特征重要性动态提取的广告点击率预测模型
2022-05-10蒋兴渝黄贤英陈雨晶
蒋兴渝,黄贤英,陈雨晶,徐 福
(重庆理工大学 计算机科学与工程学院,重庆 400054)
1 引 言
在广告行业中,当下流行的计费模式之一是广告主向广告发布商按照每产生一次点击进行计费(Cost Per Click).在这种模式下,提升点击率预测的准确度,不但会影响广告主和广告目标客户对广告发布商的认可度,而且很大程度上影响了广告发布商的收入,因此提升CTR预测准确率已经成为大规模广告推荐的关键任务.
目前学术和工业界针对该任务提出的预测模型主要可以分为两类:传统预测模型和基于深度学习的预测模型.其中传统模型如:协同过滤(Collaborative Filtering,CF)[1]通过设立用户和物品的共同评分矩阵进行预测,逻辑回归(Logistic Regression,LR)[2]学习每个用户、商品特征的参数得到预测结果,Polynomial-2(Poly2)[3]在LR的基础上通过特征之间的交互矩阵参数解决了特征交互问题,基于梯度提升树模型(Gradient Boost Decision Tree,GBDT)[4]考虑了特征之间的熵关系,以及利用矩阵分解为每个特征设置隐向量来进行交互的基于因子分解机(Factorization Machine,FM)[5]和改进FM利用特征域使特征交互更准确的域感知因子分解机(Field Factorization Machine,FFM)[6],除此之外还有FaceBook发布的GBDT+LR[7]组合模型.由于这类模型提出的时期较早,只考虑了对低阶特征的学习,未能使用深度神经网络挖掘低阶特征的高阶信息,限制了模型的预测能力.
近年来随着深度学习在各个领域上取得的重大成功,业内学者和工程师提出了许多基于深度学习的CTR模型,因此利用深度神经网络(Deep Neural Network,DNN)预测广告点击率已然成为该行业的研究趋势.随之出现了基于神经网络的因子分解机(Factorization-Machine Supported Neural Networks,FNN)[8],Wide&Deep(WDL)[9],深度因子分解机(Factorization-machine based neural network,DeepFM)[10],xDeepFM[11]等.这类模型的重点是通过神经网络对高阶特征之间的关系进行拟合,从而提升模型的预测准确率,却忽略了提取低阶特征时不同特征交互所含的重要性不同等问题,限制了深度神经网络学习的高阶特征表达.对于特征交互重要性问题,AFM[12]提出将注意力机制引入到特征交叉模块,使其能够显式地学习出每种交互特征的重要性,但这种方式没有考虑到特征交互时引入的干扰信息并且只考虑了特征两两交互的情况,因此预测准确度的提升十分有限.
针对以往模型提取特征重要性的不足[10-13],仅仅使用复杂的深度网络模型不但会增加计算资源的消耗,存在网络退化、梯度爆炸、梯度消失等隐患,而且难以从具有干扰的特征信息里学习到更多有效交互特征.为此,本文提出了一种特征重要性动态提取的广告点击率预测模型(Feature Importance Dynamic Extraction Supported Gating-Residual Network,FIDE).该模型的基本思想是:在提取的特征重要性之前增加门控机制(Gating Mechanism)对特征信息进行筛选避免引入干扰信息;为了获得多个特征之间交互的重要性,迁移使用了一种来自图像的特征重要性提取方法SENet[14]计算特征重要性交互并将其与原始一阶特征融合;然后通过双线性方法对融合特征进一步交互,最后利用门控和残差(Residual)[15]结合方法构建出更深的网络获得更高阶的特征交互.
本文的主要贡献如下:
1)提出一种特征重要性动态提取的CTR预测模型FIDE.巧妙地结合了SENet、门控机制和残差方法,用于特征重要性的提取.
2)提出的FIDE在提取特征重要性的过程中,考虑了特征中的干扰信息,通过门控机制实现了特征重要性的动态筛选;
3)提出的FIDE在训练深度神经网络时通过使用残差和门控机制,动态获取特征高阶信息,一定程度上抑制了随着网络层数的加深出现的网络退化和梯度问题.
