基于改进Faster R-CNN的码头自动识别
2022-05-12常莉莉王贤敏王春胜
常莉莉,王贤敏,王春胜
中国地质大学地球物理与空间信息学院,武汉 430074
1 引 言
随着建设“海洋强国”的战略形势方兴未艾,对于“走向深蓝”发展战略的重要一步——合理规划、治理港口和码头越来越受到关注。从遥感影像中对其准确识别能够为港口的建设与开发、海岸带地理信息的获取及海上军事实力的分析提供重要依据(刘腾飞,2018)。码头作为民用领域的重要交通枢纽和军事领域的重要打击目标,是港口组成的重要部分,对其进行自动识别研究具有十分重要的经济和军事价值。然而由于码头普遍尺寸小、数量多、分布散乱,且受周围船舶、建筑等环境干扰严重,传统方法难以满足对高速发展的码头进行精准监测的需求。如何对码头目标进行准确的识别成为亟需解决的问题。
码头目标识别的研究方法主要有传统的边缘检测方法(魏军伟,2007;黎经元等,2019;Yu等,2016)、面向对象的码头提取方法(刘亚飞等,2014;Li等,2019;Wang等,2019;Bhagavathy等,2002)以及基于特征的遥感图像港口检测方法(毕奇等,2019;李正威等,2018;Bovolo等,2013;Liu 等,2016a)。传统边缘检测方法的研究可以追溯到相位编组法,Burns 等(1986)依据码头边缘的局部灰度变化特征确定其位置和属性,该算法作为最早的码头检测方法,为后人提供了宝贵的经验。魏军伟(2007)以SPOT 影像为基础,提出了基于最大熵和形态学结合的边缘检测方法,该方法可以实现对码头边缘的快速提取。在面向对象方法方面,Li 等(2019)建立了面向对象的港口空间格局遥感检测方法,对码头实现了有效的检测;Bhagavathy 等(2002)提出了学习共同纹理特征的模型,能够对港口及港内目标进行有效的描述。在基于特征的检测方法方面,Bovolo等(2013)等采用雷达影像,利用变化检测层次化方法和多尺度技术实现了港口及港内目标的检测;Mandal 等(1996)利用启发式规则在聚类图像中加入目标及其相互关系的空间知识,实现了码头的识别。上述研究方法为码头识别提供了宝贵的经验,但传统的码头检测方法主要依赖于根据先验知识建立的港口或码头特征,受主观因素影响较大,对含有水域、建筑、船舶等复杂背景下的码头进行特征描述较为困难。
近年来,图像处理、模式识别和计算机视觉技术的飞速发展为遥感图像目标识别技术的提升创造了条件,将深度学习技术应用于遥感图像信息提取成为新的趋势。比如YOLO(Redmon 等,2016)和SSD(Liu等,2016b)等深度学习算法在高分遥感影像中的飞机、车辆、舰船等目标的快速检测(Kharchenko 和Chyrka,2018;Lechgar 等,2019;Li等,2020;Qu等,2020;Zhang等,2019),R-CNN(Girshick 等,2014)和Faster R-CNN(Ren等,2015)等深度学习算法在舰船、飞机、油罐等目标的准确识别(Wei 等,2020;Han 等,2020;Zalpour等,2020)。与此同时深度学习算法在码头识别中也成为新的发展趋势,Salakhutdinov 等(2011)利用SUN 数据集,采用层次结构共享的分类模型学习识别稀有物体,实现了船舶、港口、码头等多类目标的检测。除此之外,朱廷贺(2018)利用高分遥感影像数据,基于卷积神经网ResNet101(He 等,2016)结合人工设计特征与深度学习特征完成了港口及码头的目标检测。