M型变速箱总成密封质量预测方法研究
2022-05-10周康渠张朝武唐蔗湛
周康渠,张朝武,屈 清,唐蔗湛
(1.重庆理工大学 机械工程学院,重庆 400054;2.庆铃汽车股份有限公司,重庆 400052)
变速箱是汽车传动系统的重要组成部分,起到降速增扭,利用倒挡改变车辆行驶方向的作用。密封性作为变速箱总成的关键质量特性,直接影响变速箱总成的质量。如果变速箱总成密封质量不合格就会导致变速箱“泄漏”,如渗油等,严重影响变速箱工况及驾乘安全[1]。在变速箱多工序装配过程中,零部件之间的连接、密封不严等会使得变速箱泄漏值超过规定要求,导致密封质量不合格。通过变速箱相关装配工艺参数对变速箱总成密封质量进行预测,做好事前控制,对提高变速箱一次性密封质量合格率有重要作用。
在装配质量的预测研究中,You等[2]通过建立3D Solid Works实际尺寸模型,使用有限元分析方法预测了精密压装配合的压装质量。Wong等[3]通过构建RVM预测模型,对柴油发动机制动比进行预测,比人工神经网络的预测精度高。Abellan-Nebot等[4]通过建立状态空间方程,实现多工序装配过程的产品质量预测。张根保等[5]使用PSO-BP神经网络预测模型,结合灰熵关联分析,预测某外圆磨床砂轮架的装配质量。刘明周等[6]使用PSO-LS-SVM模型预测曲轴的回转力矩。万方华等[7]使用KPLS模型对滚动轴承装配质量进行预测。贾振元等[8]使用灰关联分析提取关键装配要素,应用BP神经网络模型预测液压偶件系统的装配质量。赵明志[9]使用PSO-BP算法模型对某双联齿轮变速箱试漏量进行预测。以上研究为本文建立的变速箱总成密封质量预测方法提供了重要的理论指导。