2 相关工作
在深度学习领域,卷积神经网络(Convolutional Neural Networks,CNN)的发展对其它计算机视觉任务如目标检测[16]和语义分割[17]都起到推动作用,而卷积核作为卷积神经网络的核心,通常被认为是在局部感受野上,将空间(Spatial)信息和特征维度(Channel-Wise)信息进行聚合的信息聚合体.在SENet提出之前的卷积操作[18,19]主要是将输入特征的所有Channel进行融合,未能考虑Channel之间的关系,而SENet的创新在于使模型可以自动学习到不同Channel的重要程度.为此,SENet提出了Squeeze-and-Excitation(SE)模块,该模块对每个Channel独立使用全局平均池化,然后使用两个非线性的全连接(Fully Connected,FC)层捕获非线性的跨通道交互作用,并通过一个挤压函数生成每个Channel的权值,最后将提取到的权值与原始数据融合得到具有重要性表示的特征.事实证明SENet在图像分类任务中能够高效地解决问题,并在当年ILSVRC分类任务中获得第一名.基于该方法在特征重要性提取上的优势[20-23],本文提出的FIDE通过SENet多特征向量交互信息挤压来学习特征的重要性,使原始特征和重要性特征能够融合.
近年来门控机制在自然语言处理(Natural Language Processing,NLP)任务中被广泛应用,例如LSTM[24]通过增加隐变量细胞状态(Cell State)记录信息解决了循环神经网络(Recurrent Neural Network,RNN)[25]的梯度问题,除此之外GRU[26]通过重置门(Reset Gate)和更新门(Update Gate)分别捕捉时间序列里短期和长期的依赖关系.ABSA-GCN[27]则证明了,门控机制具有筛选特征的功能,门控机制相当于一个调节阀,可以控制流入的信息流量的流入程度,因此通过门控机制可以自适应地使不同粒度的潜在特征用于不同的处理流程.基于门控机制的特征自适应选择能力,本文在数据输入SENet前利用了门控机制过滤出重要性信息,使SENet能够将得到的信息用于重要性提取.
深度学习的重点在于其能够对数据特征进行学习抽象,直观上可以认为是在非线性激活函数的条件下,通过增加网络层数获得更大的假设空间,以此更有可能获得最优解.但在实际应用中,更深的神经网络往往会遇到梯度消失、梯度爆炸以及网络退化问题.出现问题的原因在于神经网络难以在最优解层之后的网络层中拟合出恒等映射,使得预测结果反而偏离了最优解,针对这一问题,残差网络通过残差单元以跳层的形式实现连接,使得模型可以在获得最优解之后进行恒等映射,实验表明[15],残差网络解决了深度神经网络的退化问题,并在ImageNet和CIFAR-10等图像任务上取得了较大的提升,同等层数条件下相比前馈神经网络,残差网络收敛速度更快.除此之外,去除个别神经网络层,残差网络的表现不会受到显著影响,这一点上与传统的前馈神经网络有较大差异.受这一思想的影响,在NLP领域,谷歌提出的Transformer[28]的编码器和解码器中,每一个子模块使用了残差连接用于保留特征信息和防止梯度问题.与文献[15,28,29]不同的是,本文针对的CTR任务在使用残差结构拟合数据特征时,能够在前几层就获得最优解,这是由于公开数据集中特征组相比图像少,限制了更多预测的可能性.
本文以广告点击数据作为研究对象,在SENet的基础上采用门控机制动态筛选出细粒度特征重要性,并通过SE模块进一步挤压提取特征重要性,同时还考虑了原始特征所含的有效信息,结合两者得到了含有特征重要性的数据表示,最后将其和原始数据都进行双线性交互后送入隐藏门控残差网络计算出预测结果.本文提出的FIDE主要解决的问题是:以往预测模型中忽略的特征重要性提取和提取特征时数据中的干扰问题,将在第4节通过实验证明其能够解决以上问题并达到更好的预测效果.
3 特征重要性动态提取的广告点击率预测模型
本文提出的FIDE目的在于能够通过细粒度方式动态地提取特征重要性和去除数据中的干扰.模型结构如图1所示,为了清楚起见,省略了可以简单合并的LR[2]部分.FIDE主要包含以下部分:Embedding嵌入层(Embedding Layer),门控SE层(Gating Mechanism and SE Layer,GM-SE Layer),双线性交互层(Bilinear-Interaction Layer),组合层(Combination Layer),隐藏门控残差网络(Hidden Gating-Residual Network,HGR-DNN),输出层(Output Layer).其中嵌入层与DeepFM相同,对类别输入特征采用稀疏特征表示,并将稀疏特征嵌入稠密向量中.门控SE层可以将嵌入层的输出通过门控机制得到向量,并利用SE进一步挤压提取获得特征重要性表示,这有助于增强特征的可分辨性,提升模型对重要特征的学习效率.接下来的双线性交互层分别学习原始嵌入特征和具有重要性分辨的嵌入特征的二阶特征交互.随后将这些交互特征通过组合层连接,输入到隐藏门控残差网络中,最后由隐藏门控残差网络输出预测得分.

