IP化超高清视频解析和监测系统设计及实现
2022-05-03王晨颜金尧蔡洋
王晨,颜金尧,蔡洋
(中国传媒大学媒体融合与传播国家重点实验室,北京 100024)
1 引言
1.1 研究背景及意义
对于超高清(4K、8K)专业媒体流信号域的实时制作播出,传统SDI 架构局限性大,传输速率较低,需要的电缆数量多且维护成本高,一根电缆仅可承载一路SDI;SDI信号传输距离有限;可替代性弱。不同于发展缓慢、成本较高的SDI 技术,以太网带宽和交换能力发展迅速,目前已经发展到400Gbps 以上,具有传输速度快、结构简单、传输距离远、成本低、兼容性强、覆盖范围大、管理便捷、充分利用IP 网络等多个优点[1]。
因而广电制播系统的采集、制作、播出等从传统的SDI 架构逐渐向全IP 化架构迁移。为促进IP 技术在实时视音频领域的应用,目前行业内基本达成共识采用SMPTE 2019 年发布的ST 2110 标准系列。ST 2110 系列标准定义了视频、音频、其他数据在IP 网络中的单独封装、分发。研究专业媒体流IP化的意义重大,可打破现有网络中媒体制作播出的技术壁垒,充分利用IP 的特点,将所有信号接入IP 中心矩阵,建立IP资源池,实现大带宽、多格式、跨域协同、远程制作,为未来的全文件共享、云化做准备。
1.2 国内外技术发展现状与研究
2014 年,ESPN 建立了世界上第一个广播电视直播IP 中心系统[2],该系统最初采用ST 2022-6 及ASPEN 的IP 信号标准。2020 年,BBC 威尔士新中央广场总部使用Grass Valley 的技术支持全球最大的SMPTE 2110 IP 工作流[3]。截止到2020 年底,全球范围内已知规模最大的IP 系统是由NBC 部署的Telemundo 超大型IP 化数据中心。CNN 新总部大楼实现IP 化,成为全世界首个完全基于SMPTE 2110 IP 网络的重要广播基地[4]。
在国内2018 年广东台建设了一个4K 频道IP 总控系统[5]。2018 年爱奇艺创意制作中心建成IP ST 2110 总控系统。2018 年中央广播电视总台建设了2条完整的4K 生产线(其中1 条为全IP 化4K 生产线)。2019 年总台首次在国庆活动采用全IP 方式实现超大规模4K 和高清信号的无损高质量回传和信号分发。2019 年中国第一辆符合ST 2110 标准的单流4K 超高清全媒体转播车在贵州台交付[6]。2021 年中央广播电视总台在春晚期间建设全IP 化8K 信号制播生产环境,实现了4K、8K 和高清的并行直播。2021 年第十四届全运会期间,总台转播系统的核心业务调度系统实现全IP 架构,画分和控制调度系统也实现全IP 化。
