地形校正对U-Net深度神经网络分类器分类精度的影响
2022-05-12贾莉郑柯唐娉霍连志
贾莉,郑柯,唐娉,霍连志
1.中国科学院空天信息创新研究院,北京 100094;
2.中国科学院大学电子电气与通信工程学院,北京 100049
1 引 言
遥感影像在国土资源监测、森林资源调查等多个领域得到了广泛应用。为了把遥感影像转换为专题类别信息,普遍使用遥感影像分类技术(唐娉等,2016)。尽管传统遥感影像分类技术取得了巨大进步,但仍有很多因素限制着其进一步发展(贾坤等,2011)。在众多制约因素中,由地形起伏引起的地形效应是其中一种外部因素。不规则的地形起伏造成地表同种地物辐射亮度不一致,进而导致地表反射率有所差异,在影像上表现出阴坡暗,阳坡亮的现象。这种因地表坡度与坡向变异引起的辐射畸变会扰乱地物光谱信息,给影像分类带来一定误差,使得基于影像光谱信息的土地覆被分类难以达到较高精度(何超等,2014)。
为进一步提高遥感影像分类精度,国内外学者基于DEM 数据建立了SCS (Gu 和Gillespie,1998)、SCS+C(Soenen 等,2005)、VECA(Gao和Zhang,2007)等多种地形辐射校正模型来消除地形效应(姜亢等,2014),并初步评估了不同地形校正模型对地表覆盖分类的影响情况(陈趁新等,2014)。已有的研究表明在最大似然、决策树、支持向量机等传统影像分类法中加入地形校正这一预处理过程,一定程度上会恢复模糊的地表信息,大大提高地表地物特征的表达与解译(Brown 等,1998;Li 等,2013;Pimple 等,2017;邓禹等,2018)。
近年来,深度学习技术被广泛用于图像分类领域(许慧敏,2018)。相比传统主要基于影像光谱信息的统计分类方法,计算机模拟自学习的深度神经网络分类模型能有效地将轮廓、颜色等底层特征抽象成高层易分类特征;并学习提取复杂的本质特征、融合多种影像特征信息,从而降低分类不确定性,增强分类效果,成为图像深度特征提取的有力工具(马亚飞等,2018)。在图像分析领域,卷积神经网络CNN 表现出独特的优势,获得了巨大的成功(李彦冬等,2016)。而全卷积网络FCN 进一步将图像级分类延伸到像素级分类(Shelhamer 等,2017),其中基于FCN 架构的语义分割模型U-Net在医学图像分析领域获得了较好的分析效果(Ronneberger 等,2015),也逐渐在遥感影像分类研究中取得了较高的分类精度(Maggiori等,2016)。且有研究表明,在非100%精度的样本标记前提下,使用深度神经网络分类器对遥感影像进行分类,仍然能获得较好的分类结果(Isikdogan等,2017;Liu和Chen,2018)。