本文结合变速箱多工序装配的特点,首先分析影响变速箱总成泄漏值的装配工艺参数,然后通过灰关联分析筛选出影响总成泄漏值的关键装配工艺参数,建立基于遗传算法GA的BP神经网络预测模型,实现对M型变速箱总成泄漏值的预测,并对几种预测模型的预测结果与实际值进行比较。
1 变速箱总成密封质量影响因素分析
M型变速箱由200多个零部件所构成。由若干主线工序、分线工序及测试工序完成装配和测试。M型变速箱示意如图1所示。

图1 变速箱示意图Figure 1 The picture of gearbox
通过分析M型变速箱的装配工艺,变速箱总成密封质量的主要影响因素包括零部件的清洁度、变速箱壳体和离合器壳体等结合面的涂胶直径、垫片油封的压装深度、离合器壳体和变速箱壳体及后盖等主连接螺栓拧紧力矩等装配工艺参数。变速箱主要接合面示意如图2所示。
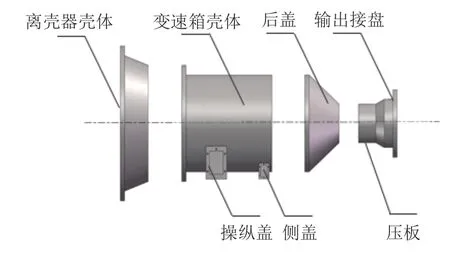
图2 变速箱接合面示意图Figure 2 Schematic diagram of gearbox joint surface
变速箱密封质量常用泄漏值来衡量。根据M型变速箱装配工艺以及变速箱结合面的分析,影响装配总成泄漏值Y0的装配工艺参数有12个,如表1所示。
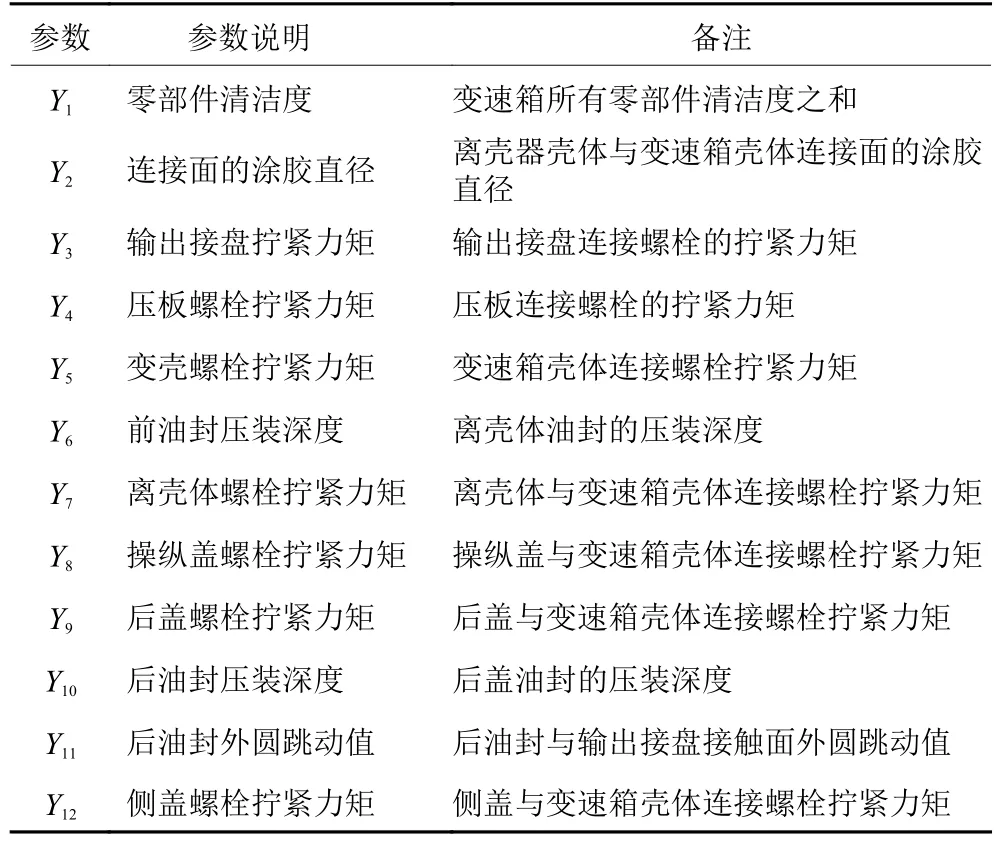
