基于变电站检修历史数据的检修图谱研究
2022-04-20张霞徐立纲
张霞,徐立纲
(国网江苏省电力有限公司苏州供电分公司,江苏 苏州 215000)
变电站电力设备的日常巡检和维护中,积累了大量关于设备检修记录和缺陷情况的记录文本,而在检修流程和缺陷的分级消缺等处理工作完成后,相应的检修和缺陷记录往往闲置于系统中。在对变电站检修的过程中,往往关注的是检修工作的分级分类和故障的处理过程,而很少关注检修数据的整理和归类,这就造成检修数据的分散、缺漏和数据记录缺乏系统性。这些数据的分类和统计工作,往往是通过人工进行的,不仅工作量大,而且耗时耗力,并且由于统计人员的经验的不同和其他主观因素,可能会造成统计工作的缺乏有效性。因此,需要一个更系统的方法对变电站检修历史数据进行管理和应用。针对这一问题,在变电站检修系统中引入人工智能、知识图谱及自然语言等技术,以此构建基于检修历史数据的知识图谱,实现对检修数据的整合和梳理,并进行处理和分析,从而保证检修数据的规范化和可视化,提高变电站的检修效率和运行稳定性。
1 知识图谱的定义
目前,在学术界对知识图谱没有统一的定义。一般来说,知识图谱是Google公司在2012年提出的一种技术类型,用来支持从语义角度组织数据网络,从而提供智能搜索服务的知识库。
互联网中具有海量、复杂甚至泛滥的数据,这些信息大多以非结构的形式存储和传播,为了让计算机能够处理这些信息,就需要理解这些非结构化形式数据中蕴含的语义,分析其中的语义单元之间的关系,从而转换成结构化形式。图1是一种能有效表示数据之间结构的表达形式,因此,人们考虑把数据中蕴含的知识用图的结构进行形式化表示。因此,知识图谱是一种比较通用的语义知识的形式化描述框架,它用节点表示语义符号,用边表示符号之间的语义关系。
具体来说,知识图谱以结构化三元组的形式存储现实世界中的实体以及实体之间的关系,表示为{实体,关系,实体}。三元组通常描述了一个特定领域中的事实,由头实体、尾实体和描述这两个实体的关系组成。例如,{部件,出现,缺陷},其中头实体是“部件”,尾实体是“缺陷”,关系是“出现”。有时,“关系”也被称为“属性”,相应地,尾实体被称为属性值。不同的实体和属性之间具有不同的关系,通过相互联结的方式,形成网状的知识图谱。
知识图谱的构建通常分为知识抽取、知识融合、知识表示、质量评估和知识推理五个部分,构建流程如图1所示。
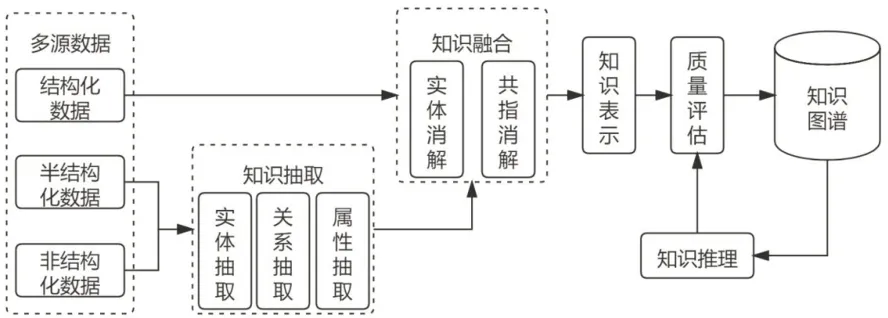
图1 知识图谱构建流程
2 构建电力系统检修图谱的具体要求
一般情况下,电力系统知识图谱构建的方法分为三种:自顶向下(top-down)、自底向上(bottom-up)和混合法。自顶向下的方法是一种从抽象到具体的方法,是从现有概念到具体数据实现的构建过程。自底向上的方法正好相反,是一种从具体到抽象的方法,是从具体数据实现抽象到概念规则的构建过程。混合法就是自顶向下和自底向上两种方法的混合,相较单一的构建方法更为复杂。本文所采用的检修谱图构建方法为自底向上构建法,即从具体数据到抽象概念规则。
电力设备检修记录通常以单个句子的形式存在,一般都以自然语言记录缺陷的设备部件、现象、程度等内容。由于在设备检修具有自身的特点,因此,在构建检修知识图谱时,要注意以下几点具体要求:
(1)在电力设备检修记录中,缺陷现象作为缺陷部件的属性,本身还具有缺陷程度等属性,故除抽取实体间及实体与属性的关系外,还要抽取属性间关系。
(2)本文构建的知识图谱仅限于电力系统的检修领域,该领域是一个封闭的领域且有明确的行业术语规范,因此,相对于开放领域而言,检修知识图谱的实体消解和共指消解相对较简单。
(3)根据从结构化数据中抽取的实体、关系、属性,作为抽取三元组的样本,以充分利用结构化数据。
