基于YOLOv5网络模型的火焰检测
2022-05-05涂沛驰傅钰雯熊宇璇杨健晟
涂沛驰,傅钰雯,熊宇璇,杨健晟
(1 贵州大学 电气工程学院,贵阳 550025;2 贵州交通职业技术学院 物流系,贵阳 550025;3 贵州大学 外国语学院,贵阳 550025)
0 引 言
近年来,随着现代工业的不断发展,发电站的发电量与日俱增。其中,燃煤发电作为主要的发电方式之一,有着十分重要的地位。在煤矿的开采过程中,会伴随着采出一种伴生资源煤层气,煤层气俗称瓦斯。在煤矿的开采过程中,如果将瓦斯直接排放至大气中,将会产生十分严重的温室效应。研究发现瓦斯热值高于通用煤1~4倍,与天然气相当,且燃烧后较为纯净,不会产生工业废气。因此,瓦斯可以作为一种良好的工业化工发电的燃料,但当瓦斯中空气浓度达到5%~16%时,遇到火焰会发生爆炸,这也是瓦斯发电站爆炸事故的根源。在瓦斯发电站中,火焰可能导致严重安全事故的发生,目前大多数工厂仍采用人工巡检的方式对瓦斯发电站进行检查,巡检效率会随着时间的延长而降低;由于火势蔓延十分的迅速,人工巡检很难早期发现并及时扑灭火焰。因此,急需一种能实时定位、识别火焰的方法来监测瓦斯发电站内可能出现的火焰。
与人工巡检监测火焰的方式相比,利用计算机视觉检测火焰具有更高的效率。张汝峰等人以及苏展等人将火焰图片经过图像预处理操作后,再通过采用RGB、GBR与HSI两两结合的颜色模型,根据火焰的颜色、亮度等进行检测;何爱龙等人采用视频检测及图像处理的方法,通过将火焰图片进行预处理后提取火焰区域,并选取其中较为明显的火焰特征构建火焰特征工程,进行火焰的识别;侯易呈等人通过采用Faster R-CNN(Faster Region-Convolutional Neural Networks)网络与深度残差网络相结合的方法提取火焰特征,采用激励网络减少相关度较低的冗余特征,最后使用多尺度特征融合结构,丰富深层特征,以此来提高火焰识别的精度。但以上方法,对火焰的检测主要集中在对火焰特征的提取,进而以良好的准确率识别检测火焰,但在现实生活中,火势蔓延十分迅速,故火焰检测的实时性也是十分重要的一个环节。
随着深度学习的发展,基于深度学习的目标检测算法发展迅速,其主要分为单步目标检测算法以及双步目标检测算法。双步目标检测算法分为图像的识别和定位两个步骤,首先使用区域候选算法从待检测图像中提取候选区域;通过卷积神经网络对图像进行特征提取及分类识别。双步目标检测算法具有较高的准确率,但是计算量大,运算速度慢,针对于实时性要求高的目标检测不太适用。单步目标检测算法是将提取候选区域以及分类识别两个部分融合到一个网络里,直接由输入图像得到图像中存在的物体类别及位置。单步目标检测算法,在精度不会丢失太多的同时兼具了运算速度快,实时性好,对硬件要求低等优点,被广泛应用于目标实时检测领域中。
1 YOLOv5模型的组成及原理
YOLO(You Only Look Once)算法是一种单步端到端的目标检测算法,将提取候选区域及识别分类融合在一起,具有检测速度快、模型文件小等优点。通过更新迭代,现如今更新到了YOLOv5模型。YOLOv5模型共有YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x 4个版本,其中YOLOv5s网络是YOLOv5系列中深度最小、模型文件最小,是其他版本网络的基础。综合检测的实时性与模型准确性,本文采用YOLOv5s网络作为火焰检测的网络。
YOLOv5的网络架构主要可分为4部分,依次为输入端、骨干网络、颈部网络、输出端。
1.1 输入端
YOLOv5网络的输入端采用Mosaic数据增强、自适应锚框计算、自适应图片缩放3种算法。
Mosaic数据增强方法在输入的数据中随机选取4张图片进行随机的缩放、裁剪及排列。可将数据扩容,使得网络的鲁棒性得以提升;其次,通过图片的拼接可以一次计算4张图片的数据,从而提升模型的训练速度,降低模型的内存要求。Mosaic数据增强操作原理如图1所示。

