基于并行混合网络的生鲜水果短文本情感分类
2022-04-25潘梦强董微张青川
潘梦强,董微,张青川
(北京工商大学电商与物流学院,北京 100048)
民以食为天,食品安全一直是人们关注的焦点,同时它也是全面建成小康社会的重要标志。随着互联网的迅猛发展,直播带货等线上销售手段如雨后春笋般涌现,由于其门槛低、数量多、质量杂等特点,难以通过常规抽查的方式来对其进行有效的质量监控。广大消费者在购买产品之后,也倾向于在平台发表一些自己对于购物的观点,这些评论观点饱含情感特征,通过对评论文本进行情感分析,于消费者而言可以缓解信息不对称,了解商品的真实情况,减少决策成本;于商家而言,可以根据评论情感来改进自己的产品,提升销量;于平台而言,可以根据短文本的情感分析来掌握直播带货等销售手段所售商品的质量,及时对不合格商品进行监管,尤其是保质期较短的生鲜水果;于国家而言,可以根据评论有的放矢,选取重点性的食品安全抽查对象进行重点抽查,这样可以以较少的成本达到一个较好的效果,在一些较大的食品安全事故中甚至可以进行舆情的监测。
在线评论的情感分析是一项应用广泛的技术,在商品推荐领域[1-2],销售量的预测领域[3],消费者满意度测算[4]等领域均有广泛的应用。为了实现海量文本的情感分析,学者们通过情感词典、机器学习和深度学习等方法分析文本情感倾向。
情感词典方面,Taboada等[5]提出一种通过构建情感词典来计算文本情感倾向的方法;Rao等[6]提出了一种改进的算法以及通过3种删减的策略来自动的构建情感词典。情感词典的建立完全依赖于人工,对于日新月异的消费者表达方式,很难与时俱进。虽然情感词典的方法也在不断地改进,但是单纯使用情感词典无法突破‘词典’的桎梏。
在传统机器学习方法方面,Pang等[7]首次将机器学习用于情感分类,并且尝试不同的机器学习方法,并且最终发现支持向量机(support vector machines,SVM)、朴素贝叶斯(naive Bayes,NB)等方法应用在文本情感分析上能取得较好的效果。然而,基于传统的机器学习方法无法适用于当今时代,海量数据的存储,新鲜词汇的涌现,传统的机器学习要随时保持训练,往往不能在第一时间发现新闻焦点。
