基于卷积核哈希学习的高光谱图像分类
2022-05-12薛朝辉张瑜娟
薛朝辉,张瑜娟
河海大学地球科学与工程学院,南京 211100
1 引 言
高光谱遥感能够感知全色或多光谱不能探测的地物。高光谱遥感的优势主要体现在光谱分辨率高,通常可达到纳米级,获取的影像数据同时蕴含丰富的空间和光谱信息(童庆禧等,2016)。然而,高光谱图像分类面临诸多难点。首先,高光谱图像存在“同物异谱”和“同谱异物”现象,像元容易混分;其次,高光谱图像波段众多,存在信息冗余,数据空间呈现复杂的非线性特性;此外,现实分类场景中的小样本问题导致分类模型极易陷入局部最优(杜培军等,2016)。因此,基于高光谱图像实现高精度、稳健的分类一直是该领域研究的热点。
当前,基于光谱特征的机器学习分类方法主要有:支持向量机SVM(Support Vector Machine)(Tarabalka等,2010)、随机森林(Belgiu和Drăguţ,2016)、旋转森林、多项式逻辑回归(Li 等,2012)、神经网络、核方法(Li 等,2013)、决策树、集成学习、多核学习(Tuia 等,2010)、稀疏表达(Chen 等,2011)等及其变种。然而,仅利用光谱信息很难大幅提升分类精度,同时分类器对噪声的鲁棒性不高。
随着高光谱图像分类研究的不断深入,基于光谱—空间联合特征的分类已成为主流。光谱—空间联合分类不仅利用光谱信息,还能充分挖掘像元之间的空间关系,从而有效提升分类精度(张良培和沈焕锋,2016)。光谱—空间分类方法的核心问题在于如何有效获取纹理、布局结构、形状、语义等空间信息以及如何将光谱信息与空间信息结合并挖掘更深层次的光谱—空间联合信息(张兵,2016)。目前,空间信息提取方法主要有:空谱联合马尔可夫随机场(Tarabalka 等,2010)、空谱联合滤波器(Fauvel等,2012)、邻域像元求均值或权重信息、空谱小波特征(Zikiou等,2020)、核Hilbert 空间嵌入(Gurram 和Kwon,2013)、数学形态学(Dalla Mura 等,2010a)等,该类方法能很好地弥补仅利用光谱信息的不足。此外,研究者还提出了基于字典学习和稀疏表示的高光谱图像处理与分析方法(张良培和李家艺,2016)。近年来,深度学习因其有效的深层特征挖掘能力和强有力的非线性表达能力,逐渐受到学者们的广泛关注(Li等,2019)。
哈希学习是一种提取紧凑特征并进行快速近邻搜索的技术,目前已发展成为机器学习和模式识别领域新的研究热点。哈希学习也被引入到遥感图像分类方面。Zhong 等(2016)提出了一种基于哈希学习的多特征融合方法,率先利用哈希学习提取紧凑二值特征进行高光谱图像分类。该研究对比分析了局部敏感哈希LSH(Locality-Sensitive Hashing)、核局部敏感哈希KLSH (Kernelized Locality-Sensitive Hashing)(Jiang 等,2015)、光谱哈希SH(Spectral Hashing)(Weiss 等,2009)、核哈希KSH(Supervised Hashing With Kernels)(Liu 等,2012)、迭代量化哈希ITQ (Iterative Quantization)(Gong 和Lazebnik,2011)和快速哈希(FastHash)(Lin 等,2014)对高光谱图像分类的效果,实验结果表明:局部敏感哈希和光谱哈希分类表现较差,核局部敏感哈希和核哈希分类效果良好,迭代量化哈希和快速哈希分类效果最好。Fang 等(2019)提出了一种新的深度哈希神经网络,将哈希学习与卷积神经网络相结合提取保持相似性的深度特征,实验结果表明:该特征与SVM相结合的分类精度优于其他特征提取方法和竞争性分类方法。Yu等(2019)通过哈希学习提取的语义特征嵌入到原始高光谱图像内进行卷积神经网络分类。