表1 装配工艺参数明细表Table 1 List of assembly process parameters
2 确定关键装配工艺参数
由变速箱总成密封质量影响因素可知,12种装配工艺参数可以影响变速箱总成的密封质量。如果将这12种装配工艺参数直接应用于BP神经网络学习训练,就会导致预测模型复杂化,预测结果难以满足精度要求,甚至预测结果不收敛。本文使用灰关联分析法来分析各个装配工艺参数关系的强弱,筛选出影响变速箱总成密封质量的关键装配工艺参数,以简化BP神经网络预测模型,得到更精确的预测结果。
1) 首先采集M型变速箱装配线上的原始装配数据,部分原始样本数据如表2所示。

表2 M型变速箱原始装配数据集Table 2 M-type gearbox original assembly data set
2) 无量纲化处理样本数据。
由于上述12个装配工艺参数具有不同的量纲和数据级,如果将原始装配数据直接用于灰关联度分析,就会导致大数据序列覆盖小数据序列,难以保证各个装配工艺参数的等效性。可以使用初值化、均值化和极值化3种方法对原始数据进行无量纲化处理,同时避免单种方法处理数据的片面性[10]。部分数据处理结果如表3所示。表3中数据使用均值化方法对原始数据无量纲化处理。其中,
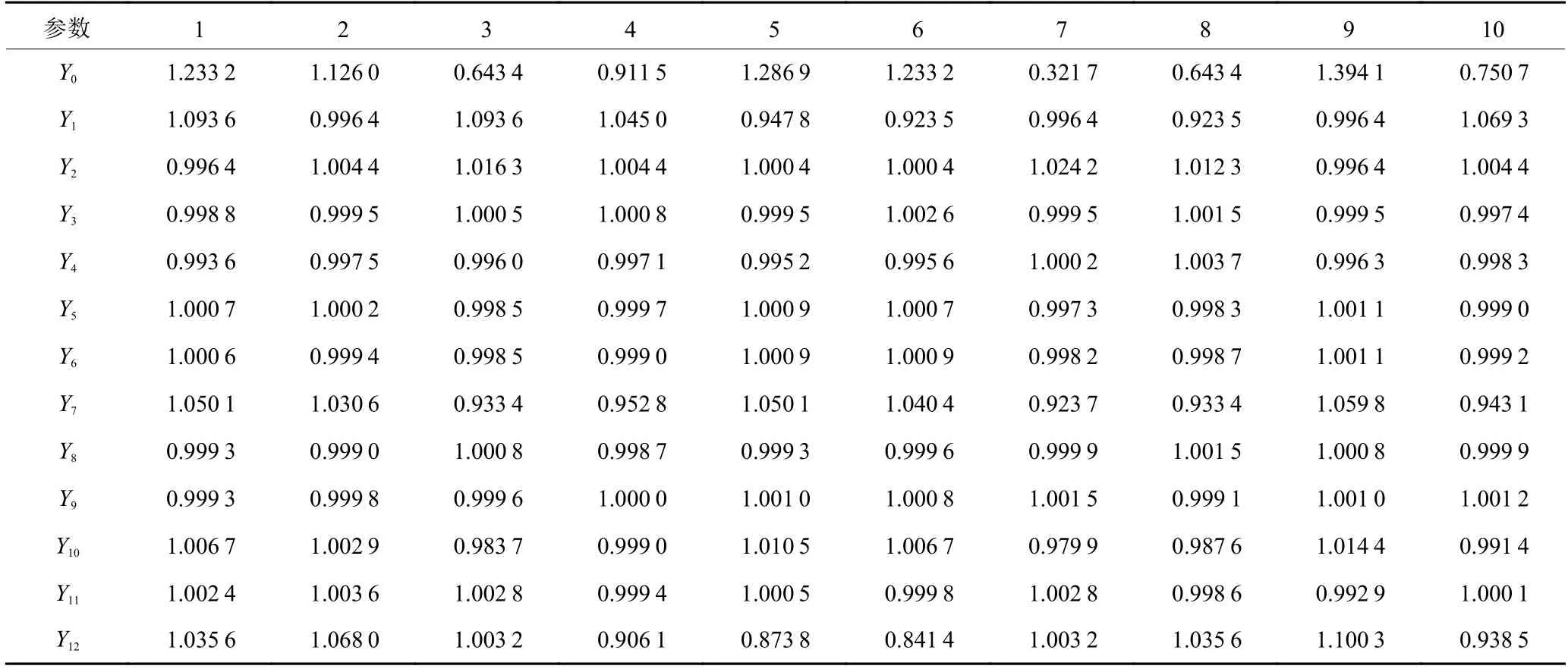
表3 部分样本数据无量纲化结果Table 3 Part of the sample data non-dimensionalization result table