在深度学习方面,首先要解决的是词的表征问题,即将字或词转换为计算机能够识别的数值向量形式。Mikolov等[8]提出了Word2Vec模型来对文本中的单词进行向量化表示,解决了传统的独热编码所带来的维度灾难问题。Pennington等[9]提出了Glove模型来对文本序列进行特征表示。但是以上方法都是对于文本序列特征的静态表示,忽略了序列的位置信息,特别对于中文文本序列而言,一个词只用一个固定的向量表示,无法解决广泛存在的一词多义现象。针对这一问题,GPT模型与ELMO模型[10]被提出,不同于之前模型,它们可以对同一个词训练出不同的词向量,以应对同一个词在不同语境下可以有不同的含义的情况。在此基础上,Devlin等[11]提出了基于Transformer的BERT模型,进一步提升了对于文本序列的表征能力。张腾等[12]利用Glove模型进行词嵌入,BiGRU模型克服双向长短期记忆网络(BiLSTM)计算量大的问题,并通过卷积神经网络(CNN)与BiGRU模型分别对文本序列进行特征提取,然后融合特征进行情感分类。Du等[13]针对传统CNN忽略文本语法结构而单独对句子结构进行建模会带来大量的计算负担的缺点,改变了CNN的池化策略,用PCNN对句子中的语法结构进行分割,并提与相应文本序列中相应成分的特征,取得了较好的结果。Bahdanau等[14]将注意力机制引入自然语言处理中,其优点是可以动态的调整文本序列的权重分配,使得分类器可以有的放矢,专注于重点的特征信息,进而提升分类的准确率。杨长利等[15]在双通道混合模型中加以注意力机制,提升了情感分类的准确率。已有较多的学者将BERT模型与Word2vec、Glove、ELMO等模型进行对比,最终发现使用BERT的模型在进行情感分类任务中得到最高的准确率[16-18]。然而以上研究都只是针对电商平台的普通产品,没有对产品进行详细划分,但是水果产品有着其特有的属性,水果产品属于生鲜产品,然而用户针对其在形、味、包装、运速等方面有着特别的关注。针对此类现象,现提出一种融合BERT和并行混合网络的生鲜水果短文本情感分析算法,就电商平台的生鲜水果产品的评论进行短文本情感分析。
1 相关理论
1.1 BERT模型
如图1所示,BERT由若干个Transformer层[24]组成,得益于Transformer中的自注意力机制层模块以及前向传播神经网络层模块结构,使得BERT具有很强的词向量表征能力。BERT通过“Masked Language Model”以及“Next Sentence Prediction”这两个无监督的子任务进行训练。使得输出的词的向量化表能够详尽地展现文本序列所包含的信息。BERT模型本质上也是作为词向量的提供工具,相比于静态的特征提取,BERT可以根据下游任务来动态的调整,对于一词多义现象友好。