非线性哈希学习方法使用核哈希函数,在性能上比线性哈希函数有了很大的改进,代表性的方法有KSH 等。但是,将KSH 直接应用于高维数据时存在一些问题。首先,损失函数使用l2范数损失函数导致出现运行速度慢的现象;其次,原有方法并未考虑空间邻域信息。针对以上不足进行了以下改进:在核哈希学习中引入RBF(Radial Basis Function)作为损失函数;采用四维卷积挖掘更深层次的空间邻域信息,提出了一种基于卷积核哈希学习CKSH(Supervised Hashing with RBF Kernel and Convolution)的高光谱图像分类方法。
本文主要工作包括:(1)使用四维卷积充分挖掘高光谱图像邻域空间信息;(2)定义预测函数并进行核映射;(3)学习哈希函数与基于RBF的损失函数;(4)基于哈希编码和汉明距离实现高光谱图像分类。
2 研究方法
2.1 光谱—空间联合特征提取
研究发现利用空间信息可有效提高遥感图像分类精度(Fauvel 等,2012),比较有代表性的空间维特征提取方法有数学形态学(Dalla Mura 等,2010a)。数学形态学有严密的数学理论和几何学基础,其核心是将具有一定形态的结构元素在图像中不断移动,从中提取几何信息。
(1)扩展形态学剖面。扩展形态学剖面EMP(Extended Morphological Profile)由形态学剖面MP(Morphological Profile)堆叠形成。该方法首先利用主成分分析PCA(Principal Component Analysis)将高维数据降到低维,然后利用每个主成分PC(Principal Component)得到MP,其中图像像元x的MP定义为(Dalla Mura等,2010a):
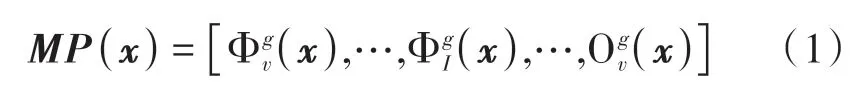
式中,g代表结构元素的大小,v表示重构操作次数,Φ 代表闭操作,O 代表开操作。将所有MP堆叠得到EMP:
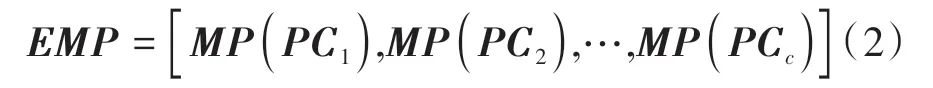
式中,c代表第c个PC。
(2)扩展形态学属性剖面。采用形态学属性的方法对每个PC进行细化和粗化操作,可得到图像的形态学属性剖面AP(Attribute Profiles),每一类属性ai,i= 1,2,…,z选取t′个属性值重建图像组合形成扩展形态学属性剖面EAP(Extended Attribute Profiles),将重建后的EAP以矩阵形式组合得到扩展形态学属性EMAP(Extended Multi-attribute Profiles)(Dalla Mura等,2010b):
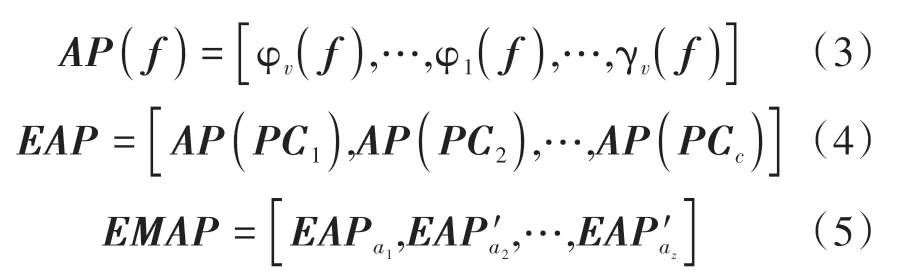
式中,φ和γ分别代表对灰度影像f进行细化和粗化操作;EAP′=EAP/[PC1,…,PCc],c代表第c个PC。
2.2 卷积核哈希学习
2.2.1 基于四维卷积的空间信息表征
基于四维卷积的空间信息表征包括两个部分:一是空间信息的构建;二是四维卷积。
(1)空间信息构建。利用像元的空间邻域信息去表达该像元。高光谱遥感图像X∈Rm×n×d,m和n表示二维几何空间信息,d表示光谱信息。首先在遥感影像X以补“0”的方式填充图像行和列的边缘,使用大小为ω=p×p,p= 2w+ 1,w∈N*的窗口,即邻域空间。从处理后的图像中第一个非“0”填充的像元滑动到最后一个非“0”填充的像元,提取出窗口ω所覆盖像元的波长信息来代替窗口中心位置所对应的像元信息,经过上述操作得到矩阵Z∈Rp×p×d×m×n。