(4)知识融合步骤将从半结构化数据和非结构化数据中形成的三元组,与从结构化数据中形成的三元组相整合,形成可视化的电力设备检修数据知识图谱。
3 电力系统检修图谱的构建
本文构建电力系统检修图谱的环节包括知识抽取、知识融合和知识表示三个环节。知识抽取就是在电力行业特定环节的文本语料中抽取实体、关系和属性,并将其以{实体,关系,实体}或{实体,属性,属性值}的形式存储。由于抽取后的知识是分散的和缺乏逻辑性的,因此,需要将抽取自不同数据源的知识进行融合。最后,就是将融合后的知识按照电力行业的知识结构和人的思维方式表示为特定的机器可处理的形式。
同互联网一样,电力系统中的数据也是繁多且复杂的,来源也是多种多样。因此,有必要对构建检修图谱的数据来源作出说明。
3.1 数据获取
电力系统维护检修数据从数据的规范程度,从高到低可分为结构化数据、半结构化数据和非结构化数据。
结构化数据一般存储于系统的数据库中,如变电设备缺陷管理数据库、设备运行数据库以及检修计划管理数据库等。半结构化数据是指在一定程度上具有某种特征的数据,如检修工作计划、评价报告、年报月报等。非结构化数据是指符合自然语言规范的文本数据,如设备检修记录和缺陷情况的记录文本等,变电站检修数据多数来源于这种非结构化数据。由于半结构化数据和非结构化数据存在表述不规范和句法结构复杂等一系列问题,因此,不能像结构化数据那样直接应用于知识图谱的构建。因此,需要对其应用自然语言处理(natural language processing,NLP)等技术,进行分词、实体提取、实体消解、共指消解等操作。
3.2 知识抽取
构建电力系统的检修图谱的第一步就是要在检修记录和缺陷情况记录文本中抽取实体、关系和属性。常见的实体/属性抽取方法有隐马尔可夫模型和BILSTM模型等。由于是在电力行业特定的检修领域中,因此可直接采用电力专业词典进行抽取和匹配。
根据对电力专业词典和缺陷记录的匹配,本文共确定了8个实体、7种关系和12个属性。检修图谱中的实体是指知识库中所需要的不同的概念类别,包括设备、部件、缺陷、现象、原因、缺陷等级、解决方案和责任单位。关系是指实体之间的关系,包括包含、出现、描述、诊断、程度、措施和对应。而属性是实体自身所拥有的特征,不同实体可以具有相同的特征,也可以具有不同的特征,包括编号、名称、类型、措施、故障等级、监测方法、状态、告警、时间、维修人员、维修活动和位置。将实体、关系和属性以三元组的形式存储,如{一次设备,包含,电子式互感器}、{合并单元,出现,缺陷}。
3.3 知识融合
在对不同数据源的数据进行知识抽取后,可能会存在重叠现象,为保证所获得知识的质量,需要进行实体消解和共指消解。由于本文构建的知识图谱仅限于电力系统的检修领域,该领域是一个封闭的领域且有明确的行业术语规范,因此,实体消解指将具有同义属性的实体消解为一个权重较大的实体。例如,“缺陷”“故障”“漏洞”在表示“设备状态”时,实际上表示的是同一个意思。因此,可以对各个实体设置一个权重,利用How Net知识库计算实体对的相似度,实现知识的融合。
3.4 知识可视化表示
构建电力系统检修知识图谱的主要目的就是利用节点和边的形式,实现检修知识的可视化。本文以8个实体为主要节点,通过7种关系将它们相连,在将每个实体的属性扩展到图上,实现可视化的网状检修图谱。图2是检修图谱的实体关系图,再将各个实体的属性添加上去,将是一个巨大的网状图。
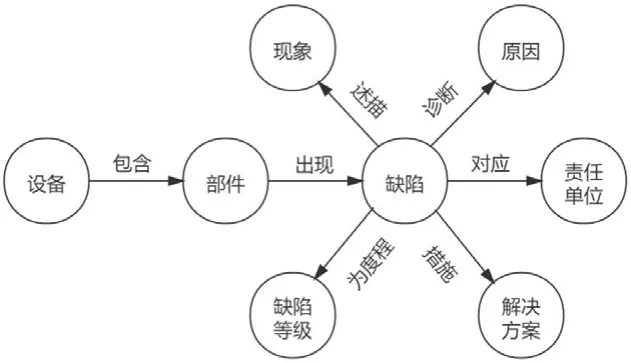
图2 检修图谱的实体关系图
4 结语
本文根据变电站检修的特点,结合人工智能中的知识图谱技术,构建了变电站检修知识图谱。这只是变电站检修数据治理的理论工作的第一步,还需要对检修图谱在检修记录检索和缺陷记录检索等方面的应用做进一步的探索,以真正实现变电站检修工作的数字化、智能化管理。

