加权属性K-means聚类在高速公路养护路段划分中的应用
2022-04-27卢军源刘宇马进
卢军源 刘宇 马进

摘要:文章介紹了加权属性K-means聚类算法在路面养护工程中的应用,提出了基于该算法的高速公路路面技术状况分析及养护路段划分决策,并以广西某高速公路养护工程为例,对传统K-means和加权属性K-means聚类分析法在路面技术状况属性特征类似的每百米路段分类中的应用进行了比较。结果表明:加权属性聚类算法比传统的聚类算法更有效、可靠,可为今后高速公路养护工程项目提供计算分析和科学决策参考。
关键词:数据挖掘;聚类分析;技术状况;加权属性;养护决策
中国分类号:U418.1
0引言
在养护工程实际工作中一般以每公里路段作为技术状况评定或实施养护工程单元,且路况评定指标是以每公里为单元的平均值计算,不能反映病害的具体位置。若以每公里及更长里程为单元进行养护分析和病害处治,不利于精准地实施养护、维修的科学决策,必然会造成资源的浪费。况且现行养护技术规范内的养护决策树技术指标阈值是以路网级的养护水平制定的,未必能够适用于项目级养护工程。因此,依据大量的路况数据将养护路段细化划分,有利于管理者决策和实际施工[1]。在大数据时代,数据挖掘应运而生,聚类分析作为数据挖掘的重要分支,在信息化时代有着举足轻重的作用[2]。
1聚类分析方法理论
1.1传统的K-means聚类算法
K-means聚类算法是由J.B.MacQueen在1967年提出的基于距离的聚类算法[3],但是没有考虑不同属性特征。其计算方法步骤如下:
2在路面养护工程的应用
2.1加权属性K-means聚类方法
基于传统K-means聚类分析并改进欧氏距离计算方法[4],有针对性地设定权重值,突出路面使用性能属性,实现快速归纳不同路段位置的综合病害特征,依据该特征进行路段划分,可为相应的养护决策提供参考。加权属性改进K-means聚类分析算法流程如图1所示,其中k值和权重值ω的选择成为聚类计算的关键。
2.2特征属性数据标准化
由于路面技术状况检测指标如平整度、破损率、横向力系数和车辙深度等在数值上不是一个量级,根据欧氏距离计算原理,直接进行聚类计算,量级大的样本属性如横向力系数的影响最大,最终聚类结果会偏向该属性,其他各类中属性无明显划分,会陷入局部优解。因此,在进行聚类分析前需要对不同的路面技术状况指标数据进行标准化。
2.3聚类参数选择方法
2.3.1聚类k值的选择
在K-means聚类分析方法中[5],k值是人为设定的,往往需要领域专家结合实际状况和需求定义。在高速公路养护工程中,基于路面技术状况分项指标进行聚类分析,实际上是根据不同路面技术状况进行路段划分,不同路段有不同的属性特征,理清“养护哪儿”“怎么养护”的主要矛盾。主要参考两方面因素:(1)依据路面养护时机;(2)根据养护措施的综合修复效果。以路面病害较为复杂的沥青路面为例(如图2所示),综合沥青路面病害属性养护措施为4类、养护时机为4类,本文选定k=4进行聚类计算,其他聚类计算可参考本文研究思路进行选择。
