网络流量采集与分析系统的实现
2022-04-12龙恒张劲勇吴红梅
龙恒 张劲勇 吴红梅

摘 要: 在使用基于网络的应用或服务的过程中会遇到各种问题,需要使用流量分析工具找出原因才能解决问题。文章阐述了一套流量采集及分析系统的实现过程,重点讲解了数据包的捕获技术及分析方法、后台进程的结构,以及线程之间的交互过程、采用双缓冲区方案实现线程同步以避免出现资源竞争、使用内存预分配技术来提高内存缓冲区数据结构的性能等方面的内容。该系统已实际运行一年多,可以解决网络应用中的常见问题,具有较强的实用性。
关键词: 数据包捕获; 数据包分析; Npcap; 线程同步; 内存预分配
中图分类号:TP311 文献标识码:A 文章编号:1006-8228(2022)04-24-05
Implement of network traffic collection and analysis system
Long Heng Zhang Jinyong Wu Hongmei
(Maoming Polytechnic, Maoming, Guangdong 525000, China)
Abstract: In the process of using network-based applications or services, various problems are encountered, and it is necessary to use traffic analysis tools to find out the reasons and solve these problems. In this paper, the realization process of a set of flow collection and analysis system is expounded. It focuses on the capture technology and analysis method of data packets, the structure of the background process, and the interaction process between threads. The double buffer scheme is used to achieve thread synchronization to avoid resource contention. The memory pre-allocation technique is used to improve the performance of the memory buffer data structure. The system has been in practical use for more than a year. It can solve common problems in network applications, and has strong practicability.
Key words: packet capture; packet analysis; Npcap; thread synchronization; memory pre-allocation
0 引言
随着互联网的普及,很多应用和服务都需要联网才能使用,这些应用和服务在使用过程中会出现各种由于网络原因导致的问题,例如网页加载缓慢、视频播放卡顿、服务不可用等等。管理员需要对网络中的流量数据进行分析,从中获取有用的信息,才能找到并解决问题。
本文详细介绍了一套网络流量采集与分析系统的实现方法,该系统分为前后台两部分,后台进程捕获数据包然后对其进行分解,根据数据包首部字段的值和应用层数据对数据包进行分类并将指定信息保存到数据库中;前端应用负责对保存在数据库中的数据进行统计分析并将结果显示给用户。这套系统难点在于后台的实现,这也是本文關注的重点。
1 数据包捕获技术
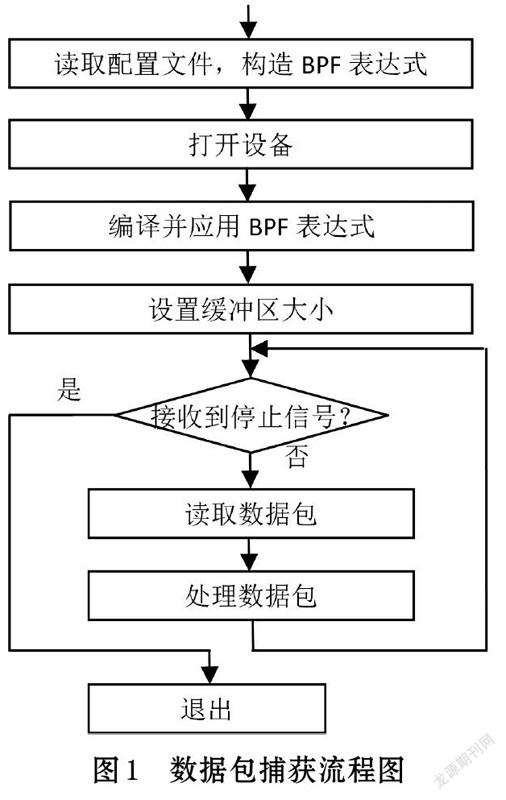
本系统使用Npcap技术捕获数据包,Npcap 是一个用于Windows系统的数据包捕获和网络分析架构,是Winpcap的后续版本,架构与工作原理与Winpcap相同,但是具有更好的性能、更强的可移植性、更高的安全性以及更丰富的功能。其结构包括一个名为NPF的内核模式驱动程序和一组与 libpcap 兼容的用户态API函数[1],应用程序只需要调用这些API函数即可以实现捕获数据包的功能,步骤如图1所示。