图1 特征重要性动态提取的广告点击率预测模型
3.1 Embedding嵌入层
CTR预测任务中,数据中的特征通常分为类别特征和数值特征.由于类别特征不能直接用于数值计算,因此需要通过独热编码将类别特征,转换为二进制向量表示,以便机器学习算法的处理.例如,在宠物食品广告中,可以将狗的性别特征按雌雄分别编码为二维向量[1,0]和[0,1].体型特征按照超大型、大型、中型、小型分别表示为4维向量[0,0,0,1]、[0,0,1,0]、[0,1,0,0]、[1,0,0,0]、[1,0,0,0].但在实际情况下,类别特征的独热编码通常是高维且稀疏的.如果直接用深度神经网络训练这样的高维稀疏特征向量,将带来难以忍受的计算复杂度并且会降低模型的泛化能力.因此在输入深度网络训练前,需要将高维稀疏特征向量通过Embedding嵌入层映射为低维稠密向量,这种方法在基于深度学习的CTR预测模型中被广泛应用[8-11].例如一只小型雌性狗的独热编码为[1,0,0,0,0,1],假设将这个6维稀疏独热编码通过一个两层神经网络,映射为4维的稠密嵌入向量[0.64,0.36,0.4,0.6],其中前两维[0.64,0.36]表示体型特征,后两维[0.4,0.6]表示性别特征,这种映射操作可以减少后续神经网络中的神经元数量和计算开销.值得注意的是,不同特征对应的嵌入向量维度可以有差别.
嵌入层的输入为原始数据特征的稀疏独热编码表示,输出是稠密的原始嵌入向量E=[e1,e2,…,ef],其中f表示特征域的个数,这里的域可以包含多个特征,例如狗的品种特征:博美、牧羊犬、哈士奇、斗牛犬等都属于品种这一个特征域,ei∈Rk表示第i个域的嵌入向量,k表示嵌入向量的维度.
3.2 门控SE层
不同特征对目标任务的重要性是不同的,例如预测一条化妆品广告是否能够被点击时,通常性别特征比爱好特征具有更高的重要性.由此利用SENet在特征重要性提取上的优势,使模型能够更加关注特征的重要性.但SENet在提取特征重要性过程中,对所有特征进行挤压提取,忽略了特征中的干扰问题,又由于门控机制在NLP领域应用中取得的成果[23-27],本文将门控机制与SENet结合.使得模型可以通过门控SE层动态学习重要特征的权重并减少非重要特征的权重.
门控SE层的输入是由嵌入层输出的嵌入向量E.首先嵌入向量E经过门控机制获得嵌入向量的门控重要性向量GE=[ge1,ge2,…,gei,…,gef],随后将向量GE经过SE挤压提取得到特征重要性向量S=[s1,s2,…,si,…,sf],然后将特征交互重要性向量S与原始嵌入向量E融合得到自适应重要性嵌入向量C=[c1,c2,…,ci,…,cf],其中gei∈Rk表示第i个嵌入向量的门控重要性向量,si∈R表示第i个嵌入向量的交互重要性,ci∈R表示第i个嵌入向量的自适应重要性嵌入向量,f表示特征域的个数,k表示嵌入向量的维度.
门控SE层由4个步骤组成,如图2所示,图中fg(·)、fsq(·)、fex(·,W)和fimportance(·,·)分别表示门控过滤、特征挤压、特征重要性提取以及特征重要性融合步骤.以下是这4个步骤的详细过程描述:
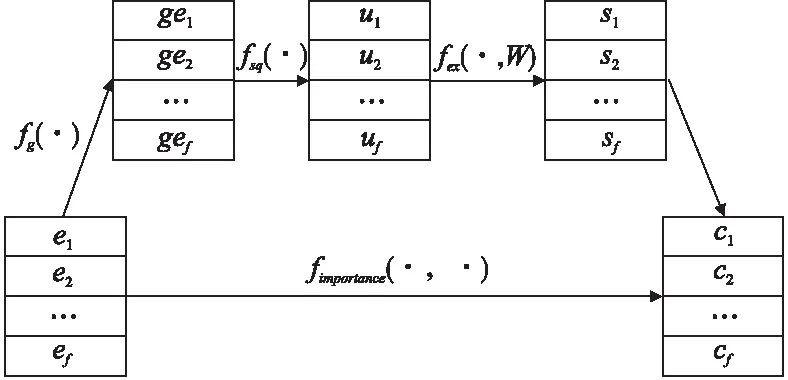
图2 门控SE层
1)门控过滤:这一步可以去除原始嵌入向量中的干扰信息,并为原始嵌入向量赋予重要性.门控过滤首先为每个嵌入向量ei计算出特征门控重要性gi,其计算过程如式(1):
gi=σg(wi·ei)
(1)
其中ei∈Rk表示原始嵌入向量,wi表示第i个嵌入向量的重要性学习参数,i=1,2,…,f,σg表示门控过滤激活函数.
