隐私数据库多关键词秘密同态检索方法研究
2022-05-14姜姗,曹莉
姜 姗,曹 莉
(河南中医药大学信息技术学院,河南 郑州 450046)
1 引言
在网络数据安全威胁指数不断上升的态势下,隐私数据库作为大部分用户选择承载隐私数据的安全平台,它的主要用处是针对数据储存以及访问数据进行一定的管控[1]。其中可以将管控分为两个方面,其一是隐私数据库在被访问过程中,必须要保证库中数据绝对安全性;其二是在未经授权的访问者想要访问数据时,系统必须拒绝访问数据的要求,这样才能够保证有效性,即可从根本上确保隐私数据库中数据的安全性[2]。
目前,越来越多的人将关键数据和个人信息提供给云数据库进行存储,外包前的数据加密是数据保护基本方法,从加密云中检索所需文件,可搜索加密技术在保证用户数据隐私的同时,实现数据检索服务,同时使用户能够也能够使用关键字正确有效地定位加密文件[3]。
杨旸[4]等人提议出一种基于隐私数据库的多关键词检索方法,首先根据该领域中加权评分的基本理念代入到需要检索的文档中,对需要检索数据进行输入题目关键词等处理,并在此基础上计算求解出不同类别关键词的本身权重数值;其次针对需要检索的关键词做对应的语义扩展处理,并且计算出关键词语义之间相似程度。最后,在对文档向量进行加密时进行分段,使每个分段乘以相应维数的矩阵完成检索。
周艺华[5]等人为保证云存储数据的安全性,提出一种f-mOPE数据库密文检索方案,该方法首先根据f-mOPE方法以及二值排序树的数据结构理论,形成检索明文以及对应的保序编码,并且在AES加密方法的基础上,将检索出来的隐私数据明文转换成为密文并将其加密处理,最后运用秘密同态技术获取出检索的数据。
上述两种方法虽然都可以有效保护用户数据的安全性,但实际上并不能保证检索的时效性。基于此本文将提出一种隐私数据库多关键词秘密同态检索方法。
2 模拟隐私数据系统模型
首先构建出一个模拟隐私数据库系统,将组成系统的参与者分为三个主要个体,分别是需要存储数据个体、根据关键词检索数据的用户个体以及存储数据的服务器。系统构成结构如图1所示。
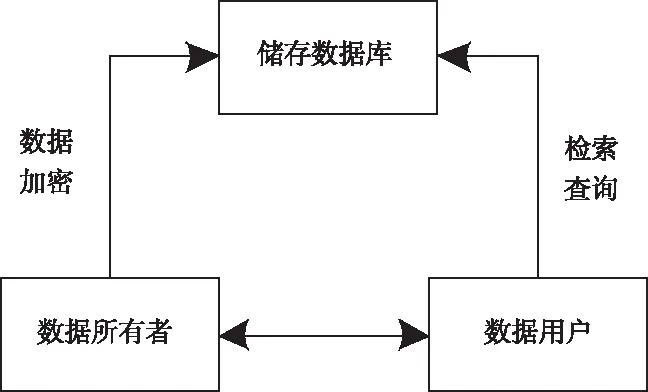
图1 系统模型图