Ye 等(2017)利用ResNet101 和SSD 检测算法实现了大尺度遥感图像上的港口及码头检测。上述深度学习方法通过设计各种结构的网络模型和强大的训练算法来自适应地学习图像特征,完成对目标的分类和定位,在检测精度和效率方面均有很大的提升,并且对环境的适应能力较强。如YOLO 和SSD等单阶段算法可直接对输入的图像进行卷积特征提取,该类方法通过在特征图上进行边界框的回归,而将目标检测过程转化为回归问题处理,具有速度上的优势。与此相比,双阶段方法Faster R-CNN 则在精度上表现更加突出。该系列方法首先通过选择性搜索、边缘检测、区域提取网络等方法生成可能包含目标的候选区域集合,从而进行精确的目标类别估计和边界框位置回归(周天怡,2019)。当前的目标检测算法大多针对于自然场景中分布较为稀疏的中大型目标,且在通用数据集上取得了较好的效果,但对于码头此类小目标的检测仍有一定局限性。码头尺寸较小,在大幅遥感影像中所占像素数较少,携带的信息十分有限,纹理、形状、颜色等外观信息较匮乏,目标识别精度低、难度大,更容易出现漏检与虚警现象。
考虑到Faster R-CNN 将特征提取和目标识别定位整合在同一网络中,综合性能强,更适合多种尺寸的目标提取研究(Ren 等,2015)。因此本文将该算法引入到码头的自动识别中,并根据码头的尺寸特征和空间分布特征对算法进行了改进:(1)采用K-Means 算法(Hartigan 和Wong,1979)对候选框进行预设,使其大小更适应码头的尺寸;(2)采用Soft-NMS (Bodla 等,2017)代替NMS(Non-Maximum Suppression,非极大值抑制)算法(Neubeck 和Van Gool,2006)以降低分布密集地区码头边框误删率和漏检率。论文采用了多种评价指标对码头的识别结果进行定量精度评价以验证本文方法FKSN(Faster R-CNN+K-Means+Soft-NMS)的可行性,并证明该方法具有良好的普适性。
2 研究方法
2.1 Faster R-CNN网络结构
Faster R-CNN 算法通过引入区域建议网络RPN(Region Proposal Network)实现了对R-CNN(Girshick 等,2014)、Fast-RCNN(Girshick,2015)模型的优化,它的出现解决了检测算法中候选框生成耗时的问题,极大的提高了算法效率(Ren 等,2015)。如图1所示,Faster R-CNN 首先利用卷积神经网络ResNet101 对整幅图像进行特征提取,并采用RPN 寻找可能包含码头目标的建议区域,根据预先设定不同比例、尺度的锚点产生不同候选框,寻找最接近真实边框的候选框。通过RPN 提取的建议区域会和经ResNet101 提取的特征图一起输入RoI池化层中,最后通过全连接层进行码头目标的分类和边界框的回归定位。
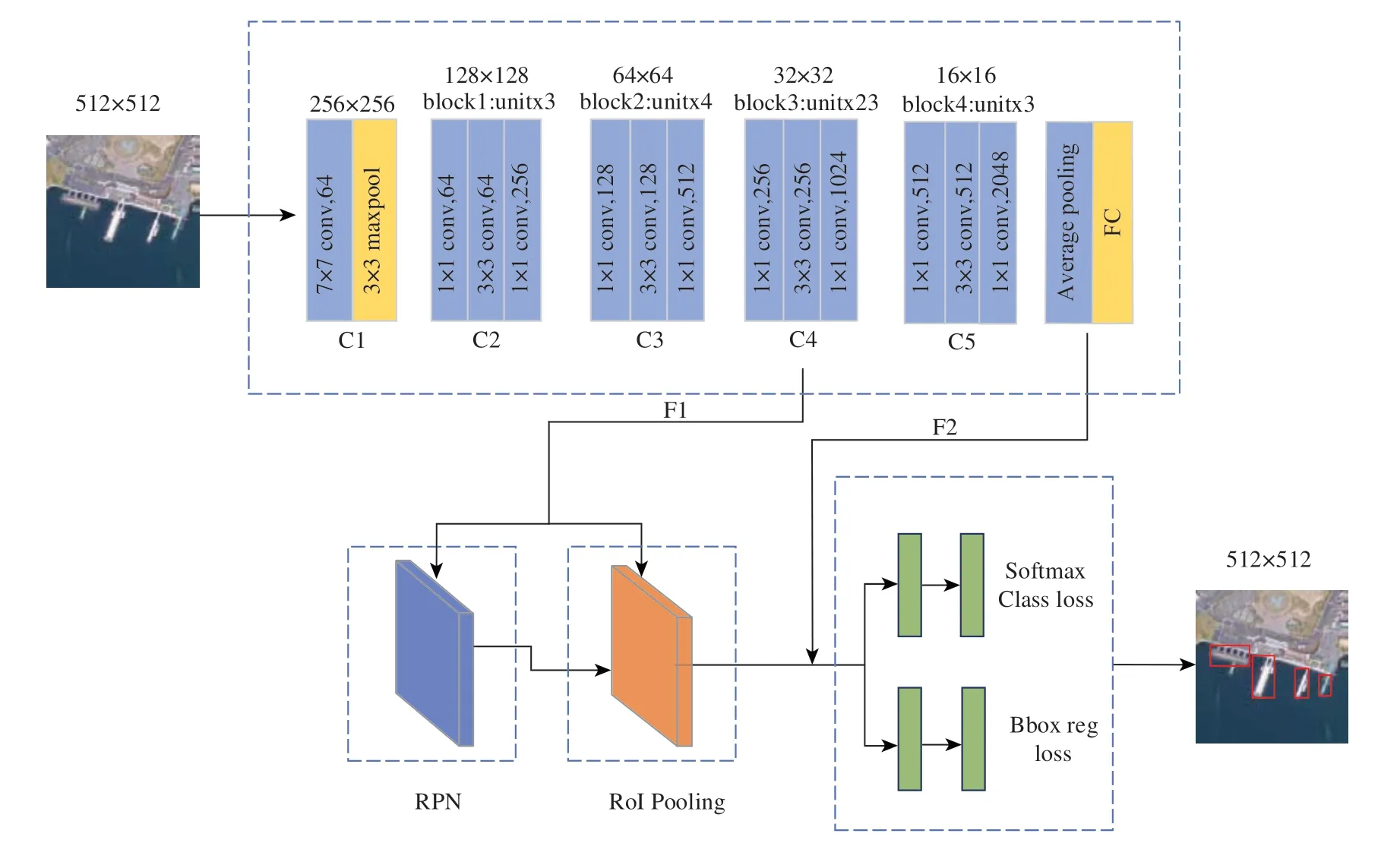
图1 码头识别的Faster R-CNN网络框架Fig.1 Faster R-CNN network framework for dock recognition
2.1.1 主干网络
本文采用残差网络ResNet101作为Faster R-CNN的主干网络进行码头目标特征的提取。ResNet101通过增加网络层数以挖掘图像深层语义特征,同时利用残差块以减少层深带来的计算量负担(He等,2016)。