然后将过滤后的特征门控重要性gi与相应的原始嵌入向量ei融合,生成门控重要性向量gei,计算过程如式(2):
gei=fg(ei)=ei⊗gi
(2)
其中ei∈Rk表示第i个原始嵌入向量,gi表示第i个门控重要性,i=1,2,…,f,⊗表示Hadamard积或元素级矩阵计算.
通常公式(1)中利用门控机制输出得到的门控重要性是一种标量特征重要性表示,本文为了更细粒度地获取嵌入向量重要性,考虑了另一种矢量特征重要性表示,两种表示的计算如图3所示.当门控重要性gi为标量特征重要性gis∈R时,嵌入向量的重要性学习参数wi∈Rk×1,门控重要性gi为矢量特征重要性giv∈Rk时,嵌入向量的重要性学习参数wi∈Rk×k,k是嵌入向量的维度.

图3 标量与矢量特征重要性表示计算
从图3可以看出,标量特征重要性gis是一个值,并按照这个值为对应的嵌入向量的每个维度特征赋予相同的特征重要性.矢量特征重要性giv则是一个k维的向量,它可以为每个维度特征赋予不同的特征重要性.两种重要性表示方法的性能比较将在实验4.4节进行讨论.
2)特征挤压:这一步用于获取每个门控重要性向量的摘要统计信息,常用方法是通过最大池化或平均池化,将门控重要性向量GE=[ge1,ge2,…,gei,…,gef]转化为摘要统计信息U=[u1,u2,…,ui,…,uf],本文通过实验,发现在CTR预测任务中,平均池化效果优于最大池化,其计算方法如式(3)所示:
(3)

3)特征重要性提取:这一步的目的是通过特征挤压得到的摘要统计信息U计算出嵌入向量的交互重要性向量S.具体操作是利用两个非线性的全连接层实现,第一层是一个学习参数为W1,减少率(Reduction Ratio)为r的降维层,第二层是一个学习参数为W2的升维层,计算过程如公式(4)所示:
S=fex(U,W)=σ2(W2σ1(W1U))
(4)
其中第1层学习参数W1∈Rf×(f/r),第2层学习参数W2∈R(f/r)×f,σ1、σ2分别代表第1层、第2层激活函数,r是全连接层的维度减少率.
4)特征重要性融合:门控SE层的最后一步是特征重要性融合,这一步将原始嵌入向量E和嵌入向量的交互重要性S融合,输出得到的自适应重要性嵌入向量C.具体计算过程如公式(5)所示:
C=fimportance(S,E)=[s1·e1,…,sf·ef]=[c1,…,cf]
(5)
其中,si∈R,ei∈Rk,ci∈Rk,i表示第i个特征域,i=1,2,…,f,k表示嵌入向量的维度.
3.3 双线性交互层
特征之间的信息关联对模型预测准确率有着较大影响,例如一条流行服饰的广告中,服饰的品类和款式往往决定了广告能否吸引用户观看,直接影响了广告的点击率.传统的特征交互方法有内积、外积、Hadamard积等.但这类方法遗漏了特征交互时的重要性选择,并且特征之间的交互结果往往会因交互特征而异.因此本文提出使用一种更细粒度的自适应特征交互方法——双线性交互[31].其计算方式如公式(6)所示:
qij=ciW⊙cj
(6)
其中ci,cj∈Rk分别表示第i,j个自适应重要性嵌入向量,i,j=1,2,…,f,W为交互参数,⊙代表对应元素相乘.由于交互方式的不同,公式(6)中的双线性交互参数W又分为:全域共享交互Wall,域私有交互Wi,域专属交互Wij.3种交互方式分别如公式(7)-公式(9)所示:
全域共享交互:
qij=ciWall⊙cj
(7)
其中Wall∈Rk×k是一个所有自适应重要性嵌入向量ci,cj∈Rk的共享参数矩阵.
域私有交互:
qij=ciWi⊙cj
(8)
其中Wi是第i个自适应重要性嵌入向量的参数矩阵,在域私有交互的计算方式下,共有f个这样的参数矩阵,f为域的个数.
域专属交互:
qij=ciWij⊙cj
(9)
其中Wij是第i个自适应重要性嵌入向量与第j个自适应重要性嵌入向量的参数矩阵,在域专属交互的计算方式下,共有f(f-1)/2个Wij参数矩阵,f为域的个数.
如图1所示,双线性交互层对输入的原始嵌入向量E和自适应重要性嵌入向量C都进行了双线性交互,目的是提取两种不同向量的自身向量之间的关联交互信息.双线性交互层的输出是由原始嵌入向量得到的原始交互P=[p1,…,pi,…,pn]和由自适应重要性嵌入向量C得到的自适应重要性交互Q=[q1,…,qi,…,qn],其中pi,qi∈Rk,k是嵌入向量的维度,n∈Rf(f-1)/2是向量之间交互个数.针对三种交互方式的对预测性能的贡献,将在实验4.5节进行讨论.
