污染源变化条件下地下水监测网优化设计
2022-04-08黄瑞瑞王锦国
黄瑞瑞,王锦国,杨 蕴
(河海大学 地球科学与工程学院,江苏 南京 211100)
近年来,地下水环境不断恶化,地下水污染问题日益突出。在地下水污染防治和修复过程中,建立和完善地下水污染监测网是获取准确的地下水污染信息的必要先决条件[1-2],是实现可持续发展和保证人类身心健康的重要工作,利用地下水污染监测可以实时掌握地下水水质变化规律,以便及时有效地监测和预警该地区地下水污染情况。由于地下水污染源往往呈现多点分布,污染源的变化影响着监测井的空间布局和数量选择。因此,在场地地下水污染监测网设计时,还需考虑多个污染源对监测网络设计的影响。
关于地下水污染监测网的设计,我国自20世纪50年代建立监测井网以来,已经形成了一定规模的监测网络,具有较为完善的管理和监测体系[3]。但是,在地下水水质监测的过程中,过量取样是较为普遍的现象[4],它将导致监测数据冗余,而且地下水监测又是长期的工程,这便意味着巨大的经济成本浪费。因此,在保证监测精度的前提下,如何寻求优化的地下水污染监测方案使得监测成本最低,是地下水监测网优化设计的关键技术难题。
20世纪70年代末,国外学者开始着手进行地下水监测网的优化设计,提出了很多经典的方法来解决昂贵的监测费用问题,比较典型的方法有Kriging法、水文地质分析法、聚类分析法、卡尔曼滤波法、信息熵法等[5],但这些方法均未综合考虑水文地质信息、监测井位、监测井数、计算量和人为主观因素对地下水监测网优化设计的影响[6-7]。本文运用模拟—优化方法对理想场地污染源变化条件下的地下水监测网进行优化设计,在不显著影响采样数据的准确性和充分性的情况下,通过剔除多余的监测井来实现长期监测成本最低的目标,并对不同的优化结果进行对比分析。
1 地下水污染监测网设计模拟—优化技术
本文采用的模拟—优化方法,包括3个主要组成部分,即地下水流和溶质运移模拟、地下水污染监测网优化设计模型以及基于遗传算法(GA)的最优搜索技术[8]。前两者是用于评估所有潜在采样设计的各种约束条件,而第3个部分是用于识别最优或接近最优的地下水污染监测网采样设计。研究中用于实现具有成本效益的地下水监测网采样优化设计的步骤如图1所示。
1.1 地下水流和溶质运移模拟
本文假定的地下水流和溶质运移模型是基于三维有限差分流动程序MODFLOW和溶质运移程序MT3DMS,2个程序共同来模拟地下水污染物在不同时间段的空间分布和变化情况,从而获取在不同位置上的污染物真实浓度值[9]。MODFLOW具有模块化结构,使其易于适应特定的应用程序;MT3DMS也同样具有模块化结构,并具有模拟污染物运移的功能,可评估污染物运移情况。
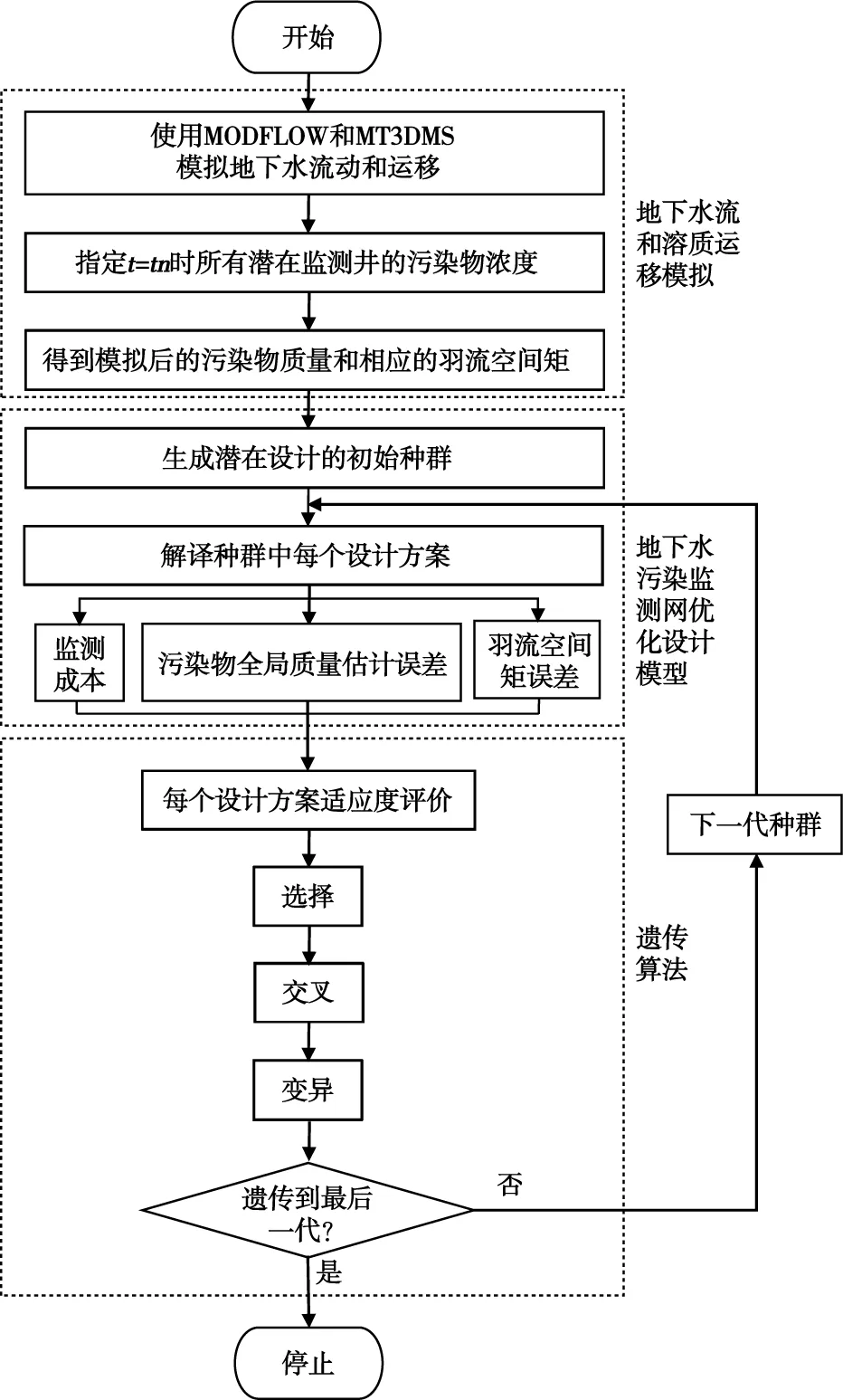
图1 基于GA的地下水采样网络设计模拟—优化流程Fig.1 Flow chart of GA-based groundwater sampling network design simulation-optimization method
1.2 地下水污染监测网优化设计模型
污染物在地下水含水层中某一特定时刻的空间分布情况可以用污染物总质量(零阶矩)、污染羽流质心的位置(一阶矩)、污染羽流围绕质心的空间分布范围(二阶矩)来描述[10]。当这3个物理特征值都已知时,就可以刻画出污染羽流的空间分布状态。
