标签结合现实场景的交通标志分类检测研究*
2022-04-19张瑞宾王曙道
张 成,张瑞宾,王曙道
(桂林航天工业学院 汽车与交通工程学院,广西 桂林 541004)
0 引言
在车辆安全和自动驾驶领域,交通标志的检测有着很大的实用价值。真实的交通场景复杂多变,交通标志易受到光照、雨雾和遮挡等外在因素的影响。传统的检测算法根据交通标志的形状、颜色等特点[1-6],使用不同尺度大小的滑动窗口对待检测图片进行潜在目标区域提取,之后对潜在区域通过HOG(Histograms Of Oriented Gradient)[7]、Gabor[8]、Haar-like[9]等人工提取特征方法,结合支持向量机、BP(Back Propagation)神经网络、极限学习机和最近邻算法等常用的机器学习算法完成分类的任务。这些方法若要完成细分类检测问题,工作量巨大,且最后的效果也不尽理想。
深度学习方法不同于前面的方法,它利用深度卷积神经网络完成特征提取,实现交通标志的检测任务。目前常用方法可分为候选区域和逻辑回归。候选区域的网络(如RCNN(Region-Convolutional Neural Network)[10]、Faster R-CNN[11])先提取出候选的区域特征,之后根据候选区域的特征进行位置和类别的学习,这种方法突出了出色的检测精度,牺牲了计算的时间和存储资源;逻辑回归的网络(如YOLO(You Only Look Once)[12]、SSD(Single Shot Detector)[13])直接将预测边界框的坐标和类别设置为回归问题,提升了网络的检测速度,但是针对具体的任务网络模型还需要进一步调整,且完成交通标志检测的研究需要数据庞大的交通标志数据集。
针对交通标志检测研究方法中的问题,本文提出了一种标签结合现实场景的交通标志分类检测方法。首先,为得到深度学习算法所需要的数据集,采用交通标志标签结合现实场景自动生成;然后,为解决常规算法体积大、速度慢的不足,对深度学习算法进行调整优化;最后,完成交通标志的分类检测。
1 相关工作
完成交通标志检测的深度学习算法研究,一是需要数据庞大的交通标志数据集,二是需要针对交通标志检测的算法。
1.1 交通标志数据集
目前,用于交通标志检测的LISA[14]搜集的是美国交通标志,有47 种标志类型。德国交通标志检测数据集GTSDB[15]应用也非常广泛,但是数据集只有900 张图片,数据规模较小,且没有对交通标志进行细分。BTSD[16]是比利时的交通标志数据集,数据集包含约7 300 个图像数据,包含不同场景下的交通标志样本,数据样本的分布不够均匀。针对中国交通标志的TT100K[17],从10 万个腾讯街景全景图中创建了一个大型的交通标志数据集,也是迄今中国公开的最大交通标志数据集。TT100K虽然拥有众多的数据,但也无法对中国的交通标志实现细分,且数据集内的不同交通标志的样本也不够均匀,部分常见交通标志数据较多,其他不常见标志数据较少,导致无法很好地实现最终的检测效果。因此,本文提出了交通标志标签结合现实场景的方式自动生成数据集,可以很好地解决数据集问题。
1.2 深度学习的交通标志检测
针对交通标志的检测算法的研究有很多,Rajendran等[18]通过加深ResNet[19]网络,采用反卷积模块方法提升了网络的检测效果,但是这加大了网络的规模。Aghdam等[20]采用膨胀卷积方式完成滑动窗口,并且利用数据集统计的信息加快前向传播,得到了较高的精确度,但该方法的最终结果受限于使用的数据集。YOLO 算法在目标检测领域有着广泛的研究,该算法在保证检测精度的同时,具有较块的检测速度。
1.2.1 YOLO 算法基本思想
YOLO 算法的检测流程如图1 所示。
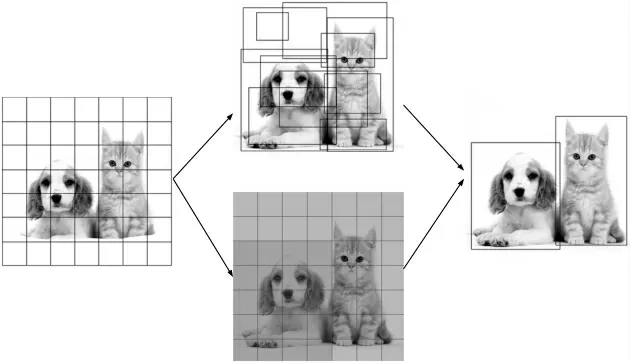
图1 YOLO 预测流程
首先,将输入的图像划分成S×S 个网格,然后每一个网格预测B 个边界框。对每个预测的边界框都用置信度进行评分。置信度分数反应了该网格包含待检测物体的信心以及预测的准确程度,定义为:

式中,confidence 为置信度值,Pr(Object)为预测的目标概率,pred 表示预测边界框的面积,truth 为实际边界框的面积,IOU 是实际边界框与预测边界框的交集和并集的比值。
在检测时,每一个预测种类的置信度(classConfidence)为条件类别概率(Pr(classi|Object))与目标置信度的乘积:
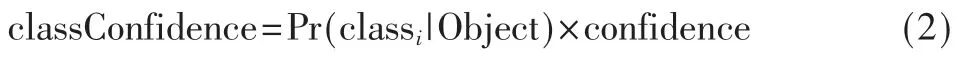
1.2.2 目标框位置预测
YOLO 中使用锚框来预测待检测物体的边界框,如图2 所示,每个固定框预测4 个边界坐标(tx,ty,tw,th)。通过相对网格坐标来预测目标框的中心位置,假设网格距离图像左上角的距离为(cx,cy),该网格预设的固定框宽高为(pw,ph),则预测的表达式如下:
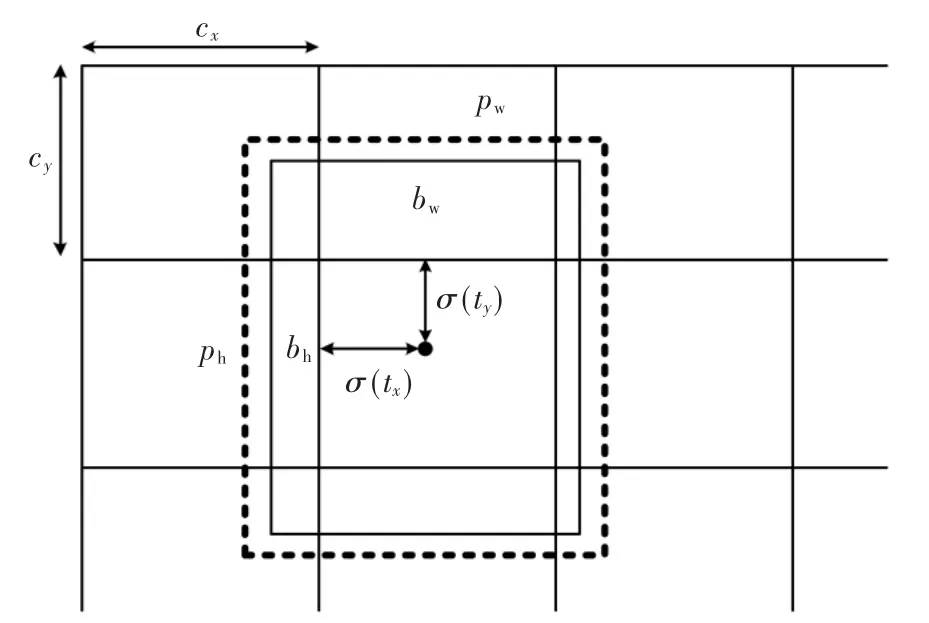
图2 目标框位置预测

