随机噪音,在比较噪音支持度和噪音阈值时,剔除未能达到噪音阈值的候选序列,反之就将其加入频繁序列集合中。
3.2 算法描述
首先来详细描述提出的ProSVT算法(如Algorithm1所示),其输入参数有数据集D,子集块数量b,阈值θ,错误概率δ,敏感度Δ,隐私预算ε,算法的输出为最终的频繁序列集合。
ProSVT算法将数据集D分割成β个子集块B1,B2,…,Bβ,其中β=|D|/b,在同一时间只处理一个子集块。根据统计学的Vapnik-Chervonenkis(VC) dimension及相关公式计算出的误差参数α,然后由该误差参数α得到降低后的阈值ξ,将参数ξ作为新的阈值进行频繁序列挖掘,获得第一个子集块的输出结果。接着依次对后面的子集块进行操作,不断更新输出序列集,得到最终结果F并输出。
Algorithm 1:ProSVT
Input:datasetD,block sizeb,minimum frequency thresholdθ,failure probabilityδ,sensitivity Δ,privacy budgetε
Output:a setF
1β←|D|/b
3ξ←θ-α/2
4Q←pretreatment(B1)
5F←doubleNoise-getFS(B1,Q,Δ,ξ,ε)
6 returnIntermeiateResult (F,α)
7 for eachi←2,…,β-1 do
9ξ←θ-α/2
10Q←pretreatment(Bi)
11F←upadteRunningSet (F,doubleNoise-getFS(Bi,Q,Δ,ξ,ε))
12 returnIntermediateResult(F,α)
13F←upadteRunningSet(F,Bβ,ξ)
14 returnF
Algorithm2是改善过后的SVT法,即doubleNoise-getFS算法。该算法的输入为子集块B,查询队列Q,敏感度Δ,下调阈值ξ,隐私参数ε,输出为查询结果。
doubleNoise-getFS算法中,先将给定的隐私参数ε分为ε1(分配给支持度的隐私预算)和ε2(分配给支持度的隐私预算),然后分别计算出支持度噪音和阈值噪音,接着对于查询队列Q中每个查询序列的支持度和阈值添加噪音,保留噪音支持度大于噪音阈值的序列,并将其加入挖掘算法的中间结果。
Algorithm 2:doubleNoise-getFS
Input:subsetB,query queueQ,sensitivity Δ,lower frequencyξ,privacy budgetε
Output:query answera1,a2,…,a setF
1ε1=ε2=ε/2
3 for each queryqi∈Qdo
4 ifqi(B)+ρ1≥ξ+ρ2then
5 Outputai=qi(B) andF.add(ai), count+1
6 else
7 Outputai=⊥
3.3 隐私性证明
定理4:ProSVT算法满足ε1+ε2-差分隐私。
证明:由于在ProSVT整体算法中,doubleNoise-getFS算法中加入了支持度噪音和阈值噪音,因此需要证明加噪过程满足差分隐私保护。对于任意的输出a={丅,丄}l,只要证得:
(5)
首先考虑第一种情况:

fi(B,z)=Pr[qi(B)+ρ2<ξ+z]≤
Pr[qi(B')+ρ2<ξ+z]=
fi(B',z)
(6)
gi(B,z)=Pr[qi(B)+ρ2≥ξ+z]≤
Pr[qi(B')+ρ2+Δ≥ξ+z]≤
eε2Pr[qi(B')+ρ2≥ξ+z]=
eε2gi(B',z)
(7)
又因为|I┬|≤c,所以,

eε2Pr[A(B')=a]<
eε1+ε2Pr[A(B')=a]
(8)
然后考虑第二种情况:
∀iqi(B)≤qi(B'),记qi(B)≥qi(B')-Δ,所以有:
fi(B,z-Δ)=Pr[qi(B)+ρ2<ξ+z-Δ]≤
Pr[qi(B')-Δ+ρ2<ξ+z-Δ]=
fi(B',z)
(9)
考虑到约束条件qi(B)≤qi(B'),所以有:
gi(B,z-Δ)=Pr[qi(B)+ρ2≥ξ+z-Δ]≤
Pr[qi(B')+ρ2≥ξ+z-Δ]≤
eε2Pr[qi(B')+ρ2≥ξ+z]=
eε2gi(B',z)
(10)
再将积分变量z转换为z-Δ,可得:


eε1+ε2Pr[A(B')=a]
(11)
因此,该算法满足ε1+ε2-差分隐私。
4 实验及分析
本节对提出的ProSVT算法进行实验仿真,并从精确率、召回率和F-score等方面对ProSVT算法进行性能分析。
4.1 实验设置
实验环境为Intel® CoreTMi7-9750H CPU@2.60 GHz,16 GB内存,Windows10 64位操作系统,实验用Java语言实现具体的ProSVT算法。
4.1.1 数据集
实验基于两个公开可获得的真实序列数据集(见表1)。
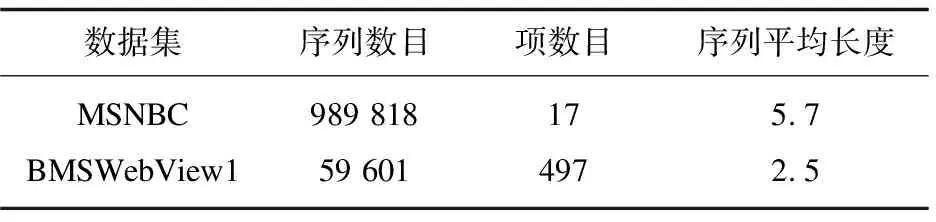
表1 真实数据集参数
MSNBC数据集为1999年9月28日msnbc.com网站按照时间顺序记录下的用户访问,数据集中的每个序列对应于该用户在24小时内的页面浏览点击,该数据集共有989 818条序列记录,点击项为17项,对应了17个页面类别,序列平均长度为5.7。BMSWebView1数据集用于KDD CUP 2000,它包含来自电子商务的clickstream数据,序列量为59 601,共包含497个不同的项,序列平均长度为2.5。
4.1.2 测试对象
测试主要集中在三个算法:(a)ProSVT:此算法是该文提出的差分隐私保护下的频繁序列挖掘算法;(b)Prefix:这是文献[13]中提出的一种构造前缀树挖掘频繁序列的差分隐私保护算法;(c)N-gram:此算法是利用可变长度的n-gram模型来挖掘频繁序列的差分隐私保护算法[14]。
4.1.3 指 标
在实验中测试的衡量标准为Precision、Recall和F-score。其中Precision为挖掘的精确率,Recall为挖掘的召回率,F-score为两者的综合评价指标。设Up是由具有隐私保护的算法挖掘得到的频繁项集,Uc是真实的频繁项集,具体定义如下:
(12)
4.2 实验结果
本节首先针对最低阈值θ和隐私预算ε对ProSVT算法进行测试,然后将ProSVT与Prefix、N-gram进行对比,并分析实验得出的结果。由于敏感度和序列长度成正比,因此在本实验中用平均序列长度来表征敏感度。
4.2.1 不同阈值
这里测试了ProSVT算法在隐私预算固定时,改变阈值对其挖掘性能造成的影响。图1和图2分别是在MSNBC和BMSWebView1数据集下的测试结果。实验结果表明,随着阈值的提升,挖掘结果的精确率、召回率都有明显的增加,从而使F-score也得到提升。因为阈值提高后,算法挖掘的候选频繁序列数目减少,出现误差的可能减少,由此提高了挖掘性能。用户在挖掘频繁序列时,不宜将阈值设置得过低,否则会大大降低挖掘结果的可用性。

图1 MSNBC:不同θ下的挖掘性能

图2 BMSWebView1:不同θ下的挖掘性能
4.2.2 不同隐私预算
这里测试了ProSVT算法在最低阈值固定时,改变隐私预算对其挖掘性能造成的影响。图3和图4分别是在MSNBC和BMSWebView1数据集下的测试结果。可以看出随着隐私预算的提升,挖掘结果的精确率、召回率都有明显的增加,从而使F-score也得到提升。当隐私预算增加时,所添加的拉普拉斯噪音随之降低,因此理论上会使挖掘结果更加精确。
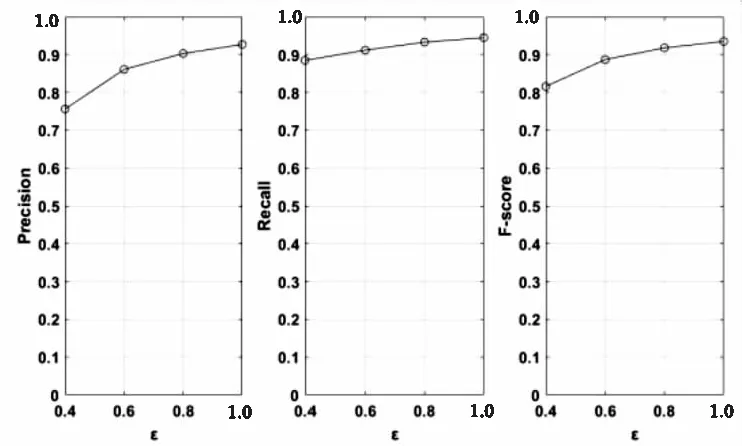
图3 MSNBC:不同ε下的挖掘性能
4.2.3 ProSVT与其他算法
这里测试当固定阈值,改变隐私预算时在两个数据集中ProSVT、Prefix以及N-gram算法的F-socre指标变化,如图5和图6所示。对于MSNBC数据集,ProSVT在低隐私预算时表现较差,当隐私预算大于0.4后,其挖掘性能较Prefix和N-gram更优秀;对于BMSWebView1数据集,ProSVT在各种大小的隐私预算情况下的挖掘性能表现都要优于Prefix和N-gram。

图5 MSNBC:三种算法的挖掘性能对比

图6 BMSWebView1:三种算法的挖掘性能对比
5 结束语
提出了一种满足差分隐私保护的频繁序列挖掘算法ProSVT。此算法是在Prosecco算法的基础上加入了改善过后的双拉普拉斯噪音方法以保证挖掘期间的差分隐私机制,以其渐进式、交互性的特点给挖掘者更便捷、有效的挖掘频繁序列的体验。在真实数据集下的相关实验表明了最低阈值和隐私预算的分配对于挖掘性能的影响,在和其他算法对比的过程中,ProSVT也有比较出色的表现。在隐私预算的分配中,对于支持度噪音和阈值噪音的隐私预算分配采用均分的方法,进一步的研究中可以针对隐私预算分配方法作深入的探讨。