假设存储数据的服务器既能保证数据隐私安全性又可以让不明身份的用户停止访问数据,那么当数据所有者将数据文件F=(f1,f2,…,fm)上传到存储器之前,就需要针对上传文件F进行加密处理。为了能够从根本上符合数据检索的分级条件,将对数据文件集F进行提取相对关键词W=(w1,w2,…,wp),在此基础上根据关键词的模糊集合构建出与关键词语义对应的陷门Tw以及数据加密检索索引,最后再将关键词检索索引传至加密隐私数库。这样当需要检索的用户在进行关键词检索的过程中,即可向数据所有者发送检索请求,在所有者同意的情况下检索用户获取对应陷门的函数密钥,这样在存储数据的服务器在接收到陷门的放行指令时,就可以完成根据数据文件关键词进行检索。
3 秘密同态技术
本研究使用秘密同态技术对统计数据进行加密,在不泄露的情况下处理敏感数据,秘密同态技术源于代数理论,其基本思想如下:
假设将Ek和Dk2分别描述为加密与解密函数,并且令明文数据空间中的元素是一个有限集合{M1,M2,…,Mn},而α和β分别表示为加密和解谜运算。如果α(Ek1(M1),Ek1(M2),…,Ek(Mn))=Ek1β(M1,M2,…,Mn)是一个相对成立的运算,且Dk2(α(Ek1)(M1),Ek1(M2),…,Ek1(Mn))=β(M1,M2,…,Mn)也是一个成立条件,那么就会将函数(Ek1,Dk2,α,β)族称之为秘密同态。
3.1 加密解密算法
在对数据进行加密解密处理的过程中,首先需要选择出两个相对应的安全素数p和q,然后让m=pq,其中m是隐私数据,再根据隐私数据选取出数据空间T=Zm以及隐私数据空间这样就有T′=(Zp*Zq)n,这里的n为数据库中较为安全的数据参数值,这样数据空间中计算集合F就可以由m加、m减、m乘、m除构建而成,并且隐私数据库中的运算集合也是由其构成,这样分别选取出rp∈Zp、rq∈Zq生成乘法子群Zp-{0}和Zq-{0},加密密钥为K=(p,q,rp,rq)。
加密过程:针对明文x∈Zm,任意地将x等同划分成为x1,x2,…,xn,xi∈Zm,i=1,2,…,n,使满足x=modm,其中对x的机密运算为
Ek(x)=([x1rpmodp,x1rqmodq],
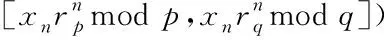
(1)
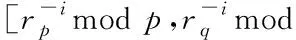
3.2 定理运算
根据上述加密解密结算结果,如果令文件数据x、y的加密运算为Ek(x)和Ek(y),并且其中包括了最高次指数幂运算n1和n2,那么乘积Ek(z)=Ek(x)Ek(y)就是由包括1≤j≤n(n=n1+n2)在内的次指数幂运算的项目Ek·j(z)构成的,这里将Ek(z)描述为向量形式便有
(Ek·1(z),Ek·2(z),…,Ek·n(z))
(2)
如果假设r=(rp,rq),那么Ek(z)就可以描述为多项式的形式