地下水污染羽流中污染物总质量可由式(1)表示:
(1)

羽流质心在t时刻的坐标位置由关于原点的一阶矩定义,可以表示为[11]:
(2)
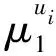
污染羽流的二阶矩描述了羽流围绕质心扩散的度量,用空间协方差张量表示:
(3)

(4)

空间协方差张量的分量项与羽流浓度分布在其质心周围的分布情况相关,在应用中,必须从一组离散的指定点浓度中估算矩的大小。在这项研究中,上述内插浓度可用于估算整体质量以及第一和第二阶矩,以便与从流动和运移模型直接输出的污染物羽流分布作比较。插值的方法是普通克里金(OK)或逆距离加权(IDW)插值方法。
如果在各种潜在设计中监测井选择足够多,即取样点选择越多,那么插值后得到的地下水污染羽流与模拟所得到的羽流相比差别会越小或趋于一致,但如此一来,监测成本就会上升。因此,在监测成本和污染羽流精度之间存在着一种权衡关系。本研究中监测问题的目标函数是最小化长期监测成本,同时保持污染物质量和羽流矩估计的准确性。目标函数是所有采样点的总安装/钻井和采样成本的总和,那么监测问题可以表示为:
(5)
errormass≤εmass
(6)
errormoment≤εmoment
(7)
式中,J为井安装/钻井和采样总成本的管理目标;n为潜在监测井总数;C1为每次采样的成本;xi为二进制变量,表示第i井是否采样(如果是,则xi=1;如果否,则xi=0);li为第i井在不同深度处的采样数;C2为第i井每单位深度安装/钻井的固定成本;yi为二进制变量,表示位置i处是否需要钻井(如果是,则yi=1;如果否,则yi=0);di为第i井的深度。
式(6)、式(7)分别为对总体质量估计误差和羽流矩估计误差的约束。总溶解污染物质量估计误差errormass可以表示为:
(8)
式中,masscal为由流动运移模型确定的模型域内污染物总质量;massj为采用第j个取样设计通过插值后得到的污染物总质量。
由于空间矩张量包含不同的分量,羽流矩估计误差errormoment可以表示为:
(9)

1.3 遗传算法
遗传算法(GA)是由Holland[12]在1975年开发的一种使用自然选择机制在决策空间搜索最优解的技术,它能够模拟自然选择的生物进化过程和达尔文生物进化理论的遗传机制[13]。
对于任何一个地下水污染监测网设计问题,都有n个潜在的监测井位置。遗传算法认为每个采样方案是由n个0或1组成的字符串,其中第i位的值为1表示从第i个位置采样,0表示不采样。字符串中非零数字的和表示当前设计中使用的采样位置的数目。
遗传算法由选择、交叉和变异3个遗传算子组成[14-15]。首先在每一代种群中评估所有字符串的适应度大小,其次根据适应度大小选择多个字符串,最后使用交叉和变异遗传算子进行繁殖、突变以形成新种群[16],母种群被后代种群取代。随着世代的发展,获得最优或接近最优的采样设计。
1.3.1 选择过程
遗传算法的第一个阶段是选择单个字符串(采样备选方案),具有高适应度的字符串将有更高的概率被筛选出来进入交配池以繁殖后代。对于等式(5)—(7)中提出的监测网设计问题,目标是在考虑总体质量估计和矩估计精度的同时,最小化采样成本。因此,适应度函数必须考虑到约束条件,可以通过在目标函数中添加任何违反约束的量作为惩罚来定义适应度函数:
F=J+V1+V2
(10)
(11)
(12)
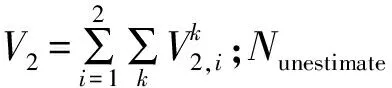
1.3.2 交叉过程
遗传算法的第2个阶段是交叉,交叉操作以一定的概率Pcross从交配池中选择2个字符串(父、母亲)创建2个新的字符串(子代)。因为采样网络设计的任务是决定是否选择一个潜在的采样地点(即1或0),所以均匀交叉最适合本研究。通过均匀交叉,在一个字符串的特定位置上的选定位与在另一个字符串相同位置上的相应位交换。交叉之后,新一代的字符串数量与上一代相同。
1.3.3 变异过程
遗传算法的第3个阶段是变异,对于经历了交叉后的子代字符串,变异会在字符串上逐位进行,是否变异取决于变异的概率Pmute。某一字符串的变异操作就是根据变异概率对某一个字符取反,即将0变为1,1变成0。变异概率一般很小,因为变异针对的是某一字符而非字符串[17]。该操作的主要目的是保持字符串的多样性,也是为了更好地优化全局地下水污染监测网设计[18]。
选择算子旨在保留那些具有较高适应度的采样设计,交叉算子是通过结合较高适应度的采样计划来提高采样效率,而变异过程旨在防止信息不可挽回的丢失[19]。
2 单、双污染源地下水监测网优化设计案例
2.1 场地概况及地下水流和溶质运移模拟结果
本算例涉及到的是二维均质各向同性的承压含水层。假设一个含水层系统平面图及模型的平面中心有限差分网格,研究区域x方向延伸长600 m,y方向延伸长400 m,含水层左侧为恒定水头边界,上水头为89.0 m,下水头为89.5 m,自上而下线性渐升;右侧为恒定补给边界;顶部和底部是隔水边界,其他含水层相关参数如下:孔隙度为0.175;含水层厚度为10.0 m;纵向弥散度为6.0 m;横向弥散度与纵向弥散度之比为0.1;恒定补给量为9.45 m3/d;纵向格距为20.0 m;横向格距为20.0 m;渗透系数为8.9 m/d。
假设在图中污染源处发生了泄漏,污染源初始污染物浓度为1×10-6,污染羽流随水流向左边界移动。本研究考虑的是自污染物泄漏以来前3年作为监测期,基于56个监测位置的插值羽流污染物总质量、一阶矩、二阶矩与使用研究区内所有节点污染浓度值的流动运移模型的输出结果相当接近。单、双污染源场地第一个监测周期结束时由流动和运移模型计算出的污染羽流“真实”分布状态如图2、图3所示。

图2 单污染源含水层结构平面图及模型网格示意Fig.2 Schematic diagram of the structure plan and model grid of the single pollution source aquifer
2.2 目标函数及优化参数设置
此算例的监测网优化设计模型可利用式(5)—(7)表示。假设采样的成本(C1li)和固定安装/钻井的成本(C2di)为每口监测井2 000美元。违反污染物总体质量和污染羽流矩估计误差的惩罚系数为每口监测井总成本的5倍(即α1=α3=10 000),考虑到矩估计的相对误差可能大于质量估计相对误差,因此这里假设εmoment>εmass。
其他参数设置如下:遗传代数100代;种群大小600;交叉概率Pcross=0.65;变异概率Pmute=0.01;每口监测井的安装与采样成本2000美元;潜在监测井数目56口;允许的空间矩误差Emoment=0.10;一、二阶矩权重W=1.00;超出允许监测井数量的惩罚系数α0=1×1010;质量估计误差的惩罚系数α1=1×104;未估计点浓度惩罚系数α2=50;羽流矩估计误差惩罚系数α3=1×104。