图1 Mosaic数据增强操作原理Fig.1 Mosaic data enhancement operation principle
自适应锚框计算方法是在建立的数据集中设定指定长宽的锚点框,以输入图像的每一个像素作为中心点,以此生成多个边界框。当网络进入到训练阶段时,会在初始锚点框上输出与其对应的预测框,计算其与真实框的差距,进行反向更新,进而迭代更新网络参数。
1.2 骨干网络
YOLOv5网络的骨干网络采用了Focus结构及CSP(Cross Stage Partial)结构。Focus结构对输入图片切片操作,每一张图片采集某个像素点的值后,不采集相邻像素点的值,而是中间隔开一个像素点,采集下一个像素点,从而扩充输入通道数;最后,将获得的拼接图片通过卷积操作,得到没有特征信息丢失的二倍下采样特征图。Focus切片操作原理如图2所示。
2.1.1 主茎。“鸿福金钻蔓绿绒”及其亲本的主茎均为圆柱形,“鸿福金钻蔓绿绒”主茎上部为红紫色,下部为黄绿色,茎节为红紫色,其亲本为黄绿色,茎节为红紫色(表2)。种植12个月时“鸿福金钻蔓绿绒”的平均主茎长为12.3 cm,主茎粗为2.5 cm,其亲本的主茎长为12.3 cm,主茎粗为2.6 cm,差异不显著(表3)。
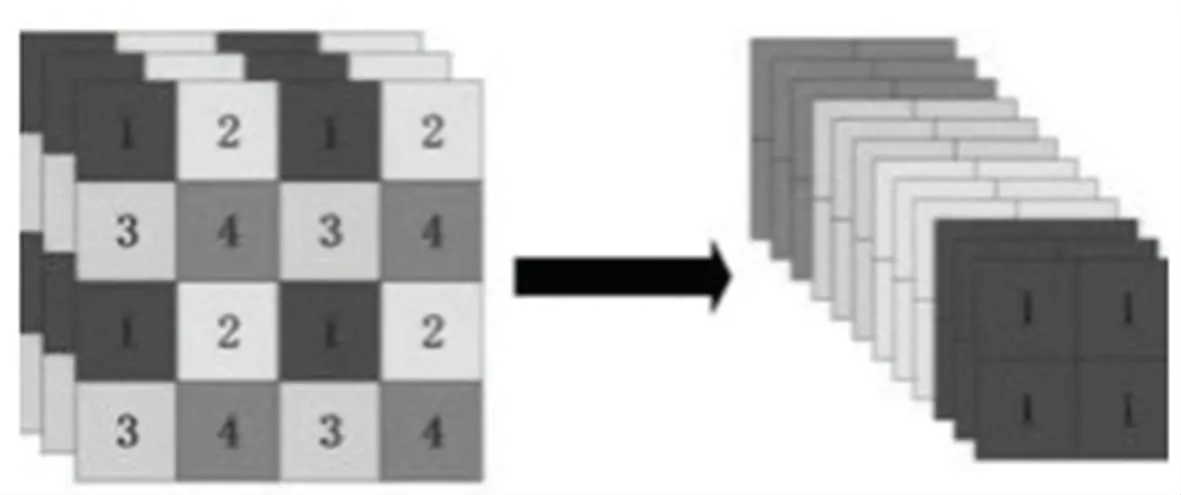
图2 Focus切片操作原理Fig.2 Focus slicing operation principle
以YOLOv5s位列,输入图像尺寸为640×640×3,将图像输出至Focus结构中,通过切片操作,得到320×320×12的特征图,最后经过卷积核为32的卷积层,得到320×320×32的特征图。
CSP结构在Yolov5s网络中有两处应用,Csp_1结构应用于骨架网络中,Csp_2结构则是应用于颈部网络中。Csp_1结构中包含了CBL(Conv+BN+LeakyRelu)模块以及多个残差组件(Res unit)。CBL模块与残差组件的组成,如图3所示。
残差组件是借鉴了Resnet网络中的残差结构,应用于较深的网络中,可以解决网络层数过深而导致的梯度消失的问题。Csp_2结构中,使用普通的CBL模块代替了残差组件。Csp结构用两条支路,通过支路实现特征融合,提取更为丰富的特征信息。

图3 CBL模块及残差组件的组成Fig.3 Composition of CBL module and residual components
SPP(Spatial Pyramid Pooling)是为了解决卷积神经网络输入图像数据大小固定的问题而提出来的一种结构,卷积神经网络是由卷积层和全连接层构成,卷积层对输入图像数据大小没有规定,但第一个全连接层对输入图像的数据大小是有要求的。因此卷积神经网络基本上对输入数据的大小有所规定,针对许多数据高宽比不固定的情况,如果直接对图片进行切割,那么会存在丢失特征信息的可能性。因此,为了解决上述问题,提出了SPP结构,SPP结构工作原理如图4所示。YOLOv5中引进了SPP结构,用来解决图像由于裁剪、缩放等操作而引起的特征丢失等问题。

