基于出土文献数据库的集外字数字化处理方法研究
2022-05-11唐杰刘铭陈镱文
唐杰,刘铭,陈镱文
(西北大学 科学史高等研究院,陕西西安 710127)
自20世纪80年代始建“古汉语语料库”以来,经过30余年的积累,现已整理出数亿字的古籍数据库[1]。现有古籍语料库中含较多字符集以外的文字,即集外字。该类文字由于无法被OCR识别或通过键盘直接录入,在一定程度上影响了古籍的数字化及其转换与检索[2],因而成为古籍数字化的重点工作之一;又由于目前的集外字技术不能适用于计算机的自然语言信息处理技术,也成为古籍数字化中汉字处理难点之一。出土文献数据库是关于中国出土文献简、牍、帛书的封闭式数据库,如《简帛金石资料库(全文)》《引得市数据库》《汉代简牍数位典藏》《汉达文库》《瀚唐典籍》等[3],其中存在大量的避讳字、异体字、俗体字、生僻字,多以集外字为主。《瀚唐典籍》采用替换法将集外字认定为集内字,字库所用字符集编码为Unicode5.0字符集[4],《引得市数据库》采用造字法建立集外字字库,字库所用字符集编码为Unicode字符集编码,参考中央研究院汉字部件检索系统,利用部首结构来查询集外字[5]。香港理工大学开发的“中文古籍网上出版平台”采用描述法对集外字进行描述,字库所用字符集编码为Unicode编码[3]。目前,这些数据库对集外字的信息处理均集中在解决集外字录入、显示及检索功能,尚未关注集外字在文本信息处理中的应用。本文基于课题组建立的《中国出土文献数据库》中的集外字字库,提出出土文献集外字在文本信息处理中的程序化方法。该方法基于《汉典》网站及相关工具书对先秦至晋期间出土文献的集外字进行整理;使用造字法将所造集外字存储至Unicode编码私用区码位,建立集外字字库;结合四角号码检字方案生成输入法码表,借助多多输入法生成器生成集外字输入法。并以里耶秦简为例,探讨了分词工具对文本的处理效果。
1 特殊文本的集外字信息处理方法
少数民族文字、西夏文字、甲骨文字相关的数字化研究工作都是从20世纪下半叶开始的,在这之前,我国使用的是GB2312-80字符集,少数民族文字、西夏文字、甲骨文字都属于集外字。通过分析此类集外字的信息处理技术并借鉴其处理方法,可对出土文献的集外字处理提供帮助。
1.1 藏文字的信息处理
藏文由辅音字母、元音符号和标点符号构成[6],其同时包含横向拼写及纵向拼写,藏文是从20世纪90年代开始编码研究工作,1997年发布了《信息交换用藏文编码字符集》,该标准包含192个编码点、169个编码字符,是按照拼音文字编码规律对藏文进行编码[7]。藏文是通过使用造字法,在长宽不等的点阵中造字,字体有点阵字、矢量字、曲线轮廓字,将其保存为Unicode编码,Unicode编码范围为0F00~0FFF,其键盘输入法有字丁、音节和词组的形式,通过藏文输入法实现藏文自动排版,实现藏文的输入输出。目前藏文和其他少数民族文字已收录在CJK字符集中[8],已被规范为集内字,信息处理更加方便。