3.4 组合层
组合层的输入是原始交互P和自适应重要性交互Q,输出是将两者进行拼接后的组合交互V.其组合过程如公式(10)所示:
V=[P,Q]=[p1,…,pn,q1,…,qn]=[v1,…,v2n]
(10)
如果直接组合交互V里的每个元素相加求和,然后通过Sigmoid函数输出预测值,则可以得到一个未经过深度网络计算的浅层部分(Shallow Part)模型FIDEshallow.
3.5 隐藏门控残差网络
以往的CTR预测模型使用的深度网络往往层数不深(通常在3-5层左右),由于网络退化和梯度等问题,未能完全利用深度网络拟合数据的优势.本文结合门控和残差方法提出的隐藏门控残差网络(HGR-DNN),该网络由如图4所示的多层堆叠形成.HGR-DNN的输入是组合交互V拉平后的表示V0,V(l),表示隐藏门控残差网络第l层的输出.计算公式如式(11)、式(12)所示:

图4 一层隐藏门控残差网络
V(l)=V(l-1)⊗σv(W(l)V(l-1)′)
(11)
(12)

3.6 输出层
输出层将LR计算部分、HGR-DNN输出的V(l)求和用于最终预测.此处LR部分所用的原始嵌入向量E=[e1,e2,…,ef],是通过稀疏独热编码通过两层神经网络映射得到的,因此计算它的梯度更新受到LR部分和V(l)的共同影响,对应的原始编码可以通过稠密嵌入向量和稀疏高维编码之间的神经网络参数逆向计算得到.
综上所述,FIDE模型输出的整体公式如式(13):
(13)
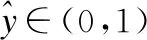
(14)

算法1.特征重要性动态提取的广告点击率预测算法.
输入:学习率α,样本批量大小M,Embedding嵌入层参数θG,门控SE层中门控过滤、特征挤压、特征重要性提取以及特征重要性融合步骤参数分别为θge,θsq,θex,θimportance,双线性交互参数θBi,深度神经网络参数θHGR-DNN.
输出:完成训练的网络fFIDE.
1.从数据集中随机读取M个样本X={x1,x2,…,xm}
2.E←fθe(X) /*其中fθe(·)为Embedding嵌入层函数表示*/
3.GE←fθge(E)/*其中fθge(·)为门控SE层中的门控过滤步骤函数表示,如公式(1)(2)所示*/
4.U←fθsq(GE)/*其中fθsq(·)为门控SE层中的特征挤压步骤函数表示,如公式(3)所示*/
5.S←fθex(U,W)/*其中fθex(·,W)为门控SE层中的特征重要性提取步骤函数表示,如公式(4)所示,W为该步骤的两层神经网络参数*/
6.C←fimportance(S,E)/*其中fimportance(·,·)为门控SE层中的特征重要性融合步骤函数表示,如公式(5)所示*/
7.P←fBi(E),Q←fBi(C)/*其中fBi(·)为双线性交互层函数表示,如公式(6)-公式(9)所示*/
8.V←fcombination(P,Q)/*其中fcombination(·,·)为组合层函数表示,如公式(10)所示*/

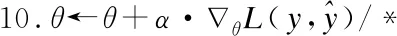
11.重复步骤1至步骤10直至网络收敛
4 实验及性能评价
本节将介绍实验数据以及评价参数设置,通过在两个真实的公开广告数据集Criteo(1)Criteo:http://labs.criteo.com/downloads/download-terabyte-click-logs/和Avazu(2)Avazu:http://www.kaggle.com/c/avazu-ctr-prediction/上进行的实验,对FIDE模型的预测性能进行评价.实验内容包括:
1)FIDE与目前最高水平的BaseLine(基线)对比
2)门控嵌入层对模型性能的提升
3)不同双线性交互方式对模型性能的影响
4)HGR-DNN对模型性能的提升
5)超参数设置对模型性能的影响
4.1 实验数据及评价指标
4.1.1 数据集
Criteo数据集近年来被广泛应用于对CTR任务模型性能的评价.它包含了约4500万真实用户点击反馈数据,Criteo数据集的特征由26个脱敏分类特征和13个连续数值特征组成.本文实验将数据集随机分为两部分:90%用于训练,其余用于测试.Avazu数据集由不同日期的广告点击按时间顺序组成.该数据集包含约4000万真实世界的用户点击记录,每个广告点击有24个特征.本文实验将其随机分为两部分:80%用于训练,其余部分用于测试.自2014年以来,学术界一直使用Criteo和Avazu数据集来衡量CTR预测模型的性能[30-32].