(2)四维卷积。基于方法(1)构建的空间信息,设计四维卷积,挖掘更深层次的空间信息。如Yuan 等(2013)为了在空间和角度域中充分利用光场摄影图像的四维4D(four-Dimensional)结构信息,4D 卷积用于有效的表征类别内与跨类别的像素之间的复杂且信息量大的结构。前面得到的Z∈Rp×p×d×m×n表示分辨率为p×p×d的m×n个像元的高光谱图像,假设Y∈Rp×p×1×m×n表示高光谱图像里一个光谱波段下的五维张量,4D 卷积同时在高光谱图像的两个邻域空间和两个几何空间上应用卷积。通常,对于第q= 1,2,…,d层,输入Yq-1∈Rp×p×(q-1)×m×n和滤波器Wq,具体原理如式(6)和图1所示:
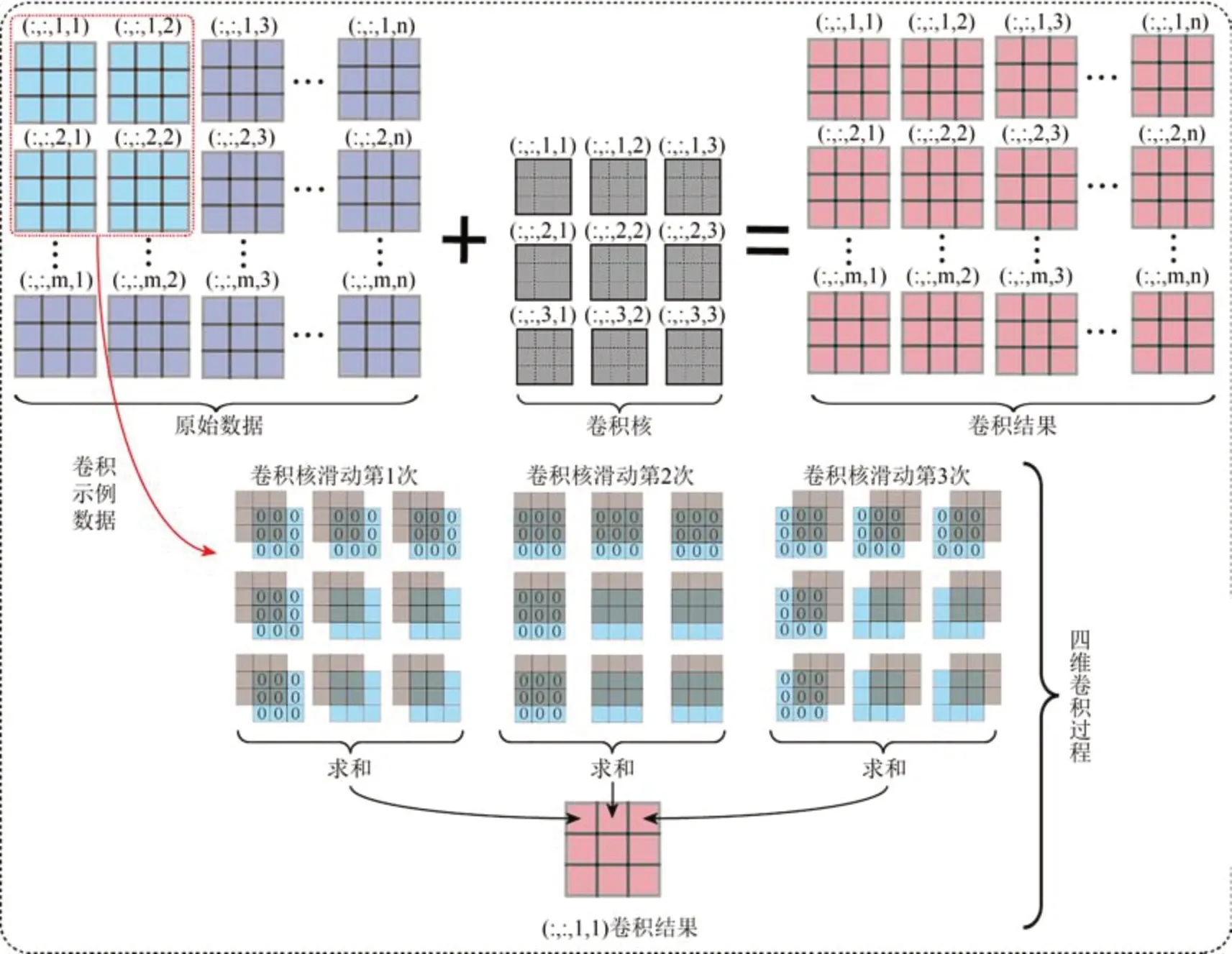
图1 基于四维卷积的空间信息表征Fig.1 Representation of spatial information based on four-Dimensional convolution
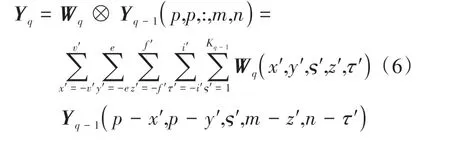
式中,Wq(x′,y′,ς′,z′,τ′)是第q层包含尺寸为Fp×Fp×Kq-1×Fm×Fn的滤波器,其中Fp对应邻域空间维的滤波器尺寸,Fm和Fn对应几何空间维的滤波器尺寸,Kq-1表示第q-1 层滤波器,⊗表示卷积操作,本文中卷积核里的数值均设置为1。
2.2.2 构建核函数和点对标签矩阵
Liu 等(2012)定义一个预测函数,并在该预测函数上进行核映射。初始定义预测函数pre(x)的具体做法是从训练数据集x=[x1,x2,…,xtr]中随机选择t个样本作为锚点x′=[x1,x2,…,xt]:
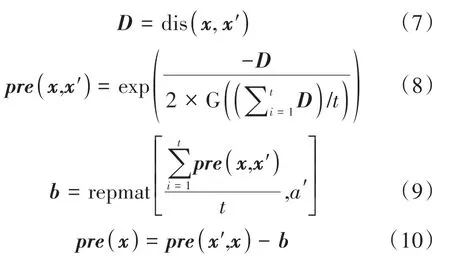
式中,dis 表示欧氏距离,G(·)表示求众数,repmat[A′,a′]表示将A′重复a′次。值得注意的是,样本数量t直接影响哈希学习的计算效率。
监督哈希与非监督哈希区别是是否使用标签信息,哈希目的是通过在编码空间中使用汉明距离来生成有区别的哈希码,使得相似数据对与不相似数据对区分开。具体来说,建立点对标签相似矩阵Sij:
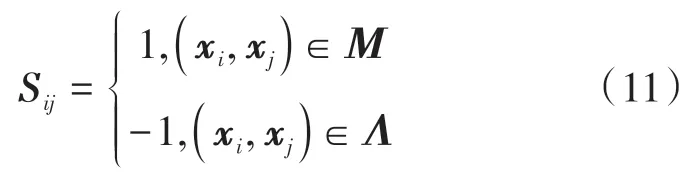
式中,Μ和Λ分别代表相似点对集合和不相似点对集合。
2.2.3 基于RBF的损失函数学习
哈希学习主要特点体现在学习能真实表达样本的哈希编码。为了获得哈希编码,需要先学习哈希函数h(x),具体学习过程同KSH(Liu 等,2012)。KSH中的损失函数L,即目标函数为
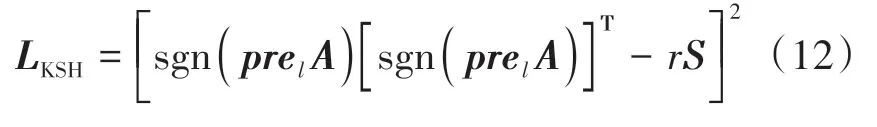
式中,pretr=[pre(x1),...,pre(xtr)]T∈Rtr×r表示训练数据集x的核函数,A=[a″1,...,a″r]∈Rr×t表示系数向量,r是哈希字节。
大多数现有的哈希方法都应用一种形式的哈希函数,通常使用的优化过程与该特定形式密切相关。这种紧密的耦合限制了哈希方法响应数据的灵活性,并可能导致难以解决的复杂优化问题。针对这一问题,Lin等(2013)提出一种灵活而简单的框架,称作两步哈希方法TSH(Two-step Hash),该研究使用不同的损失函数评估了TSH 方法的性能,其中TSH-KSH 使用了l2范数损失函数,TSH-RBF 使用了RBF内核的STH方法,从运行时间和精度两个方面均显示了TSH-RBF 的有效性。因此,本文改进了KSH中的目标函数,使用RBF作为损失函数:
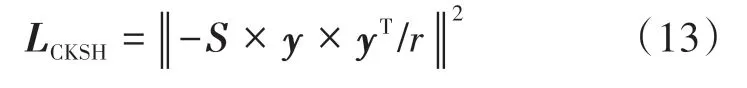
式中,y= sgn(pretr A)。
2.2.4 基于卷积核哈希学习的高光谱图像分类
由上一节可获得哈希函数h(x) ∈Rt×r,则某个样本xi的字节长度为r的哈希编码为
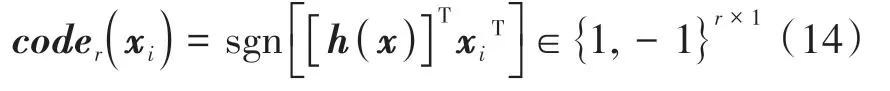
对待分类数据coder(xte)和训练数据coder(xtr)使用内积公式,得到相似度矩阵sim:
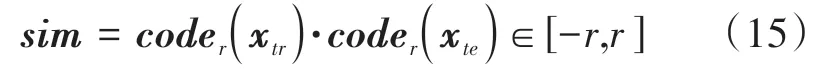