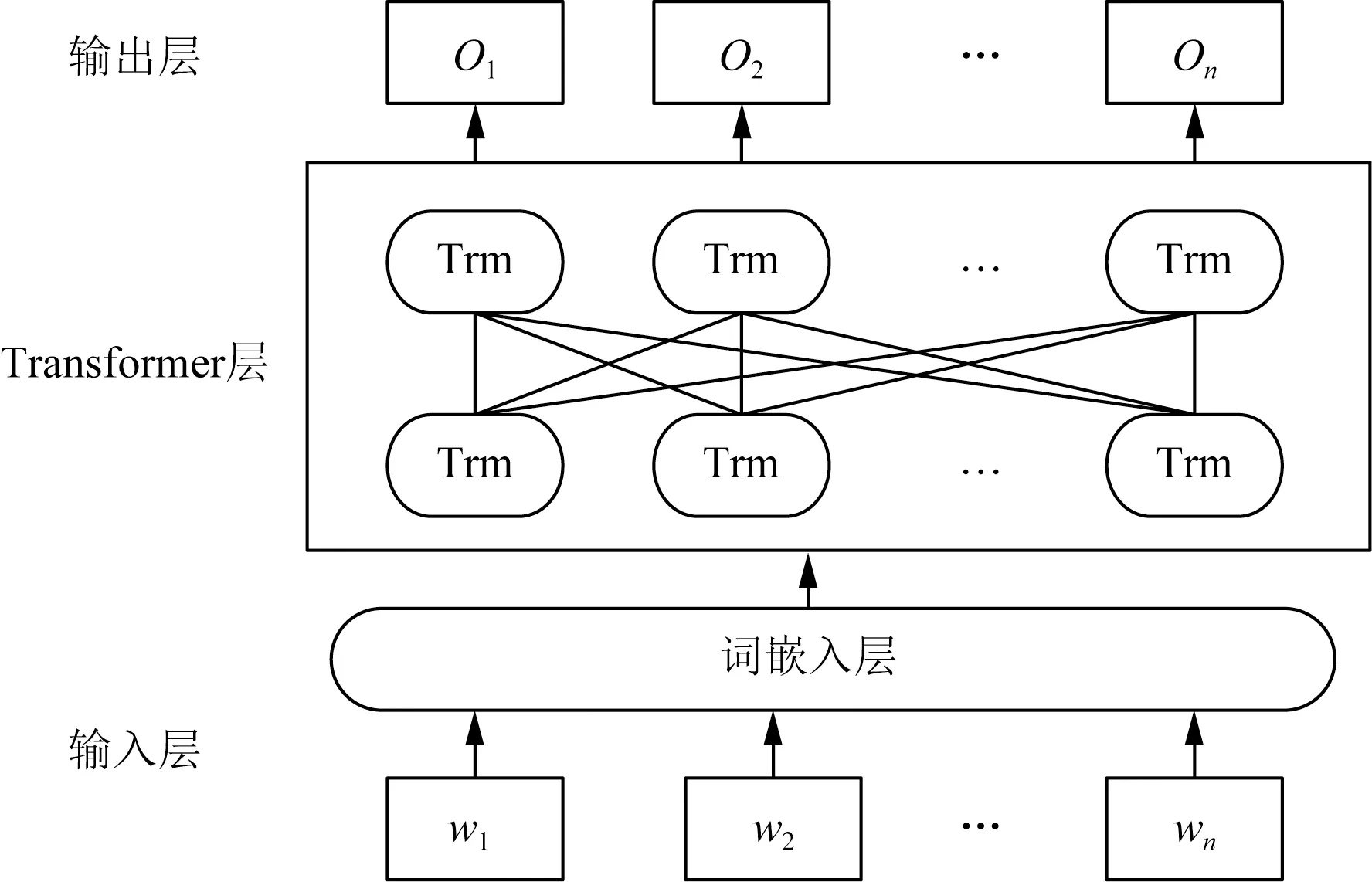
wn为输入的单词;Trm为Transformer结构;On为输出的结果
1.2 CNN与PCNN模型
CNN模型与PCNN模型主要由卷积层和池化层组成。
1.2.1 卷积层
卷积层是在得到词的向量化表示之后,使用若干的卷积核对所得向量进行卷积操作,得到特征的初步提取。由此可得新的特征矩阵。对于一次卷积操作而言,在第i个卷积核进行卷积操作之后,可以得到特征值ci,j:
ci,j=f(ωixj:j+h-1+b)
(1)
式(1)中:h为卷积核的窗口大小;f为非线性函数;b为偏置项。对于一条文本序列,卷积核i在沿着序列的方向滑动,最终可以得到特征序列ci:
ci={ci,1,ci,2,…,ci,n-h+1}
(2)
1.2.2 池化层
卷积操作可以得到文本序列特征,由于得到的特征向量较大,如果直接传分类器会导致模型参数增加,训练难度增大,且容易出现模型过拟合的情况。为了解决模型复杂度较大的问题,往往会在卷积操作之后加入全局最大池化层,这样可以减少参数并且进一步的提取主要特征,图2为全局最大池化的卷积神经网络的结构图。

图2 CNN模型结构
在得到一个卷积核提取的特征序列ci之后,选取其中最大的值,全局最大池化的操作如式(3)所示,di为最大池化操作提取的特征。
di=max({ci,1,ci,2,…,ci,n-h+1})
(3)
全局最大池化是将卷积操作所得的特征进行一个筛选,得出与任务最相关的特征,达到一个‘降维’的目的。但是在应用于文本语言中,最大池化的操作难以捕捉句子的语法结构。分段池化不仅仅是在卷积核ci中提取最大的数,而是先将ci分成若干段,再对分成的各段进行一个最大池化操,然后将所得的特征进行一个拼接,在一定程度上弥补单一的最大池化操作忽略语法结构的缺点。图3为分段池化卷积神经网络的结构图。
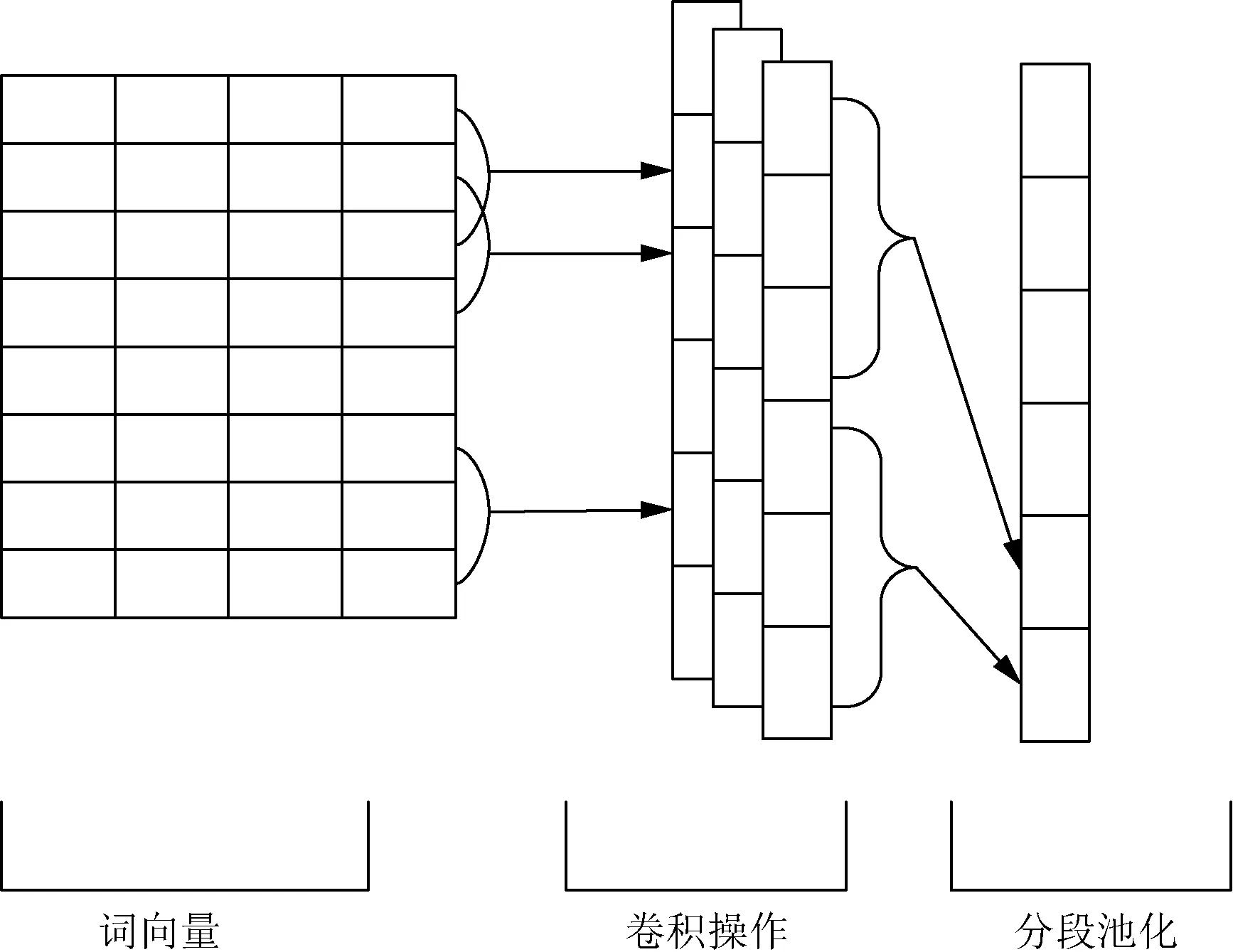
图3 PCNN模型结构
在得到一个卷积核提取的特征序列ci之后,将特征序列分为k段,即
ci={ci,1,ci,2,…,ci,k}
(4)
式(4)中:1≤k≤n-h+1。在分为k段之后,分段池化是对于其中的每一段进行一个最大池化的操作,如式(5)所示,对第i个卷积核所得的特征ci进行分段池化可得di,即
di={max(ci,1),max(ci,2),…,max(ci,k)}
(5)
1.3 BiGRU模型
