基于实体注意力的生成式摘要算法
2022-04-14李萧洋周安民
李萧洋,周安民
(四川大学网络空间安全学院,成都 610065)
0 引言
大数据时代的到来使得信息的获取和传播日益便捷,但随之而来的信息过载问题也不容小觑。文本摘要作为从海量的信息中提取出关键信息的重要手段,旨在从原文本中提炼出简洁精炼且能够反映原文中心内容的短文,从而帮助读者从较长文本中快速筛选出有效信息,达到快速浏览、有效筛选、精准阅读的效果。然而,人工提取摘要耗时费力,因此自动文本摘要技术应运而生。
近年来,自动文本摘要任务已经成为了自然语言处理领域的热门研究方向之一,并且在医学、新闻、金融、学术等领域都有实际的应用,如观点摘要、专利摘要、新闻摘要等。现有的自动文摘方法主要分为抽取式和生成式两大类。前者的核心在于从原始文档中提取关键的短语或句子进行重组,该方法提取出来的摘要能够保留文章中的关键信息且有着良好的语法,但是由于缺乏某些特定的连接词往往可读性较低。后者是模仿人类归纳摘要的过程对原文的内容进行理解和压缩,该方法可以根据语义内容来生成摘要且可以生成原文中未出现的内容,但是往往依赖于大量高质量标注数据来训练模型,且可能出现一些语法与事实方面的错误。
针对生成式摘要中存在的语法错误与事实描述不准确的问题,本文提出了一种基于seq2seq模型并融合时序信息与实体信息的生成式摘要算法,并在开源的中文长文本摘要数据集CLTS上对其有效性进行了验证。
1 相关研究
随着深度学习的发展,现有的生成式自动文摘方法主要利用深度学习的相关知识对文本进行自动建模与分析,快速准确地从源文本中提取有效信息,在舆情分析、智能问答、观点挖掘等方面都有广泛的应用。
Nallapati等将循环神经网络与注意力机制相结合构建了一个端到端的摘要生成系统,使得解码器在生成的每一步都聚焦于当前的输入,在主流的摘要生成数据集上都取得了较好的效果,但是模型的生成能力依然受限于词汇表。