在整体IP制播系统环境下,诸多国外厂家和研究人员不断研发相关IP 硬件设备和技术来促进广播行业的全IP 化。在视频信号IP 化、解析播放视频IP 信号等方面的设备类型多样。 SONY NXLKIP50YNXLK-IP51Y 网关、GV 网关、ROSS Raptor 网关等国外设备以及仅有的国产网关格非IPGate 均可实现将SDI信号根据ST 2110标准封装为IP流来通过网络传输。Imagine SNP、LAWO 画面分割器、SONY切换台等均可接收解析IP信号,并通过显示器进行视频画面观看。视频监测分析方面,目前仅有Tektronix(泰克)公司的PRISM 示波器提供IP 工作流媒体技术指标分析功能,可以详细诊断ST 2110 流量问题。此外,N. Ranasinghe 提出了一个可扩展的FPGA 架构,用于ST 2110 端到端的专业视频解决方案,是第一个公开发布的此类硬件架构[7]。
1.3 研究内容与主要贡献
现阶段电视台和各大厂家主要通过硬件网关来实现SDI视频的IP化和IP视频信号监看,尽管硬件功能较为齐全,但这些国外的硬件设备价格昂贵,连线复杂,采用硬件板卡烧制固定程序,通用性和灵活性不够。
本文面向ST 2110-20 标准,实现了基于RTP 流的未压缩基带视频在IP 网络中的解析播放、监测分析的软件系统;设计了一套可以运行在高性能通用计算机上的实时IP 解析监测的软件系统装置,大大提高了性价比,打破了硬件和价格壁垒,更利于灵活研究IP 视频信号。在IP 视频解析方面,本文提出设计了缓存算法阻塞队列长度设计和多线程并发来实现视频解析播放。在IP 视频监测分析方面,本系统监测分析丢包率、帧频分布、帧间隔分布、首包处理时延、端到端时延5 个技术指标和主观观看画面效果。通过技术指标和主观效果的对比分析,本系统的系统设计及实现效果,在一定程度上可对比国外专用设备PRISM 示波器的视频信号分析功能,在制播IP 化设备国产化和通用化方面,同时对融入电视制作域内的整体监控系统,多流监测方面有重要意义。实验结果分析证实本文创新提出的IP 视频阻塞队列长度设计算法是有效的。
2 系统设计
2.1 系统框架设计
一套完整的基于ST 2110标准的IP化视频流采集解析监测系统设计框架如图1所示。视频信号源产生专业媒体视频,封装成ST 2110 标准的IP 流并通过网络进行传输。本系统利用网卡接收IP视频流信号,根据自主设计的阻塞队列长度算法,使用阻塞队列实现实时数据缓存及处理机制可控制化,采用多线程并发的方式,低门槛与低成本实现了IP基带视频流的实时解析与系统监测,解决IP视频系统的数据处理透明可控制化、视频流解析技术通用化的问题。
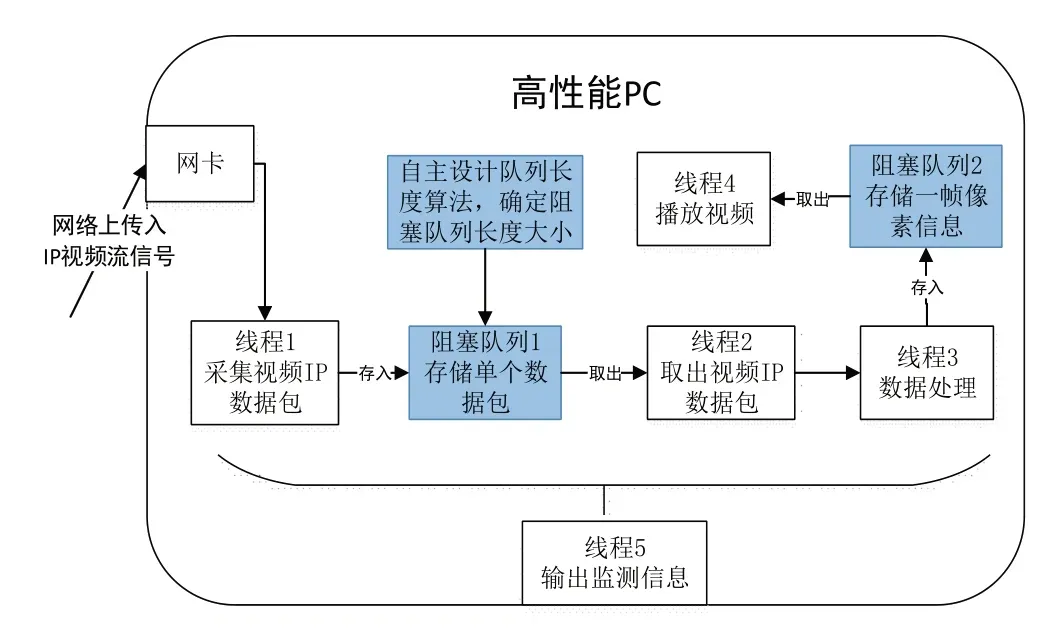
图1 系统设计框架
2.2 阻塞队列长度算法设计