1.2 西夏文字的信息处理
西夏文是记录西夏党项族语言的文字,其文字特征类似于汉字,同为方块字。自20世纪后半叶,西夏文数字化研究逐渐展开,宁夏大学开发并研制出了《汉夏字处理及电子字典》,创立了西夏文字字符集[9]。景永时等[10]通过使西夏字与GB2312-80标准汉字共用同一编码,制作了西夏文字库,此方法在处理西夏文与汉字同框的文本时需不断切换字库。马希荣等[11]采用位面技术在GBK的用户自定义区分配西夏字编码,避免了与汉字或其他字符的码位冲突问题,但其本质上并没有解决西夏文字符编码问题,字库不便应用于文本信息处理。2016年6月发布的Unicode9.0版本收录了西夏文字符,使西夏文字规范为集内字,解决了占用汉字码位、夏汉同屏共存等问题,对于西夏文字库在文本信息处理方面的应用具有非常重要的作用[12]。著名西夏学研究专家李范文[13]根据西夏字结构编排了西夏字的四角号码,使得西夏字检索更加方便,为西夏文字数字信息化开辟了捷径。
1.3 甲骨文字的信息处理
甲骨文字形的特点是笔画繁多、无法区分、构造复杂[14]。自1990年开始就有专家关注甲骨文的信息化技术,徐松[15]开发了“甲骨文象形码编码系统”,可实现甲骨文笔画检索。江铭虎等[16]同时制作两套甲骨文字库,通过区位码和拼音形式输入甲骨文。顾绍通等[17]根据甲骨文字形的拓扑结构建立了甲骨文输入法,实现甲骨文的字形和拼音输入。刘志祥等[18]建立了字形编码型甲骨文6位数字码输入法,类似于汉字检索的四角号码,实现精确的甲骨文字的输入输出。刘永革等[19]通过对甲骨文的笔画特征进行分析,将构成甲骨字的笔画归纳为九种笔画,在此基础上采用香港中文大学的甲骨文字库设计了甲骨文笔画输入法。
2 字符集编码及集外字处理
2.1 字符集编码
字符集是遵循国家或国际标准,对每一个字符进行定义的唯一代码[20],常见的汉字字符集有GB2312,BIG5,GBK,GB18030,Unicode[21],其 中Unicode编码字符集是国际标准字符集,可实现跨语言文本信息转换[22]。
集外字是指字符集以外的字,不采用特定的技术方法无法对集外字进行录入、处理及显示[23],字符集的选择与集外字的数量呈负相关,故在建立字库时优先选择收录字符最多的Unicode字符集,其满足共享、国际通用的条件,同时也是目前古籍数字化项目最常用的字符集。
2.2 集外字处理方法
在古籍数字化项目中常见的集外字的处理方法大致分为造字法、替换法、描述法[24-25]。
造字法是在字符集的自定义区为集外字定义编码,这些编码与集外字的字形一一对应。优点是只要有字符集自定义编码区的支持,造字的检索与显示和集内字完全相同,缺点是自定义编码区只有13万余个码位[26],如果不加限制地造字,码位很快会消耗殆尽,且不同的古籍数字化项目对私用区码位的使用可能完全不同,若同时使用这些古籍数字化项目,可能发生私用区编码冲突。