通过ResNet101 网络7×7 卷积处理后的码头原始图像,经最大池化层后,大小由512×512缩小为256×256。在此基础上连接到由3 个瓶颈架构单元构成的C2 卷积层,然后依次经过C3 卷积层和C4卷积层,之后输出32×32大小的特征图F1。F1进入RPN与RoI Pooling用于候选框的筛选提取(Ren等,2015),RoI Pooling 根据RPN 给出的建议区域,从F1 中得到对应的局部特征,并进行汇总后输入到C5 卷积层进行再次学习,得到16×16 大小的特征图F2,最后进行最终的码头目标分类和定位。相比较常用的通过ResNet101 进行32 倍下采样进入RPN,该方法中特征图F1 的提取只有4 个池化层起到作用,从而更便于建立特征点与原始图像区域坐标的一一映射,且该方法经过初步候选框筛取后再次通过C5 卷积层进行学习,在减少算法对大量无用候选框计算的同时,能够通过多次卷积学习进行更准确的定位。
2.1.2 RPN网络
RPN 网络针对码头目标检测框进行端到端的训练,同时在原图上铺设不同比例的锚框,以产生匹配各种尺度目标的候选框进行图像中码头目标的自动识别(Uijlings 等,2013)。如图2所示,RPN结构中第一层是3×3卷积层,该卷积层的作用是增加目标附近区域的语义理解(Long等,2015);然后再经过两条支路P1、P2,每条都首先经过一个1×1 的卷积。支路P1 的作用是对前景和后景进行二分类(Girshick 等,2014),支路P2 的作用是进行矩形框的回归定位(Zitnick 和Dollár,2014)。两条支路汇合去除后景类别后,对于前景类别,RPN 先将锚框映射到原始图像上得到建议区域,然后对数量过多的建议区域候选框进行两次筛选:在剔除严重超出边界的候选框的基础上,对其余候选框进行最大值抑制(Neubeck 和Van Gool,2006)。最后对处理后的候选框根据类别得分进行排序,选取最优区域作为最终的目标框(Zitnick和Dollár,2014)。
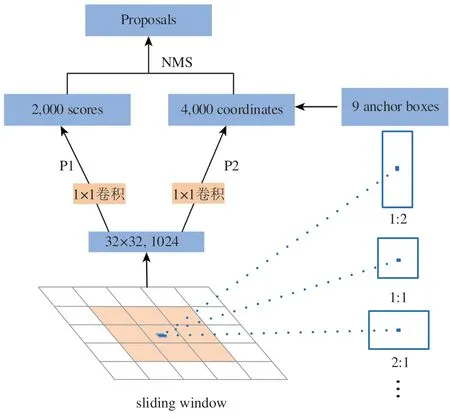
图2 RPN网络架构Fig.2 RPN network architecture
2.1.3 RoI Pooling
RoI Pooling主要是对建议区域进行池化,它的特点是将尺寸不固定的特征图转变为固定的尺寸(Girshick,2015)。RoI Pooling 以ResNet101网络输出的特征图和RPN 网络输出的候选框作为输入,并与C5 卷积层连接,经平均池化后输出16×16×2048 的特征图F2。最后Faster R-CNN 利用Softmax层对候选框进行码头二分类并输出候选框得分,同时利用Bbox reg 计算相对标注框的偏移量修正其位置,以得到更精确的码头候选框,最终完成对码头目标端到端的识别。
2.2 面向码头识别的Faster R-CNN改进
2.2.1 基于K-Means的码头候选框预设
K-Means 算法常用来解决目标检测出现的漏检及误检等问题(Hartigan 和Wong,1979)。标准K-Means 使用欧氏距离作为度量会导致目标框较大的聚类簇产生较大误差,因此本文以交并比IoU(Intersection over Union)(Rezatofighi 等,2019)为度量对码头数据集外接矩形的长宽比进行聚类,用于发现最佳的聚类簇数量。
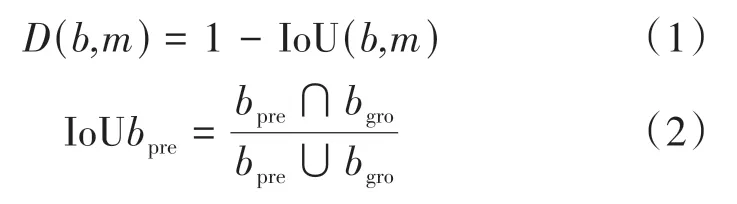
式中,D(b,m)是预测框b和聚类中心m的距离,IoU 是交并比,bpre表示预测框,bgro表示实际框。由式(1)可知IoU 值越大,预设框到聚类中心的距离越小。