在此基础上,See等提出了指针网络来解决词汇表限制问题,即在每一个解码时刻由指针网络决定是根据词汇表生成词语还是从原文中直接复制,进一步提高了生成摘要的可读性。此外,随着自然语言处理领域的发展,Liu等提出了一种基于BERT模型的摘要生成方法,通过使用不同的优化器对编码端和解码端进行微调,使生成式摘要的质量达到了新的高度。
2 基于实体注意力的生成式摘要模型
2.1 问题分析
现有的生成式摘要算法虽然能够取得比较好的可读性,但仍然存在着以下问题:①现有的研究成果大多面向英文新闻文本,针对中文长文本的研究比较少。②当处理长文本问题时,由于神经网络的记忆能力有限,会导致部分关键信息的丢失;另外处理长时记忆问题时往往需要比较大的资源和时间开销。③由于某些特定的实体词语难以被神经网络学习,现有方法生成的摘要尽管有着较高的可读性,但是在事实准确性方面却有所欠缺。
针对上述问题,本文面向中文长文本摘要,聚焦于实体信息和时序信息,提出了一种基于实体注意力的生成式摘要算法。该算法基于seq2seq模型,将实体信息引入编码器端以及损失函数中,在保留模型生成可读性摘要能力的同时,提高生成摘要的事实准确性。
2.2 基于实体注意力的生成式摘要模型
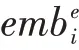

图1 基于实体注意力的生成式摘要模型
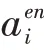
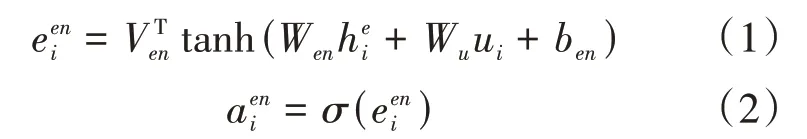
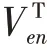
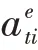
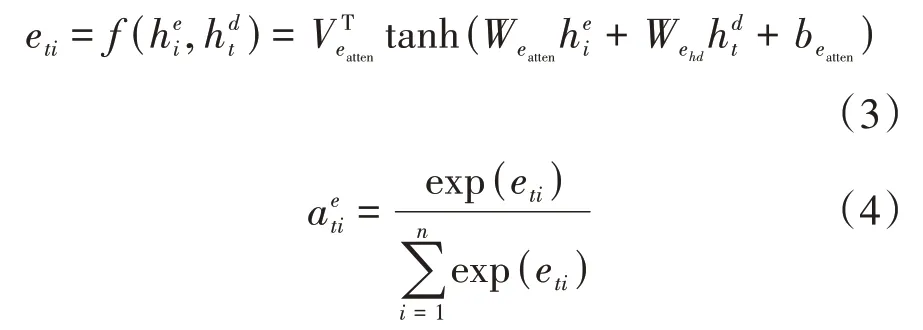
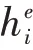
最后编码器端的语义向量由以上两种注意力混合而成,其计算如公式(5):
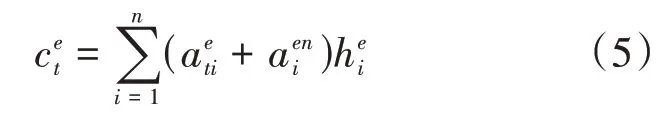