门控循环单元(gate recurrent unit, GRU)模型本质上与长短期记忆网络(long short term memory, LSTM)一脉相承,都是对循环神经网络(recurrent neural network, RNN)的改进,都能在一定程度上克服长期依赖问题以及梯度弥散的问题。GRU与LSTM的区别在于GRU的内部结构相较于LSTM来说要简单,主要由更新门(zt)和重置门(rt)组成,参数较少,易于训练。GRU的信息传播方式为
rt=σ(Wr[ht-1,xt])
(6)
zt=σ(Wz[ht-1,xt])
(7)
(8)
(9)

虽然GRU相较于传统的循环神经网络,已经有了较大的进步,但是单向的GRU模型应用于文本情感分析时会出现文本后面出现的字词要比前面的重要的情况,这一问题在长文本时尤为突出。所以本文利用双向的GRU模型来缓解这一情况,同时得益于GRU参数较LSTM少的特点,使用双向GRU模型不会对模型训练产生太大的压力。图4为双向GRU(BiGRU)模型的结构图。

图4 BiGRU模型结构
2 模型设计
提出一种融合BERT的并行混合网络模型来进行水果方面的短文本情感分析。如图5所示,该模型由4个信息处理层组成:输入、特征提取、特征融合和输出。由于单一的卷积层无法提取文本的上下文信息特征,所以在卷积神经网络的基础的并联一个双向门控循环单元来提取文本的上下文信息特征,二者优势互补,这样可以提取到较多的特征以提升最终模型的准确率。虽然BERT模型可以很好地进行文本序列的特征表示,但是由于其缺乏领域知识,所以在后面使用PCNN来提取静态特征以及结构特征,使用BiGRU提取上下文信息,再将二者组成双通道之后进行特征融合,进而弥补BERT所缺乏的领域知识。采用并行连接的方式,使得PCNN提取到的结构特征得以完整保留,并且相比于CNN与RNN堆叠的方式,可以避免模型过深带来的问题。

Wn为输入的字;BiGRU和PCNN分别为BiGRU模块和PCNN模块
2.1 输入层
对于一条文本句子序列,经预处理后的词语序列{W1,W2,…,Wn}作为模型的输入,然后由预训练模型BERT来提供词的向量化表示,并依据上下文语境来对词向量进行一个动态的调整,以便让模型得到真实的文本语义。
2.2 特征提取层
在经由BERT预训练模型处理之后,便得到了文本的向量化表示。一方面利用BiGRU来提取上下文信息,得到文本的深层次特征信息。另一方面利用分段池化卷积神经网络来提取局部语义特征信息以及结构特征。