2.3.2权重值的选择
由于不同属性对路面技术状况的重要程度有差异,因此为保证聚类的精度和效率,根据不同属性对聚类结果的影响、重要程度进行赋权,进行加权时需要将计算的权重用在欧式距离计算中。聚类分析方法在路面养护工程中的应用需要在各种约束条件下进行才能获取良好的聚类效果。依据路面技术状况评定等级里程的统计,选择参与聚类分析分项指标评定等级为良、中、次、差的里程数,用于本文研究加权属性聚类的权重值计算。权值计算方法如下页表1所示。
3应用项目案例
现以广西某高速公路养护工程项目为案例,路段全长108 km,以2019年度路面技术状况指标检测结果DR、RD、SFC和IRI的每百米数据作为样本对象,上下行各1 080个样本,分别采用传统K-means和加权属性K-means聚类分析法,将路面技术状况属性特征类似的每百米路段分类。学者们通常应用SPSS等软件直接进行聚类运算和统计分析,但是类似软件并没有特征属性设置权重值的功能。本文应用Python编写传统K-means聚类和加权属性K-means聚类两种算法的程序,统计分析聚类结果。
3.1聚类计算过程
根据前文所述将数据进行标准化,并选择聚类K=4。依据2019年广西某高速公路路面技术状况分项指标评定里程汇总如表2所示,按前文的计算方法,计算聚类属性距离权重值ωDR=0.04,ωIRI=0.06,ωSFC=0.81,ωRD=0.09。
3.2聚类计算结果分析
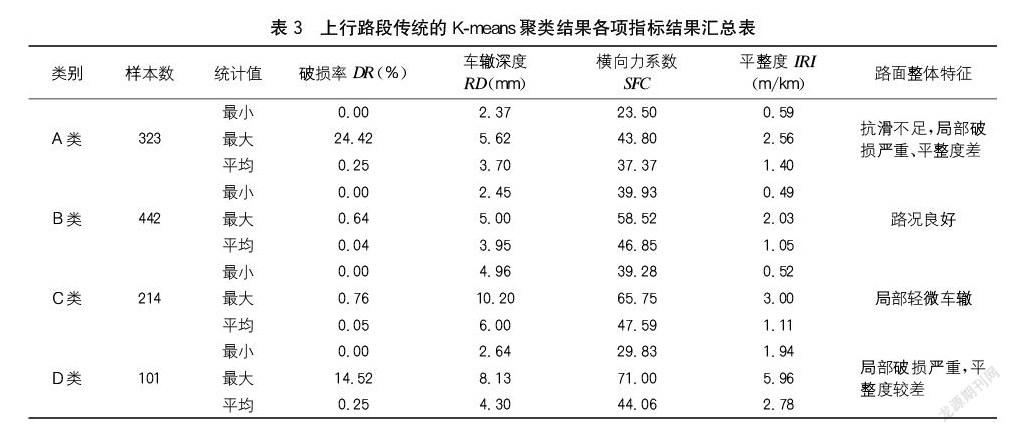
3.2.1传统的K-means聚类结果
对上述高速公路上行路段样本,执行计算结果为A、B、C、D共4类,如表3所示。A类和D类是路面养护需重点关注路段,主要病害是抗滑不足和平整度较差,可采取加铺薄层罩面或铣刨重铺的养护措施提高路面使用性能。但路况分项指标数值范围出现嵌套,划分类别中路段特征属性有重叠,主要原因是数据组属性提供的贡献一致,并且受到随机初始聚类中心的影响,聚类准确性不高。
3.2.2加权属性的K-means聚类结果
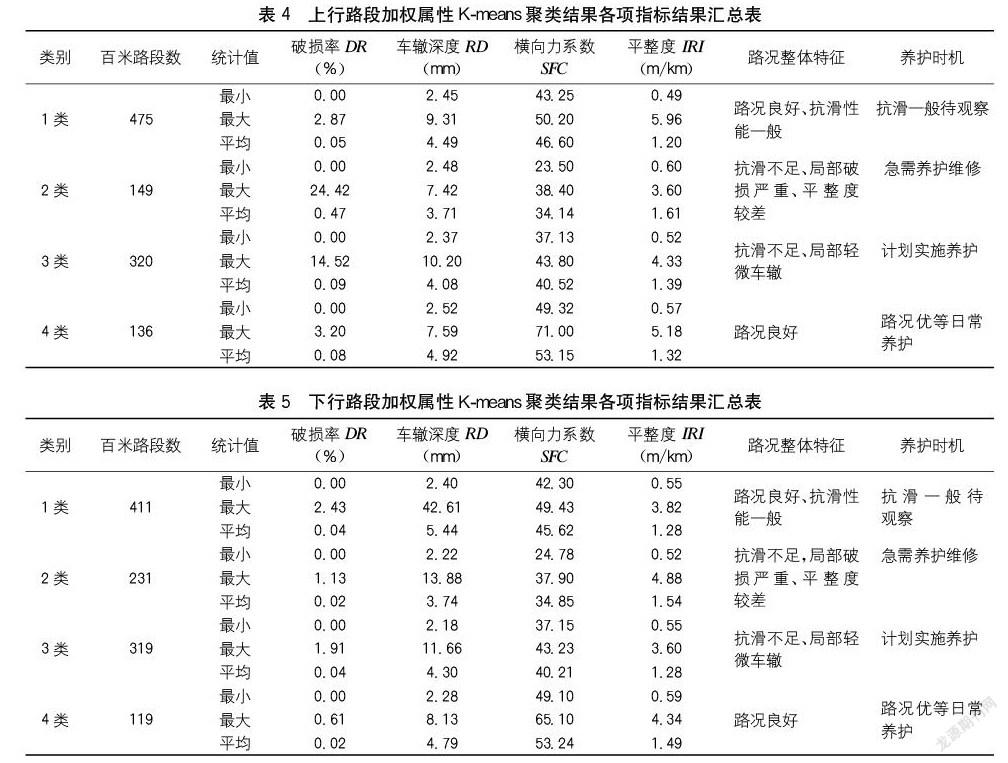
对上述高速公路上、下行路段样本,执行计算结果为1、2、3、4共4类,结论如下:
(1)如表4和表5所示分别为广西某高速公路上、下行路段应用加权属性K-menas聚类计算结果,对比该传统的算法,路面技术状况各分项指标的数值范围内基本消除类别之间嵌套的问题,划分类别中数据属性能突出病害特征,能够更清晰地判断主要路面技术状况问题。