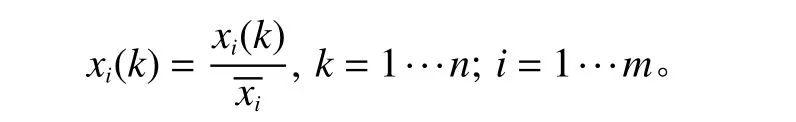
3) 计算各个装配工艺参数的灰关联度。
将X0=[x0(1),x0(2),···,x0(n)]设为参考数列,具体到表3表示泄露值,即x0(1),x0(2),···,x0(n),其中n=10,即x0(1),x0(2),···,x0(n)的10个数据分别为1.233 2,1.126 0,0.643 4,0.911 5,1.286 9,1.233 2,0.643 4,1.394 1,0.750 7。Xi=[xi(1),xi(2),···,xi(n)]设为比较数列,具体到表3表示零件清洁度等参数,如x1(1),x1(2),···,x1(10)的数据分别为1.093 6,0.996 4,1.093 6,1.045 0,0.947 8,0.923 5,0.996 4,0.923 5,0.996 4,1.069 3。以此类推。则2组数列在第k个点的关联系数为
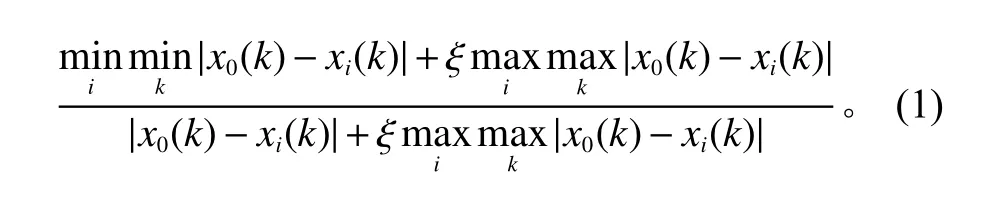
其中,分辨系数ξ 取值为0.5。
2组数据序列间的关联度为
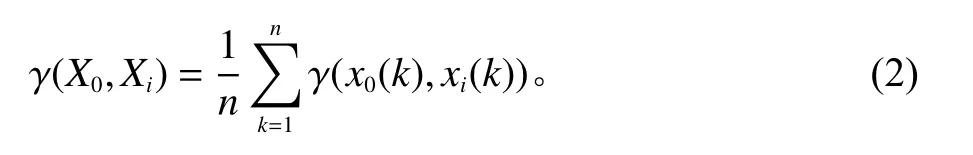
使用初值化、均值化和极值化3种方法处理数据后得出的各个装配工艺参数的灰关联度值如表4所示。并将关联度值进行排序,结果如表5所示。
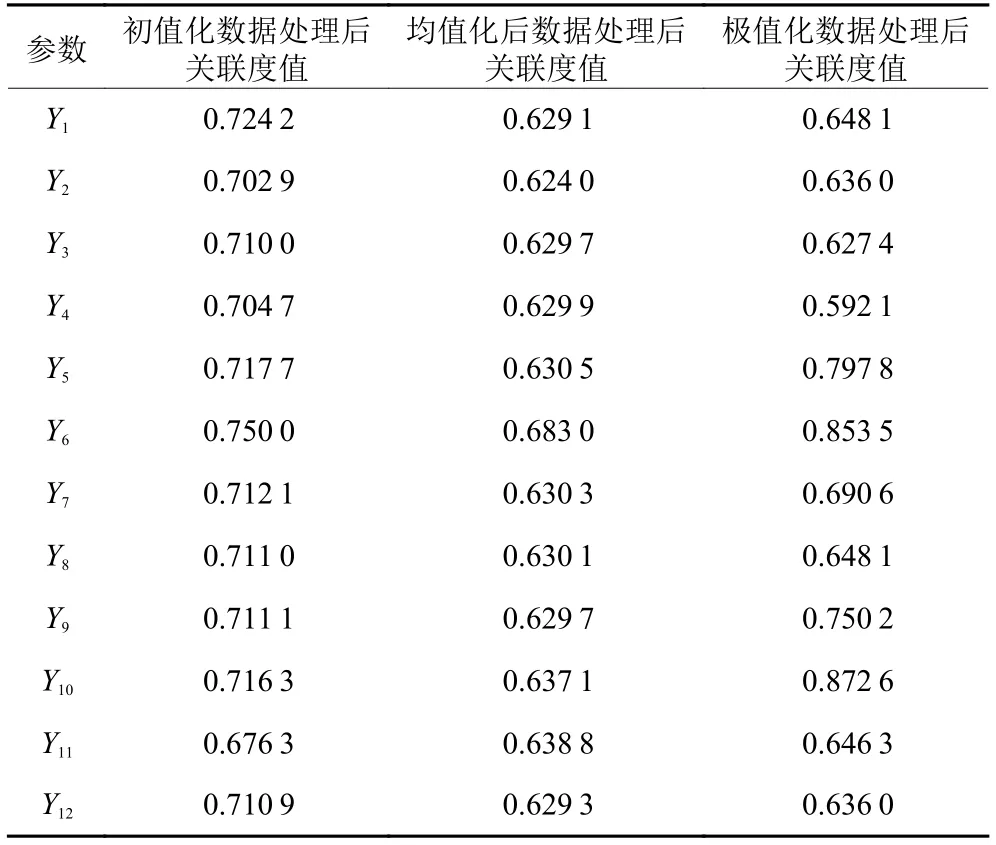