相似度矩阵sim表示两个哈希字节的相似度,当相似度为r时表明两个哈希编码完全相同;当相似度为-r时表明极不相似。根据待分类数据个数逐列对相似度矩阵sim进行降序排序,并返回位于top1位置的索引。根据该索引对应的训练数据,得到待分类数据的预测标签。以此遍历所有待分类数据,即可得到待分类数据的所有类别标签。本文提出的基于卷积核哈希学习的高光谱图像分类(CKSH)伪代码:

CKSH的流程图如图2所示。
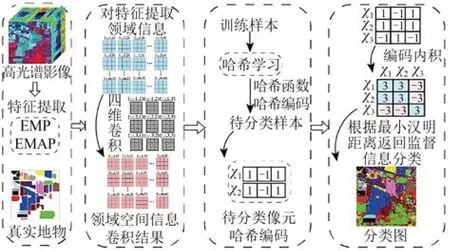
图2 基于CKSH的高光谱图像分类流程图Fig.2 A flowchart of hyperspectral image classification based on CKSH
3 实验结果与分析
3.1 实验数据
第1 套数据集为Indian Pines,1992-06 利用AVIRIS 传感器在印第安纳州西北部农场获取。该数据影像空间范围为145 像素×145 个像素,空间分辨率为20 m,光谱范围为0.4—2.5 μm,光谱分辨率为10 nm,包含224 个波段,剔除了水汽吸收波段,仅利用剩余200 个波段进行实验,包含16 种不同的农作物类别。该数据由美国普度大学的David Landgrebe教授提供。

图3 Indian Pines数据Fig.3 Indian Pines data
第2 套数据集为University of Pavia,2003-06利用ROSIS 传感器在意大利帕维亚大学获取,610 像素×340 个像素,空间分辨率为1.3 m,波长范围为0.43—0.86 μm,光谱分辨率为10 nm,包含115 个光谱反射波段,剔除了受噪声影响的波段,利用剩余的103 个波段进行实验,包含9 种不同地物类别,该数据由意大利帕维亚大学的Paolo Gamba教授提供。
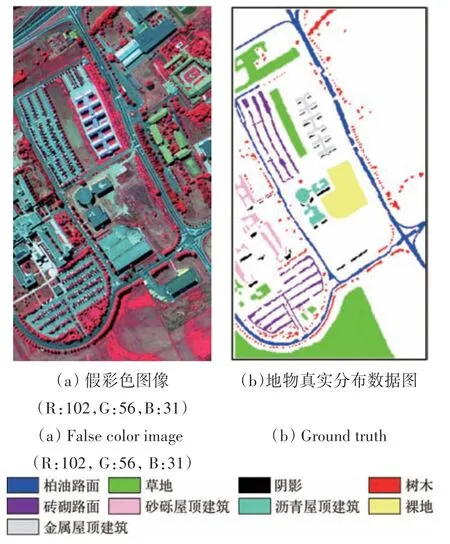
图4 University of Pavia数据Fig.4 University of Pavia data
3.2 实验设置
3.2.1 训练数据和精度评定
对Indian Pine 数据随机选择10%/类的样本作为训练集,剩余样本作为测试集;对University of Pavia 数据随机选择5%/类的样本作为训练集,剩余样本作为测试集。针对小样本条件下的实验(3.8 小节),Indian Pines 数据训练样本依次设置为[1%,2%,3%,…,10%];University of Pavia 数据训练样本依次设置为[0.5%,1%,1.5%,…,5%],剩余样本作为测试集。针对所有实验随机选择样本20次,并给出平均结果和方差。
采用总体精度OA(Overall Accuracy)、Kappa系数、逐类别的精度CA(Class-specific Accuracy)、平均精度AA(Average Accuracy)以及计算时间(Time)来评价不同方法的分类性能。
3.2.2 对比方法选取
为验证CKSH 算法的优越性,本文对比了6 种哈希方法和两种传统方法。哈希方法包括监督和非监督,其中非监督哈希包括LSH、SH、球哈希SpH(Spherical Hashing)(Heo 等,2012);监督哈希包括监督离散哈希SDH (Supervised Discrete Hashing)(Shen 等,2015)、潜在因子哈希LFH(Latent Factor Hashing)(Zhang等,2014)和KSH。传统方法包括SVM和随机子空间方法RSM(Random Subspace method)(Ho,1998)。
3.2.3 实验参数设置