Ek(z)[r]=t1r+t1r2+….+tnrn
(3)
根据上式计算结果可得知加减乘除运算定义为
加法和减法
Ek(x±y)=Ek(x)±Ek(y)
(4)
其结果为Zm上的向量加减法或者是Zm上的多项式加减法。
于是便有
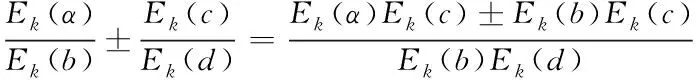
(5)
乘法
Ek(xy)=Ek(x)Ek(y)
(6)
其结果为Zm上的向量乘积或者是系数在Zm上的多项式乘积。
则有
Ek(xy)=Ek(∑xiyj)
=Ek((x1+x2+…+xn1)(y1+y2+…+yn2))
(7)
Ek(xy)可以被表示为多项式形式,便有
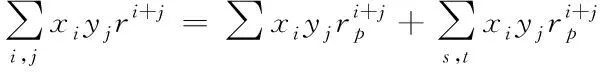
(8)
其中1≤i,s≤n1,1≤j,t≤n2,1≤i+j≤n。
除法:
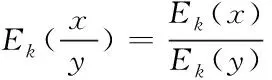
(9)
其结果为Zm上向量相除或者是系数在Zm上的多项式相除。
那么根据上述加减乘除运算便可进一步得出
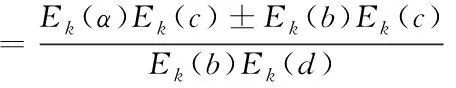
(10)
根据计算结果便可得知,这些运算保证可以直接对隐私数据进行运算操作。
4 多关键词下秘密同态检索方法
根据上述秘密同态技术运算定理,本研究将在同态加密基础上提出一种多关键词检索方法[6],其中检索模块将由以下五种模块构成:
1)Init():当隐私数据库在被不明身份者进行访问的过程中,DO会在存储隐私数据库中根据加密计算的参数λ形成同态加密前提下的公钥Pk以及私钥Sk;
2)Encrypt():DO根据数据文件集合形成的向量空间模型中文档向量D,将其采用公钥Pk加密的方式获取出对应的{D}Pk,并且把文档集合运用私钥加密方式进行加密进一步得出{DS}Ek,最后通过调试系统应用接口层中API接口上传加密数据文件;
3)Query():在数据库中检索用户向DO申请访问,如果数据所有者同意该检索方的申请,将会给出对应的公钥Pk密钥Sk以及隐私数据空间Ek,当检索方进行多关键词检索时,首先需要将初始检索向量扩展为目前标准检索向量Q,并且需要运用公钥Pk对其进行加密处理获取出{Q}Pk,这样即可调试应用接口层提交检索请求;
4)Score():当隐私数据库接收到检索方的申请之后,就会在隐私数据库中对向量Q和文档D之间的相关性分数进行计算,并且将每个不相同的计算结果反馈给到存储客户端中;