码头候选框预设具体步骤如下:(1)首先随机选取k个码头外接矩形框作为初始锚框;(2)然后使用IoU 为度量,将每个码头外接矩形分配给与其距离最近的初始锚框,得到k个聚类簇;(3)计算每个簇中码头外接矩形框宽和长的均值,更新初始锚框。此时,每个簇的中心即为更新后的锚框;(4)重复第2 步和第3 步,直到锚框不再发生变化,在此过程中得到的平均IoU 随聚类中心k的变化曲线如图3所示;(5)最后结合变化曲线和elbow 方法(Saputra 等,2020)确定最终的k值。本文使用的elbow 方法其基本思想为:若某k值使平均IoU 的斜率发生了明显变化,该值即为真实聚类数。如图3所示,当k达到聚类数3 时平均IoU上升幅度达到最高,继续增加k值斜率会趋于平缓。因此根据elbow 方法和图3得到码头真实聚类数k为3。
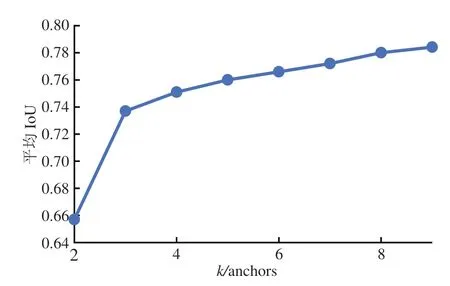
图3 IoU平均值曲线图Fig.3 Average IoU curve
根据上述系列步骤确定聚类数之后,本文采用K-Means 聚类算法(代码地址:https://github.com/ybcc2015/DeepLearning-Utils/tree/master/Anchor-Kmeans[2020-10-22],编程语言为Python3)将包括顺岸式、突堤式和引桥式的所有码头数据集聚类成3 个簇,这3 个聚类簇分别对应不同的锚框尺寸和长宽比,用于覆盖不同的码头类型。每个聚类中心的长宽比(90∶69,128∶129,317∶258)即(0.76,0.99,1.23),并且将原基本尺度(128,256,512)预设为(64,128,256)以更加适应码头尺寸。此时每个基本尺度对应3种不同的长宽比,最终得到9 个锚框(56,73),(64,65),(71, 58),(115, 142),(127, 129),(147,111),(223,293),(254,257),(283,230)。3 种类型码头的原始锚框与预设锚框对比效果如图4所示,其中图4(a)—(c)分别为突堤式码头、顺岸式码头和引桥式码头的原始锚框示意图,图4(d)—(f)分别为突堤式码头、顺岸式码头和引桥式码头的预设锚框示意图。由图4可知,原算法候选框在提取码头的同时会覆盖大量背景地物,而算法改进后得到的锚框更适合于码头尺寸。如图5所示为原始锚框与预设锚框的尺寸对比,其中黄色及蓝色框的基本尺度分别为64 和128,分别对应尺寸较小的突堤式码头和顺岸式码头,红色框基本尺度为256,用于覆盖尺寸较大的引桥式码头。同时,由于将所有码头外接矩形即长宽比进行聚类针对的是码头尺寸,而不是类型,因此对于大小相同但类型不同的码头会归为同一聚类簇中,即应用同一尺寸的锚框。
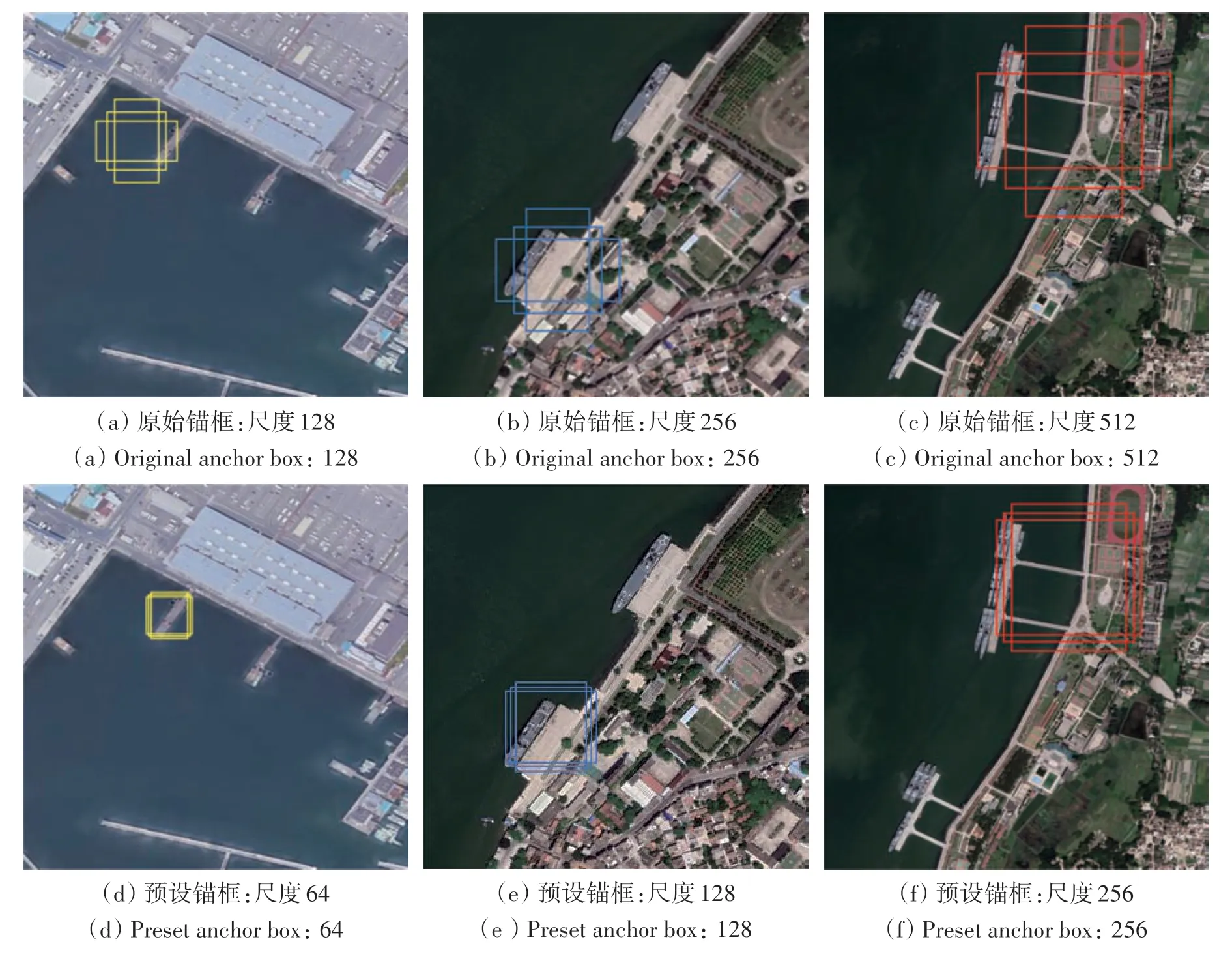
图4 原始锚框与预设锚框对比Fig.4 Comparison of original anchors and preset anchors
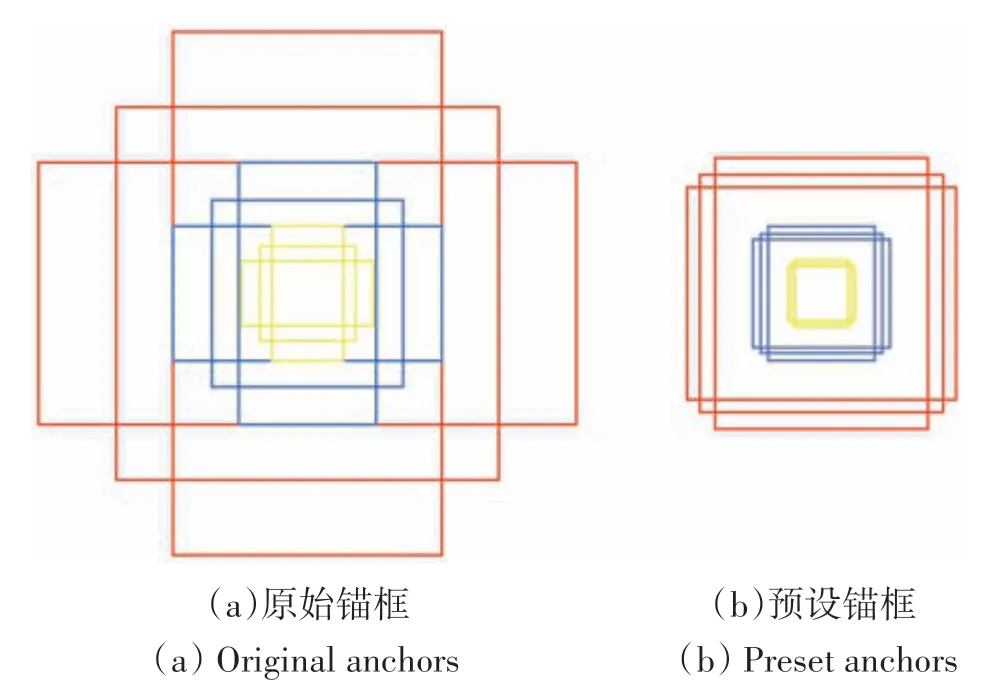
图5 原始锚框与预设锚框的尺寸对比图Fig.5 Size comparison of original anchors and preset anchors
2.2.2 基于Soft-NMS的码头定位
