基于注意力机制的视频检索算法设计
2022-05-09北方工业大学信息学院苏清松
北方工业大学信息学院 苏清松
针对视频信息中空间域和时间域上特征提取存在运算成本高和时序信息不明显的问题,本文使用基于注意力机制的残差网络和双向LSTM复合模型,将视频提取出的关键帧输入到嵌入注意力机制的卷积神经网络和双向LSTM网络结构中分别提取视频的空间信息和时序信息,将本网络模型进行实验验证准确率有了一定的提升。
随着互联网和自媒体的发展,视频文件逐渐成为了人们日常生活中的主流信息载体。由于之前对文本和图片数据研究的积累,对该类型数据已有较为成熟和完善的分类检索方法,人们的研究方向也逐渐转移到视频领域[1]。面对数量巨大的视频信息,如何高效检索出用户需要的内容成为信息检索领域研究的重要问题。注意力机制从模拟生物学的角度出发,可以根据任务需求专注于输入或特征子集,自动地学习到待处理信息中比较重要的部分。Sanghyun Woo等[2]提出CBAM,通过通道注意力模块和空间注意力模块依次对输入特征进行处理后获得精炼特征。在深度学习领域,循环神经网络经常用来学习序列的时序信息,因此被广泛应用到自然语言处理等领域。而长短期记忆神经网络(LSTM)是RNN中最具有代表性的结构,Wang等[3]人提出了3D CNN与LSTM相结合的网络,同时对原始视频进行显著性检测,有效降低了网络参数和训练的难度。Tran D等[4]在二维CNN的基础上融合时间信息实现了3D CNN,该方法收敛较慢且相对使用更多的资源;Donahue J等[5]提出了基于CNN和LSTM的模型LRCN,该模型分别使用CNN和LSTM提取空间信息和时间信息,然后使用Softmax计算得出预测值,该方法准确率相对较低。
针对以上出现的问题,本文卷积神经网络基础上嵌入SENet模块,为视频不同通道赋予不同的权重,随后输入到双向LSTM网络中提取时序信息,从而提升视频特征的表示和检索能力。
1 相关技术
1.1 SENet模块
SENet是一种通道注意力网络模型,通过Sequeeze与Excitation操作得到不同通道的权重信息,进而对与目标相关性比较小的通道进行抑制,同时对与目标相关性大的通道信息赋予更大的权重。整个注意力操作通过学习得到各个通道的权重系数并进行加权处理,从而使得模型对各个通道的特征信息有更好的表达能力。
1.2 LSTM网络
LSTM是一种具有记忆功能的神经网络,每个单元由遗忘门、输入门、输出门和两个状态信息(隐藏状态和细胞状态)组成。其中遗忘门决定记忆单元中的上一时刻有多少信息被保留到当前时刻,在反向传播时可以防止梯度弥散和梯度爆炸,输入门的作用是决定有多少信息输入记忆单元,输出门的作用是决定存储单元的输出信息。所以LSTM相比于传统RNN最大的特点是使用门结构对视频信息和记忆单元之间的交互内容信息进行控制。
2 方法设计