表4 3种数据无量纲化后关联度值Table 4 Three kinds of data dimensionless correlation degree value
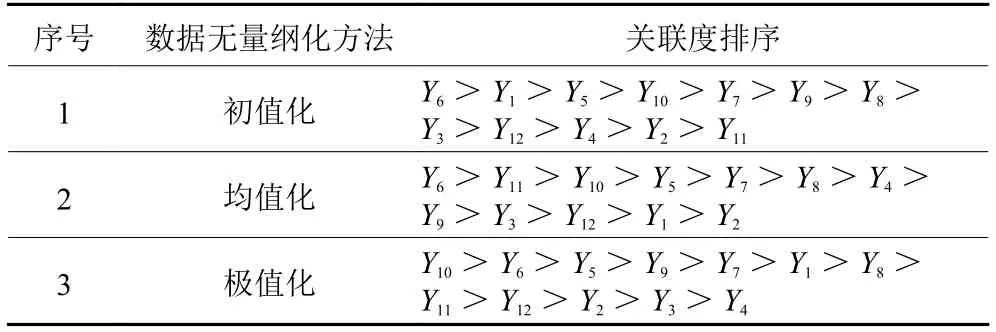
表5 装配参数关联度排序Table 5 Ordering of the association degree of assembly
通过分析表4装配工艺参数的灰关联度值以及表5的排序结果,将3种灰关联排序中都排在前面的装配工艺参数作为影响变速箱总成的关键参数,分别为Y6、Y10、Y5、Y7、Y9。可以将这5个关键装配工艺参数应用于变速箱总成密封质量预测模型,从而简化预测模型结构,得到更为精确的总成泄漏预测值。
3 建立GABP神经网络预测模型
3.1 BP神经网络
BP神经网络由信号正向传播和误差反向传播组成[11]。它能同时处理大量的数据集,并模拟任意的非线性、多输入多输出关系,可以实现从输入到输出的任意非线性映射。网络结构如图3所示。
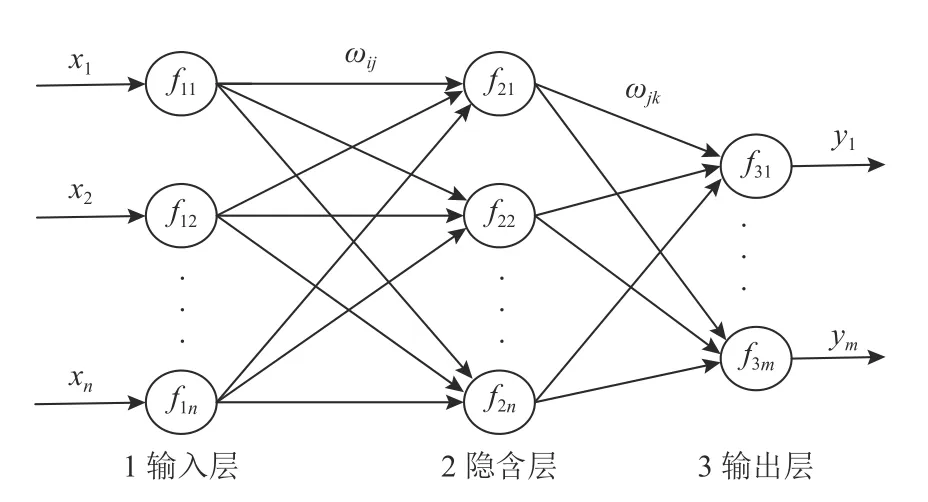
图3 BP神经网络拓扑结构Figure 3 BP neural network topology
在信号传递中,激活函数选为S形函数,即

再通过误差的反向传播,得到最优神经元权值和阈值,并赋值于BP神经网络以满足误差要求[12]。误差值为

BP算法也存在着一些局限性:1) 初始权值和阈值的不确定性;2) 最终结果可能是局部最小值;3) 缺乏高效的方法选取学习率;4) 隐含层神经元的个数难以确定[13]。