在实验系统设计中,数据包的存储采用了阻塞队列实时缓存而非直接写入本地文件,节约了大量的写入和读取磁盘的时间。阻塞队列采用先进先出模式,当队列已满时会等待队列中的数据消耗,当队列为空时则等待数据填充,可以解决某个时间段内产生数据的线程与消耗数据的线程之间速度不匹配的问题。
存储数据包的阻塞队列1长度的大小和视频监测系统的丢包率、端到端时延的大小密切相关。队列越长,帧均丢包率越小,时延越大;队列越短,帧均丢包率越大,时延越小。
针对队列长度,本文自主设计一种算法,根据不同视频流格式在网络条件下的输入输出速率变化,设计相应的队列长度,来得到低丢包率和低时延。该算法适应于高清、超高清等不同清晰度的视频格式,但在超高清格式中只有逐行扫描格式。
阻塞队列的输入速率λ是指每秒采集经网络传输后到达队列的视频数据包的速率,可由计算机根据一段时间内接收的数据包个数n_input除以相应时间t_input得到;输出速率μ是指视频播放时每秒解析数据包的速率,同样可由一段时间内解析的数据包n_onput除以相应时间t_onput得到。在实际网络情况中,网络状态变化复杂,需根据队列长度算法调整队列长度,来保证较低的丢包率和时延。
当输入速率大于输出速率时,队列长度L1 等于视频流输入速率λ与输出速率μ的差乘实时视频时长duration:
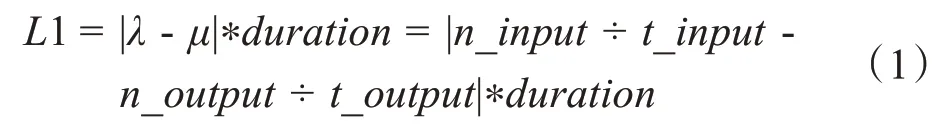
当输入速率小于等于输出速率时,队列长度L2等于抖动jitter。抖动是指数据包延迟的变化程度,变化具备随机性,队列的输入和输出都有抖动。因此本算法采用一种最佳抖动时延处理,通过实际测量无限长队列长度情况下,在系统稳定时的最大抖动队列长度jitter,并选择该jitter作为阻塞队列长度。本文实验中采取此方法确定队列长度。

算法伪代码如下:

算法1:阻塞队列长度算法输入:输入速率和输出速率1.If μ<λ:2. L = |n_input ÷ t_input - n_output÷t_output|*duration 3.else if μ>=λ:4. L = jitter 5.end;输出:阻塞队列长度L
2.3 解析监测原理
如图1 系统设计框架所示,该部分可在VS 2019开发环境下编写C++程序完成。
经多次实验发现,采集、解析、播放几项操作均需耗费较多时间,如果按顺序依次执行,则最终呈现的视频播放效果差,画面切换缓慢。因此需采用多线程并发的形式来提升程序的运行速率,并通过阻塞队列共享数据,进行线程间通信。程序中视频数据包的采集缓存、缓存取出、解析、播放与监测可以分成5 个并行任务,因而采用5个线程形式实现,提高程序运行效率。线程1 和线程2、3 共享阻塞队列1 中数据包。线程3和线程4共享阻塞队列2中完整帧像素数据。