图4 SPP结构工作原理Fig.4 SPP structure working principle
1.3 颈部网络
YOLOv5网络的颈部网络采用的是FPN(Feature Pyramid Networks)+PAN(Path Aggregation Network)结构。FPN是自顶向下的,将高层特征通过上采样和低层特征做融合得到进行预测的特征图。FPN是自顶向下的,将高层的强语义特征传递下来,对整个金字塔进行增强,不过只增强了语义信息,对定位信息没有传递,而在FPN的后面添加一个自底向上的金字塔,是对FPN的补充,将低层的强定位特征传递上去。
FPN就是把深层的语义特征传到浅层,从而增强多个尺度上的语义表达。而PAN则是把浅层的定位信息传导到深层,增强多个尺度上的定位能力。FPN+PAN结构如图5所示。

图5 FPN+PAN结构示意图Fig.5 Schematic diagram of FPN+PAN structure
1.4 输出端

其中,A为预测框与真实框的最小外接矩形,为A中不属于预测框与真实框的部分。当真实框与预测框越接近时,越小,从而使得越小。
YOLOv5网络处于预测阶段时,会产生许多围绕同一目标的预测框,通过使用非极大值抑制使得预测框合并。将GIoU损失函数与非极大值抑制结合可以更好的识别图像中有重叠的目标。
2 数据采集及数据集制作
2.1 数据来源
本文的火焰图片数据来自公开数据集以及手动拍摄两部分,手动拍摄的数据为丁烷点火器生成的火焰视频,将视频截取成火焰图片。此次数据共采集600张火焰图片,通过数据增强的方法将原有数据进行旋转及亮度变换等操作,扩容至3000张图片,火焰数据图片如图6所示。

图6 部分火焰图片数据Fig.6 Part of the flame picture data
2.2 数据集建立
将得到的火焰图片数据使用Labelimg软件进行标注。在标注过程中,尽可能的选取完整的火焰区域,防丢失图像特征。本次实验对象为火焰一个类,通过手动标注后自动生成txt文件,标签文件中包含了标签类别、预测框坐标等信息。标注结果如图7所示。

图7 火焰数据标注图像Fig.7 Flame data labeled image
火焰样本数据标注完成后,通过脚本文件自动划分成训练集和测试集。以便后续输入模型训练。
3 实验结果及分析
3.1 实验环境
此次实验采用Windows10专业版操作系统,Pytorch1.7版本框架,集成开发环境为Pycharm。平台硬件参数如下:CPU为i9,内存大小为32 GByte,GPU为Nvidia QUADRO RTX4000。
3.2 实验结果
本文实验采用YOLOv5目标检测模型,总体训练轮数设置为200轮,分组大小设置为20,学习率设置为0.001。网络训练过程中,训练前期模型的损失函数迭代收敛速度较快,随着训练次数的增多,损失函数收敛速度逐渐趋于缓和,最终实现收敛,并结束模型的训练。训练完成后将保存一个最新训练的权值文件与一个最优权值文件。网络训练结果如图8所示,可以看出,值为096。

图8 模型训练结果Fig.8 Model training results
平均精度与召回率是目标检测中常用的评价指标,其计算公式如式(2)~(3)。

其中,表示将正类别预测为正确类别的个数;表示将负类别预测为正确类别的个数;表示将正类别预测为负类别的个数。
将训练好的权重文件导入模型之后,输入火焰图片进行识别,识别所耗时间为0.245 s,识别效果如图9所示。

图9 火焰识别效果图Fig.9 Flame recognition effect diagram
从图9可以看出,针对不同情况下的火焰,训练后的模型对其识别后置信度为91%-93%,因此,经过训练的YOLOv5模型对火焰的识别具有较高的准确性,同时训练完成的检测模型兼具良好的实时性。
4 结束语
针对火焰检测存在实时性不足的问题,本文提出了基于深度学习的火焰检测方法,使用YOLOv5s目标检测算法模型,通过3000张火焰图片数据的训练后,使用训练结果最优的权重参数文件。实验后期采用火焰图片数据对模型进行检测,具有较高的准确性和良好的实时性,可以满足实时性要求较高的火焰检测场景。
