基于多元混沌时间序列PS-LSTM污染物预测模型*
2022-04-12王圣伟娄天泷绽玉林李鸿鸿
王圣伟, 李 萍, 娄天泷, 绽玉林, 李鸿鸿
(西北师范大学 计算机科学与工程学院,甘肃 兰州 730070)
0 引 言
随着我国经济的迅速发展、工业化和城市化的进程不断加快,在消耗水资源的同时也排放大量的污水和其他污染物,其中对环境的污染中重金属污染尤为突出。因此精准预测流域重金属污染程度有着重要的研究意义。法国的学者Ruelle与荷兰的学者Takens[1]在他们共同发表的《论湍流的本质》中首次对湍流使用混沌理论来进行描述,并在研究过程中通过数学论证的方法证明了动力系统中“奇怪吸引子”的存在。1973年,日本学者发现一种杂乱的振动形态—Ueda吸引子[2]。1975年,李天岩和Yorke共同给出了在闭区间上连续的自映射的混沌定义[3]。而人工神经网络(artificial neural network,ANN)预测土壤重金属含量与混沌相空间相结合研究较为鲜见,在过去几十年,ANN被广泛应用于不同环境工程领域[4~6]。实际应用中流域重金属含量的高低受到温度、降水、pH值等多因素的共同影响,单一依靠重金属的含量去预测重金属含量的方法准确性较低,所以本文根据影响重金属含量的多种因素构建一个多元时间序列的混沌系统。通过构建多变量混沌时间序列,改进神经网络长短期记忆(long short-term memory,LSTM)模型,准确挖掘变量间内在联系是进行污染物预测的研究方向。
本文通过多元混沌时间序列的重构相空间构建,利用相空间(phase space,PS)重构和增加窥视孔连接的LSTM循环神经网络LSTM时间序列预测模型相结合,提出多元混沌时间序列的PS-LSTM预测模型,实现对流域污染物重金属含量的精准预测。
1 材料与方法
1.1 研究区概况
大夏河是黄河上游的重要支流,其发源于青海省的同仁县,流经夏河县、临夏县等地,最后注入刘家峡水库,整个流域总面积达到7 154 km2。大夏河整个流域包含了30个乡镇268个村,流域内生活的人口达到59.96万人。多年平均流量在大夏河县城段为9.44 m3/s,多年平均径流量达到3.12亿m3。在降雨方面,流域内年平均降水量为44.4 cm,且分布不均匀在时间和空间范围上,降水主要集中在7~9月,大部分以连续降雨或高强度暴雨的形式出现。大夏河流域独特的地形和分布不均的降水在一定程度上影响着土壤中重金属的含量。
1.2 多元混沌时间序列的相空间重构模型
1.2.1 多元变量的选取
在各类流域的复杂生态系统预测研究中,其影响因素具有多样性。Lorenz于1936年在《确定性的非周期流》[7]中指出:在三阶非线性自治系统中可能会出现混乱解,并因此提出了著名的Lorenz混沌方程,由此产生三变量的混沌时间序列。因此,本文结合重金属含量的相空间经过反复实验,最终选择三个影响因素共同构建多元混沌的相空间。对于影响因素的选择本文使用较广泛的相关系数法,通过Spss软件计算各影响因素与重金属含量的相关性,最终选择相关性最高的三个影响因素温度、日径流和重金属含量。
本文以大夏河2016年11月到2017年12月的数据计算温度、pH值、降水、日径流,四种数据每星期求一平均值与周数据的重金属含量的相关性,结果如表1所示。