Faster R-CNN 采用NMS 算法去除重复的候选框(Ren 等,2015),但该算法易对重叠度高的边框产生误删,不能准确识别密集分布的多个码头,如式(3)所示。针对NMS 存在的不足,本文采用Soft-NMS 算法代替NMS。如式(4)所示,候选框bi与最高分候选框M重叠度越高,候选框bi得分越低;而候选框bi与M的重叠度小于阈值Nt,则候选框bi保留。对于码头分布较为密集的区域,NMS 更容易错过候选物体,而Soft-NMS 通过降低IoU 最大边框的置信度,保留其参与下一轮比对的可能,从而降低误删的可能性(Bodla 等,2017)。
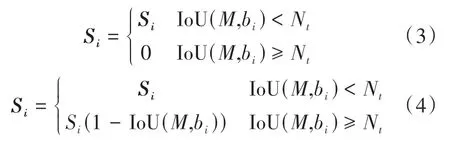
式中,Si是候选框得分集合,M为最高分候选框,bi待处理候选框,Nt为阈值。
如图6所示为NMS 算法与Soft-NMS 算法识别效果对比示意图。由图6可知,传统Faster R-CNN中的NMS 算法只选取重叠度区域中较高得分的候选框,造成了码头目标候选框的漏检。而改进后的Soft-NMS 算法保留了重叠区域中得分较低的候选框,降低了码头识别的漏检率。

图6 NMS算法与Soft-NMS算法识别效果对比Fig.6 Comparison of the recognition effect between NMS algorithm and soft NMS algorithm
3 实 验
3.1 实验数据集
3.1.1 码头解译标志
码头在遥感影像上的解译标志主要包括光谱特征、形状特征、尺寸特征和空间分布特征。码头在影像上呈亮灰色和部分船舶颜色接近;典型码头形状在影像上一般呈I 型、L 型和T 型,类型主要分为顺岸式码头、突堤式码头和引桥式码头(李正威等,2018)(图7);码头在影像数据集上像素占比较小,平均为0.03;在空间分布特征上主要表现在与陆地连通,且分布较为密集。
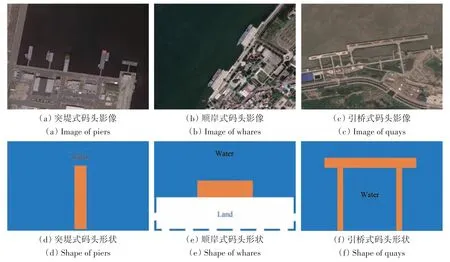
图7 不同地区的码头类型及形状Fig.7 Various types and shapes of docks in different regions
3.1.2 数据增广及数据集建立
本文对码头数据集进行随机旋转、亮度调整和增加噪声等数据增广方式提高数据的多样性(Taylor 和Nitschke,2018),以最终提高模型的泛化性能。本文基于公开遥感数据集DIOR(Li 等,2020)和Google Earth 遥感影像构建了码头目标数据集。该数据集大小为3000,其中各图像空间分辨率为1 m,尺寸大小为512×512。图像采集地区主要包括长江沿岸区域以及湛江、厦门等港口城市。本文将整个数据集分为互斥的训练集和测试集,其中验证集包含在训练集中。数据集中码头像素占比直方图如图8所示,可见像素占比大多在0.15 以下,码头目标较小导致识别难度增加。数据集中码头目标外接矩形的长度、宽度、面积及像素占比统计参数如表1所示。
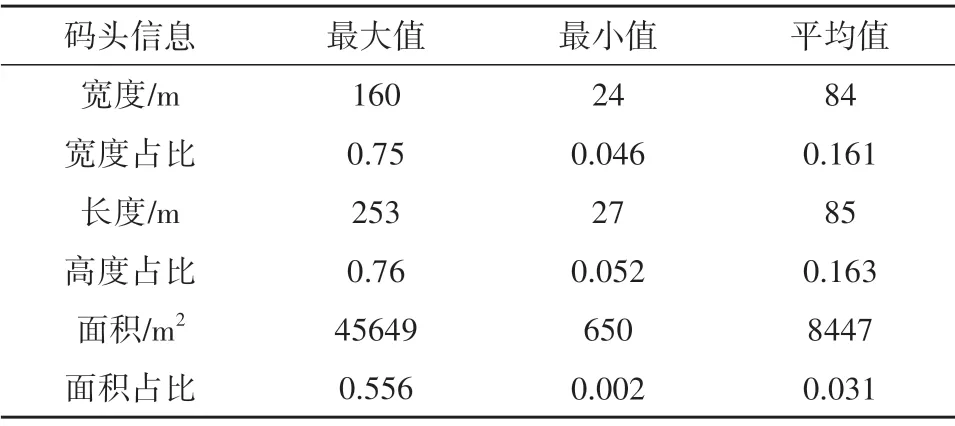
表1 码头目标统计参数Table 1 Statistical parameters of dock targets
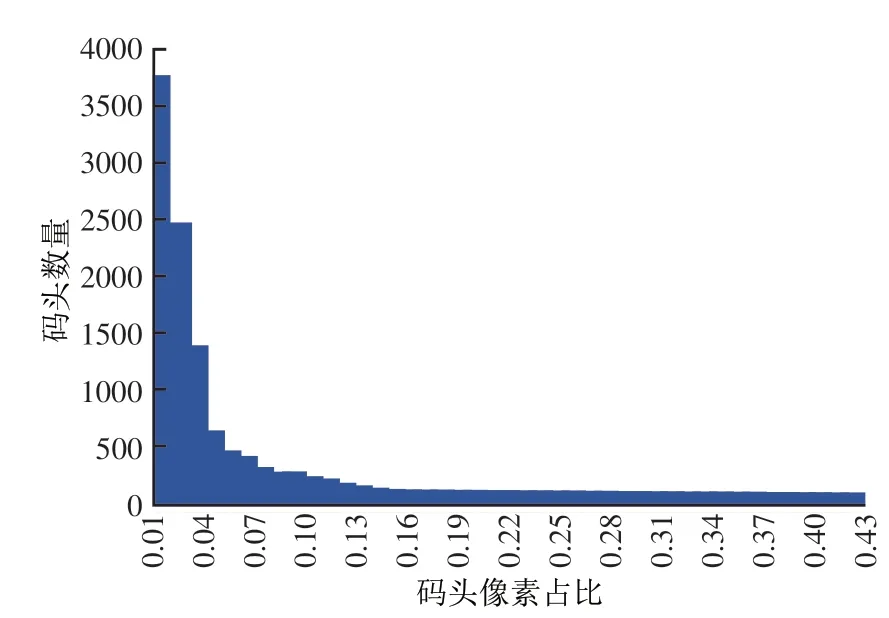
图8 码头目标像素占比直方图Fig.8 Histogram of pixel proportion of docks
对于数据集比例R,采用控制变量法对其进行选取,当训练集、验证集和测试集中样本数比例为6∶2∶2 时,训练精度和测试精度均最高(表2)。图9、10 分别为训练集和测试集中码头样本的情况,训练集采集自大连、秦皇岛、宜昌、江阴、厦门、天津等地区,而测试集采集自广州、湛江、海口、珠海、深圳、横滨等地区,两数据集均包含突堤式、顺岸式以及引桥式3种码头,具有尺寸及形状等特征的相似性。同时训练集和测试集中的码头来源于不同地区,具有空间差异性。因此算法在测试集中的识别精度能够很好地体现模型的泛化性能。