线程1 可利用Winpcap 嗅探网卡捕获视频IP 数据包。Winpcap是Windows系统下捕获和过滤底层网络数据包、发送原始数据包到网络上、收集网络流量与网络状态的统计信息的一个开发库[8]。捕获数据包的主要步骤为:首先创建一个网络设备链表以获取本机的适配器,找到并打开网卡来捕获完整数据包;设置混杂模式、内核缓存区和用户缓存区,以解决抓包时的丢包漏包;调用回调函数不断地捕获数据包,并在回调函数中不断将数据包存入阻塞队列1中。
线程2 取出视频IP 数据包。首先根据IP 数据包类型初始化。初始化后,线程2 按存入顺序不断地从阻塞队列1中取出以太网数据包,进行结构体赋值。
线程3进行数据处理,提取数据包中的视频信息,拼接出视频帧的像素信息。首先根据视频内容设置视频的帧率、宽高、色度采样等参数,新建一帧图像缓存区(例如采样格式为4:2:2 的高清缓存区大小为1920*1080*2)。然后根据ST 2110-20 协议读取数据包SRD 字段中的F、SRD Row Number、C、Offset 的值[9],读取方式为数组偏移,偏移量由字段所在的字节位置距数据包包头的距离决定。数据包从外到内的封装依次为以太网/IP/UDP/RTP/ST 2110-20 有效载荷头/视频像素数据。若数据包的首字节用pkt[0]表示,第一个SRD F位于ST 2110-20有效载荷头的第5个字节中的第一位,即数据包的第58 个字节(58=14+20+8+12+4),即pkt[58]中的第一位。当以上SRD 字段全为0时,为图像起始行;若不是,继续读取数据包,直至全为0。当图像起始行的数据包确定后,根据序列号依次读取同一帧图像的所有数据包中的像素信息,直到数据包标志位M 为1,通过相邻字节拼接恢复出相应比特(例10bit)的原始取样像素值元组,再结合SDL 显示图像的特性对像素值数据进行处理,以方便图像显示。最后根据采样结构将上述得到的图像对应像素信息Y、Cb、Cr 按照SRD 头部样本行中的Row Number、Offset、Length 位置信息进行相应赋值,直到一帧图像缓存区完全被填满,即得到一帧完整图像,并将一帧完整图像数据存入阻塞队列2中。重复这个过程,不断将图像缓存区的新图像存入阻塞队列2。
线程4 播放视频SDL(Simple DirectMedia Layer),SDL 是一套开放源代码的跨平台多媒体开发库,它提供了丰富的控制图像、声音、输入输出的函数[10]。SDL 显示视频的流程主要可以分成两大部分:初始化和循环显示画面。首先按照顺序创建SDL 窗口、渲染器、纹理进行初始化,之后重复从阻塞队列2中获取一帧图像数据来纹理更新、渲染器渲染、视频显示。
线程5为输出监测信息,含阻塞队列实时长度、队列输入输出包间隔、丢包数、总包数、帧频、帧解析、播放及总间隔。
3 实验及结果分析
3.1 实验设置