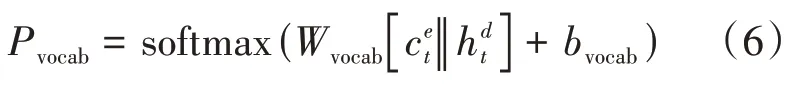
其中、为模型要学习的参数;||代表向量的拼接。
其次使用指针开关来衡量一个词应该采取生成策略还是复制策略,充分考虑编码器端语义向量c、解码器端隐藏状态h和解码器端的输入x,其计算公式如(7):
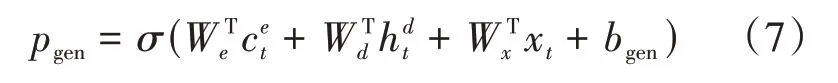
其中 、 、 、为模型要学习的参数。
最后得到扩充后的词汇表分布如公式(8)所示:
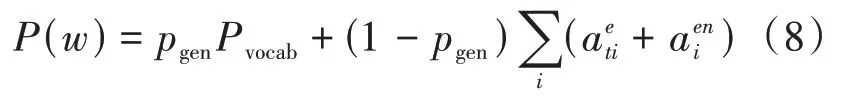
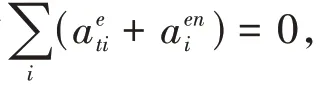
2.3 损失函数
在传统的seq2seq模型中,通常以最小化每一个解码时刻的最大似然损失为目标来训练模型,即,对于输入文章,记参考摘要为={,,…,},模型训练的目标函数如公式(9):
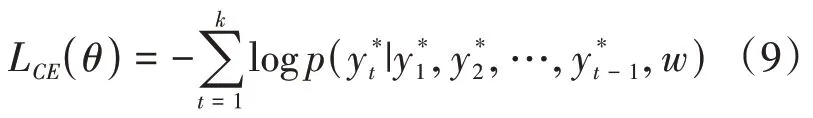
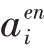
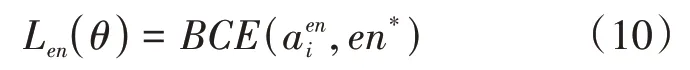
其中代表传统的二进制交叉熵函数;代表当前词语是否为实体,如果当前词语为实体则=1;否则,=0。
对以上两种损失函数进行加权求和得到最终的损失函数形式,如公式(11):
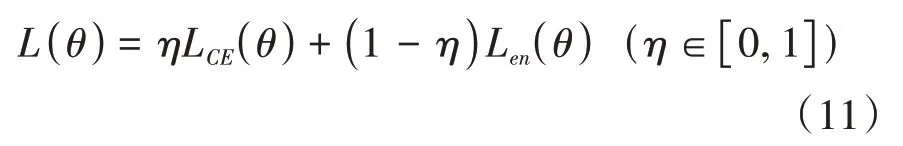
3 实验结果与分析
3.1 实验数据集
本文使用Liu等收集并整理的中文新闻长文本摘要数据集,该数据集收集了澎湃新闻网站自2014年7月22日至2020年4月20日之间发表的新闻文章以及由专业编辑编写的摘要。共包含185397篇文章摘要对,涵盖政治、军事、经济、娱乐等多个领域,并且在多个主流模型上测试都有较好的效果。
3.2 实验环境与参数设置