图9 训练集码头样本示例Fig.9 Dock samples in the training set

表2 数据集比例参数R值的选取Tab.2 Determination of the number ratio
3.2 实验平台
本文实验操作平台为Ubuntu 16.04 操作系统,使用CUDA10.0 和cuDNN7.5 加速训练,处理器为Intel Core i7-8700 CPU@3.20 GHz,GPU 为NVIDIA GeForce RTX 2080(8 G显存)。使用的编程语言为Python,开发框架为Tensorflow。Faster R-CNN 算法的框架链接为:https://github.com/endernewton/tffaster-rcnn[2020-10-22]。


图10 测试集码头样本示例Fig.10 Dock samples in the testing set
在码头识别过程中,数据集比例R、阈值Nt和batch_size 共3 个参数值的选取对模型性能影响较大,因此本文采用控制变量法进行选取。首先固定阈值Nt=0.5,batch_size=128,变化数据集比例参数R的值,当训练集、验证集和测试集中样本数比例为6∶2∶2 时,训练精度和测试精度均最高(表2),因此数据集比例参数R值取为6∶2∶2。采用同样的方法得到阈值Nt为0.5(表3),batch_size 为256(表4)。为避免在参数中引入较大的噪声导致迭代引起较大的震荡,本文参阅文献(Krizhevsky 等, 2012; Bengio, 2012; Smith,2017)选择了较小的学习率0.001。其余参数对模型影响较小,选择了初始参数,最终参数值如表5所示。
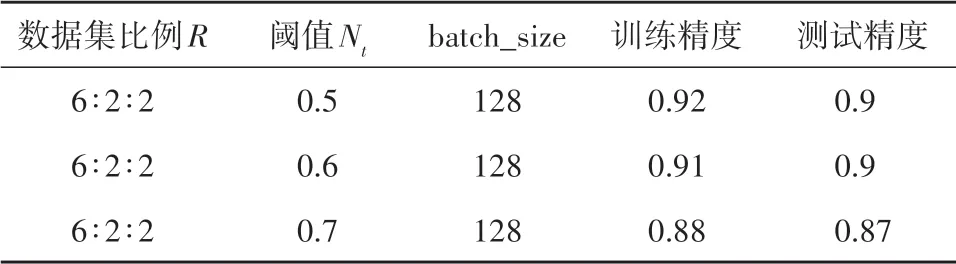
表3 阈值参数Nt的选取Table 3 Determination of the threshold
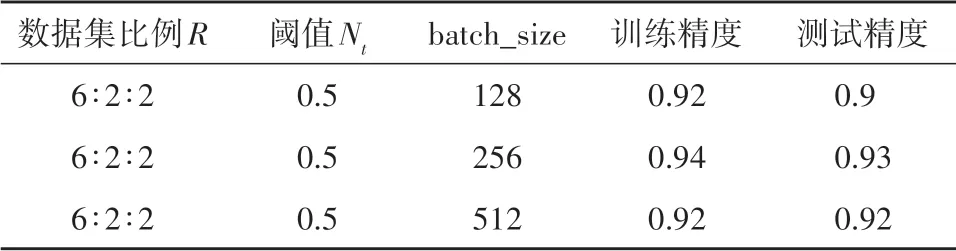
表4 batch_size参数的选取Table 4 Determination of the batch_size
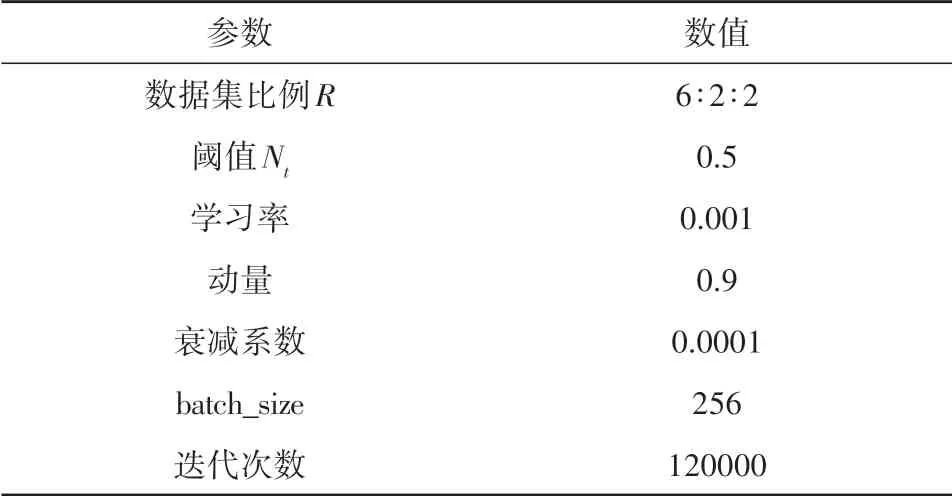
表5 深度网络中各参数值的选取Table 5 Values of various parameters in the deep networks
3.3 评价指标
为定量评价模型的性能,采用平均精度AP(Average precision)、准确率P(Precision)、召回率R(Recall)(Zhu,2004),以及漏检率(Missing Alarm)和虚警率(False Alarm)(Ma 和Bai,2015)作为评价指标。本文以TP 作为识别结果中正确提取的码头个数,FP 作为错误提取的码头个数,FN作为遗漏提取的码头个数。
(1)AP 是评价模型性能的重要指标,计算公式如式(5)所示:

(2)Precision表示在码头的预测结果中正确识别的比例:
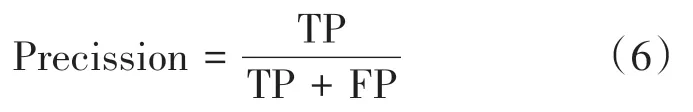
(3)Recall 表示在码头的所有真实标记框中正确识别的比例:
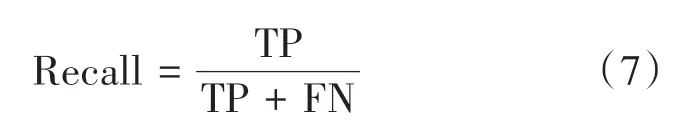
(4)虚警率是错误提取的码头目标占总识别数量的比例,计算公式如式(8)所示:

(5)漏检率是遗漏提取的码头目标占总识别数量的比例,计算公式如式(9)所示:
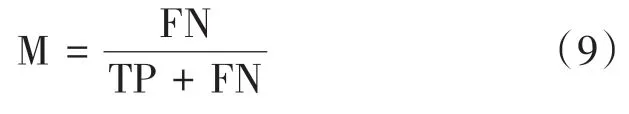
4 讨论与分析
4.1 训练函数
为比较算法的有效性,本文基于构建的码头数据集分别在SSD 算法、传统Faster R-CNN 算法、Faster R-CNN+Kmeans 算法以及本文FKSN 算法上进行了实验。4 种算法在码头数据集上的损失函数值Loss 随迭代次数的变化曲线如图11 所示。总体来说,4种模型的Loss曲线相对平滑,在模型训练初始阶段,各曲线的Loss 值均保持在一个较高的水平,随着迭代次数的增加,Loss 值不断缓慢振荡下降。当4 种算法模型都迭代到80000 次之后,各算法的Loss值基本趋于稳定。其中本文FKSN 算法在训练初期下降最快,并较其他3种算法持续保持更低的Loss值。SSD算法、Faster R-CNN 算法和Faster R-CNN+K-Means 算法的Loss 值最终稳定在0.31、0.30 和0.23。本文FKSN 算法的Loss 值在训练到120000次时最小,保持在0.20。
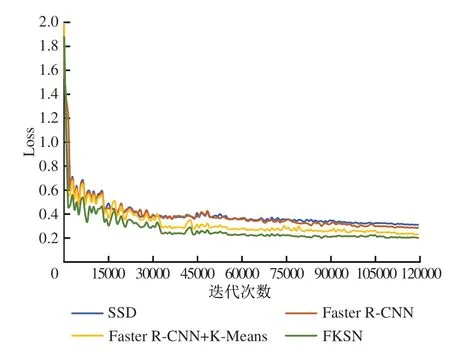
图11 不同算法的损失函数Loss曲线对比图Fig.11 Comparison of loss curves of various algorithms
4.2 精度检验及算法比较
测试集精度评价结果如图12 所示。相较于前4种算法,本文FKSN 算法的准确率AP最高,达到了92.6%,较传统Faster R-CNN 算法提高了8.3 个百分点。传统ISODATA 分类方法(Ball 和Hall,1965)的识别精度最低且虚警率(FalseAlarm)最高,说明该方法应用到码头的自动提取中效果较差。SSD 算法的虚警率及漏检率(Missing Alarm(%))指标表现同样较差,分别为28.1%和23.2%,说明该方法不能很好的对码头目标进行识别。与此相比,Faster R-CNN 的漏检率最高,说明该方法在码头目标识别中漏检最多。在Faster R-CNN+K-Means 和本文FKSN 方法的识别结果中,本文方法的召回率和漏检率最优,分别为90.2%和7.6%。在虚警率指标方面,Faster R-CNN+KMeans算法表现与本文方法相类似,说明通过采用K-Means 算法可以满足一定的目标识别任务,但Faster R-CNN+K-Means 的漏检率较高,说明该方法对小型目标的提取存在一定的缺陷。本文方法在识别精度、虚警率及漏检率综合表现更好,说明本文方法完全能满足对复杂地区小型码头目标自动提取的任务。
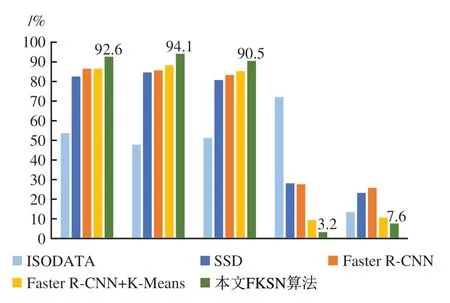
图12 不同算法精度评价对比Fig.12 Accuracy comparison of various algorithms
5 种方法在测试集中的识别结果如图13 示,(a)—(e)分别为5 种算法在横滨突堤式码头遥感影像上的识别效果图,(f)—(j)分别为5种算法在湛江顺岸式码头遥感影像中的识别效果图,(k)—(o)分别为5 种算法在广州引桥式码头遥感影像中的识别效果图。其中红色框为4种深度学习算法的识别结果。为更好的分析算法性能,本文在4种算法的识别基础上分别用黄色和蓝色标示出了漏检和虚警情况。传统ISODATA 分类方法的提取结果如图13(a)(f)(k)所示,该方法在识别出部分码头的同时产生大量的虚警,即将大量的人工建筑物和部分并排的船舶误提为码头,说明该方法在码头目标提取中性能较差。