表1 各时间序列与当地平均重金属含量的相关性
如表1所示可以明显看出温度、降水以及日径流数据与平均重金属含量相关性较高。后续研究中表明降水数据不具备混沌特性,因此,选择温度、日径流和重金属含量共同重构相空间,其中重金属含量和温度、日径流分别作为预测模型的因子。
1.2.2 延迟时间和嵌入维数的确定
混沌时间序列分析的基础是重构相空间,Takens F等人[8]使用延迟坐标的方法对混沌时间序列进行相空间重构。
X={Xi|Xi=[xi,xi+τ,…,xi+(m-1)τ]T,i=1,2,…,M}
(1)
式中m为嵌入维数,τ为时间延迟,M=N-(m-1)τ为相空间中实际点数。Kugiumtzis D提出的嵌入窗法,明确指出两者相关且依靠嵌入窗τw=(m-1)τ相互关联[9]。本文采用陆振波改进的C—C方法[10]在MATLAB中实现。得出各时间序列的时间延迟τ以及嵌入窗τw,根据公式τw=(m-1)τ计算三个时间序列相关参数,结果如表2所示。

表2 重构相空间中各影响因素的参数
1.2.3 最大Lyapunov指数
本文通过最大Lyapunov指数验证该序列混沌特性,采用小数据量法计算该时间序列的Lyapunov指数进行混沌判别,计算原理如下:
首先寻找相空间中Yj点的近邻点并对其进行分离,距离计算方法如下
(2)
其次,计算相空间中每个点Yj对应i个里斯按时间步后的距离dj(i)为
dj(i)=|Yj+1-Yi+i|
(3)
对上述两步每个i求得的j的lndj(i)平均y(i),通过最小二乘法计算回归直线的斜率,其斜率为此时间序列的最大Lyapunov指数。当最大Lyapunov指数λ大于0时,可以对该时间序列的混沌特性进行判定,反之亦然。
经过MATLAB计算可得,重金属含量、温度和日径流的时间序列的最大Lyapunov指数分别为0.060 5,0.021 4和0.054 9,结果均大于0,说明以上三个分量均具有混沌特性。降水时间序列虽然与重金属含量的相关性较高,但由于大夏河流域降水概率较小甚至为0,所以该时间序列不具有混沌特性,在此予以剔除,不参与相空间的重构。
1.2.4 多元混沌相空间
在此简单介绍多元相空间建立的基本步骤:设有Q个变量时间序列X1,X2,…,XQ且Xq={Xq,i,Xq,2,…,Xq,n},q=1,2,…,Q,N为观测分量时间序列长度,对应变量的时间延迟为τ1,τ2,…τQ,嵌入维数为m1,m2,…,mQ,此时多元相空间产生的相点数L=N-max[(mq-1)τq]。相空间的P时刻的状态坐标表示为
Vp=[x1,p,x1,p-τ1,…,x1,p-(m1-1)τ1;x2,p,x2,p-τ2,…,
x2,p-(m2-1)τ2;…;xQ,p,xQ,p-τQ,…,xQ,p-(mQ-1)τQ]
(4)
多变量时间序列重构的相空间矩阵为
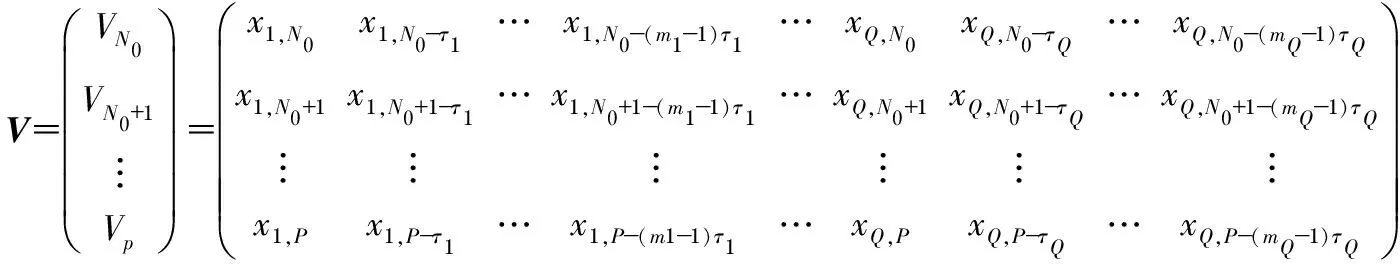
(5)
P=N0,N0+1,…,N
(6)

1.2.5 重建关于重金属含量的多元混沌相空间