为了避免直接使用BP神经网络的弊端,本文提出使用遗传算法来优化BP神经网络的方法,使得预测的结果更加准确。
3.2 遗传算法
遗传算法(GA)是通过遗传三大操作,获得适应度值最高的种群个体,从而寻找最优解。
1) 遗传编码。编码是应用遗传运算的关键[14]。在编码过程中一般采用的方法为实数编码和二进制编码。根据应用遗传算法优化的实例要求,本文选取实数编码。
2) 适应度函数。设计该函数的目的是为了对种群中的染色体进行选择,以判断染色体的好坏。因此适应度函数应根据实际而设定,本文将训练值与实际值的绝对差值之和设为选择的适应度值。

其中,tk表示网络预测值;yk表示实际输出值。
3) 选择。通过选择算子不断择优,即寻找并筛选出优秀的个体。其中染色体被选择的概率为

4) 交叉。通过交叉算子得到异于母体的子代,以增加优秀的个体并提高遗传算法的搜索能力。
5) 变异。通过变异算子得到区别于母体的子代,即获得更优秀的种群个体达到全局最优的效果。
3.3 遗传算法优化BP神经网络
GA优化BP神经网络的核心是利用GA的全局寻优能力,借助遗传三大操作获得最优染色体,并将最优权值和阈值赋值于BP神经网络[15],使得网络输出结果更接近实际值。优化过程如图4所示。

图4 遗传算法优化BP神经网络流程Figure 4 Genetic algorithm to optimize the BP neural network