实验过程中的物理拓扑如图2 所示,视频源由小米盒子和格式转换器BlackMagic 组成,SDI-IP 网关为ROSS Raptor、通过华三交换机和光纤实现数据包网络上的转发。小米盒子传输出含时间码内容的视频作为视频源,通过HDMI 线缆发送到BlackMagic。BlackMagic 可输出1920*1080 50p,4:2:2,10bit 的高清视频及3840*2160 50p, 4:2:2,10bit的4K 超高清视频。视频数据经SDI 同轴线缆传输到ROSS Raptor 网关,网关根据ST 2110-20 标准封装成在IP 网络中传输的数据包,数据包大小均为1262 字节,一帧高清4320 个数据包。数据包继而经由光纤和交换机在网络中灵活传播。高性能PC捕获数据包进行解析监测。

图2 实验物理拓扑
在超高清视频系统建设过程中,最开始主流方案是将一帧4K 完整图像分割成4 个子图像通过4 路3G-SDI 信号来传输,主要有2SI(2 Sample Interleave)和SQD(Square Division)两种传输模式[4],现电视台多用1路4K。为便于理解和减少实验复杂度,本文仅选取超高清4路中的1路无压缩高清视频IP流来进行实验。不同清晰度视频IP 化实现的原理同本实验相同,但当需要4路高清视频合成时,必须按照传输方式将4路3G-SDI链路的信号绑定在一起,且严格区分两端序号对应关系。
3.2 阻塞队列长度选择
数据包包间隔指两个连续数据包进入或离开阻塞队列的间隔。网络传输中,因为网络链路、拥塞情况、抖动、系统处理方式等因素,数据包到达和离开队列的间隔不一。图3展示了系统稳定运行后100万个数据包队列输入和输出的包间隔变化,可以看出队列的输入输出均有抖动,输入的抖动明显大于输出的抖动,说明数据流从网络到达系统阻塞队列的缓存后,抖动可以明显下降,证明了阻塞队列的必要性,通过阻塞队列的缓存可以使系统平稳地解析播放视频。队列输入和输出的包间隔平均值分别为4620ns和4611ns,与数据包生产时间间隔相当(4629ns),说明系统采集和处理数据包的性能足够。
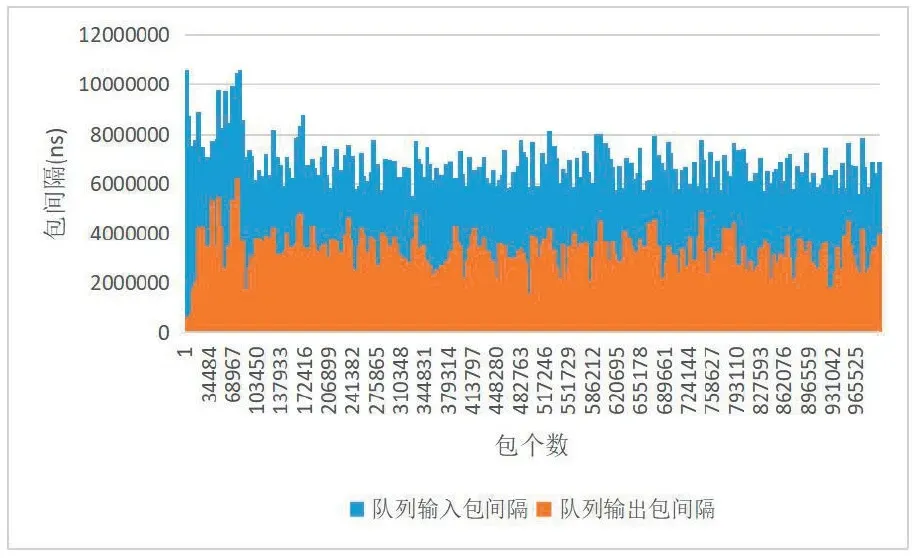
图3 阻塞队列输入输出包间隔抖动
实验中采用的视频源和网关平均20ms发送一帧视频信号,一定程度代表了输入速率。为简单测试本系统性能,实验时先缓存50帧视频内容,然后再进行视频解析播放,经测试系统可以平均14.5ms解析一帧视频,相对应代表输出速率,远小于20ms,说明系统性能足够好。但输入速率是前提,即使系统性能再高,输出速率也会受到输入速率的限制,由此得出本系统的输出速率大于等于输入速率。因此,阻塞队列长度采用公式2。