本文在ResNet50网络中嵌入SE模块对输入的视频帧进行空间特征提取,并对注意力模块的嵌入位置在进行对比试验。其中,方法(1)不使用注意力模块;方法(2)在每个残差结构中使用注意力模块;方法(3)在ResNet50的第1至第5组卷积后使用注意力模块;方法(4)在第2至第5组卷积后使用注意力模块。实验结果如表1所示,由于ResNet50网络中第一组卷积相较于后四组卷积能够处理视频图像中更为原始的底层信息,所以本文采用方法(4)且相较于其他方法在准确率上有了提升。

表1 注意力模块效果验证Tab.1 Attention module effect verification
本文采用双向LSTM进行视频时序特征提取,在前向传播中将特征信息输入LSTM,反向传播中将特征信息以反向形式输入LSTM模型,每层LSTM网络对应输出一个隐藏状态信息,模型参数由反向传播进行更新,该模块可以提取视频信息的前后时序关系并进行输出。整体处理流程如图1所示。
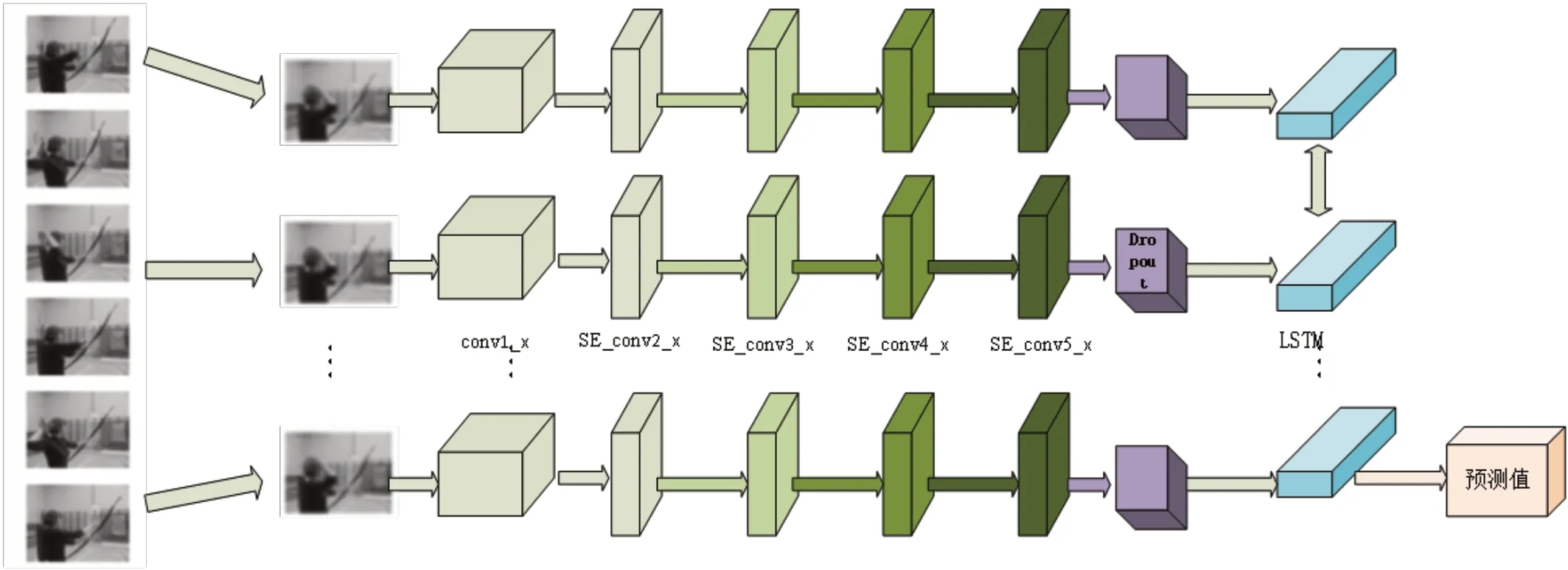
图1 本文模型网络流程图Fig.1 This paper models the network flow chart
在卷积神经网络模块中,conv1_x采用了64个7×7大小的卷积核,步长为2,池化层采用卷积核为3的最大池化,步长为2。SE_conv2_x采用3组64个1×1的卷积核、64个3×3的卷积核和256个1×1的卷积核,并且在每组之后添加一组Attention模块,其中Attention模块由3个卷积核为1的最大池化、两个全连接层、ReLU激活函数和Sigmoid激活函数组成,通过加入Attention模块给提取的通道特征给予不同的权重,提升特征表达的能力,从而提升视频检索的准确率。SE_conv3_x采用4组128个1×1的卷积核、128个3×3的卷积核和512个1×1的卷积核,并且在每组卷积之后加入和SE_conv2_x相同的Attention模块。SE_conv4_x采用6组256个1×1的卷积核、256个3×3的卷积核和1024个1×1的卷积核,并且在每组卷积之后加入和SE_conv2_x相同的Attention模块。
SE_conv5_x采用3组512个1×1的卷积核、512个3×3的卷积核和2048个1×1的卷积核,并且在每组卷积之后加入和SE_conv2_x相同的Attention模块。将上一模块的输出进行Dropout处理后作为LSTM的输入进行处理,根据LSTM结构调整输入序列完成前向传播过程,最后经过输出单元将LSTM模块中的隐层进行输出。
3 实验及结果
3.1 数据集
本文实验是在UCF-101数据集上进行的,该数据集全部从YouTube上收集,包含101个类别共13320个视频片段。
3.2 实验细节