式中,σ 为逻辑函数,可以将边界框坐标约束在[0,1],用来预测相对于网络中心的偏移;bx、by为归一化后相对于单元格的数值,bw、bh为归一化后相对于预设固定框的值。
2 标签结合现实场景的交通标志分类检测
本文提出的标签结合现实场景的交通标志分类方法。整体结构如图3 所示。原始的交通标志标签通过数据增强,之后与现实背景结合得到了大量的数据,用以训练网络;通过训练的网络证明生成数据的有效性,并通过网络的检测结果,进一步调整优化数据和网络;最后实现较优的检测方法。
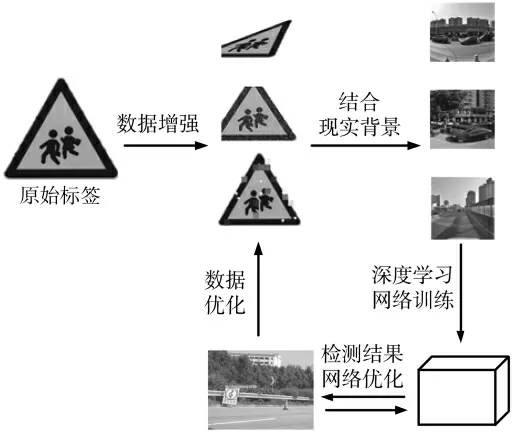
图3 整体结构
2.1 标签结合现实场景数据生成
2.1.1 标签数据增强
深度学习网络实现检测任务需要强有力的数据支持。中国的交通标志可分为7 大类,包括数百个标志。其中常见的3 大类为警告标志、禁令标志和指示标志,多数研究也只将交通标志划分为这3 大类而没有细分。本文为了便于研究,分别从3 大类中抽取3 个标签,如图4 所示。

图4 部分中国交通标志标签示例
交通标志拥有完整的图案标签,将这些标签进行有效利用,可以降低任务的成本。传统的数据增强多是按批次统一加入噪声、旋转等方法,这种变换方式不能够很有效地增强样本的多样性。本文针对现实交通标志的环境,设置多种数据增强方式,且进行随机组合可以有效地扩张数据的多样性,如图5 所示。生成的部分增强图片如图6 所示。
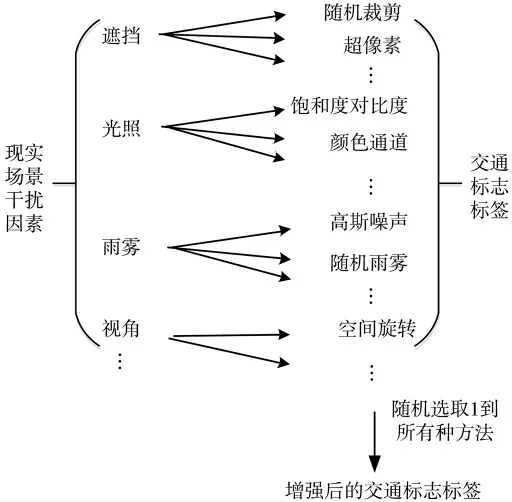
图5 交通标志标签增强流程

图6 增强交通标志标签示例
2.1.2 结合现实场景
完成交通标志标签的数据增强后,并不能直接用于交通标志检测的研究。深度学习网络在检测时不仅需要识别出物体,还需要准确地找出物体的位置。这意味着网络不仅需要学习检测目标的深层特征,还需要能够学习到背景的相关特征,从而有效定位分类。交通标志因不同的拍摄距离,在照片上的尺寸大小不一。
充分考虑到交通标志背景和尺寸问题,本文选择TT100K 中不含有交通标志图片以及搜集的道路图片作为背景图片。通过以下步骤将2.1.1 节中增强后的交通标志标签与背景进行融合,如图7 所示,并自动生成用于训练的交通标志类别位置文件:

图7 结合现实场景多尺度生成图片
(1)交通标志标签大小限定,交通标志因不同的拍摄距离,表现在照片上的大小不一,在进行分析后本文选择相对背景图片0.01~0.2 进行尺寸限定;
(2)交通标志标签位置限定,交通标志在照片中的位置也是不固定的,因此本文通过随机的方式将步骤(1)处理的图片融合在背景中;
(3)交通标志标签类别位置文件生成,交通标志检测任务需要相应的标签位置信息,通过步骤(1)、(2),可以直接读取生成的数值,免除了大量的人工标注成本。
2.2 交通标志分类检测深度卷积网络
YOLOv5 具有检测速度快模型轻量化的特点,有4个版本分别为YOLOv5S、YOLOv5M、YOLOv5L 和YOLOv5X,网络的深度和广度逐渐增加。考虑到交通标志检测对于速度和文件体积的要求,YOLOv5 进行优化,形成本文方法,如图8 所示。其中,网络中使用的卷积核个数为YOLOv5S的一半,并且在Focus 模块中加入最大池化操作。
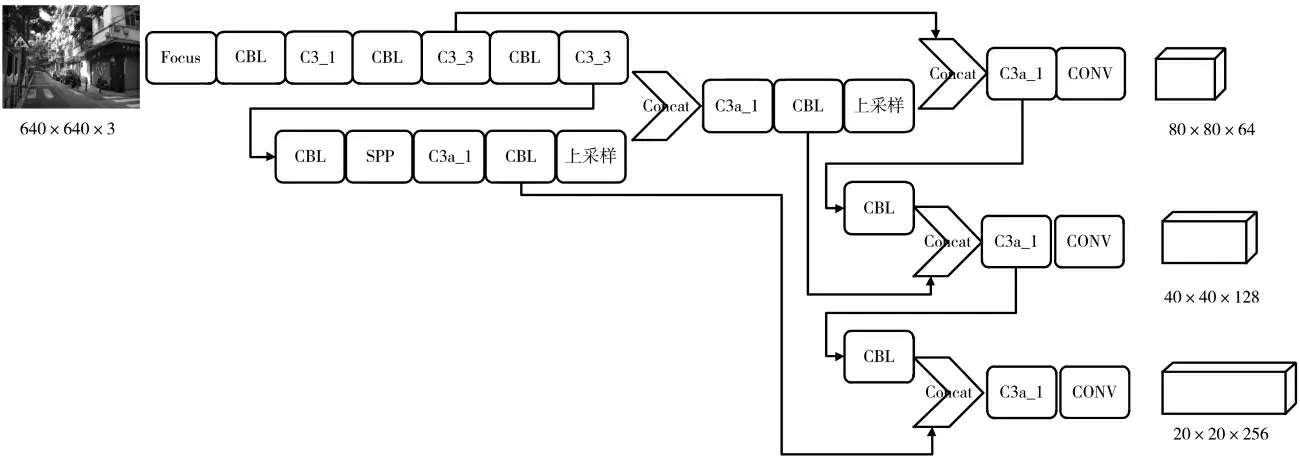
图8 网络结构
其中CBL 模块如图9 所示。批量正则化(BN)是避免梯度消失和梯度爆炸的有效手段。网络中,在卷积操作(CONV)和激活函数中间加入BN 模块,可以提高模型的泛化能力,加快学习收敛速度。

图9 CBL 模块
Focus 模块如图10 所示。在获得输入图像时,进行滑动取样(Slice)和最大池化(Maxpool)操作,处理后的数据进行组合(Concat),从而将高分辨率图片转换成低分辨率多通道数据,之后进行卷积等操作。
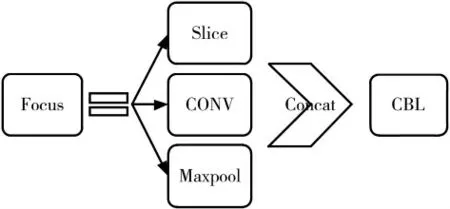
图10 Focus 模块
C3_X 模块如图11 所示。网络在深度增加时会出现退化问题,残差模块(Resunit)在加深网络的同时,有效地解决了这一问题。将残差模块的输出与卷积后特征进行组合,进一步增加网络特征的的获取。
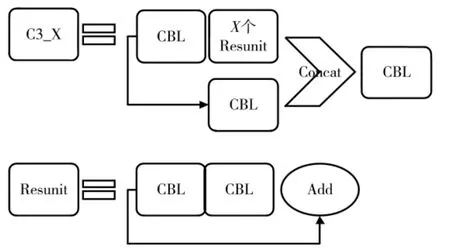
图11 C3_X 模块
SPP 模块如图12 所示。该模块可以有效提升网络的感受野,将特征中的重要部分分离出来,同时也不会给网络增加硬件消耗。
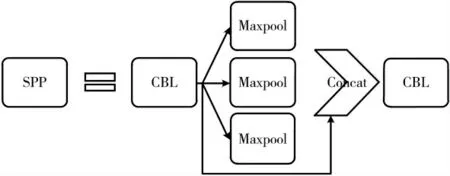
图12 SPP 模块
3 实验与结果分析
3.1 实验环境及数据
本文研究的硬件环境为i5 处理器,内存为16 GB,显卡为NVIDIAGeForce1660,操作系统为Ubantu18.04。软件环境为PyTorch2.0,Pyhon3.8。
研究中,对交通标志中的9 类标签数据进行检测。训练数据使用本文提出的标签结合现实方法生成,测试数据集选自TT100K 以及采集的图片,每类30 张共270张用于检测网络的效果。
网络训练时,初始学习率设置为0.001,权重衰减系数为0.000 5,迭代次数为500。
3.2 评价指标
目标检测算法常用的两个指标为mAP 和检测速度(f/s)。其中,mAP 代表多类别中AP 的平均值。AP 是查全率(Recall)和查准率(Precision)曲线围成的面积。Recall 和Precision 计算时,需要根据真实标签将检测结果划分为真正例(tp)、真反例(tn)、假正例(fp)、假反例(fn)。
Recall 表示正确检测到的样本数占真实样本数的比例,计算公式如下:

Precision 表示正确检测到样本数占总检出样本数的比例,计算公式如下:

3.3 实验结果与分析
实验中,为验证标签结合现实场景生成数据集的有效性,以及交通标志标签和背景对于检测结果的影响,首先,将9 类交通标志标签每类分别增强10 张、20 张以及30 张,分别与10 张背景进行融合。使用本文方法与YOLOv3tiny、YOLOv5S 分别训练后得到的mAP 值进行对比,如图13 所示。
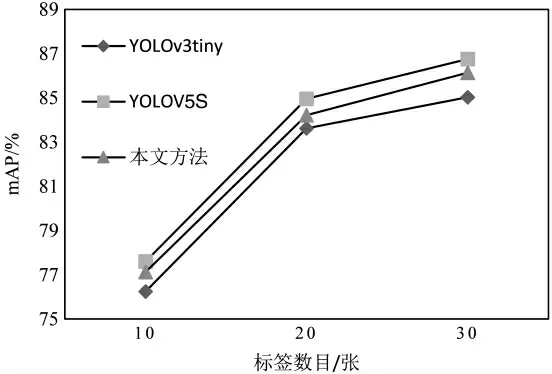
图13 不同标签增强数目检测效果对比
结果表明,本文提出的数据生成方式可以有效地训练3 个网络,并且随着交通标志标签增强数目的增加,网络的检测效果也随之改善。
在9 类交通标志标签每类增强30 张的基础上,增加背景图片为20 张、30 张,使用本文方法与YOLOv3tiny、YOLOv5S 分别训练后得到的mAP 值进行对比,如图14所示。
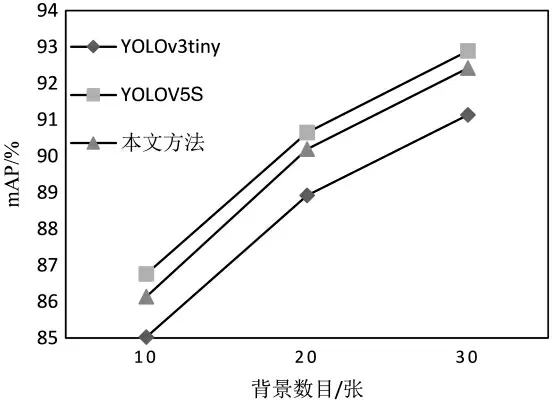
图14 不同背景图片数目检测效果对比
结果表明,增加背景图片可以有效地提升网络的检测效果。最终,通过将交通标志标签每类增强30 张,背景图片30 张生成训练集,网络检测效果mAP、检测速度和权重大小如表1 所示。

表1 最终检测结果
实验结果充分证明,本文提出的标签结合现实场景生成交通标志训练集能够有效地训练检测网络,并且可以通过增加交通标志标签和背景改善网络的检测效果。本文优化的网络在保证检测效果基础上,具有更小的体积和更快的检测速度。部分检测结果如图15 所示。

图15 检测结果示例
4 结论
本文针对交通标志的分类检测,提出交通标志标签结合现实场景方式,生成深度学习网络所需要的训练数据。该方法只需要对交通标志标签进行适当的数据增强,之后与背景图片进行结合。训练用的位置类别文件可以自动生成,节省了大量的人力物力。针对交通标志检测优化的网络虽在mAP 上低于YOLOv5S,但在检测速度和权重大小上更优,有利于降低硬件成本。