阻塞队列实时长度指在系统运行时阻塞队列1中的数据包个数。图4展示了在阻塞队列无限长的情况下,系统开始运行20s内,阻塞队列实时长度的变化。系统运行初始不稳定,队列长度大,最大值小于10000,平均值为1164.13。8s后,系统已经稳定运行,图5描述了8s-20s内系统平稳运行时的阻塞队列长度频数,图5中可以看出队列长度最大值小于2000,频数主要集中在0~800,800~2000时逐渐下降。因此,结合图4和图5,我们选择了1100、1500、2000、10000、无限长5个队列长度,来分别测试系统性能指标,选出合适的队列长度,并证明2.2节中阻塞队列长度算法的准确性。
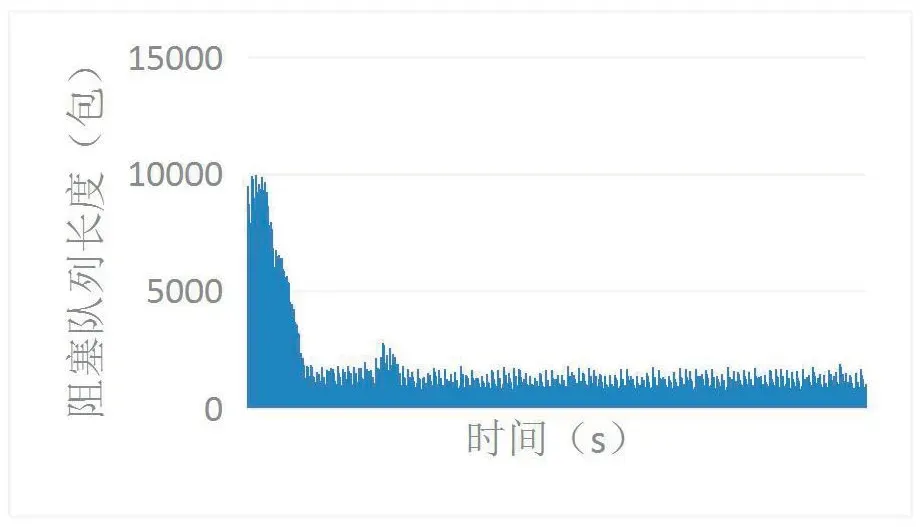
图4 阻塞队列实时长度变化
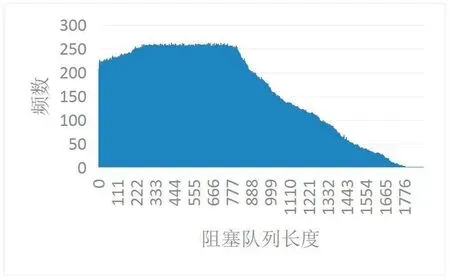
图5 阻塞队列长度频数图
3.3 系统监测指标分析
为更全面地衡量超高清IP化视频采集解析及监测的性能,从系统效率、数据完整性、传输稳定性、实时性几个方面提出了以下5个指标:丢包率、帧频分布、帧间隔分布、首包处理时延、端到端时延。通过5种阻塞队列长度的5个指标分析对比,确定当输出速率大于等于输入速率时阻塞队列长度的大小。
(1)丢包率
从系统开始运行后,由于网卡抓包或系统解析错误导致丢失的数据包数,与数据包总数的百分比值,称为丢包率。
图6描述了系统运行1分钟时,5种队列长度的丢包率。当队列长度大于等于2000时,丢包率为0。2000为系统稳定运行时队列长度的最大值,该值为1分钟内系统不丢包的5种队列长度的最小值。经测试发现,当系统运行时间更长时,队列长度2000、10000、无限长也会发生丢包,零丢包率持续时间随着队列长度增长而增加,但均在丢包较少时不影响观看效果。
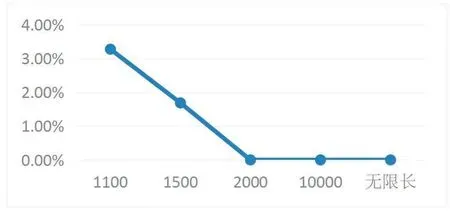
图6 丢包率对比
当队列输入的抖动过大,数据不断堆积,当队列被堆积数据填满时,数据写入线程休眠,线程休眠期间不再接收新数据。当阻塞队列中的数据被消耗一些后,写入线程重新工作,此时接收的数据与先前填入的数据便有了断层,休眠期间本应接收的数据丢失了,因而产生了丢包。当阻塞队列长度越长时,阻塞队列可容纳的数据包越多,允许的突发抖动也更大,从而丢包率小。
(2)帧频分布
在系统开始运行后,每秒视频播放帧数的分布情况称为帧频分布。
图7中描述了系统开始运行后20s内帧频的变化。除队列长度1100和1500外,各阻塞队列长度在视频开始第1s,系统不稳定,帧频均不等于50,第2s及之后帧频稳定在50,系统达到稳定。队列长度1100和1500帧频均一直未达到稳定,在49上下变化,产生此的原因与系统丢包导致的丢帧密切相关。
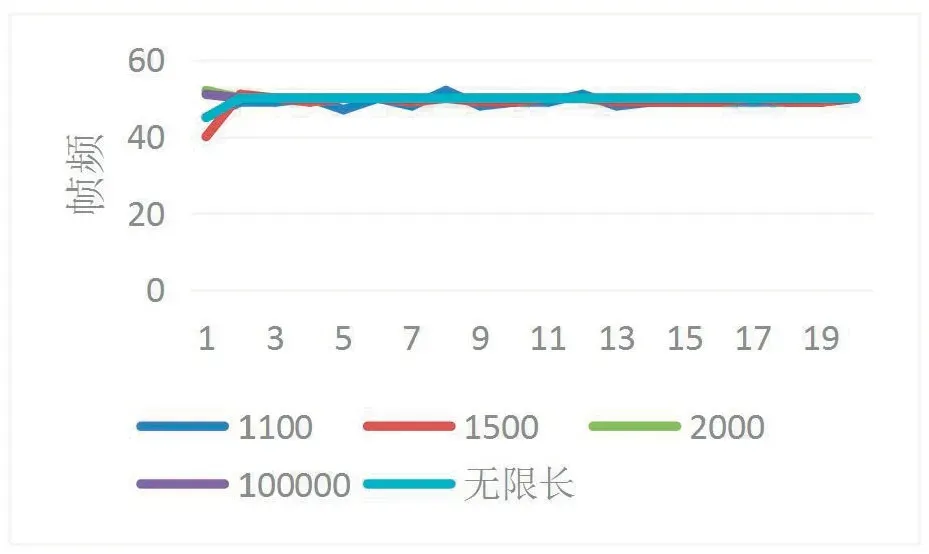
图7 帧频对比
(3)帧间隔分布