卷积核哈希学习需要输入4个参数,包括空间窗口尺寸、卷积核大小、哈希字节长度和生成锚点的样本数。实验中将锚点的样本个数固定为300,其余参数进行优化选择,其中窗口大小的取值范围为3×3、5×5、7×7 和9×9;卷积核大小的取值范围为3×3×1×3×3、5×5×1×5×5、7×7×1×7×7、9×9×1×9×9(为简化说明,当卷积核尺寸为3×3×1×3×3 时,简记为卷积核尺寸为3);字节长度r的取值范围为[10,20,…,200]。基于以上设置,对不同数据通过实验选取最优参数。
本文中采用EMP 和EMAP 提取空间特征,实验中均取PCA 前3 个分量。对于EMP 选取圆形(disk)、菱形(diamond)、方形(square)等3 种比较有代表性的结构元素,每个结构元素的取值为[1∶10];对于EMAP 选取面积(area)、对角线(diagonal)、惯性矩(inertia)、标准差(std)等4 种比较有代表性的属性。对于EMAP 中不同结构元素的设置如下:
(1)EAPe′:λe′=[10050010005000]
(2)EAPu′:λu′=[102550100]
(3)EAPr′:λr′=[0.20.30.40.5]
(4)EAPs′:λs′=[20304050]
3.2.4 平台环境
所有的实验均在Intel Core i7-7700HQ CPU,2.80 GHz,内存为64 GB 环境下,采用MATLAB R 2015软件运行得到。
3.3 哈希字节长度对分类结果的影响分析
为了验证哈希字节长度r对总体精度的影响,图5—图6显示了两幅数据集在不同窗口尺寸、卷积核大小和哈希字节长度下的分类结果。从图中可发现,当窗口和卷积核大小固定时,随着哈希字节长度的增加,分类性能也会随之增强。这是因为哈希字节越长,生成的哈希编码更具有判别力,相比于较短的哈希编码,它能蕴含更多的信息,有利于基于哈希编码的分类。然而,分类精度不会随着哈希字节长度的增加而一直提升;当哈希字节长度达到某个值时,分类精度会趋于稳定,甚至发生轻微的波动。例如,在图5(c)中,当卷积核大小和哈希字节长度分别为7 和170 时,分类精度达到最高;当哈希长度增长为190时,分类精度有所下降。在后续实验中,对于不同数据,将哈希字节长度固定为200。
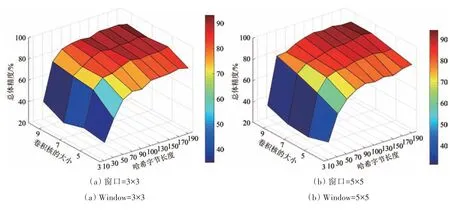
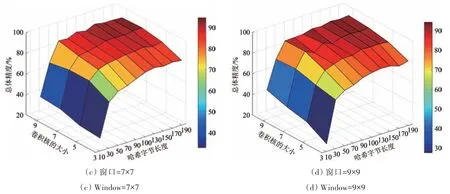
图5 窗口、卷积核、哈希字节对分类结果的影响(Indian Pines)Fig.5 The impacts of window size,convolution kernel,and hash bytes on classification accuracy(Indian Pines)
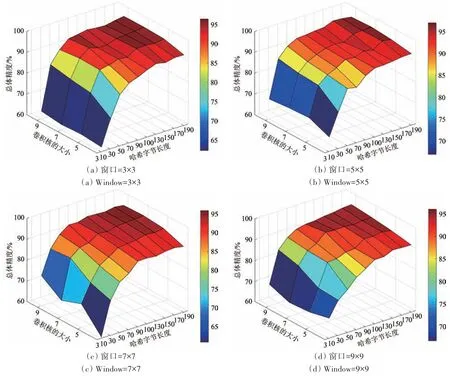
图6 窗口、卷积核、哈希字节对分类结果的影响(University of Pavia)Fig.6 The impacts of window size,convolution kernel,and hash bytes on classification accuracy(University of Pavia)
3.4 窗口尺寸和卷积核大小对分类结果的影响分析
为分析窗口尺寸和卷积核大小对分类性能的影响,在3.3 小节基础上,绘制了总体精度在不同窗口和卷积核条件下的三维图,如图7所示。从图7 中可以看出,当窗口尺寸固定时,分类性能会随着卷积核的增大而有明显提升;当卷积核大小固定时,窗口增大对分类性能的影响比较小。这是因为当窗口尺寸大于卷积核时,会过多的引入混合像元,导致分类结果出现波动。因此,应尽量避免窗口尺寸大于卷积核的情况。在后续实验中,将两幅数据的窗口尺寸和卷积核大小分别固定为5×5和9。
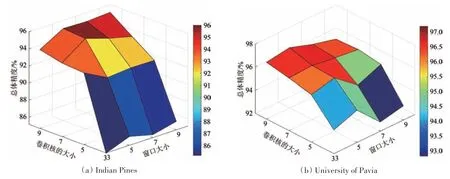
图7 不同窗口和卷积核大小对分类结果的影响Fig.7 The impacts of window size and convolution kernel on classification accuracy