本文实验环境为:处理器:Intel Core i7-6700HQ,显卡:GTX960M,内存:16G,操作系统:Windows10,编译平台:Python、PyTorch1.2.0。
(1)数据预处理。本文首先对UCF-101数据集进行训练集和测试集的划分,然后进行关键帧的提取工作。其中训练集和测试集的比例为4∶1并对数据集进行随机打乱处理,有利于提升模型的健壮性,关键帧采用随机选取的方式并以大小为224×224的图像作为输入。
(2)模型训练。本文提取空间特征是选用嵌入注意力机制的ResNet50网络,移除最后的全连接层和全局平均池化层。模型的训练过程总共300个epoch,batch_size为32,优化器使用Adam,dropout为0.4,学习率为0.0001。
(3)参数优化。训练过程中batch_size、epoch、dropout和网络深度对准确率影响较大。Batch_size越大,输入神经网络的数据量越多,模型的拟合能力越强,当超过一定值,模型的预测效果会向差的方向变化。使用mAP对实验结果进行评估。其中不同神经网络层数下使用不同的Dropout进行训练的结果如图2所示。

图2 不同网络层数在dropout变化下准确率变化情况Fig.2 The accuracy changes under dropout changes at different network layers
可以看出,相同Dropout条件下,mAP通常会随网络层数的加深而增大,因为卷积神经网络的层数会影响视频的特征提取精度;同一层数卷积神经网络模型下,mAP值随着Dropout的增大而增大,当到达一定大小后,随着mAP的增大反而会减小。其中,在进行的对比试验中,当卷积神经网络层数为50且Dropout=0.4时,mAP得到最大值0.94。
3.3 实验结果
最后为了进一步验证本文工作,与之前的方法进行对比结果如表2所示,可以看出,本文在UCF-101数据集具有较高的准确度,证明了本文算法的可行性。
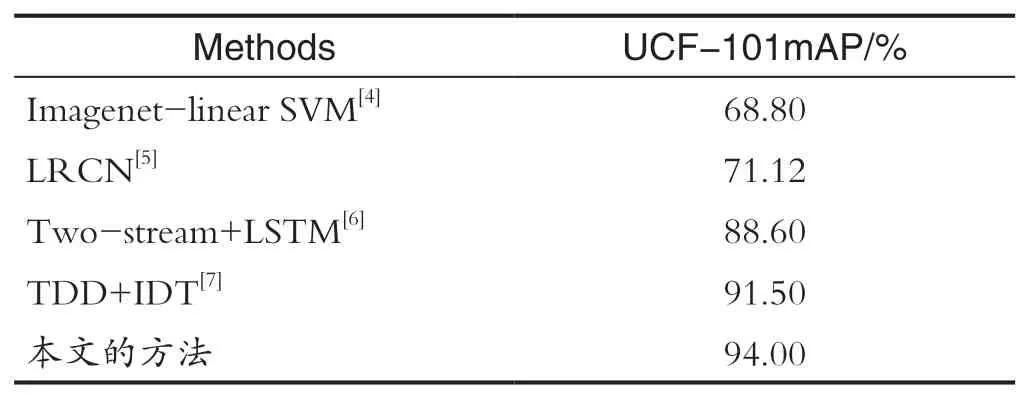
表2 不同算法在UCF-101数据集准确率对比Tab.2 Comparison of accuracy of different algorithms in UCF-101 data set
4 结语
针对不同视频帧对表达视频内容的贡献度和得到的视频特征不能充分表示该视频的特征信息和视频时序信息的特点,本文采用基于注意力机制的视频检索方法,通过卷积神经网络融合注意力模块进行视频空间特征信息提取、双向LSTM实现视频时序特征提取,可以自动为更重要的信息赋予更高的权重,提高模型的鲁棒性和对视频内容的表达能力,减少过拟合程度,实现精准识别。在UCF-101数据集上进行训练,完成使用不同网络层数进行试验效果对比工作,证明了将注意力嵌入卷积神经网络获取的语义特征输入到LSTM中使得网络整体性能得到提升,同时准确率也得到了提升。