4.1.2 评价指标
本文实验以AUC[33]和LogLoss[34]为评价指标.
AUC作为一个评价分类问题的广泛使用的指标,它的优点在于受正负样本比例影响较小.从数学上来说,AUC是受试者操作曲线(Receiver operating characteristic,ROC)的下面积,其上限为1.此外,也有研究证明AUC是对CTR预测任务的一个良好评价标准[35].在实验中,AUC值越大,模型的预测性能越好.
LogLoss是二分类问题中广泛使用的评价标准,用来表示预测值与真实值之间的差距.LogLoss的下限为0时表示预测值与真实值完全匹配.在实验中,较小的LogLoss值表示预测模型具有更好的性能.
4.1.3 实验超参数设置
本文在实验中利用Tensorflow(3)TensorFlow:https://www.tensorflow.org/实现了所需模型.实验中的嵌入门机制层在使用Criteo数据集时,嵌入向量的维度设置为20;在Avazu数据集上,嵌入向量的维度设置为50.本文使用Adam[36]作为实验优化方法,对于Criteo数据集,
最小Batch-Size为1024;对于Avazu数据集,最小Batch-Size为512.Criteo数据集的每层神经元数为512,Avazu数据集的每层神经元数为1024.统一设置学习率为0.0001,Drop Out Ratio为0.5,HGR-DNN的层数为5层.
4.2 对比试验模型设置
为了验证FIDE仅使用Shallow Part模型和使用Deep Part模型的性能,本文将实验分为两组:Shallow组和Deep组.实验还将基线对比模型分为两个部分:浅基线模型和深基线模型.浅基线模型包括LR[2],FM[5],GBDT+LR[7]而深基线模型包括FNN[8],WDL[9],DeepFM[10],xDeepFM[11].对于深基线模型,为了简化对比试验,统一设置每个隐层节点的激活函数为ReLU,输出节点的激活函数为Sigmoid,最优参数求解都采用Adam.值得注意的是,通常认为AUC提高1‰也是有意义的,因为如果公司的用户群数量非常大,它将为公司收入带来大幅度的增长[10-13].
4.3 FIDE模型与基线模型性能对比
本小节分别在表1和表2中总结了Shallow组和Deep组在Criteo和Avazu测试集上的整体性能.表1展示了Shallow组模型在Criteo和Avazu数据集上的结果,FIDE-Shallow-ALL表示浅层FIDE模型,尾称ALL表示实验中模型各个层和步骤都选用最优方法,观察实验结果可以看出FIDE-Shallow-ALL的性能始终优于其他模型.
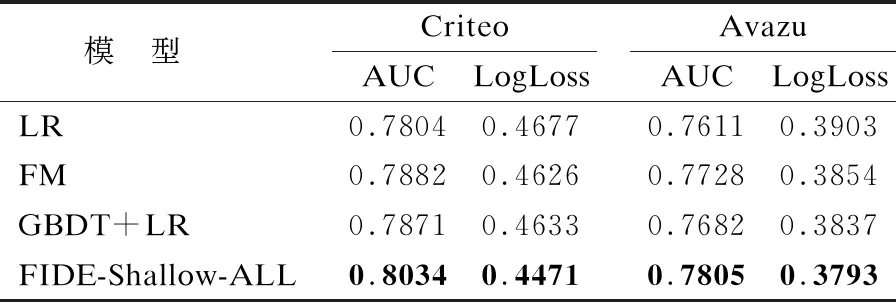
表1 Shallow组模型性能对比
为了进一步提升模型性能,将FIDE Shallow部分和HGR-DNN进行串联组成的FIDE-Deep-ALL性能如表2所示,通过观察Shallow组与Deep组模型性能比较可以看出,与HGR-DNN组合的模型确实提升了特征的高阶交互学习能力.Deep的深度学习模型性能基本优于Shallow组.在与其他Deep组模型比较中,FIDE-Deep-ALL相比FNN、WDL、DeepFM和xDeepFM的AUC提升了0.5%、0.35%、0.29%、0.23%,这说明FIDE-Deep-ALL相比其它最高水平模型具有优越性.侧面体现了FIDE-Deep的结构设计确实可以挖掘出更多对于CTR预测有价值的信息,同时也表示通过HGR-DNN获得隐含的高阶特征有助于Shallow部分获得更多的表达能力.