替换法是将集外字变换为其他可以输入的形式,如符号、图形和集内字。此方式的优点在于录入方便简洁,但是缺点也很明显。第一,集外字统一替换为某个符号,这些符号基本没有检索意义。第二,替换符号未能保留集外字的任何信息,当字符集变更时,集外字无法管理。第三,在不清楚替换规则的情况下,用户无法理解替换的意义。
描述法是将集外字表示为一个字符串,这个字符串描述了集外字的字形。优点是可使用标准化的描述符序列对汉字的构造进行说明,解决了自然语言描述法的不规范问题。缺点是很多生僻字结构极为复杂,拆解困难,一种字存在多种描述方法,且描述后的字不是一个Unicode编码,而是一组编码,例如字,需要十三个编码才可完整描述此字[23],其缺点有:占字节较多、不利于文本信息处理、需额外软件支持、所造字形与原字符存在一定差距。
相对而言,造字法是建立出土文献数据库的较好选择。第一,出土文献语料库是封闭式语料,其字数有限且相对于传世文献与自然语言而言较少,据目前统计的已释读的出土文献数据,集外字有2万余个。第二,造字法可将所造集外字保存为Unicode字符集编码,将集外字转为集内字,目前Unicode供用户自定义编码的码位有137 468个码位,可自由编辑137 468个集外字。第三,计算机的文本信息处理是识别文字所对应的字符集编码,要求集外字“一字一形一码”。造字法满足以上三种限制条件,故本文选择造字法建立出土文献集外字字库。
3 出土文献集外字输入法方案及实现
3.1 出土文献的集外字整理
计算机的应用范围越来越广泛,对汉字进行数字化已经成为了中文信息处理的必要前提。出土文献中包含大量的俗体字、异体字等,其中不乏集外字,给研究者合理规范使用文字带来了诸多不便。因此,建立出土文献数据库的必要工作就是对出土文献的集外字进行整理,但古籍版本众多,且没有非常严格的统一标准,故应选择专业的文物校释小组和权威作者所著的释文进行数字化和整理工作。基于《说文解字》《康熙字典》此类工具书及《汉典》网站,筛选查找《清华大学藏战国竹简》《望山楚简》《天水放马滩秦简》《里耶秦简牍》(壹与贰)《张家山汉简》《悬泉汉简》等先秦至晋的出土文献中的集外字。
以里耶秦简集外字整理工作为例,出土文献释文书籍选择湖南省文物考古研究所编著的《里耶秦简牍》,其释文一般按照原文字形释写,不识字是按照原样摹写。工具书选择陈伟主编的《里耶秦简牍校释》。在里耶秦简两卷的集外字整理过程中,对例如9-475中的字“”“”,此字是按照原样摹写的字,将其认定为集外字进行收录;例如9-478中的字“”,此字是“ ”下侧无法识别,所以对其不进行收录;对文本中的符号例如“”“”,不进行收录;例如8-181中的“”字,在汉典网中未收录此字,此字也不存在于Unicode字符集中,所以将其收录为集外字。根据整理已出版的两卷《里耶秦简牍》中的集外字,其在全文不重复字数的比重约为11.2%,其中集外字个数202个,两卷不重复字数约1 800个。
3.2 出土文献集外字字库的建立