(2)上、下行路段分别将各个百米路段划分为4类(根据路面技术状况数据总结和判断病害特征):路况良好、但抗滑性能一般;抗滑不足,局部破损严重、平整度较差;抗滑不足、局部轻微车辙;路况良好。
(3)依据聚类结果的主要分类,表4、表5各个类别的路面属性指标数据最大、最小值范围,可将4个路段类别结合养护时机和养护措施实施养护决策。
(4)图3和图4所示为加权属性聚类计算结果中百米路段的4个类别在某高速公路全线的分布点位、分段连续情况。根据表4和表5中4个类别的路况特点分析,抗滑不足、局部路段路面损坏严重和有车辙的路段主要集中在K1655~K1675段,经调查该路段多处为长大纵坡及转弯超高路段,且货车比例高达52%,抗滑性能较其他路段衰减快。
3.2.3基于聚类结果的路面养护建议
根据加权属性K-means聚类分析结果,主要关注1类、2类、3类路段,4类路段可在3~5年内实施日常养护。针对2类路段建议立即采取养护措施,鉴于抗滑不足的主要问题,可实施预防养护手段,对原有路面加铺超薄磨耗层;对3类路段可列入养护计划之中,或者合并至2类路段一起实施养护,满足施工连续性,具体情况依统筹养护资金和养护期限决定;1类路段抗滑性能一般,未来2~3年作为观察期,依据每年度路面技术状况检测进行养护决策。
4结语
(1)用加权属性的方法改进的K-means聚类分析,可以解决在传统聚类分析中路面技术状况各分项指标的数值范围类别之间嵌套的问题,改进后各个类别的数据属性能突出病害特征,能够清晰判断主要路面病害问题,提高路面养护路段划分的准确性,便于养护决策分析。
(2)本文在k值的选择上考虑了病害类型、养护措施和养护时机等方面情况,通常情况可以采用基于每个簇的质点与簇内样本点的平方距离误差和原理的“肘部法则”计算最佳k值,比较假定的k值是否接近,是否满足最优条件。
(3)加权属性K-means聚类分析可综合考虑所有可以量化的性能指标,但在实际养护工程中还有些非量化的因素,如历史施工情況、养护投资、施工连续性要求、气候影响等,不易在本文聚类方法中实现。因此,对于具体的养护决策应根据本文方法的计算结果综合考虑其他的非量化因素或者将其因素量化后分析再确定实际的路段划分。
参考文献:
[1]汪首元,崔玉姣,马伟中,等.基于K-均值聚类的沥青路面使用性能评价[J].公路交通科技(应用技术版),2019(2):16-18.
[2][JP3]张阳,何丽,朱颢东.一种改进的K-means动态聚类算法[J].重庆师范大学学报(自然科学版),2016,33(1):97-101[JP2].
[3]孟海东,宋宇辰.大数据挖掘技术与应用[M].北京:冶金工业出版社,2014.
[4]董旭,魏振军.一种加权欧式距离聚类方法[J].信息工程大学学报,2005,6(1):23-25.
[5]金鑫.聚类分析原理在高速公路养护路段划分中的应用[J].北方交通,2016(5):90-94.