既然已有研究证明针对浅层传统分类器,地形校正能提高影像分类精度(Pimple 等,2017),自然引发这样的思考:针对U-Net等深度神经网络分类器,地形校正能否达到同样的效果?或者说针对深度神经网络分类器,地形校正是否必要?本文以Landsat 8 遥感卫星影像和30 m 分辨率的ASTER GDEM_V2地形数据为例,结合国家基础地理信息中心制作的GlobeLand30 地表覆盖分类产品(Chen 等,2015)和清华大学研制的全国森林分类结果(Li 等,2014),用U-Net 语义分割网络对实验区进行地表覆盖分类研究,并重点对比分析了不同训练集获取方式及不同精细程度分类体系下遥感影像地形校正前后分类精度的差异情况。
2 研究实验区和数据源
2.1 实验区概况
实验区位于陕西、山西、河南3省交界处,涵盖3 省10 余个县,中心坐标为34°15'18.39"N,110°13'21.61"E,落于陕西省洛南县境内。实验区地处秦岭东段南麓,属于湿润性暖温带季风气候,最高海拔2655 m,最低海拔210 m;地势西高东低,黄河穿流而过。研究所选实验区见图1。
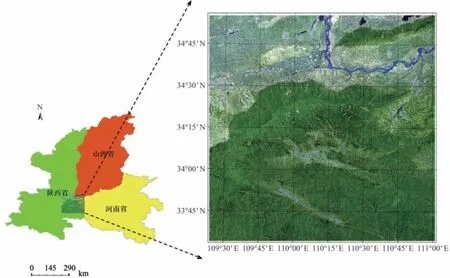
图1 实验区示意图Fig.1 The study area
通过对GlobeLand30 地表覆盖分类产品的读取,参照GlobeLand30-2010 的分类基准,即耕地、森林、草地、灌木地、湿地、水体、苔原、人造地表、裸地、冰川和永久积雪这十大地类(Chen等,2017),得到本研究实验区范围内涵盖的地物类别,包括耕地、森林、草地、湿地、水体以及人造地表6大类。其中森林面积最大,耕地次之,草地及湿地面积最少,地物种类齐全并且具有明显的地形效应。
2.2 数据源
研究中采用了Landsat 8 OLI 卫星影像、Globe⁃Land 30 分类产品、ASTER GDEM_V2 高程数据及全国30 m 森林分类产品这4 种数据源,数据详情见表1。

表1 实验数据源列表Table 1 List of experimental data
覆盖该实验区的Landsat 8 OLI影像是由相邻两景时相一致、无云的影像拼接裁剪而成,见图1,所选用的这两景影像详细信息见表2。
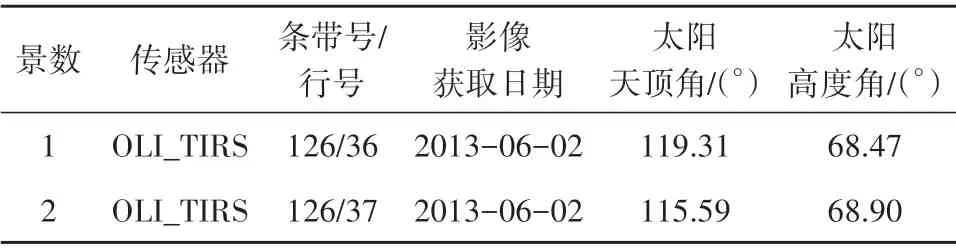
表2 实验区Landsat影像数据列表Table 2 Landsat image lists of study area
研究中首先使用USGS 官方发布的辐射校正算法LaSRC 对Landsat 8 卫星影像进行了辐射校正处理(Vermote 等,2016),获取可用于定量计算的地表反射率数据。此外,其他3种数据源均具有一定的可靠性:
(1)GlobeLand 30-2010 分类产品经第3 方抽样检验,得到83.50%的总体精度。其中,水体精度最高,其后是森林、人造地表、耕地、湿地、裸地、草地、永久积雪和冰川、灌木地(Chen 等,2017)。而本研究选择的实验区域中森林、人造地表及耕地占大多数,该数据产品在该实验区内的精度可以满足其作为样本标签数据使用的要求。
(2)ASTER GDEM_V2 地形数据根据NASA 新一代对地观测卫星TERRA 的观测结果,由ASTER传感器通过搜集130 万个立体像对数据制作完成,数据水平精度为30 m,高程精度为20 m,均达到95%的置信度,较SRTM3 DEM 和GTOPO 30 数据有明显的提高。实验选取的2 二版数据于2011-10 发布,相较于第一版在水域覆盖和偏差去除等方面有了进一步进展,数据质量得到了很大提高,可满足研究对地形数据的要求(康晓伟和冯钟葵等,2011;https//pubs.erusgs.gov/publication/70005960[2019-09-09])。
(3)全国30 m 森林分类产品经质量检验与分类评估,在中国范围内森林/非森林分类的生产者精度达到了92.0%,用户精度达到了95.7%(Li等,2014),数据产品具有一定的可靠性。
3 研究方法
本研究的总体方法为:首先针对本实验区从常用的地形校正方法中优选最佳的校正方法及其主要参数,对原始地表反射率影像进行地形校正;其次,根据地形条件特点对实验区进行训练及测试样本区的划分,并根据DEM 数据提取了研究区的坡向信息且进行了坡向分类;再次,把原始的地表反射率数据和经过地形校正的地表反射率数据分别用于U-Net 模型的训练,得到两组分类结果;最后,分别使用测试样本对不同组分类结果进行精度评价,研究技术流程见图2。
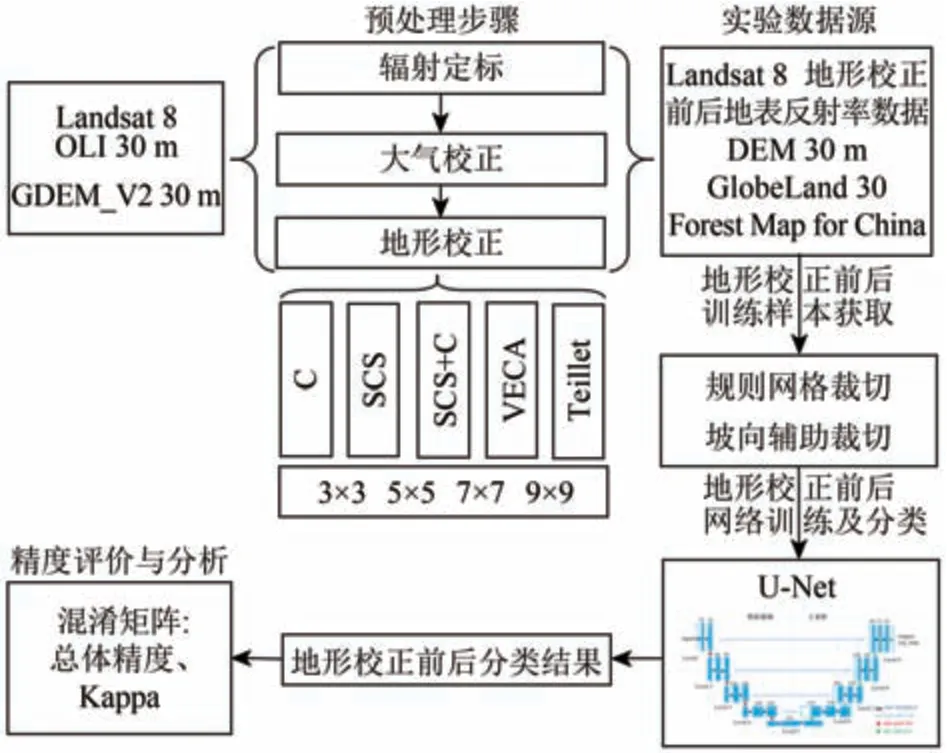
图2 研究技术流程图Fig.2 The flowchart of methods
3.1 地形校正处理
在实验区范围内选取部分区域,分别运用C、SCS、SCS+C、VECA 及Teillet 这5 种地形校正模型结合DEM 数据对地表反射率数据进行地形校正,校正效果见图3。

图3 5种地形校正模型校正效果对比图Fig.3 Comparison of correction effects of five topographic correction models
5 种校正结果中,C、SCS、SCS+C、VECA 模型均存在不同程度的过校正现象,本实验区域内Teillet 模型的校正效果较其他4 种好。接着从Teillet模型校正结果中选取方形区域(图中黑色方框所示)对该模型4种不同卷积核的适用性作进一步分析,结果见图4。