3.5 不同哈希方法在光谱特征上的分类对比
为在光谱特征上验证CKSH 算法的分类性能,对比了6 种哈希方法。观察图8发现,所有哈希方法的分类结果均随着字节长度的增长而提高;当字节长度在10—100 变化时,CKSH 算法的分类精度持续缓慢升高;而其他哈希算法在10—30 的分类精度会随着字节长度的增长而提升,之后趋于稳定。这说明CKSH 算法随着字节长度的增长可以挖掘更多信息,从而有助于分类精度的提高;相比于KSH,CKSH 算法分类精度高的原因是它引入了四维卷积,使得它在表征像元之间复杂结构时具备一定的优势;相比于其他5种哈希方法,当哈希字节为30 时,CKSH 方法的分类精度远高于其他方法。以上实验结果说明本文提出的CKSH 算法在光谱特征上的分类性能优于其他方法。
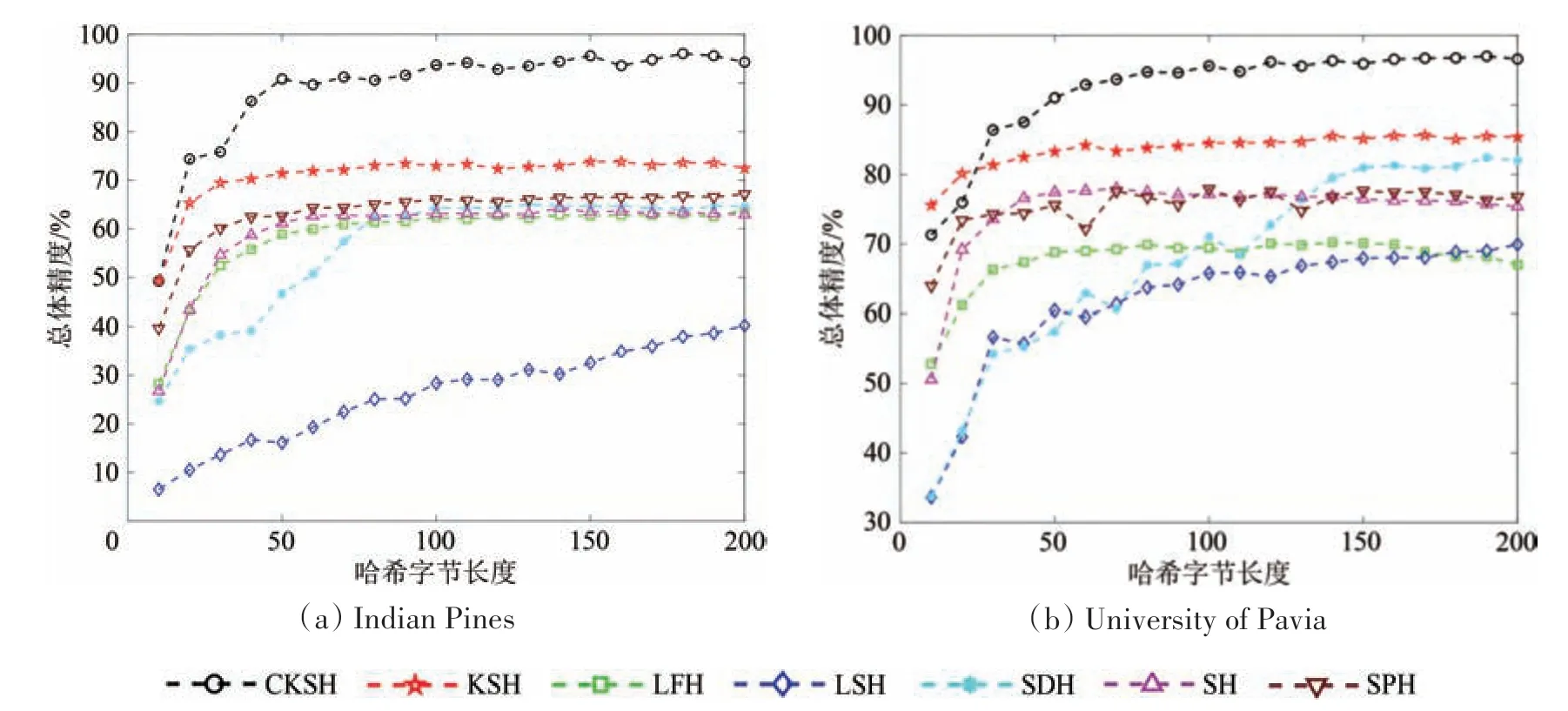
图8 采用不同哈希方法对分类结果的影响(原始光谱数据)Fig.8 The impacts of using different hash methods on classification accuracy(based on original spectral data)
3.6 不同哈希方法在光谱—空间特征上的分类对比
本节实验对比了光谱—空间特征EMAP和EMP在不同哈希方法和传统方法下的分类结果,如图9所示。从图9中发现,7 种哈希算法分类精度均随着哈希字节长度的增长而提升,表现最好的算法是CKSH,表现最差的算法是LSH 算法,这是因为LSH 算法随机生成哈希函数,而CKSH 算法通过深入挖掘底层特征,生成具有更高判别力的哈希编码,有利于提高分类精度。通过分别对比图9(a)和图9(b)、图9(c)和图9(d)可以发现,基于EMAP 特征的分类性能更好,这是因为EMAP 考虑了4个属性,并且基于属性滤波器的扩展轮廓在描述空间特征方面的能力更好。在哈希字节长度从10 增加到30 时,CKSH 算法的分类精度增长速度最快。综上,CKSH 算法在基于光谱—空间联合特征上也表现出了最佳的分类性能。
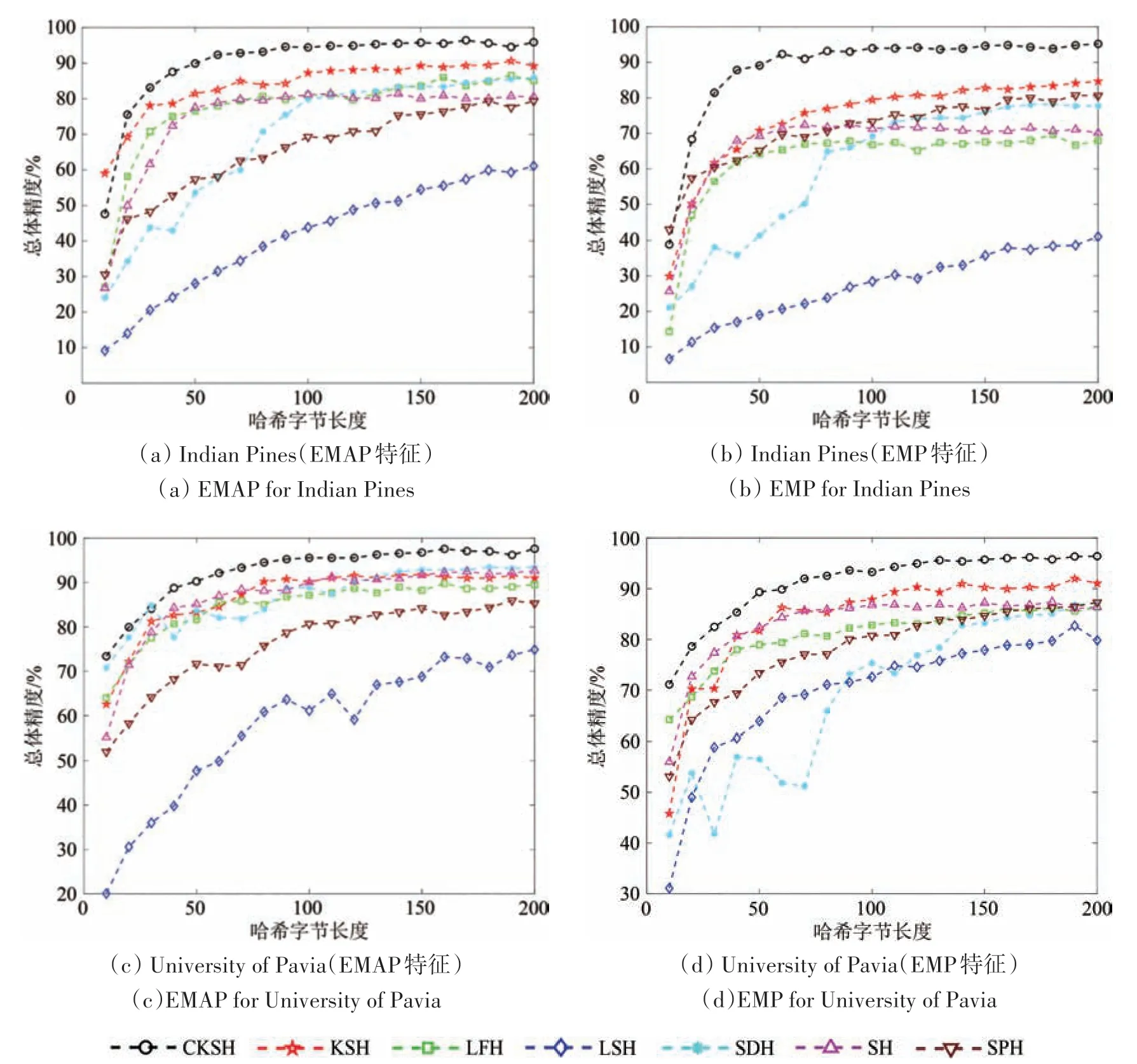
图9 采用不同哈希方法对分类结果的影响(空间—光谱特征)Fig.9 The impacts of using different hash methods on classification accuracy(Spatial-spectral features)
表1、表2出了5种哈希方法和2种传统方法对两组数据在EMAP 特征上的分类结果。从表1中可以看出,CKSH 算法均得到了最高的分类精度;对比不同地物类别的分类精度,CKSH方法对14个地物的分类精度最高;对比不同算法的计算时间,CKSH 用时10.68 s,远低于KSH 的时间,说明改进后的基于RBF 的损失函数能显著提升算法运行速度;同时,引入空间信息有助于提升算法分类性能。图10、图11 展示了两组数据的分类图,可以看出基于CKSH 方法得到的分类图更平滑和准确,而其他算法的分类图存在明显的斑点噪声现象。
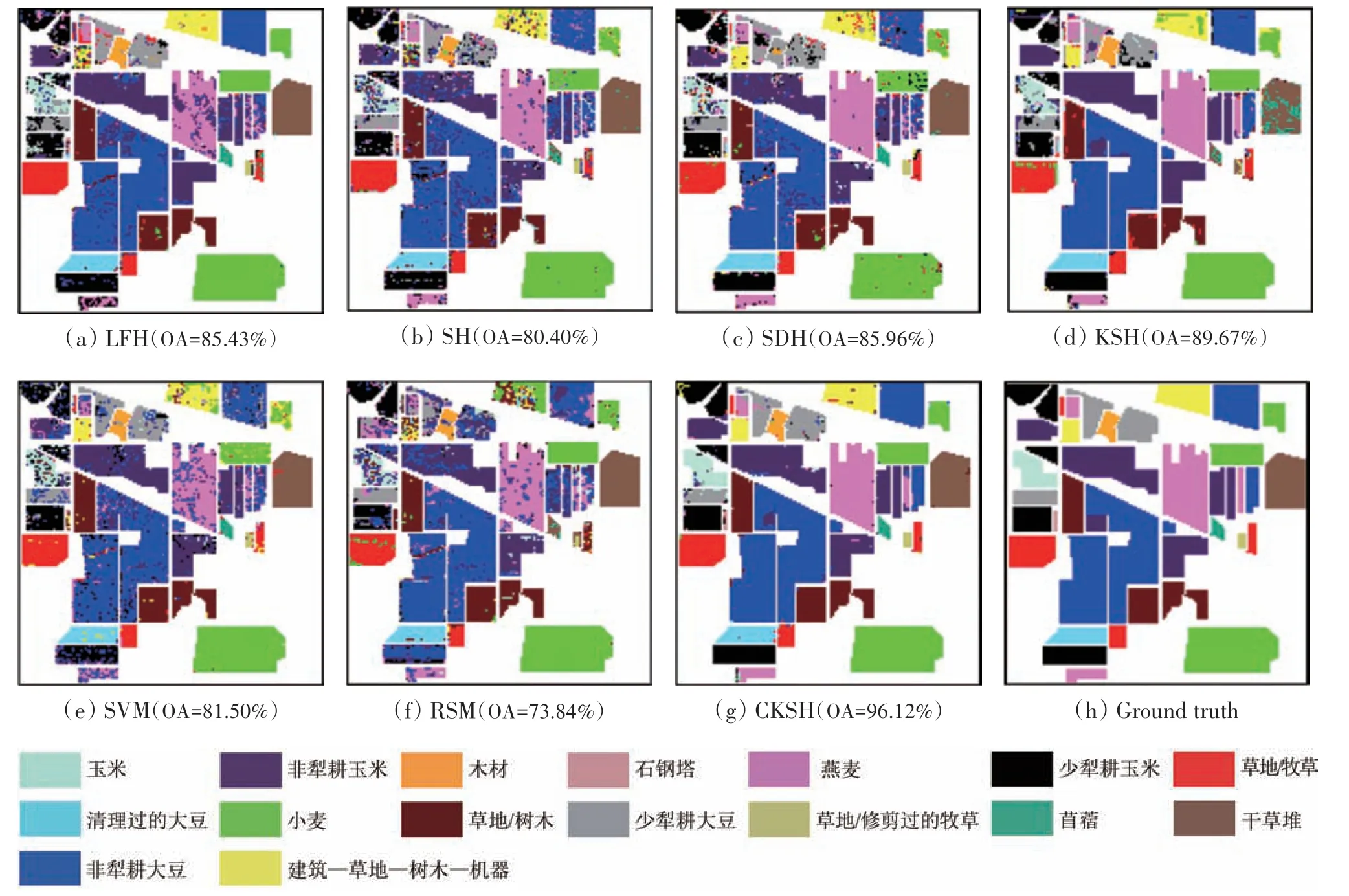
图10 不同方法对EMAP特征的分类图(Indian Pines)Fig.10 Classification maps obtained by different methods based on EMAP features(Indian Pines)
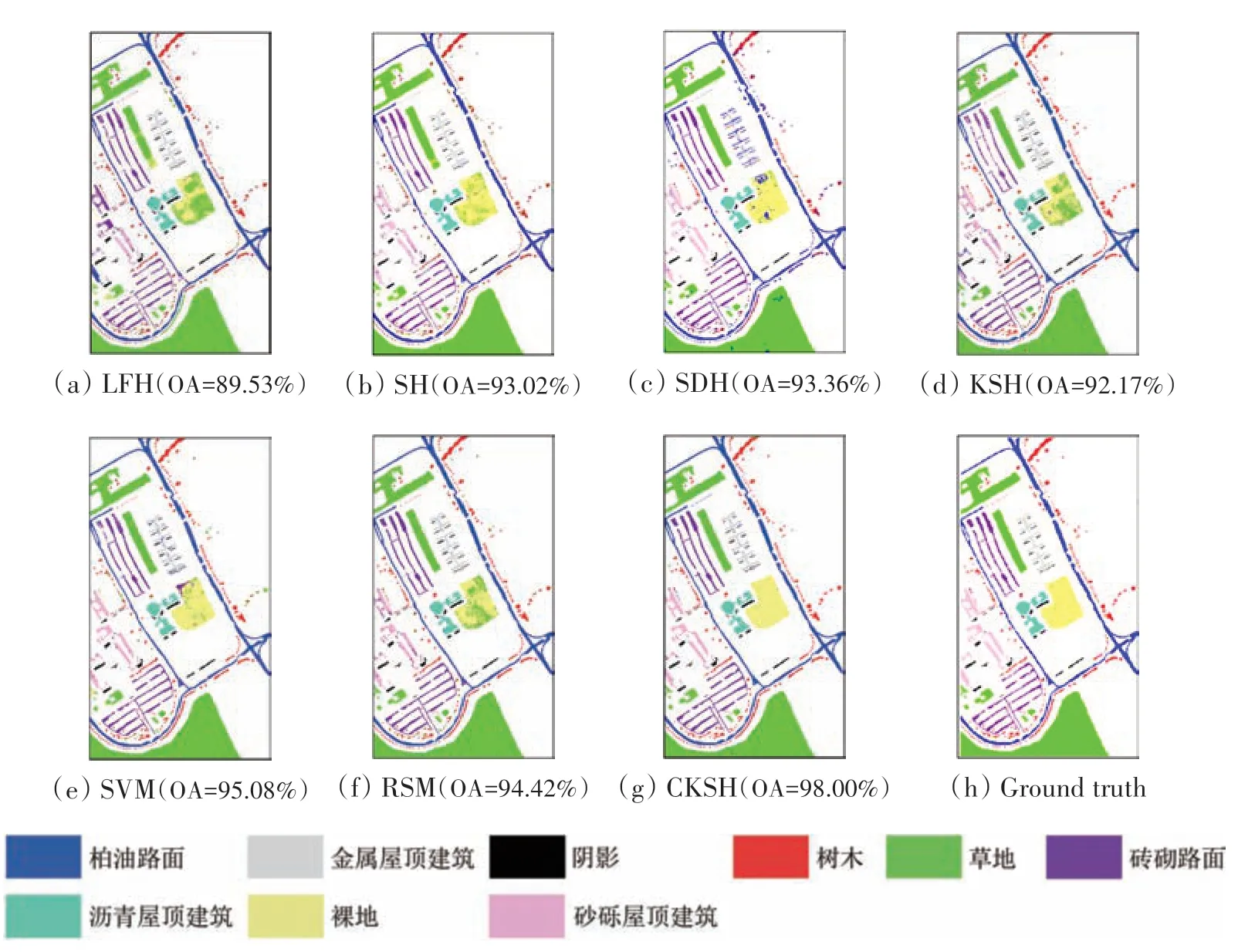
图11 不同方法对EMAP特征的分类图(University of Pavia)Fig.11 Classification maps obtained by different methods based on EMAP features(University of Pavia)