4 基于GABP神经网络模型的变速箱总成密封质量预测
4.1 总成密封质量预测模型参数设置
将关键装配工艺参数(Y6、Y10、Y5、Y7、Y9)作为GABP神经网络的输入,变速箱总成泄漏值Y0作为网络输出。本文使用Matlab软件对变速箱装配环节的实际采集数据进行训练与测试。其中BP结构的参数由算法经验所定,GA结构的种群大小、交叉概率和变异概率由算法运行实际所定,具体数值如表6所示。

表6 GABP参数设置Table 6 GABP parameter settings
4.2 质量预测结果与分析
在M型变速箱装配线共采集60组原始数据,首先对前50组样本进行GABP网络训练,再对后10组样本数据进行网络测试,得出测试样本的预测值。并将预测结果与实际泄漏值作对比分析,最后选取MRE(平均相对误差)指标验证预测方法的有效性。

式中,Y为实际值;T为预测值;N为样本数。其结果如表7所示。
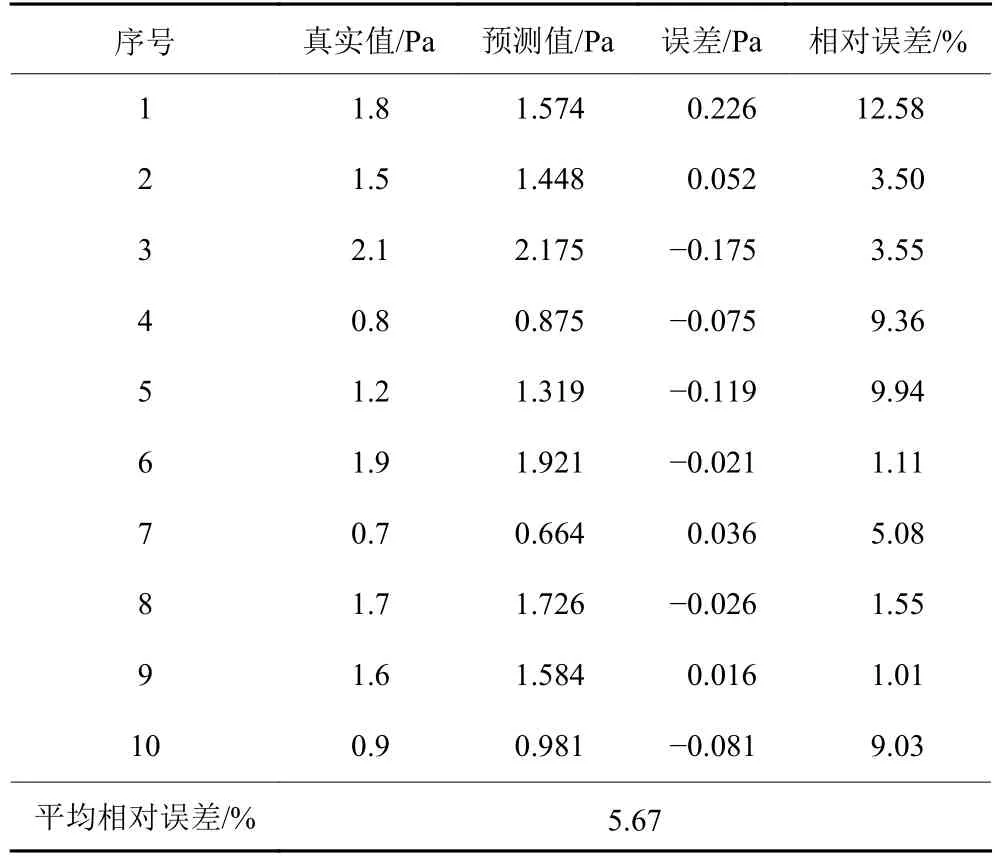
表7 装配总成密封性质量预测结果Table 7 Prediction results of sealing quality of the assembly
由表7可知,本文将灰关联分析提取到5种关键装配工艺参数后,应用简化GABP神经网络预测模型得到平均相对误差为5.67%。且本文又使用了灰关联分析简化的BP预测模型、12个装配工艺参数全输入GABP预测模型和12个装配工艺参数全输入BP预测模型3种方法对总成泄漏值进行预测,其具体质量预测结果如表8所示。