表2 Deep组模型的性能对比
4.4 门控嵌入层对模型性能的提升
本小节通过将门控过滤机制插入基线模型的对比实验发现门控机制在Criteo和Avazu数据集上能够提升模型性能.如表3所示,带有ge下标的模型表示插入了门控机制,反之则没有,△符号代表模型提升数值.从实验数据可以发现,具有嵌入门控机制的LR、FM在预测性能上有较大提升,这是因为原始LR、FM没有显式或隐式地调整模型特征的方式.除此之外,门控机制同样为DeepFM、xDeepFM以及FIDE提供了一定的精度提升.这些结果表明,从特征中细粒度地选择显着的潜在信息能够有效增强模型能力并使基线模型获得更好的性能.

表3 插入门控机制的模型性能对比
此外本文还针对门控过滤中的矢量和标量重要性表示方法,在FIDE的基础上设计了另一组实验进行研究.实验结果如表4所示,其中sc下标代表标量重要性表示,ve下标代表矢量重要性表示.
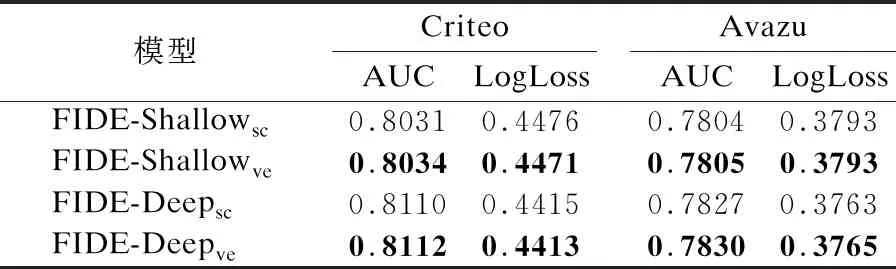
表4 两种重要性表示方法性能对比
从表4中可以看出,虽然矢量重要性表示方法可以减少学习参数数量,但同时会降低模型性能.在Avazu数据集上,不同表示方法对模型性能提升有限.实验结果表明门控机制的不同重要性表示方法,需要根据数据任务的不同灵活选择.总体而言,在本文的实验中选择矢量重要性表示方法能取得更好的效果.
4.5 不同双线性交互方式对模型性能的影响
本文对全域共享、域私有以及域专属交互方式在浅层和深层模型分别进行了实验,结果如表5所示.其中下标share表示全域共享,private表示域私有,exclusive表示域专属.

表5 3种交互方式性能对比
从表5可以发现:对于浅层模型在Criteo数据集上和全域共享相比,域专属方式可以提升0.17%,深度模型域专属方式比全域共享提升了0.9%;在Avazu数据集上,域私有方式会取得更好的效果.由此可以总结出:不同类型的双线性交互层的性能取决于数据集.在Criteo数据集选择域专属方式,在Avazu数据集选择域私有方式进行预测能取得更优效果.
4.6 HGR-DNN对模型性能的提升
表6将DeepFM、xDeepFM和FIDE使用传统DNN和HGR-DNN效果进行了对比,通过实验结果可以发现通过使用HGR-DNN代替传统DNN能够增强基线模型效果,提升模型对Criteo和Avazu数据集的预测性能.

表6 HGR-DNN对模型性能影响
其中下标d和h分别表示模型Deep Part使用的DNN和HGR-DNN网络.尽管HGR-DNN网络结构较为简单,但是通过三种模型基线的对比证明了这是提高基线模型性能的有效方法.实验结果表明,其可帮助模型隐式地更有效地捕获高阶特征交互的优势,使得隐藏的门控残差方式效果优于以往的CTR预测任务中的网络.
4.7 超参数对模型性能的影响
本小节将对FIDE模型的一些超参数进行研究,重点放在嵌入层和HGR-DNN.具体而言,将修改以下参数:1)嵌入维度;2)HGR-DNN每层神经元数量;3)HGR-DNN层数.除非特别说明,否则默认参数遵照4.1.3小节进行设置.
1)嵌入维度对模型预测性能的影响
嵌入维度的变化会影响嵌入层和DNN部分中的参数数量.实验对比了嵌入维度对FIDE预测性能的影响,希望能够得出合适的嵌入维度,从而获得更优的模型性能.本文将嵌入维度大小按照步长为5,逐步从5调整为60并在表7总结了实验结果.通过实验结果观察到了以下信息:随着嵌入维度的增加直到维度为50,FIDE的性能在Avazu数据集上获得实质性提升;嵌入维度从20之后,随着嵌入维度的增大,FIDE对于Criteo数据集的预测性能反而下降.原因是Avazu数据集特征数量小于Criteo数据集,因此FIDE模型在Avazu数据集上的优化难度相对简单.