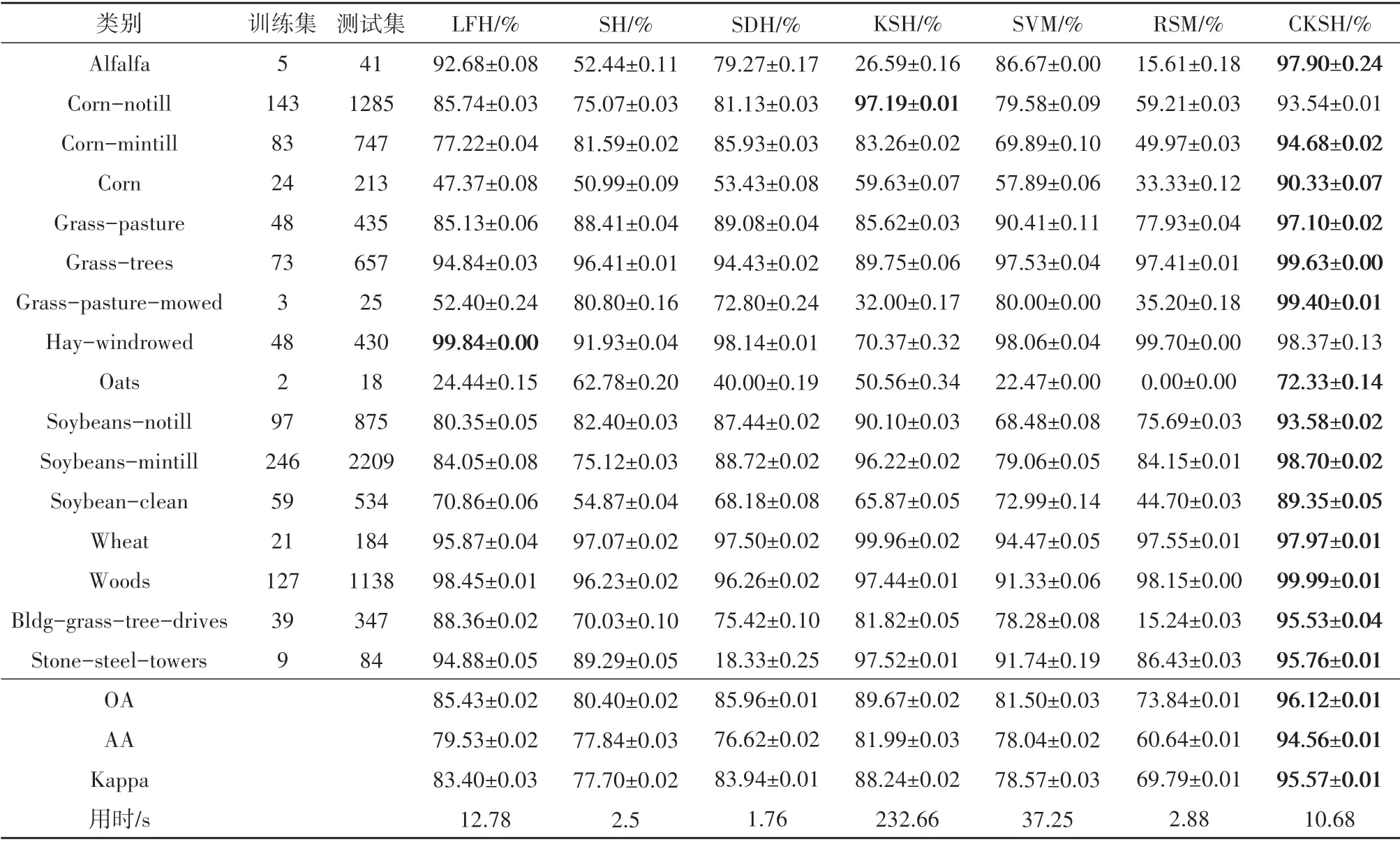
表1 不同方法对EMAP特征的分类结果(Indian Pines)Table 1 Classification results obtained by different methods based on EMAP features(Indian Pines)
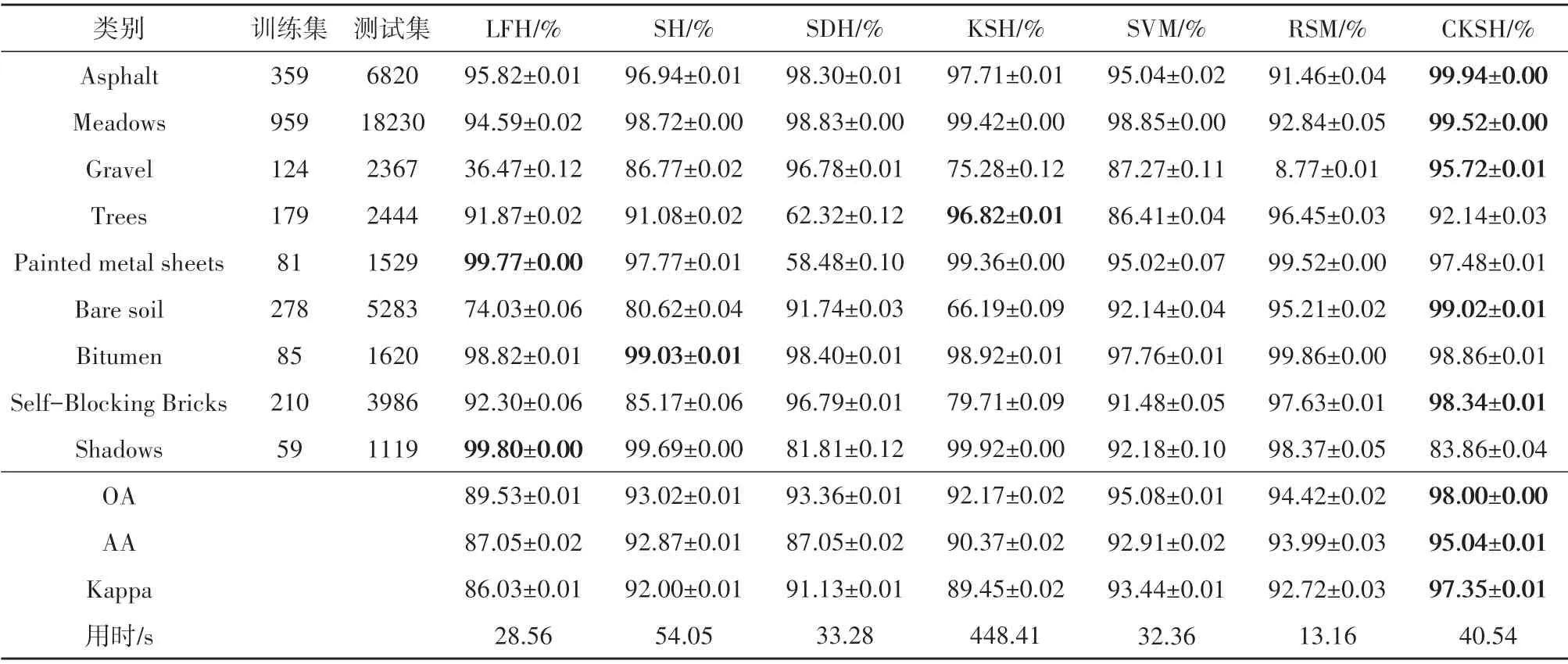
表2 不同方法对EMAP特征的分类结果(University of Pavia)Table 2 Classification results obtained by different methods based on EMAP features(University of Pavia)
表3、表4列出了5 种哈希方法和2 种传统方法对两组数据在EMP 特征上的分类结果,对比表1、表2可以看出,采用EMAP 特征得到的分类结果好于EMP 特征,这说明EMAP 特征具备更强的空间—光谱特征表达能力。从表5中可以看出,CKSH 方法的OA 为97.01%,高于其他分类方法约3.78%—11.14%;CKSH 方法用时42 s,远少于KSH 的224 s,说明改进后的损失函数能很大程度减少运行时间;在Trees 和Shadows 这两个地物类别上分类较差,这是由于地物较分散,导致卷积过程混合其他类别信息。综上,空间信息的引入有效提升了CKSH算法的分类性能。
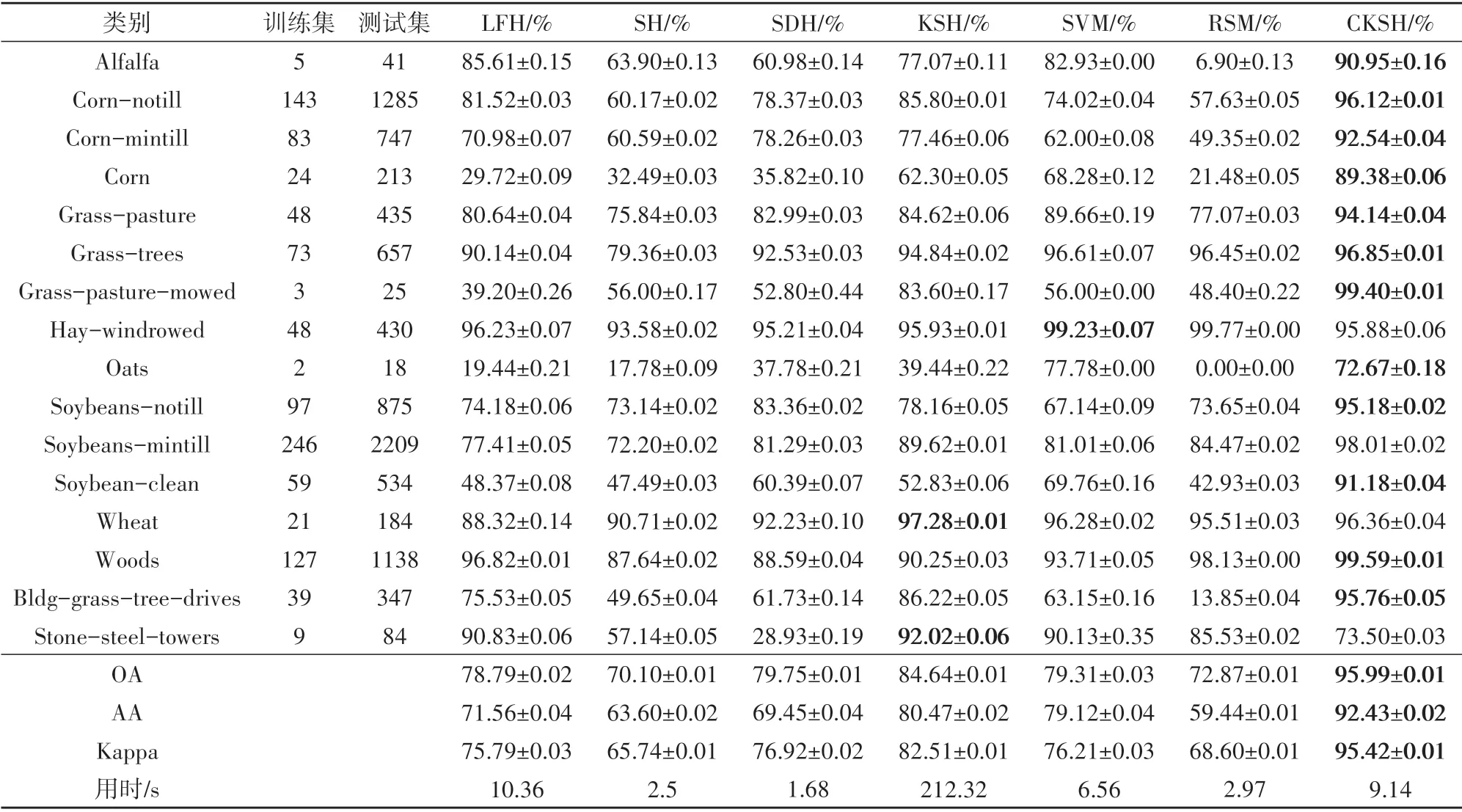
表3 不同方法对EMP的分类结果(Indian Pines)Table 3 Classification results obtained by different methods based on EMP features(Indian Pines)
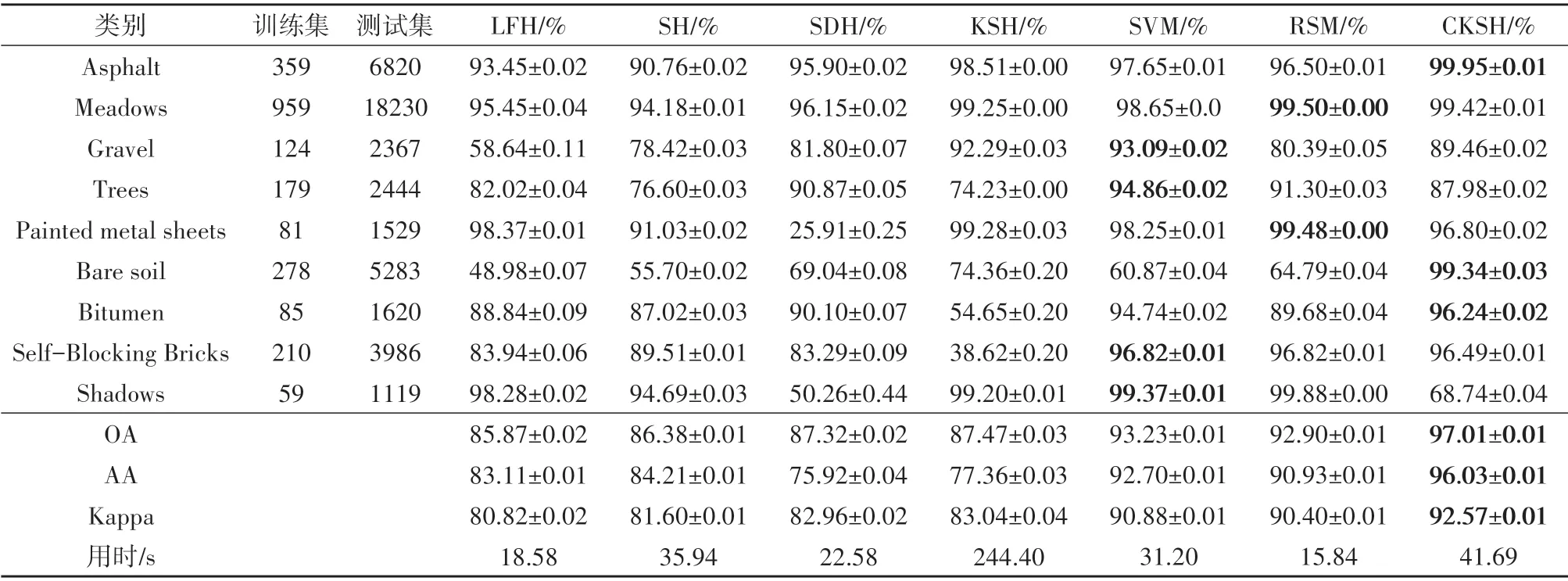
表4 不同方法对EMP特征的分类结果(University of Pavia)Table 4 Classification results obtained by different methods based on of EMP features(University of Pavia)
观察表3发现,CKSH 算法与传统方法用时相差不大;在分类精度方面,CKSH 在哈希字节长度为40时精度超过90%,如图9(c)所示。而SVM、RSM 这两种方法的最好分类精度均在80%左右;CKSH 算法可以实现迅速降维。以上实验验证了CKSH相比于传统分类方法具有显著的优越性。
3.7 不同分类后滤波处理方法的对比
为对比不同分类后处理方法的性能,表5—表6给出了不同分类后滤波方法对EMAP特征的分类结果。采用的滤波方法包括多数分析法(majority)和形态学分析法,其中形态学分析法包括膨胀(dilate)、腐蚀(erode)、开运算(open)、闭运算(close)。多数分析法的变换核大小设置为3×3,中心像元的权重设置为3;形态学的膨胀和腐蚀属性设置为disk,大小设置为3;开运算和闭运算的属性设置为square,大小设置为3。从图14和图15中可以发现,在所有分类后滤波方法中,close、open 和majority 滤波方法能明显消除噪声斑点现象,但对位于边缘处的误分像元无法有效消除;dilate和erode的总体分类结果表现较差。表6—表7显示基于close滤波结果最佳。
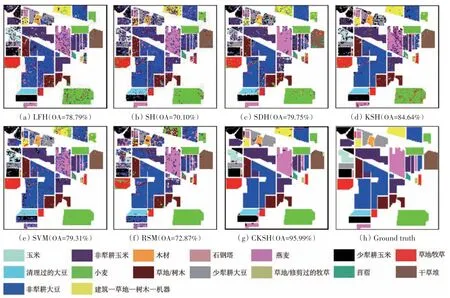
图12 利用不同方法对EMP特征的分类图(Indian Pines)Fig.12 Classification maps obtained by different methods based on EMP features(Indian Pines)