⑴ 系统在加载时读取配置文件,完成初始化工作,根据配置文件里面的参数生成BPF表达式。
⑵ 打开指定的设备(网卡)并获得该设备的句柄。
⑶ 对BPF表达式进行编译将其与上一步获得的设备句柄关联起来,对于实时捕获的情况,可以根据BPF表达式指定的条件在内核模式下进行过滤,以避免将不符合条件的数据包从内核态复制到用户态[2]。
⑷ 有两个对性能有重要的影响的缓冲区需要设置。一个是与网卡关联的内核缓冲区的大小,其用来保存捕获的数据包,使得应用程序不必实时读取这些数据包,如果这个缓冲区设置得太小,易造成数据包丢失,如果设置得太大,将会对操作系统的不可分页内存造成浪费[2]。另一个是应用层缓冲区,用来保存应用程序从内核读取的数据包,这个缓冲区的大小决定了应用程序进行一次系统调用能够返回的数据包的数量,将这个缓冲区设置得大一些可以减少系统调用的次数[3]。
⑸ 在一个循环中读取数据包,然后进行分析和处理,如果接收到退出信号,将结束数据包的捕获过程。
2 数据包的处理流程
在捕获数据包时,Npcap的内核驱动程序NPF对网卡进行监听,捕获符合条件的数据包并将其完整地交给用户层的应用程序,整个过程不经过操作系统的协议栈[4],应用程序收到是链路层的数据帧。40C76890-AA4A-4E25-83E2-8E57BD8B7F75
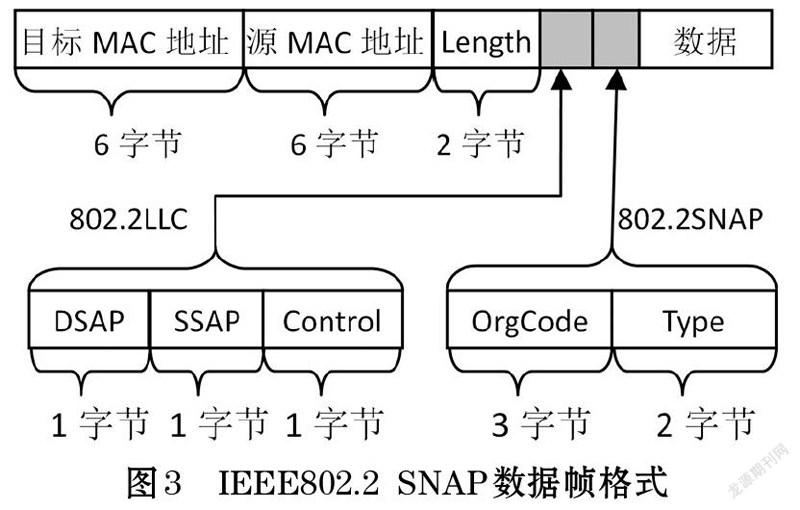
RFC 1042推荐,使用TCP/IP协议的主机必须能发送和接收采用Ethernet II (RFC 894)格式封装的数据帧、应该能处理接收到的采用IEEE802.2 SNAP (RFC1042)格式封装的数据帧[5]。Ethernet II数据帧格式见图2[5],IEEE802.2 SNAP数据帧格式见图3[6],图1、图2省略了CRC校验码。
由于以太网数据包的最大长度是1500字节,IEEE802.2 SNAP型的数据帧的第13和14字节表示数据包长度,所以其最大值为1500(十六进制为0x05DC)。而Ethernet II型的第13和14字节表示上层协议类型,取值范围是0x0600至0xFFFF,因此通过这两个字节的值就可以区分这两种类型的数据帧,另外IEEE802.2 SNAP型还要求DSAP和SSAP字段的值均固定为170、control字段的值固定为3、OrgCode字段的值固定为0,Type字段的意义与Ethernet II型Type字段相同[6]。
采集线程读取数据包后获得一个指向数据的链路层首部的指针,对这个指针指向的缓冲区中的数据进行分析,即可获得数据包各个部分的信息。
为了减少数据包的复制,定义了一个结构体PKPTR,其成员都是指向缓冲区相应位置的指针,在分析过程中,将这些指针指向缓冲区的正确位置。数据包处理流程如图4所示。
3 后台进程的结构
在流量较大的链路中会采集到大量的数据包,因此需要使用两个线程才能实现数据采集以及将数据保存到数据库这两个核心功能,这两个线程分别称为采集线程和存储线程。主进程初始化完成后立刻启动这两个线程,此后主进程只负责与用户交互,两个线程在主进程退出后才会结束。
采集线程捕获数据包并对其进行分析,然后将指定的数据保存在内存缓冲区中,该线程设置一个定时器,如果定时器超时,将会检查存储线程当前的状态,如果其没有处于休眠状态,表明存储线程还没有完全将上次提交的数据写入数据库,系统会认为是用户的配置不正确,将分别向两个线程发送退出信号,同时记录日志,以提示用户需要调整定时器的时间间隔、采集的数据类型及数量等参数;如果采集线程处于休眠状态,则唤醒存储线程,将采集到的数据提交给其处理,采集线程重新开始工作。存储线程负责将采集线程提交的数据写入数据库。
4 线程的同步机制
由于两个线程都需要访问保存采集数据的缓冲区,因此需要使用同步机制以避免访问冲突,常规的做法是使用操作系统提供的临界区、互斥对象或信号量等同步机制来实现。但是存储线程将数据写入数据库的时间较长,如果使用这些机制,将会导致采集线程长时间停止工作。