根据2016年到2017年两年共117个数据选择前100个数据建立相空间,后17个数据作为预测模型的测试集。由于其中重金属含量、温度和日径流数据间数值差距较大,因此,对其进行归一化从而降低最终预测误差。根据表2给出的m和τ两个参数及式(5)进行相空间重构,得到一个8×88的流域污染系统相空间矩阵式如下
(7)
N0=13,相空间总维数M=2+4+2=8。
矩阵中x1,x2,x3分别对应的是重金属含量、温度和日径流指标原始时间序列,PS-LSTM神经网络的输入向量和输出向量为相空间矩阵中的每一行,即将每一个状态点作为上一神经网络训练集样本输出和下一神经网络训练集样本的输入,则训练集样本输入和输出均为8×88。
1.3 基于LSTM神经网络模型预测仿真
LSTM神经网络主要通过记忆单元来实现节点的不断更新,从而有效解决了传统径向基神经网络中对于远距离数据的依赖特性,LSTM循环神经网络作为改进的RNN结构[11],在RNN模型的基础上引入了“记忆细胞”的概念,2000年,Gers和Schmidhuber提出窥视孔连接,弥补忘记门的一个缺点:目前已有的“记忆细胞”不能够影响到“输入门”和“输出门”在下一时刻的输出,对上一时间的序列处理会使整个“记忆细胞”丢失了部分信息,其基本原理是首先将上一个神经元输出的Ct与此神经元的输入共同输入到“输入门”和“忘记门”,然后将其输入到“记忆细胞”当中;由“记忆细胞”输出的数据在输入到“输出门”的同时也输入到下一时刻的“输入门”和“忘记门”;最后,“忘记门”输出的数据与激活后的数据一起作为整个“记忆细胞”的输出。增加窥视孔后“记忆细胞”改变的运行公式如下
it=σ(Wixxt+Wihht-1+WicCt-1)
(8)
ft=σ(Wfxxt+Wfhht-1+WfcCt-1)
(9)
ot=σ(Woxxt+Wohht-1+WocCt-1)
(10)
式中x为输入向量,h为输出向量,Ct为t时刻在记忆细胞中的更新状态,it,ft,ot,Ct,ht分别为输入门、遗忘门、输出门、记忆细胞以及在t时刻的输出;xt则为t时刻的输入,ht-1,Ct-1分别为隐含层及记忆细胞在t-1时刻的输出。
在PS-LSTM时间序列预测模型中使用多门协作的方式避免了梯度弥散并且能够最大程度上模拟输入因子的共同预测。PS-LSTM时间序列预测模型通过Python编码实现,以大夏河流域重金属的多元混沌相空间的状态坐标为多变量输入,本次模型将按照测试集85 %的比例选取,所以前75个数据作为训练样本,重金属含量中的最后13个数据作为测试样本进行实验。使用单层隐含层的PS-LSTM模型,总的训练迭代次数为300。本文在训练模型时将其一次训练所选取的样本数设置为45,时间步长为3,隐含层节点为100,输出节点为1,利用平均绝对误差(mean absolute error,MAE)做损失函数,Adam的随机梯度下降做优化,根据均方根误差(root mean square error,RMSE)进行模型评估。当0迭代到50次时,测试损失与训练损失下降较快,迭代到第100次时,模型损失达到最低并趋于平缓,如图1所示可知测试损失在绝大多数的情况下高于训练损失,证明模型拟合较为成功,适合作为重金属含量的预测模型。
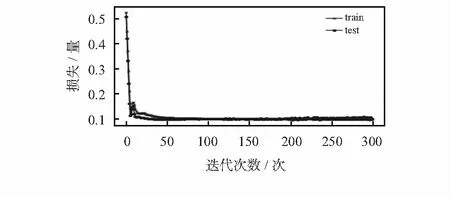