图4 Teillet模型4种卷积核校正效果对比图Fig.4 Comparison of correction effects for four convolution kernels of the Teillet model
4 种卷积核中3×3 大小的核校正效果最好。因为卷积核越大,通过DEM 计算得到的地形因子越平滑,较大的卷积核会使细小地物变模糊,影响校正效果。
为了确保校正结果的准确性与可靠性,根据地物光谱一致性,即不同地形条件下同一类地物目标在经过地形校正后应具有基本相同的反射率(Han等,2010)。以实验区部分区域为例,依据全国森林分类产品,提取该区域内落叶阔叶林这一种森林类型影像,再分别选取所提取影像中邻近阴阳坡上两块区域(图5),生成地形校正前后两区域植被均值光谱曲线及光谱差值曲线,以此来比较地形校正前后阴阳坡植被反射率的相似程度。通过对光谱一致性分析评价地形校正效果,地形校正前后光谱一致性曲线见图6和图7。
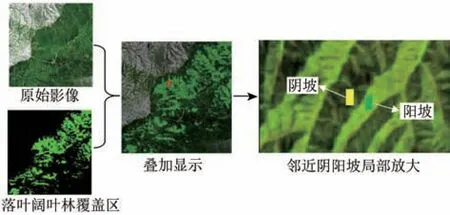
图5 落叶阔叶林覆盖区邻近阴阳坡选取示意图Fig.5 The nearby shady-slope and sunny-slope of the deciduous broadleaf area
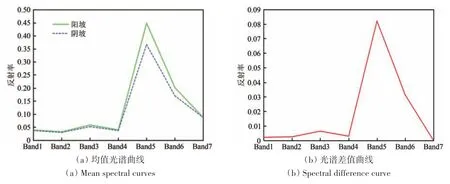
图6 地形校正前光谱一致性Fig.6 Spectral consistency before topographic correction
生成的两组植被光谱曲线中地形校正后阴阳坡光谱曲线形状趋于一致,光谱之差减小。即经Teillet模型校正后削弱了影像数据的地形效应,产生的地形校正数据有可靠性,可作为分类输入数据使用。因而在本研究的后续实验中,将采用Teillet校正模型、3×3卷积核做地形校正处理。
3.2 样本区划分
实验区被均分成同等大小的九块区域,见图8。选择6 块组合成训练样本区域,该区域涵盖6 大地表覆盖类型,具有代表性;其余3块组合成测试样本区域,该区域既有平坦地区,也有高低起伏的山地,且森林覆盖面积大小有异,可以很好地验证研究的合理性。

图8 训练、测试样本区划分Fig.8 Distribution of training data and test data
在后续的实验中,将通过从训练样本区域获取一定量的训练样本进行分类器模型的训练,并对3个测试区域分别进行分类与精度评价。
3.3 坡向分类
为了更好地分析地形校正对U-Net分类器分类精度的影响规律,探究不同的训练样本获取方式下地形校正对分类结果是否具有不同的影响,研究中加入坡向数据辅助分类(Álvarez 等,2018),基于阴阳坡及平地影像图获取训练集。首先利用ArcGIS 软件对实验区DEM 数据求取坡向,并参照国家森林资源连续清查技术规定进行坡向分类,将坡向分为阴坡,阳坡及平地3 类,具体情况见表3。