在系统平稳运行状态下,即帧频稳定在50时,当前帧解析完毕与上一帧解析完毕之间的时间间隔为帧解析间隔。
当前帧播放完毕与上一帧播放完毕之间的时间间隔为帧播放间隔。
当前帧解析播放完毕和上一帧解析播放完毕间的时间间隔为帧全间隔分布。
帧全间隔分布和队列长度关系较小,只与数据解析播放线程本身的效率有关。因此,在研究帧的解析、播放和全时间间隔之间的关系时,仅采取了队列长度10000时的帧间隔数据。
图8描述了系统稳定运行后60帧的帧全间隔、解析间隔、播放间隔的数值变化,平均值依次为19.48ms、19.4ms、4ms。其中需要注意的是,在3.2中指出系统平均14.5ms解析一帧视频,但是在本实验中帧解析间隔平均19.4ms,这是因为视频源本身为50p,每帧20ms生成的速率限制了更快的帧解析时间。全间隔包括解析和播放两步,全间隔的平均值小于解析和播放间隔之和,这说明加入阻塞队列2实现解析和播放线程分离,在不同的CPU上同时运行后,系统运行的时间只取决于运行时间长的线程,即解析线程,缩短了解析和播放顺序运行的时间,提高了程序运行效率。在图8中全间隔和解析间隔变化趋势相同,全间隔比解析间隔变化慢1帧,两者均值仅差0.08ms,从数据上也验证了系统运行时间主要依赖于耗时最多解析线程的变化。
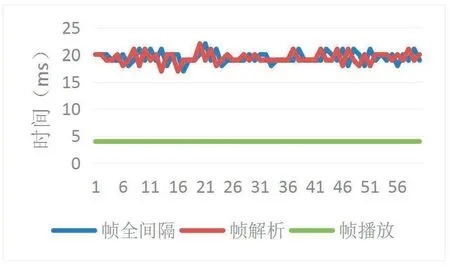
图8 帧间隔对比
(4)首包处理时延
在系统网络拓扑稳定的前提下,系统开始运行后抓取到第一个数据包与第一个数据包所属视频帧解析完毕之间的时间间隔,首包处理时延可以在一定程度上反映系统初始化效率以及数据解析效率。
首包处理时延=首帧解析完毕时间-首包捕获时间。
图9表示5种队列长度各20次实验的首包处理平均时延,从图9中可以看出首包处理时延整体趋势随着队列增长而增大,从队列长度2000开始,首包处理时延增加明显。由图4可知,在系统初始化时,队列里的长度最长,系统初始化时队列长度最大到10000。当阻塞队列长度为2000时,系统初始化时队列长度最大到1999。因此设置队列长度越长,在系统初始化时阻塞队列里的数据包就会越多,系统未及时处理,进而导致首包处理时延增大,而在系统稳定后,各阻塞队列长度中的实时队列长度则一直在0到某个范围稳定变化。
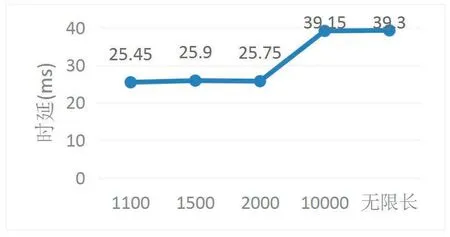
图9 首包处理时延变化
(5)端到端时延
在系统平稳运行状态下,端到端时延为视频数据源端与视频播放端二者之间的实时时间差,通过该指标的分布情况可以看出整个系统层面的整体运行效率。
端到端时延=发送时延+传输时延+处理时延。