本系统采用双缓冲区的方案来实现同步,在主进程初始化时,预先分配两个结构完全相同的缓冲区,每个线程使用一个,当采集线程的定时器超时后,对isSleep变量进行检测,如果这个变量的值是0,表示存储线程正在工作,这种情况将被当成配置错误处理;如果isSleep变量的值为1,表示存储线程已经进入休眠状态,此时由采集进程对两个线程的缓冲区指针的指向地址进行交换,然后唤醒存儲线程。由于isSleep变量被两个线程共享,因此被定义成volatile long类型的变量,使用volatile关键字对变量进行修饰时,CPU每次都从内存读取该变量的值而不会从寄存器中读取[7],使得变量值发生变化时在不同的线程之间可见。对该变量赋值的时候需要使用InterlockedExchange函数保证操作的原子性,如果修改是原子操作,两个线程访问isSleep变量时就不会出现竞争的问题[8]。
使用双缓冲区的方案进行同步还可以避免频繁调用常规同步机制的加锁、解锁操作造成性能上的损失。定时写入机制除了可以减少存储线程被唤醒的次数,还可以充分利用数据库系统的预处理语句或者批量写入功能批量写入记录,从而提高性能。
5 数据结构
为了实现延迟写入的功能,先要将采集到的数据保存在内存缓冲区中,在定时器超时后再将数据写入数据库中。本系统以IP地址为中心对数据进行组织,需要记录的数据类型包括每个IP地址在指定的时间段内的总流量、每个会话的流量及会话过程中所产生的数据等,所使用的数据结构如图5所示。
采集线程每读取到一个数据包都会根据源IP地址和目标IP地址在数据结构中进行查找,如果存在对应的记录就将数据包的信息保存到缓冲区中,如果不存在,则需要新建一条记录之后再进行保存。在高速网络中对查找和写入的性能要求非常高,在常用的数据结构中,Hash表在查找关键字和创建新结点方面的性能优异,理想状态下Hash表的查询、插入和删除的时间复杂度都为O(1)[9]。因此,在数据结构的入口处使用一个Hash表来保存每个IP地址的数据,这个表称为入口IP地址表。
入口IP地址表的每个结点保存的数据分为汇总数据和会话数据两种,汇总数据包括该结点创建的时间、在指定时间间隔内该IP地址接收到的数据包个数和总字节数、发送出去的数据包个数和总字节数等信息;会话数据保存在一个会话表中,表的每个结点记录了当前时间间隔内两个端点(endpoint)之间的通信数据,包括发送和接收的流量、会话所产生的数据等信息。
会话表也会被频繁查找和更新,会话表与入口IP地址表有两个不同的地方,一是整个数据结构中入口IP地址表只有一个,而每个IP地址都有一个独立的会话表,因此会话表的数量会非常多;第二个是会话表只保存一个IP地址在一个时间间隔内的会话,数据量比入口IP地址表要少很多,针对这两个特点,使用红黑树作为保存会话表的数据结构。
红黑树查询、插入和删除的时间复杂度为O(logn)[10],在性能上不如Hash表,但是Hash表需要预先分配一个有一定冗余的数组用来进行散列运算,如果入口IP地址比较多,将会造成比较严重的内存浪费。另外从单个会话表来看其数据量相对较少,一次查找过程所需访问的结点不会很多且大部分运算都是比较语句,而且计算Hash值本身也要一定的运算量。综合考虑各种因素,红黑树是一个合适的选择。40C76890-AA4A-4E25-83E2-8E57BD8B7F75
图5中的SKEY是会话表的键,是一个长度固定的内存块,用来唯一标识一个会话,TCP和UDP协议数据包的SKEY的组成如图6所示,ICMP协议数据包的SKEY的组成如图7所示。
会话表的结点保存会话的详细数据,包括数据包首部字段、所访问的网站的网址、配置文件指定采集的应用层数据等。
由于记录数据时需要频繁分配内存,如果使用动态分配的方式将会产生大量的内存碎片,会导致内存空间的浪费和应用程序性能下降[11],而且内存分配和释放也需要消耗处理器的资源。
由于Hash表的键和结点、红黑树的键和节点的大小都是固定的,可以使用内存预分配技术,为这些类型的数据结构分别分配一个连续的内存块作为内存池,分配和释放内存,都通过对内存池进行操作来完成,执行的是一些调整指针指向和记录使用情况的指令。
保存会话数据的数据结构大小不是固定的,但是在采集过程中只进行内存分配,内存的释放是在将数据写入数据库之后再统一进行,根据这个特点,预分配内存的方法仍然适用,只需给这些数据结构增加一个指示长度的成员变量,与指向内存开始位置的指针一起标识所使用的内存单元即可。
下面对采集过程进行模拟测试,判断预分配内存技术对性能的影响,测试方法是创建一批数据包,通过随机指定数据包的源和目标IP地址,使得图5数据结构中的入口IP地址表中保存一定数量的IP地址,每个IP地址创建指定数量的会话,每个会话采集一个URL字符串和数据包的部分首部字段的值。