图1 不同训练时期训练集和测试集损失
2 结果与分析
2.1 基于Volterra级数模型的重金属含量预测
Volterra级数在收敛区域的判定上有着严格的要求,增加了它的使用难度[12]。本文以重金属含量为输入数据使用陆振波的MATLAB混沌工具箱中的Volterra级数一步预测模型进行预测,其中只使用2016年11月至2017年12月的117个重金属含量数据,并没有建立关于重金属的相空间。从图2所示的预测结果中可以看出开始预测的4个数据较为准确,但是随后的13个预测数据相比真实值有较大的差距。

图2 Volterra级数预测结果
2.2 基于径向基函数神经网络的重金属含量预测
径向基函数(radial basis function,RBF)是前向型神经网络,主要由输入层、隐含层、输出层三部分组成[13]。RBF神经网络依靠其简单的网络结构、较快的收敛速度和能够逼近任意非线性函数的特征使其在时间序列分析和图形识别处理等领域获得较为广泛的应用[14]。
其在关于有噪声的重金属含量时间序列预测上能够实现非线性的局部预测。本文使用陆振波的MATLAB混沌工具箱中的RBF神经网络预测模型实现对重金属含量的预测,预测结果如图3所示。
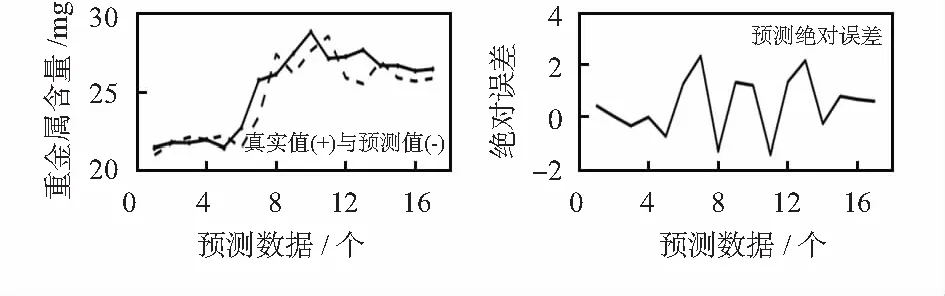
图3 RBF神经网络预测结果
2.3 基于支持向量回归的预测
支持向量回归(support vector regression,SVR) 在函数回归预测方面的应用依据支持向量机(support vector machine,SVM)原理,由SVM在其分类问题上所推广而来,其是以预测的相关性原则作为基础,确定预测目标的各特征与预测目标之间的数学模型,利用该模型对其特征的变化值进行目标预测。
大夏河流域重金属含量在MATLAB中使用SVR方法进行了单因子的预测,由于重金属含量属于小数据的预测,因此,SVR的小数据量非线性预测能够具有较强的对比性。由图4的预测结果图所示前5个重金属含量的预测准确程度相对较为理想,但后面的预测准确程度较差。SVR预测准确程度相比其他两个对比实验具有较好的效果,但经过改进的LSTM预测模型在预测准确程度上更准确。
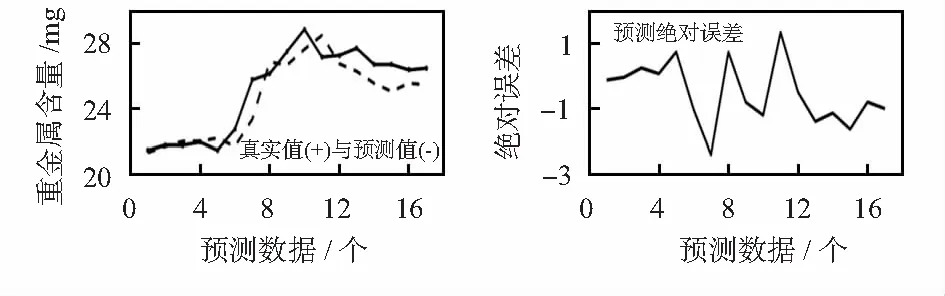
图4 基于SVR回归预测结果图
由表3可得,在平均绝对误差和均方根误差指标方面,本文的预测模型的评价指标值RMSE均小于Volterra级数,RBF神经网络,SVR测试模型,而决定系数比其他三种预测模型高,说明PS-LSTM预测模型的拟合程度比其他三种模型优度高,因此证明建立关于重金属含量的多元混沌相空间是有一定的实际意义,并且LSTM预测模型对于有噪声的混沌时间序列预测精度上具有优势。

表3 各预测模型的结果评价
3 结束语
本文利用较为完善的增加窥视孔的LSTM—RNN模型,LSTM对有噪声的重金属含量预测相较Volterra级数预测、RBF神经网络预测以及基于支持向量机回归预测模型在预测精度上具有一定优势。因此本文的预测模型具有一定的意义。采用相空间与门控循环单元(GRU)进一步的改进相结合的方法可以实现更加精准预测,这将是下一步的研究重点。