图10为各队列长度在系统开始运行1分钟内20次的端到端时延对比,平均值依次为0.72s、0.61s、0.13s、0.15s、0.14s。队列长度1100和1500的平均端到端时延过大的原因和丢包率大密切相关。队列长度大于等于2000时,端到端时延相差不大。在系统稳定后,实时队列长度(最大值2000)小于设置的阻塞队列长度时,系统的处理性能足够,可以实时处理完阻塞队列中的数据包,故而端到端时延相差不大。
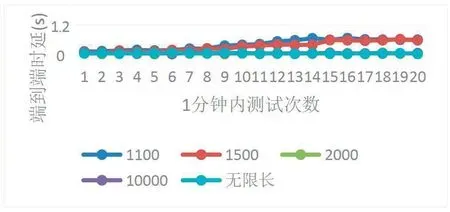
图10 端到端时延对比
(6)综合指标分析
通过以上分析,各阻塞队列长度可得出表1 的信息,其中数字1-5 代表该指标在几个队列长度中的系统性能分数,数字越大,系统性能越好。

表1 各队列长度指标性能比较
在5 种队列长度中,1100 和1500 因为产生丢包,除首包处理时延外,其他指标均表现较差,可首先排除这两个长度。剩余的三个队列长度在帧频分布上性能一样;在丢包率上,1分钟内,三者一样好,但持续时间更长的情况下,无限长最好;在首包处理时延和端到端时延上,2000表现最好,且综合得分最高。
因此,在考虑系统初始化快并且实时性高时,阻塞队列长度最佳为2000,即jitter为2000。仅考虑系统在长时间内(大于1 分钟时)的丢包率性能,阻塞队列长度最佳为无限长。而从实际出发,队列无限长即为电脑内存,存在着不定性,阻塞队列长度越大,占用的内存资源也越大,且如果阻塞队列消耗速率在一段时间内持续小于放入速率,端到端时延将越来越大。因此,在本实验环境下,阻塞队列的输入小于等于输出速率时的阻塞队列长度确定为2000 最好,即L=2000。
(7)视频解析监测结果
在阻塞队列长度为L=2000 的情况下,实验结果视频播放画面截图如图11 所示,画面显示完整,播放流畅无卡顿、画面与视频源相比得到良好的还原。

图11 实验播放效果图
4 总 结
制播全IP化符合广电和媒体行业未来发展方向。本文在通用计算机环境下设计和实现了ST 2110-20标准IP视频信号的采集、解析、播放和监测分析,大幅度提高了系统的工作效率。实现中共采用5 个线程:Winpcap 采集视频流数据包,并存储在阻塞队列1;从阻塞队列1 获取数据包;解析数据包获取完整图像像素信息,存储在阻塞队列2中;从阻塞队列2获取整帧图像像素信息,利用SDL 实现视频播放;输出监测信息。
本文设计了多线程并发和阻塞队列长度缓存算法,根据阻塞队列长度算法获得阻塞队列长度可以为整个IP系统得到低丢包率、低延时。在阻塞队列的输入速率小于等于输出速率时,通过5 种队列长度在丢包率、帧频分布、帧间隔分布、首包处理时延、端到端时延5 个监测技术指标下的性能对比,确定了本实验的阻塞队列长度为2000,该队列长度在5 个监测技术指标中整体性能良好。由此我们也可得出在无限长阻塞队列前提下,系统稳定运行后的最大抖动队列长度即为可设置的最佳队列长度,2.2 节的阻塞队列长度算法得证。