表1和表2的数据是在本系统部署的服务器上测试得出,插入和释放操作的单位为毫秒,在多台计算机上进行的多次测试都能得到类似的结果。测试中的“插入”操作包含了数据包分解和URL匹配等与内存分配无关的运算,这部分运算耗时较多,从测试结果看性能提升为20%左右;“释放”操作指的是存储线程将数据保存到数据库之后对数据结构进行重新初始化,在使用内存池的情况下内存是整块释放的,并且没有执行其他的运算,因此性能提升非常明显。
6 结束语
在我校还没有内部署专业的网络安全设备之前,经常会遇到网页加载缓慢、网速不稳定、用户访问了恶意网站却无法察觉、服务器疑似受到攻击等问题,由于无法了解网络运行的状况,解决问题时往往没有针对性,导致了不少纠纷。
该系统投入使用后,在遵守隐私管理规定的情况下对部分流量数据进行采集并保存了较长时间的历史记录,该系统提供了常用的分析功能,为网络管理人员了解网络运行状况提供了依据,从而能够快速有针对性地解决问题,在出现争议事件的时候可以通过查询流量日志数据进行处理,使得网络服务质量有所提高。
我校在开展了等保建设工作之后,部署了一批专业的网络设备,虽然这些设备在功能上与本系统有重叠的地方,但是这套系统使用简单、问题针对性强、查询结果加载速度快、稳定性高,由于有这些优点,该系统目前仍然作为一个有效的补充方案使用。
参考文献(References):
[1] RISSO F, DEGIOANNI L. An architecture for highperformance network analysis[C]. Proceedings of the 6th IEEE Symposium on Computers and Communications (ISCC 2001), Hammamet,Tunisia, July 2001:2-7
[2] Van Jacobson, Craig Leres. Npcap API. https://nmap.org/npcap/guide/wpcap/pcap.html. [2021-08-20].
[3] anonym. Developing software with Npcap. https://nmap.org/npcap/guide/npcap-devguide.html.[2021-08-20].
[4] DEGIOANNI L, BALDI M, RISSO F. Profiling andoptimization of software -based network -analysis applications proceedings[C]. The 15th IEEE Symposium on Computer Architecture and High Performance Computing (SBAC-PAD 2003) Sao Paulo, Brazil, November 2003:3-5
[5] Stevens WR.TCP/IP 详解(卷1:协议).北京:机械工业出版社,2000:15-16
[6] J.Postel,J.Reynolds.A Standard for the Transmission of IPDatagrams over IEEE 802 Networks.https://www.rfc-editor.org/rfc/rfc1042.txt. (1988) [2021-08-20].
[7] 陈睿,杨孟飞.基于编码规则的中断数据访问冲突检测方法[J].空间控制技术与应用,2017,43(3):59-65
[8] W.Richard Stevens,Stephen A.Rago. Unix環境高级编程(第2版)[M].北京:人民邮电出版社,2007:297-299
[9] William Ford,William Topp.数据结构C++语言描述[M].北京:清华大学出版社,1998:627-641
[10] Sartaj Sahni.数据结构、算法与应用-C++语言描述[M].北京:机械工业出版社,2000.334-344
[11] 刘翔,童薇.动态内存分配器研究综述[J].计算机学报,2018,41(10):2359-237840C76890-AA4A-4E25-83E2-8E57BD8B7F75