5)TopK():根据上述计算出的相关性分数结果,然后将其结果进行解密计算,此处根据TopK算法进行计算,最后获取出相关度最高的第K个文档数据编码,这样服务器接收请求就可以从存储层读取加密文档返回给客户端。
4.1 关键词权重
在信息获取领域有很多评价文档的权重模型,根据相关系数计算的基本原理,当一个关键字在文档中出现多次时,即单词频率系数越大,如果一个关键字出现在更多的文档中,使用这个关键字来区分文档的作用就更小,应该减少它的含义[7]。增加了关键字的个数,减少了每个关键字对文档的区分效果,这些关键字的含义应该是平衡的[8]。本文选择的权重公式如下
ωij=tfij×lnidf
(11)
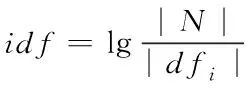
(12)
其中,将ωij描述为多关键词i在隐私数据库j中的权重取值,tfij表述为多个关键词i出现在文档中j的次数,而|dfi|则代表了文件结合中包括了关键词 的数据文件数量。
4.2 相关性分数
在对隐私数据进行访问的过程中,为了能够让检索用户不费时的收集众多含有对应关键词的数据文件,本文将采用以下两方面让检索用户得到更精简的检索结果,一方面是根据分级检索的方法过滤到部分不精准的检索结果,另一方面是通过添加关键字的数量来管控检索错误结果的大概范围,检索结果的点数越高,与其对应的检索结果相关性就会越高。基于此本文将采用了word-frequency逆文件频率模型,让数据文件中特殊关键字的word-frequency和整个文件集合中关键字的反作用频率来估测文件之间的相关性,这样便有
(13)
4.3 向量空间模型
由于已给定数据文件中多关键词的权重取值较高[9],因此,本研究将采用向量空间模型来对数据文件中多个关键字的权重进行度量,这样向量模型中与其维度对应的每一个关键词的取值,都将成为该关键词在数据文件中的权重去噪后,如图2所示。
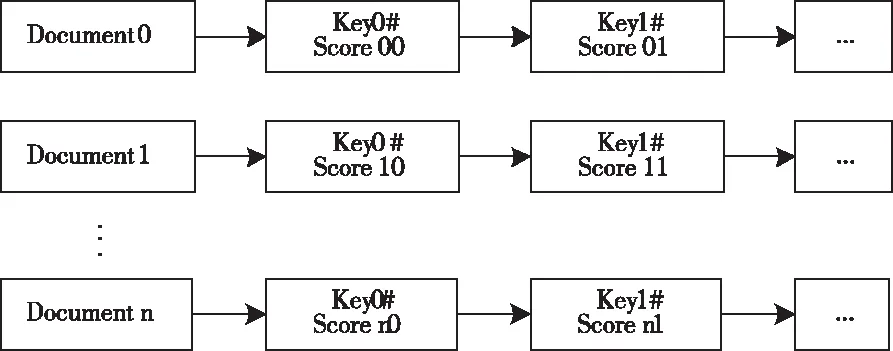
图2 向量空间模型
根据图2即可得知,在一般情况下向量空间模型是可以完全符合多关键词检索条件的,并且可以提供出一个对数据种类没有实质性要求的系统框架,所以此处本文将运用费布尔量化值来对其权重取值点数进行描述[10],如图3所示。

图3 向量空间模型计算诺请求向量
Score=vf·q
(14)
该评分计算方法考虑了文件中检索关键字的总数,即检索关键字越多,相关得分越高。
5 仿真与结果分析