本实验在Ubuntu 18.04.4、GeForce RTX 2080的环境下进行,实验模型在Python 3.6.12、Pytorch 1.7.1的环境下进行训练。输入的词向量为经人民日报语料库训练的300维word2vec词向量,长短时记忆网络(LSTM)的隐藏层大小为300维,编码器端为双层LSTM,解码器端为单层LSTM,批训练大小为8,初始学习率为0.001,迭代次数为50000次,词汇表大小为50000。在进行实体识别时使用standfordnlp工具。实验在生成摘要时设置输入句子的最大长度为800,输出摘要的最大长度为100,采用束宽大小为4的束搜索来寻找解码时的最优结果。实验参数表如表1所示。
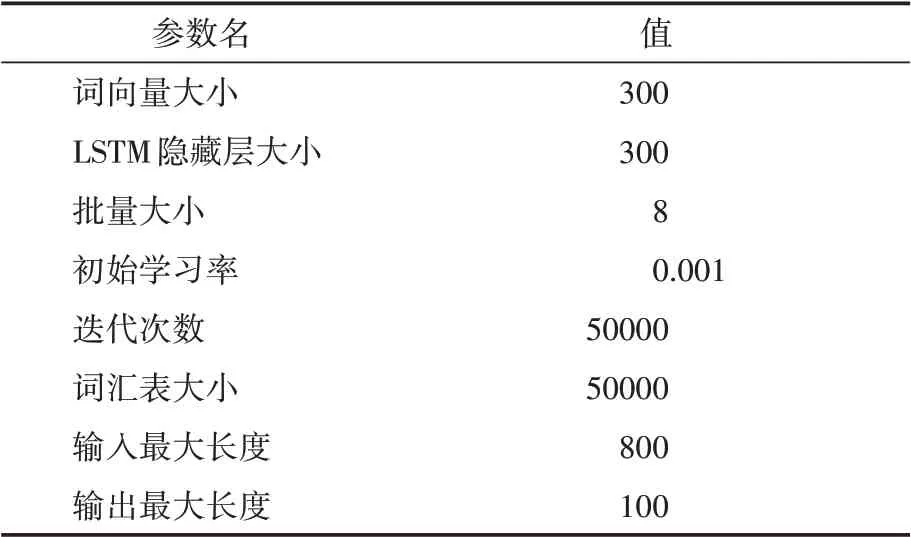
表1 实验参数
3.3 评价指标
本文使用文本摘要领域常用的ROUGE来对生成文本的可读性进行评价,具体使用ROUGE-N(=1,2)和ROUGE-L。其中ROUGEN通过计算生成摘要和人工摘要元组的召回率来评估可读性,具体计算公式如(12):
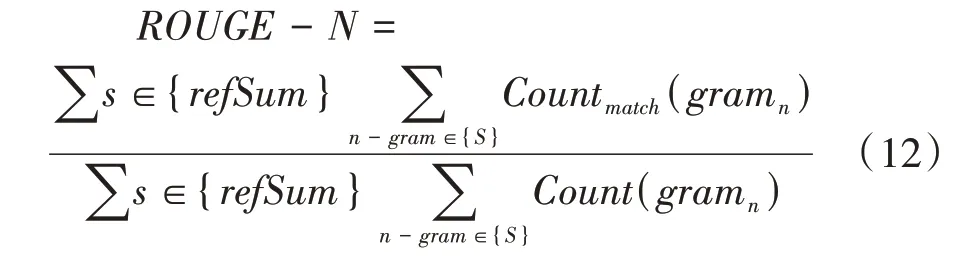
其中{}为人工摘要,Count(gram)表示人工摘要和生成摘要的共有元组的个数,(gram)表示参考摘要中元组的个数。
ROUGE-L使用人工摘要和生成摘要的最长公 共 子 序 列(Longest Common Subsequence,LSC)来衡量生成句子的可读性。其具体计算公式如(13)—(15)所示:
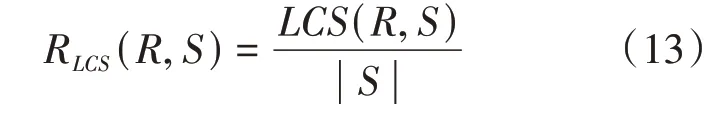
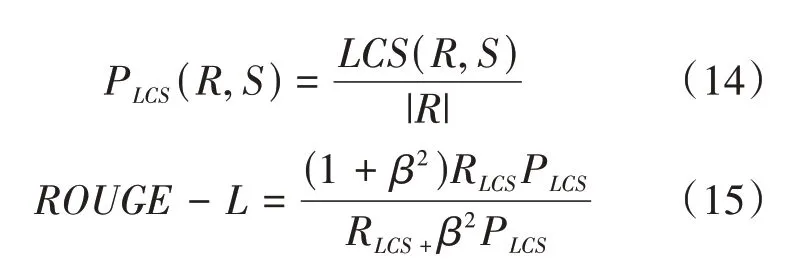
其中 ||表示生成摘要的长度,||表示人工摘要的长度,(,)表示人工摘要与生成摘要二者的最长公共子序列的长度,为精确率P与召回率R的比值。
3.4 实验结果与分析