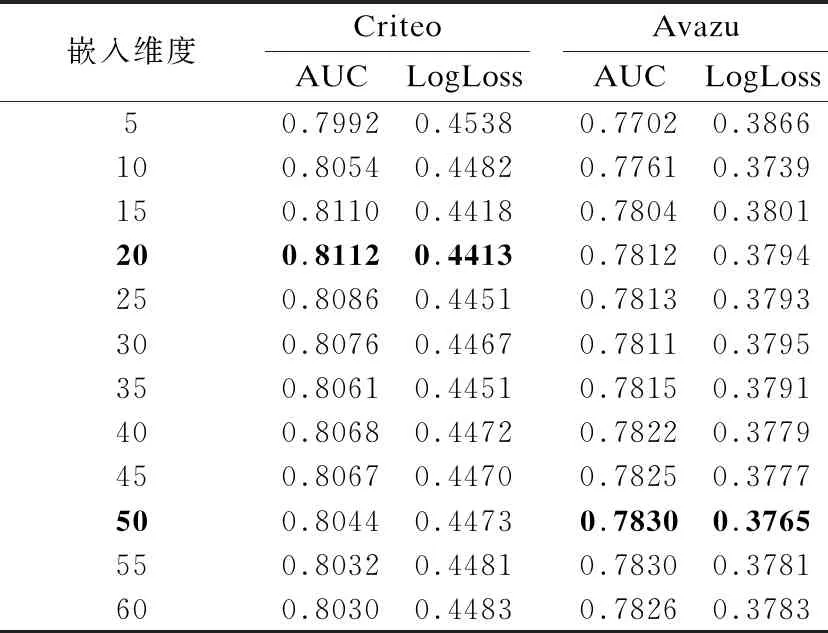
表7 嵌入维度对FIDE性能影响
2)DNN每层神经元的数量对预测性能影响
为了简化实验步骤,统一将每个全连接层的神经元数量按如下顺序设置:{64,128,256,512,1024,2048,4096},实验结果如表8所示.通过观察可以发现,增加每层神经元的数量在一定程度上可以提升模型的预测性能,但由于同时提升了学习参数的复杂度,因此在训练模型时需要考虑神经元数量.观察实验结果可以看出,刚开始逐步增加每个全连接层神经元数量时AUC指标逐渐增加,LogLoss指标逐渐降低,对于Criteo数据集,神经元数量在512时,AUC达到最优值,之后逐步增加神经元数量时AUC指标不再有明显提升,反而会有所降低.在Avazu数据集上的结果显示,每层神经元数量的最优值设置为1024,之后AUC指标同样不再有明显提升.这是因为随着神经元数量的提升,模型可以学习到更多高阶隐含信息,从而提升模型预测精度.但是当神经元数量达到一定阈值时,再增加神经元数量可能会导致模型过于复杂,甚至可能出现过拟合情况,因此需要合理选择每层神经元数量.

表8 不同神经元数量对FIDE性能影响
3)HGR-DNN深度对FIDE性能的影响
实验使用的HGR-DNN网络层数设置从0到8,当层数设置为0时,FIDE模型由深FIDE退化为浅FIDE.实验结果如表9所示.虽然本文利用残差和门控方法抑制了网络退化和梯度问题,但在网络层数已经能计算出最优解的前提下,继续增加层数只会增加模型的复杂性.可以从表9中观察到,增加层数在一开始可以提升模型的性能,但随着层数持续增加,模型性能无法继续提升.因此对于Criteo和Avazu数据集把网络层的数量设置为5(传统的CTR任务中DNN的层数通常小于等于3)是一个合理的选择.

表9 不同网络层数量对模型性能的影响
4.8 讨 论
本文在Criteo和Avazu数据集上使用了多个最高水平的基线模型(LR、FM、DeepFM、xDeepFM等)和FIDE进行实验对比.由于FIDE在预测性能上优于其它基线模型,在此基础上进行了更加全面的实验,包括各个层和步骤以及超参数.实验结果表明:1)门控机制的确能够对模型性能有一定提升;2)不同的双线性交互方式对模型性能有一定积极影响,具体使用哪种交互方式取决于数据的不同;3)HGR-DNN在增加模型的深度的同时,对预测精度有着促进作用;4)合理的超参数设置对模型性能有一定积极影响.总体而言,FIDE有效地提高了CTR预测任务的准确率.
5 结 语
近年来关于CTR预测任务发表的文章中,引入深度神经网络已经成为一种通用方法.为了提升点击率预测效果,本文提出了一种特征重要性动态提取的广告点击率预测模型(FIDE),旨在动态自适应地获取细粒度的特征重要性.该模型利用了SENet、门控机制和残差的优势,通过在两个真实广告公司数据集上的大量实验对基线模型和FIDE的预测数据对比,证明了其性能优于其它模型,有效地提升了CTR预测模型正确预测广告点击率的能力.
本文主要关注点在于特征工程,缺少对CTR样本数据的考虑.针对CTR数据正负样本不均衡的情况,未来可以尝试使用生成式对抗网络辅助生成样本.