SSD算法的识别结果如图13(b)(g)(l)所示,Faster RCNN 识别结果如图13(c)(h)(m)所示。SSD 算法的识别结果总体比Faster R-CNN 低,两者在部分小形码头的目标识别中易将并排船舶误识别为码头,导致识别结果出现了明显的虚警现象。在Faster R-CNN 算法的基础上,采用K-Means 对候选框进行改进后得到的识别结果如图13(d)(i)(n)所示,与Faster R-CNN 算法比较,由于预设了更加适合码头尺寸的候选框,使得降低周围背景影响的同时提高了识别精度,但对于分布密集区的码头仍然存在漏检现象。本文FKSN 算法的识别结果如图13 (e)(j)(o)所示,该算法在Faster R-CNN+K-Means 基础上使用Soft-NMS 算法替代了原NMS 算法,使得在保持对尺寸较小的码头进行准确识别时,降低了分布密集区码头识别的漏检率。因此可以看出本文方法较好地提高了算法的性能。

图13 不同算法的码头识别结果Fig.13 Dock identification results of various algorithms
4.3 目标识别结果
本文选择沈家门港区进行大幅Google Earth 影像的码头自动识别性能验证,其中图14 为沈家门港区最终的码头识别结果图。如图14 所示,该区域图幅像素大小为5000像素×3500像素,空间分辨率为1 m。影像幅内共有82个码头,经过本文算法共识别出75 个码头目标。本文算法在提取过程中错误识别码头共3个,主要类型为杂乱排列的集装箱或者船舶,由蓝色掩膜表示。黄色掩膜为漏提码头共有7个,漏提原因一方面是影像分辨率不足以让算法提取足够的特征,另一方面是码头的尺寸在影像中占比过小且受周围环境影响。本文FKSN 算法应用在沈家门港区最终识别结果的准确率为96.1%,召回率为91.4%,虚警率为3.6%,漏检率为8.5%,证明本文提出的FKSN算法在大幅面遥感影像中的识别性能仍然表现良好。

图14 沈家门港区识别结果Fig.14 Dock identification result in the Shenjiamen dock area
5 结 论
码头作为民用领域的重要交通枢纽和军事领域的重要打击目标,对其进行自动识别研究具有十分重要的经济和军事价值。然而由于码头普遍尺寸小、数量多、分布散乱,传统方法难以满足对高速发展的码头进行精准监测的需求,从含有水域、建筑、船舶等复杂背景的遥感影像中对码头目标进行快速识别及精准定位非常困难。本文将Faster R-CNN 算法应用于码头的自动识别中,并针对码头的尺寸特征和空间分布特征对算法进行了改进。通过对不同地区不同类型的码头目标进行识别以及对沈家门港地区大幅遥感影像的码头进行自动识别性能验证,得出以下结论:
(1)通过采用K-Means 算法对候选框尺寸进行预设,使得候选框尺寸更符合码头的尺寸特点,从而在提高识别率的同时减少了背景中其他目标对码头检测的影响,降低了虚警率。
(2)通过采用Soft-NMS 代替NMS 使算法能够更稳定地计算候选框的得分,从而使得在码头密集分布的地区这些码头均能被准确识别。将K-Means 和Soft-NMS 同时应用到Faster R-CNN 算法有效的改善了虚警和漏检问题,提高了码头识别的精度和定位的准确性。
(3)实验结果表明该算法能够对不同地区以及顺岸式码头、突堤式码头和引桥式码头等不同形状的码头进行较为精准的识别,具有很强的普适性,未来工作可采取更高分辨率的影像对码头进行更精细化的分类。