根据现筛选查找到的出土文献集外字,在现有的藏文字库、西夏文字库及甲骨文字库建立方法的基础上构造出土文献集外字字库。该工作主要分为两步:第一步,采用造字法描绘集外字,将集外字描绘成汉字字符形式。藏文、西夏文及甲骨文对其文字采用了“造字法”,即利用造字软件采用描绘的形式将文字描绘在画板上。鉴于此,本文也根据造字法利用计算机描绘出土文献集外字,使得出土文献集外字成为“汉字”形式。第二步,由于藏文、西夏文及甲骨文在建立字库时,是将描绘好的字符以Unicode字符集编码的形式储存至计算机中,故本文也通过参考该方法,将所描绘的集外字存储至Unicode编码私用区码位。由此,基于以上两项工作建立起出土文献集外字字库。具体的操作步骤如下。
利用High-Logic公司的FontCreator曲线轮廓造字软件,根据二次β样条曲线拟合算法,自动将扫描的集外字图形数字拟合成尽可能接近原样摹写的集外字,可通过调整文字的轮廓点、线、角度及位置,描绘出较为理想的集外字并保存在对应的Unicode编码私用区码位。
现有较常用的出土文献集外字字库有“引得市古文字缺字资料库”“古联瀚字输入法字库”,但是建立出土文献集外字字库无法直接采用其结果,原因有二:其一,不能包含先秦至晋期间所有出土文献中的集外字。其二,无法对其字库进行动态管理。本文所建立的集外字字库优势在于:第一,集外字数据更全面,可研究范围及角度更广,对每篇出土文献中的集外字进行整理并梳理成表。第二,对字库实现动态管理,根据出土文献的更新和Unicode字符集的更新,对字库中的字进行增加或删改。
3.3 生成集外字输入法
在西夏文字库的建立及夏汉通输入法生成过程中,西夏文字存在拼音难以读写且结构复杂的特点,由于其是仿造汉字而创制的,即以偏旁部首组成方块字,因此研究者利用此特点建立了西夏文四角号码检字法,对所有文字进行四角号码检字编码,生成了西夏文输入法码表。现有的检字方案可分音码、形码两种[27],四角号码检字法属于根据文字字形查找文字的形码检字方案,是用最多不超过5位的阿拉伯数字将所有汉字进行归类,此检字方案对于无法正确读写拼音及结构部首繁琐的文字效率极高,可在计算机中高效率录入此类文字。而出土文献集外字也存在与西夏文字类似的特点,故也可采用四角号码对其检字。出土文献集外字的检字码由5位阿拉伯数字组成,遵循《四角号码新词典》第十版的规则,对集外字进行编码拆分取号码顺序为左上角,右上角,左下角,右下角,附加码为左下角上方距离最近的笔形对应号码,例如:
本文首先利用四角号码检字法对字符编码,进而建立出土文献集外字的输入法码表,在输入法码表中需将“0123456789”用其拼音声母首字母“oyesxwlqbj”代替[28]。其次,按步骤将整理好的输入法码表文件导入多多输入法生成器中并设置相关参数,生成“出土文献集外字输入法”。图1为出土文献集外字输入法的构造流程图。
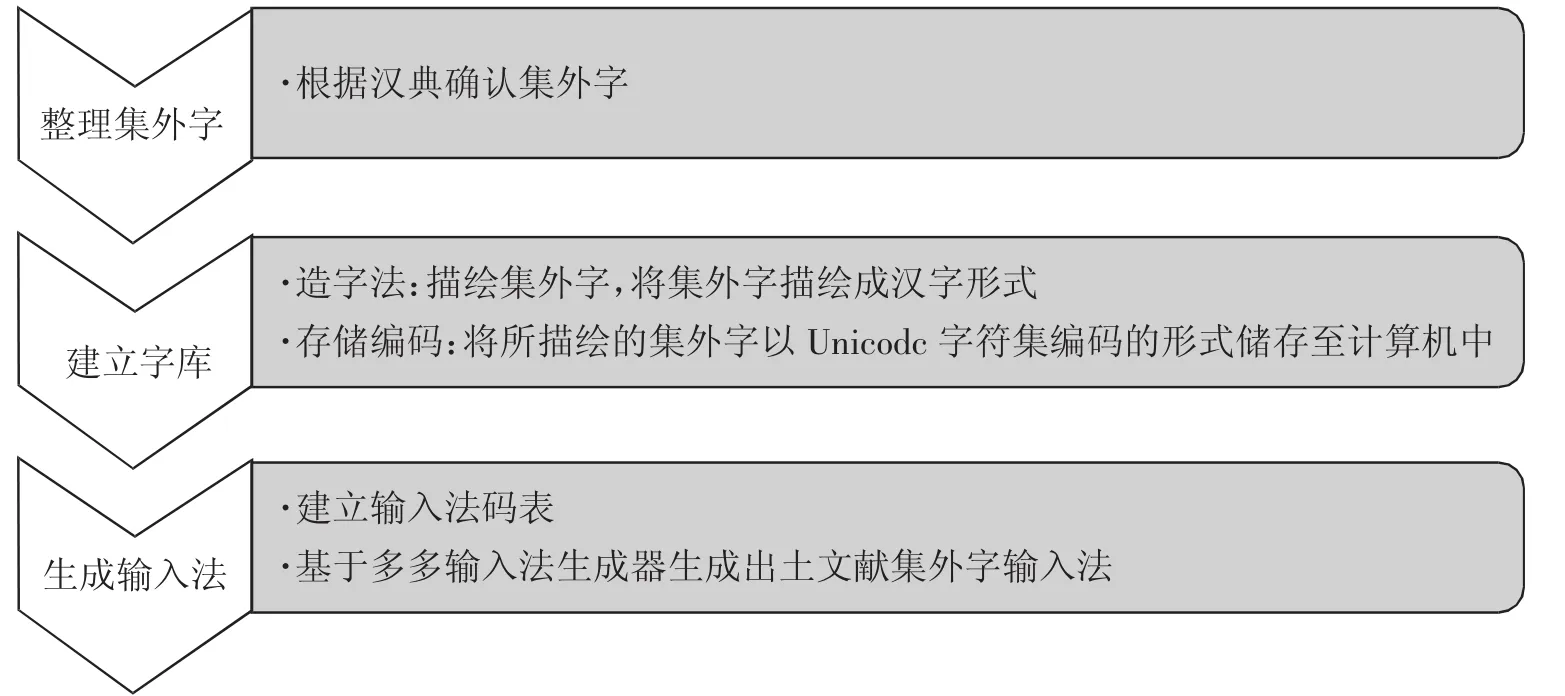
图1 出土文献集外字输入法构造
4 集外字文本分词试验