为了确定损失函数中实体信息和可读性信息所占的比例,本文首先对公式(11)中超参数的取值进行了实验,并最终确定以0.75作为后续实验中的取值,具体实验结果如图2所示。
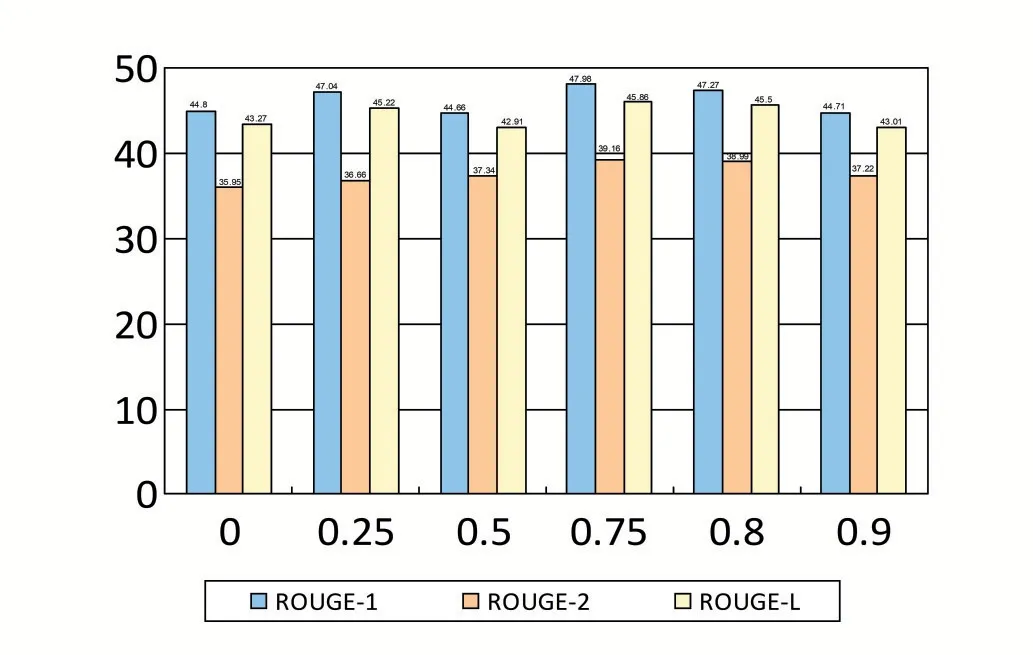
图2 超参数η实验结果
如图2所示,当=0.75时所生成的摘要在ROUGE-1、ROUGE-2和ROUGE-L评分上都有着较好的效果。此外,从图中还能观察到,随着的增大,即随着损失函数中实体比例的上升,生成摘要的可读性整体呈现先上升后下降的趋势。这是由于随着损失函数中实体比例的上升,模型将更加倾向于学习实体信息而削弱了对原文内容的学习,从而导致了可读性得分的下降。
另外,为了验证本文所提出方法的有效性,我们将多个模型在CLTS数据集上的效果进行了对比,不同模型之间的ROUGE分数对比如表2所示。
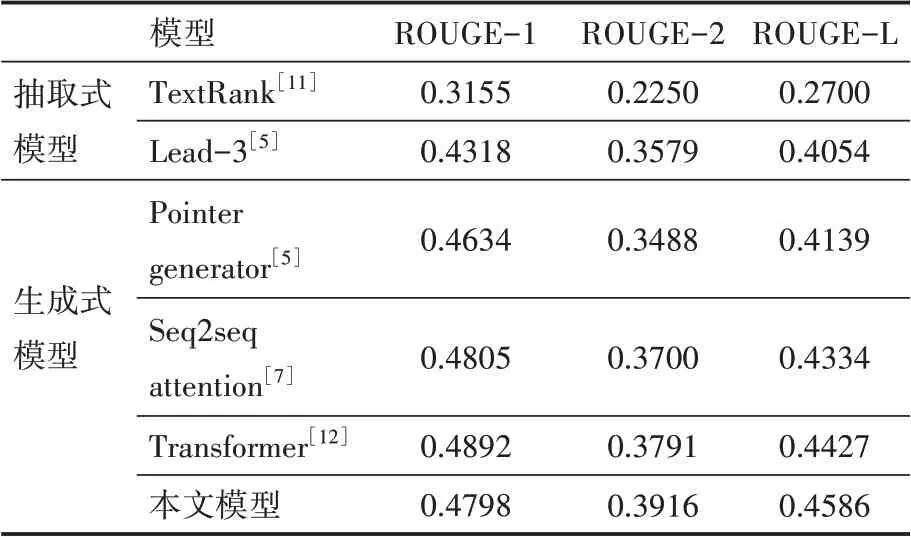
表2 不同模型对比结果
通过对表中的数据进行分析可以得到以下结论:①总的来说,生成式模型得到的摘要的可读性高于抽取式模型,这是由于传统的抽取式模型有着较为简单的模型结构,并且在对原文内容进行抽取时由于缺乏了部分关键连接词而导致可读性较低。②本文所提出的模型在ROUGE-2和ROUGE-L评分上都取得了比其他模型更优的结果,由此可以说明本文所提出的方法在以恰当的比例引入了实体信息后,在摘要生成任务上有着更为优异的表现。③通过对生成句子的分析,可以发现本文提出的模型能够识别出更多的关键实体。
4 结语
本文针对中文新闻长文本摘要中存在的可读性以及事实准确性方面的缺陷,在传统的seq2seq模型的基础上,提出了基于时序注意力和实体注意力融合的生成式摘要模型,并在损失函数中引入了实体信息,使模型在保证原有可读性的基础上能够更进一步地学习到事实信息,从而进一步提高了自动文摘的质量。实验结果表明,本文所提出的模型在ROUGE评分上与其他模型相比较得到了显著提升。下一步的研究工作是考虑如何将该算法从新闻摘要领域迁移到其他领域,并进一步降低模型消耗。