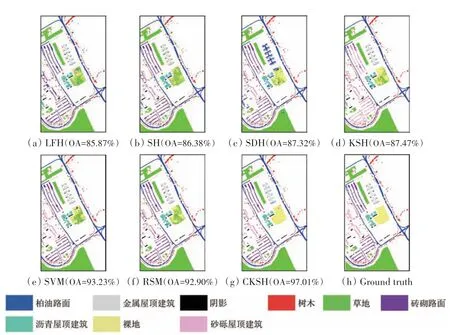
图13 不同方法对EMP特征的分类图(University of Pavia)Fig.13 Classification maps obtained by different methods based on of EMP features(University of Pavia)

表5 不同分类后滤波方法对EMAP特征的分类结果(Indian Pines)Table 5 Classification results after different filtering methods based on EMAP features(Indian Pines)/%

表6 不同分类后滤波方法对EMAP特征的分类结果(University of Pavia)Table 6 Classification results after different filtering methods based on EMAP features(University of Pavia)/%

图14 不同分类后滤波方法对EMAP特征的分类图(Indian Pines)Fig.14 Classification maps after different filtering methods based on EMAP features(Indian Pines)
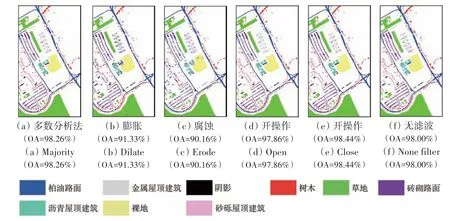
图15 不同分类后滤波方法对EMAP特征的分类图(University of Pavia)Fig.15 Classification maps after different filtering methods based on EMAP features(University of Pavia)
3.8 不同样本条件下的泛化性分析
为验证CKSH算法在不同样本条件下的泛化性,图16绘制了两组数据在不同样本量下的分类结果,横坐标为样本量的大小,以百分比为单位;纵坐标为总体分类精度。从两幅图中可以看出本文提出的方法在绝大多数情况下均取得了最高的分类精度。对于Indian Pines数据,当样本量≥2%时,CKSH算法得到的分类精度始终保持最高;对于University of Pavia数据,在不同样本量的情况下,CKSH算法的分类精度均最高。此外,除了LSH方法,其他方法分类精度均随着样本量的增加而提高,而LSH算法随机生成哈希函数,故不受样本量的影响。
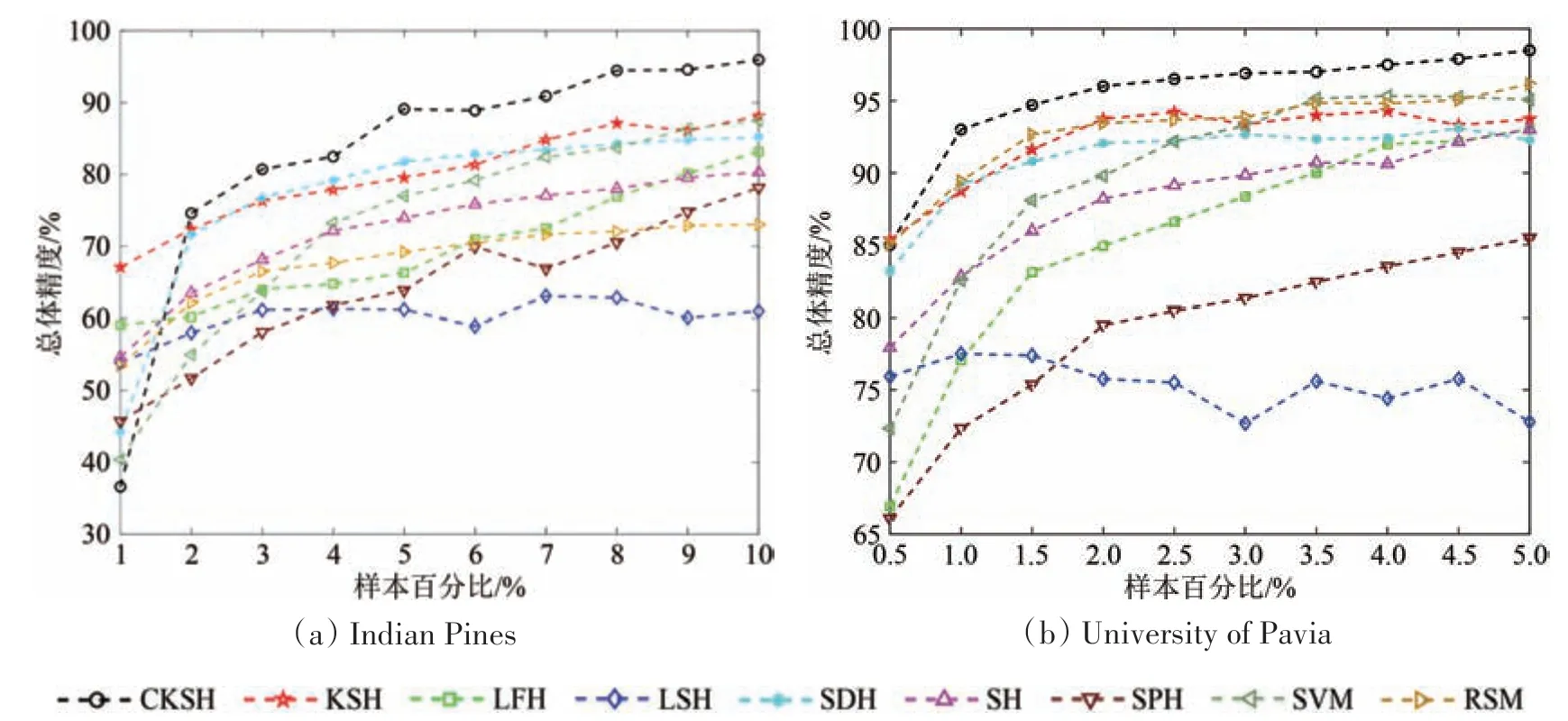
图16 不同训练样本对分类结果的影响Fig.16 The influence of different training samples on classification results
4 结 论
针对核哈希(KSH)的损失函数使用l2范数导致运行速度慢和未考虑空间信息的不足,本文在核哈希基础上利用四维卷积引入空间信息,同时使用RBF 核代替L2 范数作为损失函数,提出了基于卷积核哈希学习(CKSH)的高光谱图像分类方法。在两组国际通用测试数据集上的实验证实了CKSH方法在分类精度和运行时间两个方面表现出的优越性。一方面,由于CKSH 使用四维卷积操作,能够充分挖掘深层结构信息,获得的哈希编码更具有判别力,有利于提升算法的分类性能;另一方面,使用RBF 核作为损失函数可以明显缩短运行时间。然而,CKSH 算法使用固定大小的窗口和卷积核来提取空间信息存在一定缺陷,特别是当待分类像元位于不同类别交界处时,会混入异类像元,影响分类结果。因此,未来研究将在CKSH 算法基础上进一步考虑自适应的空间信息引入方法。