2.3 特征融合层
在特征融合层中,将BiGRU与PCNN得到的特征信息进行融入拼接,进而组成整段的情感特征向量,以便在输出层使用。
2.4 输出层
将特征融合层的输出(即得到的情感特征向量)输入到Sigmoid分类器中,从而得出最终的情感分类结果。
3 结果分析
3.1 实验数据
实验数据为开源数据集online_shopping_10_cats和waimai_10k。online_shopping_10_cats是一个包含多类商品的电商评论情感分析数据集。本文主要选取其中的水果类进行情感极性预测。其情感标签分为两类,即积极与消极分别用1和0表示,标签列表为[0,1]。随机抽取7 000条水果类的数据作为训练集,1 000为测试集组成数据集一。waimai_10k包含大量外卖订单评论数据,分别取出2 000条正向情感与2 000条负向情感评论数据组成数据集二,在实验中随机抽取3 200条数据为训练集,其余为测试集。
3.2 评价指标
采用准确率(Accuracy)、F1、召回率(Recall)作为模型的评价指标,具体公式为
(10)
(11)
(12)
(13)
式中:TP为标签为1且预测为1的样本数;FP为标签为0且预测为1的样本数;TN为标签为0且预测为0的样本数;FN为标签为1且预测为0的样本数。
3.3 数据预处理
在实验进行前,首先要对实验数据进行预处理,大量的评论文本由不同的用户书写而来,形式自由,口语化严重,还存在大量的噪声数据。此外,由于水果类的特殊性,同一种水果在不同的地方可能有不同的叫法,存在的一义多词的现象,所以需要对评论文本进行预处理,预处理过程如图6所示,具体操作如下。

图6 数据预处理
(1)过滤掉所有的标点符号和特殊字符,只保留具有语义价值信息的中文文本。
(2)使用jieba分词工具进行词语分割。
(3)使用哈工大停用词表、百度停用词表和四川大学机器智能实验室停用词表去除噪声数据。
(4)针对同一类水果可能拥有不同的叫法,选取一些常见的水果别名,以及水果品种名,将水果名统一化。
表1为部分名称统一化的样例;表2为部分文本预处理的样例。

表1 名称统一化样例

表2 文本预处理样例
3.3.1 实验一
Du等[13]的研究发现句子有一般都包含主谓宾等语法结构,而分段是对语法结构的模拟,所以分段数是一个重要的参数,它决定了信息提取的有效性,在酒店数据集中,分段数在2~5时能取得较好的效果[13]。然而电商平台水果评论有着不同的表达方式,需要对合理的分段数进行探究。为了探究采用分段池化的卷积神经网络在生鲜食品领域的短文本情感分类中的合适的分段数,先设计不同分段数的卷积神经网络来进行对比,参考Du等[13]在酒店数据集的分段数,在本研究中分段数分别为1、2、3、4。