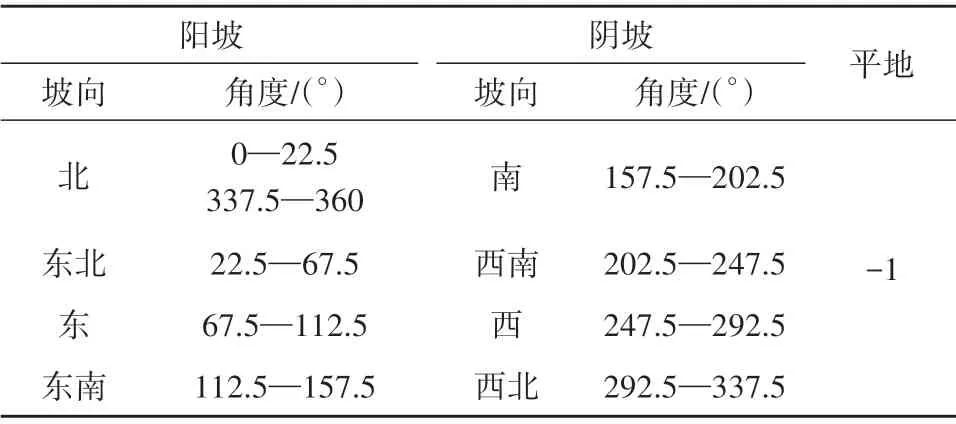
表3 坡向分类Table 3 Aspect classification
然后经波段运算分别提取阳坡、阴坡及平地这3类辅助影像,部分区域提取结果见图9。

图9 阴阳坡及平地提取结果叠加原始影像显示Fig.9 Shady-slope,sunny-slope and flat areas superimposed over the original image
3.4 训练样本获取
不同于传统的分类方法,U-Net模型需要输入一定大小的图像块且在每个图像块中逐像素地标记类别信息。研究中将该模型输入的图像块大小定为256×256,因而需要对训练样本区按照一定条件裁切出256×256大小的图像块,每个图像块将作为一个训练样本;此外,还需要对每个训练样本块中256×256个像素点逐一标注其类别。考虑到实验区Landsat 8获取时间为2013年,与GlobeLand30 2010年数据时间相近,且该实验区内地表覆盖变化较小,将直接从GlobeLand30 数据获取对应每个图像块中每个像素点的类别标记信息。在类别标记获取之前,需要进行重投影、重采样等操作,以保证不同数据集投影方式一致,分辨率及图像尺寸大小相同。
研究中选取了两种训练集获取方式。(1)坡向辅助裁切:根据提取的阴坡、阳坡、平地3个辅助影像对训练样本所在区域进行裁切,为了保持训练样本均衡,裁切样本总数为12000 个,阴坡、阳坡、平地均裁切4000 个;同时为避免阴阳坡训练样本的大量重复,选择更改训练样本的裁切步长得到更全面多样的样本数据;(2)规则网格裁切:训练样本总数为12000个,网络参数与前者保持一致。训练样本具体获取情况见表4。
3.5 U-Net模型
U-Net 是基于FCN 端到端的网络架构(Ronne⁃berger 等,2015),模型具有少样本学习的能力和较高的运算速率,在小数据集上可以训练得很好。该网络有9 层结构,左半部分卷积层结合4 个下采样层提取图像特征,右半部分4个上采样层拼接特征提取部分的输出获得准确分割,网络最后采用1×1卷积核映射出对应维数的特征图,得到精确的逐像素分类。研究所用U-Net网络结构见图10。
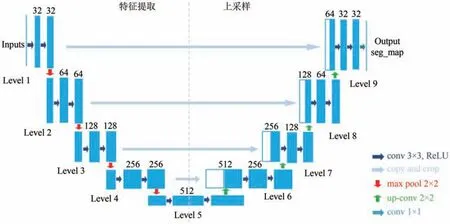
图10 研究所用U-Net网络结构图Fig.10 The framework of U-Net in our study