由表8结果可知,提取关键参数后的简化BP预测平均相对误差为8.64%,全输入GABP预测和全输入BP预测结果误差较大,分别为11.04%和12.23%。为作清晰对比,作出误差较小的简化GABP预测和简化BP预测值与实际值的散点图,如图5所示。
通过表7、表8和图5结果的综合分析,使用灰关联分析提取到关键装配工艺参数后,应用GA优化的BP神经网络得到预测值的平均相对误差最小,为5.67%。即预测结果最接近于实际泄漏值,验证了该方法的有效性。
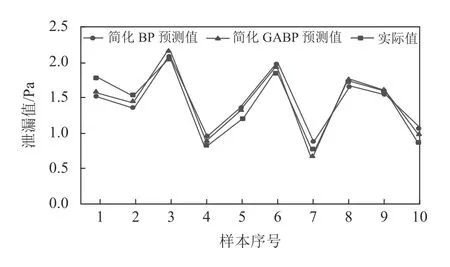
图5 预测结果对比Figure 5 Comparison of prediction results
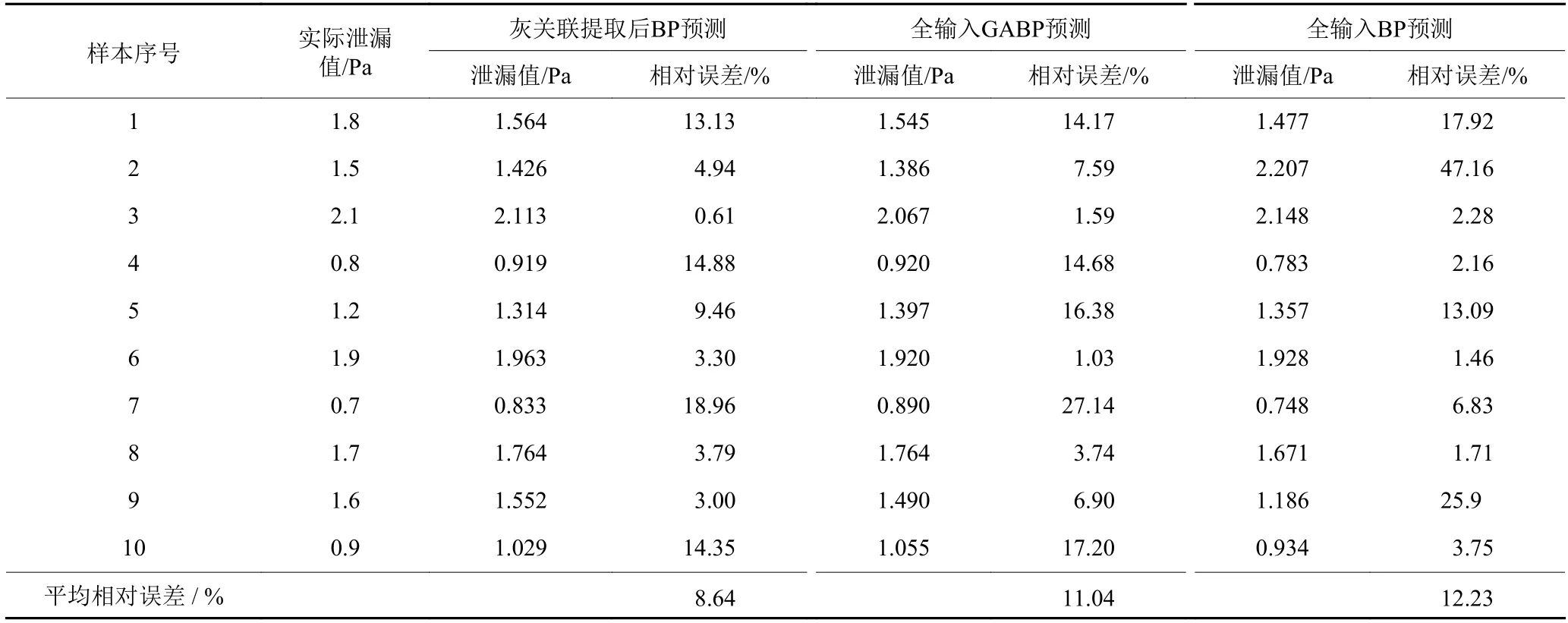
表8 不同预测方法对装配总成密封质量预测结果对比Table 8 Comparison of the prediction results of the sealing quality of the assembly by different prediction methods
5 结束语
通过数据验证,本文提出的使用灰关联分析选择关键装配工艺参数以简化GABP神经网络的预测模型可以较为精确地预测出变速箱总成的泄漏值,从而客观地评价变速箱总成的密封质量。该预测模型的使用对企业进行事前控制M型变速箱密封质量,提高一次装配合格率,降低因质量问题导致的经济损失具有重要的意义。