实验一仅对数据集一进行了实验,对比实验设置如下:①PCNN-1,池化层分段数为1,即普通的卷积神经网络;②PCNN-2,池化层分段数为2;③PCNN-3,池化层分段数为3;④PCNN-4,池化层分段数为4。其他参数如表3所示。

表3 实验一参数设置
由表4可以看出,采用分段池化的卷积神经网络在应用于生鲜类电商评论时,相较于普通的卷积神经网络(PCNN-1)在准确率上有提升,以分成3段的PCNN-3最高,达到了93.25%,提升了1%。PCNN-3无论是在准确率,召回率还是F1均领先于PCNN-1,

表4 实验一结果
说明了分段池化的操作可以在卷积神经网络提取到文本局部特征的基础上把握文本的结构特征。而通过PCNN-2与PCNN-4的实验可以发现,在3个指标上与PCNN-1相近,且部分指标甚至不如PCNN-1。由图7可以看出,PCNN-3的曲线一直在PCNN-1的上面,且能较快的收敛,随着epoch的增加Accuracy的波动较为稳定,PCNN-1在本实验中效果较差,Accuracy并不高且随着epoch的增加难以趋于稳定。印证了Du等[13]得出的不合适的分段数会破坏文本序列本身的结构,只有合理的分段数才能较好地提取特征的结论。综上可以得出结论,采用分段池化的操作并非是通过单纯地增加提取的特征来提升模型性能,在本数据集中,选择段数为3的分段数能取得较好的效果。

图7 不同分段数的ACC曲线
3.3.2 实验二
为了验证本文提出的融合BERT的并行混合模型在生鲜食品短文本情感分类任务中的优势,利用数据集一与数据集二来进行实验。
实验二对比实验设置:①PCNN+BiGRU模型,即本文提出的模型;②CNN+BiGRU模型,将PCNN替换为CNN的模型;③BiGRU模型,只有BiGRU的模型,参数同上;④PCNN模型,只有PCNN的模型,参数同上,池化方式为分段池化;⑤CNN模型,只有CNN的模型,且池化方式为全局最大池化;⑥BiLSTM模型,只有BiLSTM的模型。
参考其他文献中参数设置以及对各参数选择进行实验对比后,各模型最佳参数设置如表5所示。

表5 实验二参数设置