研究中模型训练输入图像大小为256×256,边界填充确保输入输出图像尺寸一致。将训练集中80%的样本做训练,20%的样本做验证,使用训练集中的全部样本训练150次,每次迭代训练的样本数目(即批量大小)为10,选择ReLU 函数作为分类器的激活函数,选择随机梯度下降算法作为分类器的优化方法,选择多分类交叉熵损失函数作为分类器的损失函数,选择正确率作为分类器的评估参数。实验基于Keras 框架实现,Python 语言编写,在Linux 操作系统上完成,系统配置4 个NVIDIA Titan XP GPU 显卡、32 核至强E5 CPU、128 GB内存及80 TB硬盘。
3.6 精度评估
为了定量评价分类效果同时保证精度验证样本点选取的均匀性,对每一幅测试影像,首先创建覆盖整个影像的1.32 km×1.32 km 规则网格,生成1444 个均匀的验证点;其次由解译专家以Landsat 8 影像为基础,并结合Google Earth 高分辨率影像进行真实类别标注;最后将真实类别与分类器分类结果进行对比,生成混淆矩阵,并从混淆矩阵中统计分类总体精度及Kappa系数。以一幅测试影像为例,精度验证样本点的分布及局部放大情况如图11所示。
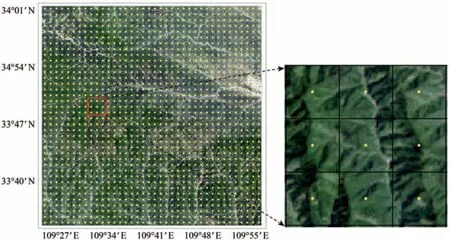
图11 精度验证样本点分布图Fig.11 Distribution map of sample points used for accuracy assessment
4 结果与讨论
4.1 分类及精度评价结果
对3 个测试样本区域影像,经U-Net 得到的分类结果如图13和图14所示,其中图13为规则网格裁切采样所得分类结果,图14 为坡向辅助裁切采样所得分类结果。为了增加对比性,原始地表反射率数据和地形校正后的地表反射率数据如图12所示。3个测试区域定量的分类精度见表5。
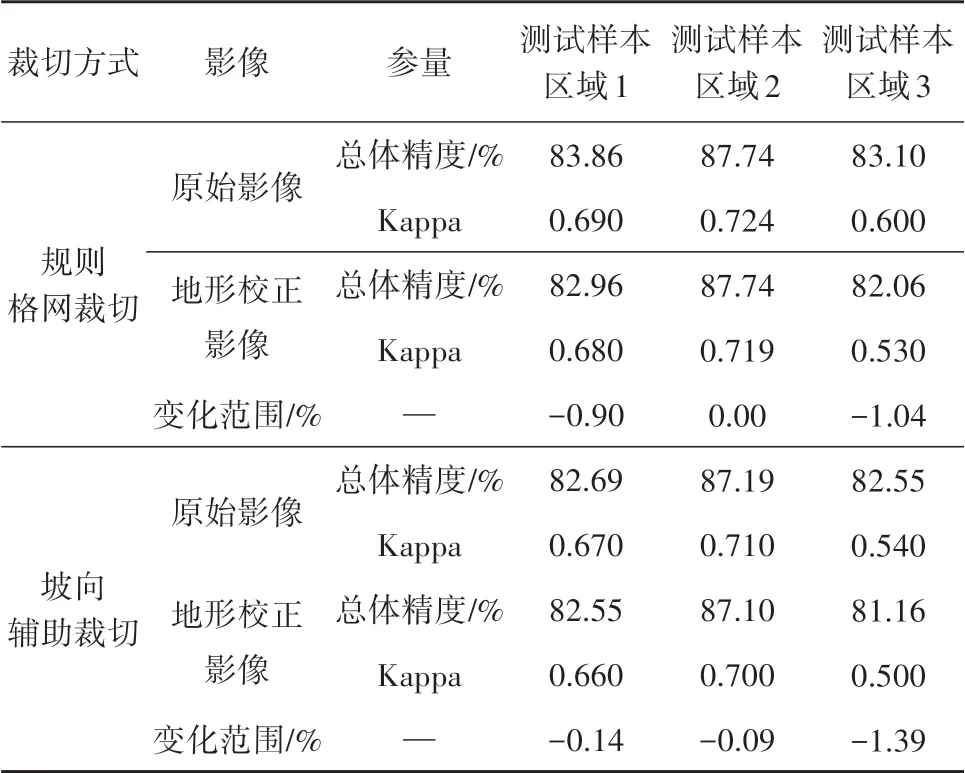
表5 分类精度统计表Table 5 Classification accuracy statistics

图12 测试样本区域1,2,3地形校正前后反射率影像图(7,6,4波段显示)Fig.12 Reflectivity image before and after topographic correction in test area1,2,3(R:7 G:6 B:4)

图13 规则网格裁切方式下测试样本区域1,2,3地形校正前后分类结果Fig.13 Classification results before and after topographic correction by grid clipping in test area 1,2,3

图14 坡向辅助裁切方式下测试样本区域1,2,3地形校正前后分类结果Fig.14 Classification results before and after topographic correction by aspect auxiliary clipping in test area 1,2,3