里耶秦简于2002年在里耶古城一号井第一次出土,计三万八千余枚简牍;及于2005年在护城壕第十一号坑第二次出土,计五十一枚简牍。简牍起止时间为秦始皇二十五年(前222年)至秦二世二年(前208年),内容为秦朝洞庭郡迁陵县遗留的公文档案,涵盖了当时社会的各个层面[29]。目前已出版《里耶秦简牍》第一卷和第二卷,两卷共包含四层,共含6 050条简,总字数约为12.25万字。本文在小组建立里耶秦简数据库的基础上,建立集外字字库,并应用于里耶秦简语料库的建设中。
中文分词是文本分类、信息检索、文本挖掘等中文信息处理工作中的难点和技术关键点,为验证所建字库及输入法可使集外字参与到文本信息处理过程中,本文将所造集外字录入语料库,以里耶秦简两卷文本数据库为例,测试集外字可参与到主流分词工具的分词过程。
试验选择目前自然语言分词的主流工具jieba[30]。jieba分词工具本身内含词典,该词典的主要内容是现代汉语及部分古代汉语,但也可根据用户需求选择是否添加自定义词典,以此保证分词的准确率。由于简牍语言以单字词居多及与现代汉语实体名词有较大区别的语言特殊性,故在分词时采取两种方案,以验证集外字字库及输入法建立的必要性。
试验数据选择里耶秦简第一卷的简8-458,简文中包含集外字“”:
遷陵庫真□
鞮瞀卅九(第一欄)
冑廿□
弩二百五十一
臂九十七
弦千八百一(第二欄)
矢四萬九百□
戟二百五十(第三欄)
试验分为两个方案:方案一,基于jieba分词工具的默认精确切分模式下,不添加用户自定义词典进行分词。方案二,添加自定义的包含集外字的分词词典进行分词。试验结果如表1。

表1 集外字文本分词试验
从表1可见,第一,根据分词结果,用jieba分词工具对含有集外字的文本直接进行分词时,集外字“”参与了分词。这说明了“甲”虽然包含集外字,但由于集外字字库及输入法的建立,这类集外字可参与至计算机对语言的信息处理工作中,最终使得集外字可被读取、被处理、被写入。
第四,方案一与方案二的分词结果略有出入,主要问题还是在jieba分词工具的内含词典主要是现代汉语,对于简牍这类特殊语言,其词库及数据库的建设还未完备,故分词的准确率较低。
5 结论
本文根据《中国出土文献数据库》的集外字字库提出了文本信息处理程序化方法,在实现集外字的数据库中显示和检索功能的基础上,为出土文献中集外字参与文本信息处理提供了可行性方案。
本文以里耶秦简为例,采用造字法将集外字转换为计算机可识别的编码并参与文本信息处理,并建立了出土文献集外字字库,提高了数据库的完整性。其次,结合四角号码,基于多多输入法生成器生成集外字输入法,并以自然语言处理技术中的基础任务——分词为例,利用已处理的文本数据进行切分,达到了较好的处理效果。
在数字人文背景下,本文利用该方法将适用于现代汉语与传世文献文本的信息处理技术泛化至出土文献文本中,不仅可直接应用于建立出土文献集外字字库及文本数据库,且为集外字参与古籍文本的计算机处理技术提供新方法。