为验证隐私数据库多关键词秘密同态检索方法研究的有效性与适用性,设计如下仿真检验过程。将实验搭建于Microsoft Visual Studio平台上,隐私数据流大小为1000byte,中心频率为5 GHz,噪声增益为-12dB,均衡系数为2.15。
根据上述设定的仿真环境,利用本文方法完成隐私数据库检索。终端数据频谱图如图4所示。
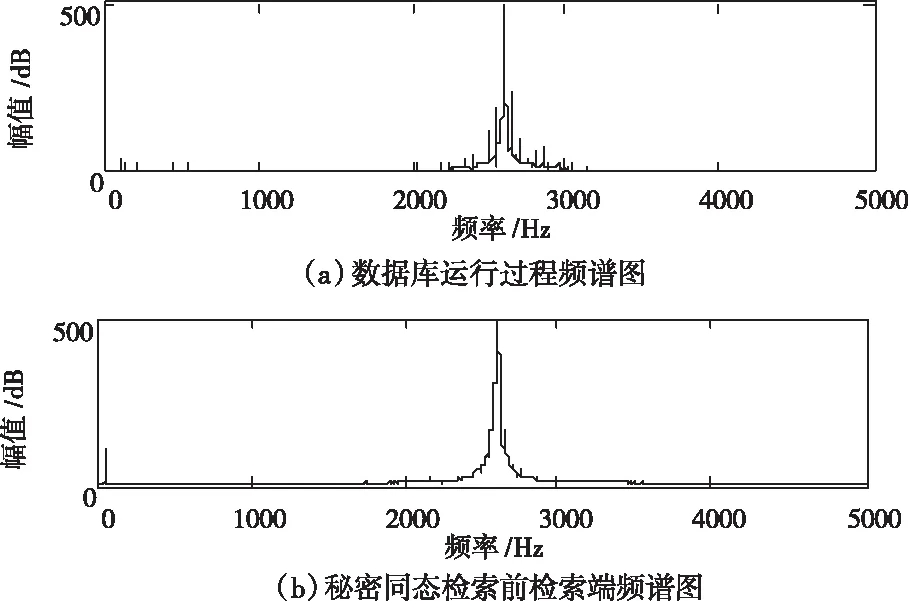
图4 终端数据频谱图
根据图4所示的终端数据频谱图进行多关键词秘密同态检索,在秘密同态技术的基础上,将数据库关键词分为五大模块,通过相关性分数以及向量空间模型完成索引,得到检索后的数据频谱图如图5所示。
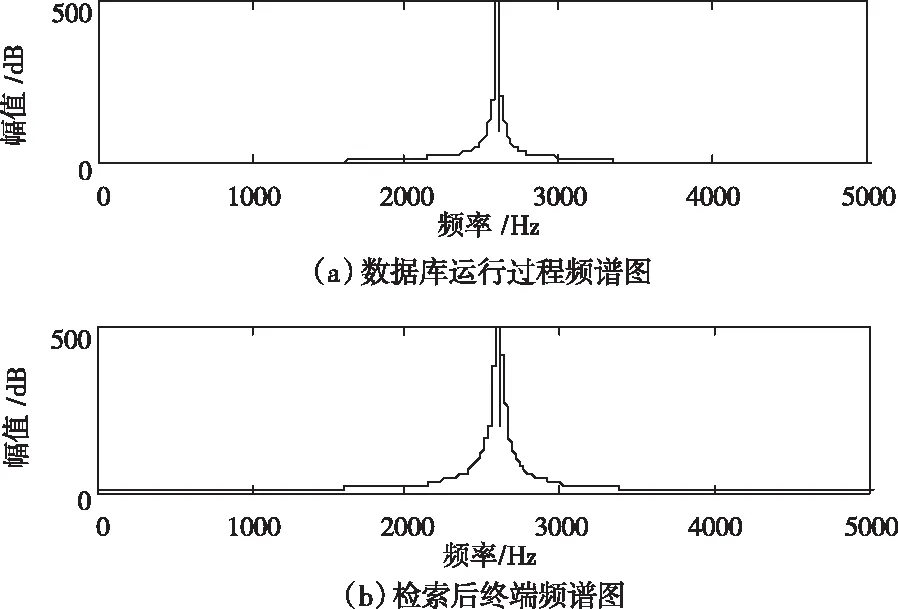
图5 检索后终端数据频谱图
分析图5所示结果可知,采用本文方法对 隐私数据库进行检索后,检索结果的输出性较好,输出状态较为平稳,初步证明了本文方法的有效性。
为突出本文方法的应用性能,从检索时间和稳定性两个角度,将本文方法与文献[4]中的基于隐私数据库的多关键词语义排序检索方法和文献[5]中的基于f-mOPE的数据库密文检索方法进行性能对比。
实现对比不同方法的检索过程耗时,结果如图6所示。
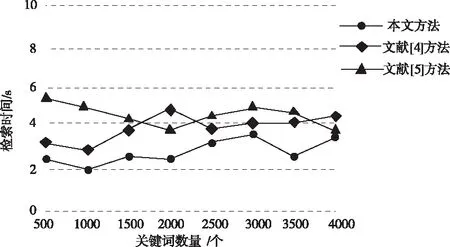
图6 不同方法检索过程耗时对比图
根据图6所示结果可知,随着检索关键词数量的增加,不同方法的检索过程耗时也在随之变化,且这种变化没有规律性。但是,本文方法的检索过程耗时始终保持较少状态,最少仅需2s,明显优于另外2种对比方法。
在此基础上,指定的初始密钥集大小为1000byte,不断增加密钥集大小,直到其大小达到3500byte,测试该过程中,不同方法的检索过程耗时,从而判断不同方法的稳定性。结果如图7所示。
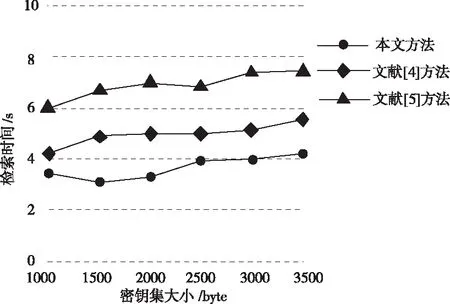
图7 不同方法检索过程用时对比
根据图7所示结果可知,随着密钥集大小的增加,不同方法的检索过程用时也在随之变化,整体均呈上升趋势。但本文方法的检索过程用时始终保持最小状态,最大的检索过程用时也仅为4.1s,明显少于另外2种对比方法。这一结果表明,尽管运行环境在不断变化,但本文方法稳定性较强,检索过程始终较快。
6 结论
本研究针对隐私数据库设计了一种多关键词秘密同态检索方法,在保证了数据安全性能的同时,根据相关性分数以及向量空间模型构建可搜索索引,从根本上避免了服务器端返回相关度不大的文件。同时,经过仿真结果证明了该方法具有实用性高、计算过程耗时少且稳定性较高的优点,表明该方法具有较好的应用前景。