4.2 讨论
研究结合已有数据源及现有分类产品,通过U-Net 分类模型实现了对3 个测试区域的分类,得到表5定量的分类精度大小。从表5总结得到:
(1)3 组测试区域中,地形校正后影像的分类精度较未校正影像不变或有极小幅度的降低,降低范围在0.9—1.39。实验结果初步表明,对于30 m分辨率的Landsat 8 遥感影像数据,地形校正未能提高U-Net深度神经网络分类器的分类精度;
(2)规则网格裁切与坡向辅助裁切这两种不同的训练样本集获取方式下,地形校正前后的分类精度呈现出一致的变化规律,且规则网格构建训练样本的方式比按坡向辅助构建方式取得了更高的分类精度。原因在于利用阴阳坡及平地影像辅助裁切训练样本集时并不能将所有地类都采样,导致样本数据训练不充分,影响了测试集的分类精度;
(3)依据GlobeLand 30 分类产品的分类体系,在实验区内只区分了森林与其他5大地类,并未对森林这类地物进行更精细的类别划分。在经地形校正后确保阴阳坡辐射差异相对一致的情况下,森林类型单一可能会掩盖地形校正的作用,使得地形校正的效果在这种粗划分的分类体系中没有得到很好地体现。
因此,为了进一步探讨森林体系单一是否是导致以上分类结果的因素,选择3.2 节图8训练样本区3 作为新的实验区,该区域山地起伏尤为明显、高差较大、有大面积森林覆盖、地形校正效果突出,具有代表性(图15)。同时,选择2010年全国30 m 分辨率森林分类图作为样本标签。在该产品类别体系中,将森林划分为六大类:常绿阔叶林、落叶阔叶林、竹子、常绿针叶林、落叶针叶林及混交林。
图15 森林测试区域(训练样本区3)地形校正前后反射率影像图(7,6,4波段显示)Fig.15 Reflectivity image before and after topographic correction in forest test area(the training area 3)(R:7 G:6 B:4)
U-Net网络训练时,训练样本集用规则网格裁切的方式获取(见3.4 节),网络训练方式同3.5 节一致,精度评价方式同3.6 节一致。森林测试区域(训练样本区3)地形校正前后的分类结果见图16。
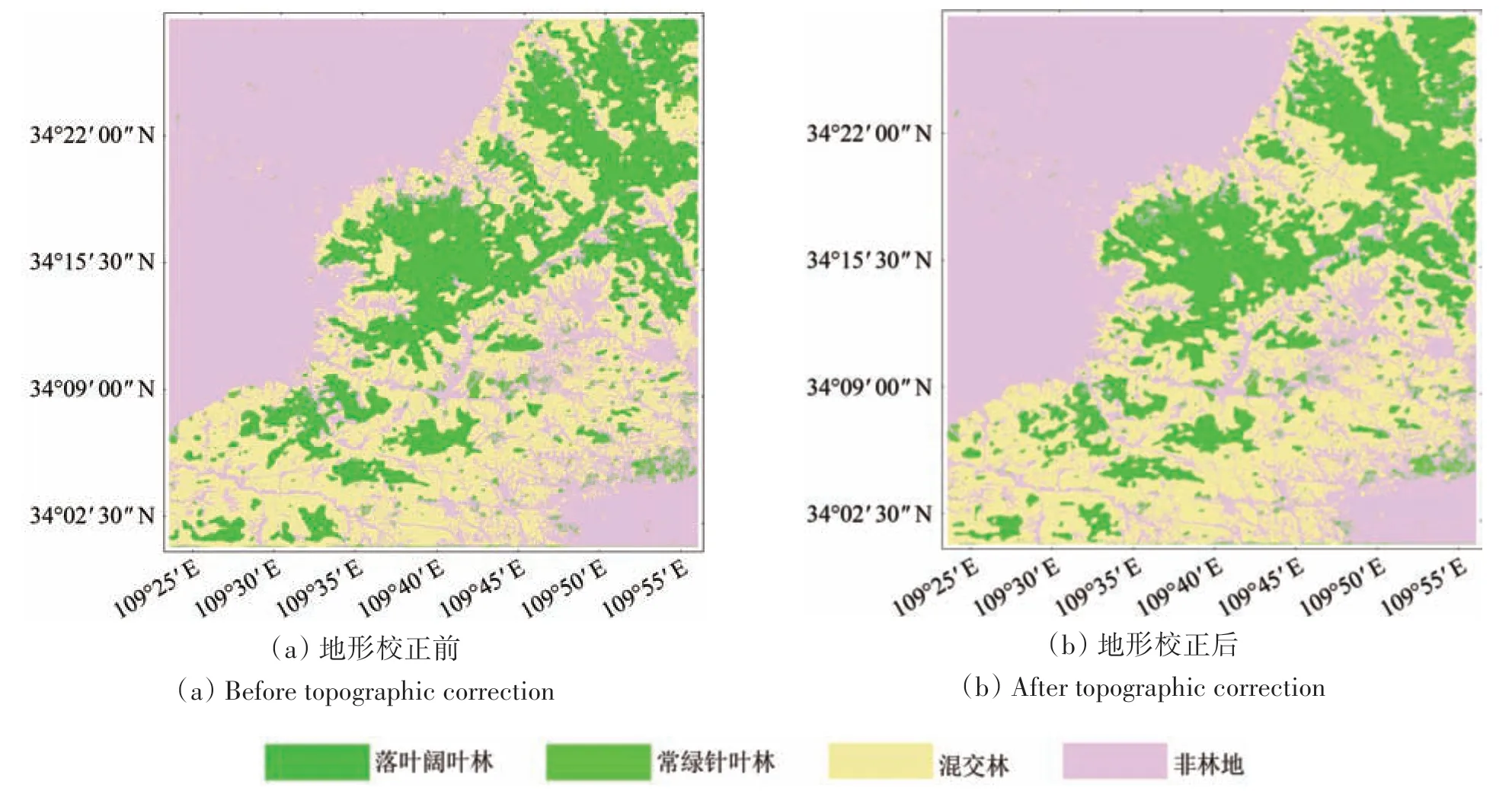
图16 森林测试区域(训练样本区3)地形校正前后分类结果Fig.16 Classification results before and after topographic correction in forest test area(the training area 3)