由实验结果表6可以看出,PCNN+BiGRU模型相比于CNN+BiGRU、BiGRU、PCNN、CNN和BiLSTM模型,在F1值上分别提高了1%、2.12%、0.83%、1.75%和1.26%。Accuracy值上分别提升了1.10%、1.5%、1%、2%和1.4%,Recall也比其他的要高。通过实验可以发现CNN+BiGRU模型的准确率、F1等指标与传统的CNN相近,但是模型训练时间却高出很多,说明单纯的堆砌参数并不能有效地提升模型的准确率以及模型的性能,并非模型越复杂就越好,当与PCNN相比时,准确率反而降低了0.1%,然后在每个epoch的训练时间上,PCNN有着较大的优势。PCNN模型与CNN模型、BiGRU模型、LSTM模型相比,可以发现,当改变池化策略时,在不过多增加参数的情况下就能达到一个较高的准确率。通过表6也可以发现PCNN模型在准确率,F1与Recall均高于CNN、BiGRU和BiLSTM模型,且训练时间较短,说明PCNN模型在一定程度上可以把握文本的结构特征。PCNN+BiGRU模型与同等复杂度的CNN+BiGRU模型相比在3个指标上均有提升,且自身的准确率也在数据集一和数据集二上分别达到了94.25%和85.88%,综合起来可以发现,PCNN+BiGRU性能的提升并非单纯因为模型参数的增加,而是因为该模型确实把握住了文本结构,对文本局部特征与全局特征的提取较为充分,也印证了本文提出的模型的有效性。
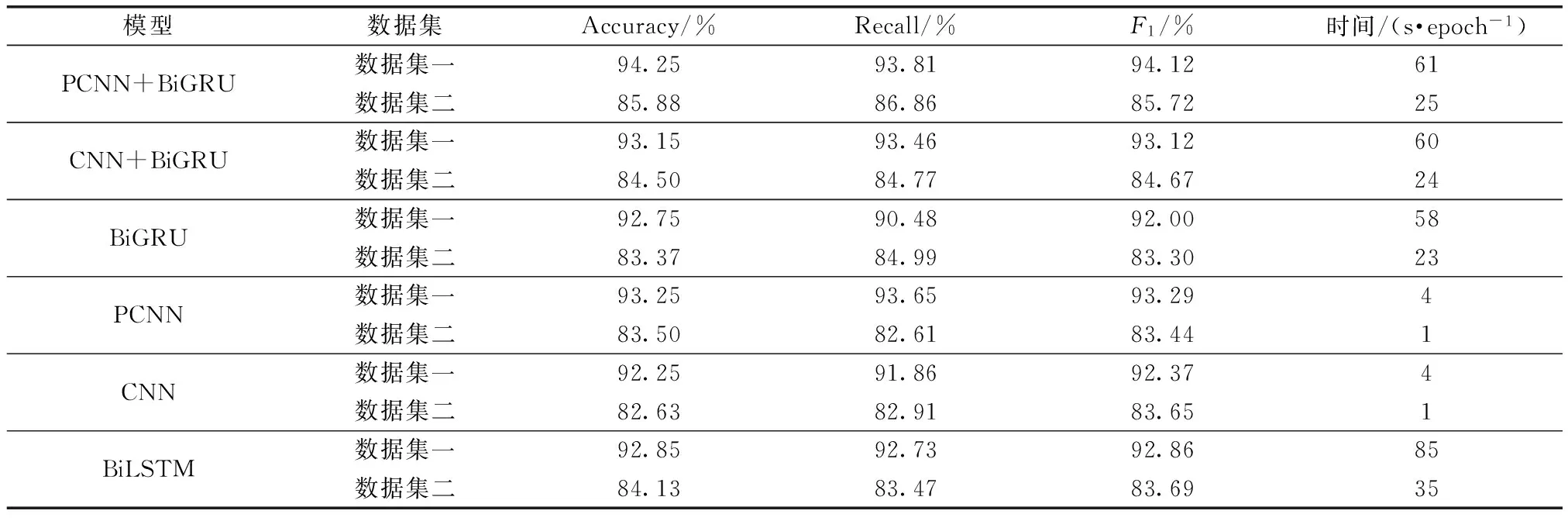
表6 数据集一和数据集二的实验结果
4 结论
随着移动互联与物流的迅猛发展,网上购物已经成为民众主要的购物方式之一。然而平台监管难成为一个大问题,在全球新冠肺炎疫情冲击下,进口生鲜产品携带新冠病毒的事情屡屡发生,国家层面的食品安全检查难以面面俱到。从在线评论的情感角度去辅助监管与重点抽查是一项颇具实际应用意义的研究。
提出了一种融合BERT的情感分类模型,在同一公开数据集上通过不同算法之间的对比,初步印证了本文提出模型的有效性。得益于BERT强大的词向量表征能力,本文模型得到了一个较好的准确率。同时发现了非模型越复杂准确率越高,并且发现分段池化卷积神经网络在选定合适的分段数时,可以提升卷积神经网络对文本序列信息的提取能力,并且在训练耗时上与传统卷积神经网络几乎相同。同时PCNN的性能可以和BiGRU模型、BiLSTM模型相媲美,但是训练时间却大大降低了。本文模型可以分别提取文本序列的结构信息与上下文信息,能较好地完成情感分类任务,为情感分类下游任务提供基础。同时相对较短的训练时间也能够支持商品监管等效性较高的任务。