由分类结果可知该测试区主要的森林类型是落叶阔叶林、常绿针叶林及混交林3大类,落叶阔叶林和混交林居多,常绿针叶林较少。初步统计得到地形校正前后不同森林类型面积的大小变化,地形校正前落叶阔叶林、常绿针叶林、混交林面积占比分别是41.91%、2.60%、55.49%,校正后面积占比分别是39.80%、2.23%、57.97%。对比发现地形校正后3种森林类型面积均有变化,落叶阔叶林和常绿针叶林的面积减小,混交林面积增多。
针对上述测试区,定量的分类精度结果见表6。结果表明,在对森林这一地表类型进行更精细的类别划分下,地形校正后的分类精度较校正前下降了1.66%,这与上述讨论(1)得出的结论是一致的,地形校正并未提高U-Net深度神经网络分类器的分类精度。即森林体系划分单一并不是导致以上分类结果的因素,而是U-Net分类器自身所达到的分类结果。
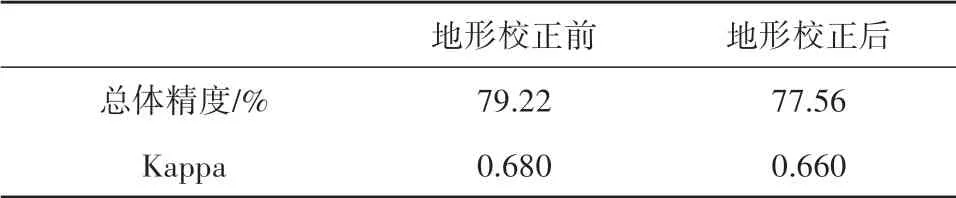
表6 森林分类精度统计表Table 6 Classification accuracy statistics in forest area
5 结 论
本文选择了深度神经网络模型U-Net,对Landsat 8 30 m 分辨率原始地表反射率数据及经过地形校正的反射率数据进行了分类提取,对比了规则网格裁切和坡向辅助裁切这两种训练样本构建方式下地形校正前后分类精度大小,并验证了不同精细程度的分类体系下地形校正前后分类精度的变化规律,并就不同情况下的分类结果进行了定量对比分析,得出以下结论:
(1)在实验区范围内利用U-Net深度神经网络分类器进行地表覆盖分类提取,在规则网格裁切和坡向辅助裁切这两种训练样本集采样方式下,地形校正均未能提高该深度神经网络分类器的分类精度。
(2)不同精细程度的分类体系下地形校正对U-Net分类器分类精度的影响规律是一致的。对森林地类精细的划分下地形校正仍然未提高U-Net分类器的分类精度。
(3)按照规则网格获取训练集较坡向辅助采样方式取得了更高的分类精度。规则网格下的采样能更好地涵盖所有地物类别,保证所构建的训练样本具备地物特征的完整性以及多样性。
本研究初步探索了地形校正在利用深度神经网络分类器U-Net进行地表覆盖分类时对分类精度的影响情况,旨在为简化深度神经网络分类器分类提取流程、提高遥感产品生产效率提供参考依据。本研究仍然存在着不足:首先,GlobeLand 30和全国森林分类产品较真实地表覆盖类型仍存在一定误差,后续会寻找更精细、准确的分类结果作为样本标签;其次,本研究中并没有考虑阴阳坡地表覆盖类型不同的情形;最后,本研究只针对U-Net这一种深度神经网络分类器展开,后续的研究中将尝试选择多种深度神经网络分类器,探究更精细尺度下不同深度神经网络模型在地形校正前后的分类精度变化情况,获取进一步的结论。