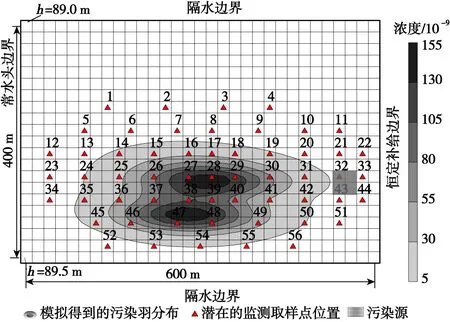
图3 双污染源含水层结构平面图及模型网格示意Fig.3 Schematic diagram of the structure plan and model grid of the dual pollution source aquifer
3 监测网优化结果及对比分析
3.1 优化结果
经过100代后,以最小目标函数进行了最优采样设计。对于单污染源地下水监测网优化设计,在权衡监测精度的前提下,采用OK和IDW插值方法对模型域内未采样点进行浓度插值,结果显示取样井数分别为37口和28口,能分别节省33.93%和50%的监测成本,优化后的取样井位和羽流分布情况如图4所示。
对于双污染源场地,在权衡监测精度的前提下,采用OK和IDW插值方法进行地下水监测网优化设计时,取样井数均为25口,可节省55.36%的监测成本,优化后的取样井位和羽流分布情况如图5所示。
3.2 确定污染源条件下不同插值方法的对比
以上算例的最优采样设计是将遗传代数设为100代的优化结果,为方便比较确定污染源条件下不同插值方法对最优采样设计的影响,现将遗传100、200代的试验结果列出,见表1。
观察表1中算例PM1、PM2可知,当污染源只有一个时,基于IDW插值方法的优化设计取样井数更少,能节省更多的成本,更具有成本效益。由图4可知,发现基于OK插值后的羽流与流动运移模型输出的羽流接近一致,明显优于IDW插值后的羽流分布。因为根据表中显示的质量估计误差和矩估计误差来看,基于OK的方法得到了更准确的污染物质量和羽流一、二阶矩估计,尤其是二阶矩估计。综上,对于单污染源场地,基于2种插值方法的采样设计各具优缺点,但在实际应用中,更多地使用OK插值方法,因为采样设计的成本效益不应以牺牲污染物全局质量和矩估计的精度为代价。在大规模的现场应用中,IDW不适合作为最优采样设计的插值方法。

图4 地下水污染监测网基于OK、IDW的最佳 采样设计(单污染源)Fig.4 The best sampling design of the groundwater pollution monitoring network based on OK and IDW(single pollution source)
观察表1中算例PM3、PM4可知,当污染源有2个时,基于2种插值方法的优化设计取样井数相差不明显或出现与单污染源设计相反的结论。由图5可知,基于2种插值方法的优化设计羽流估计误差相差很小,且无规律,随着遗传代数的增加,基于OK与IDW优化设计的精确度也随之变化,有时基于OK插值方法的优化设计更精确更具成本效益,有时则相反。随着遗传代数的增加,基于IDW插值方法的优化设计结果精确度不断提高。与单污染源算例相比,对双污染源的场地进行地下水污染监测网优化设计能获得更准确的羽流二阶矩估计,且能节省更多的潜在费用。因此,对拥有2个污染源的场地进行地下水污染监测网优化时应用2种插值方法都可行,都可以在保证污染羽流估计准确度的同时,降低所需的监测成本。若对计算速度和精度要求较高时,可选择IDW插值方法。
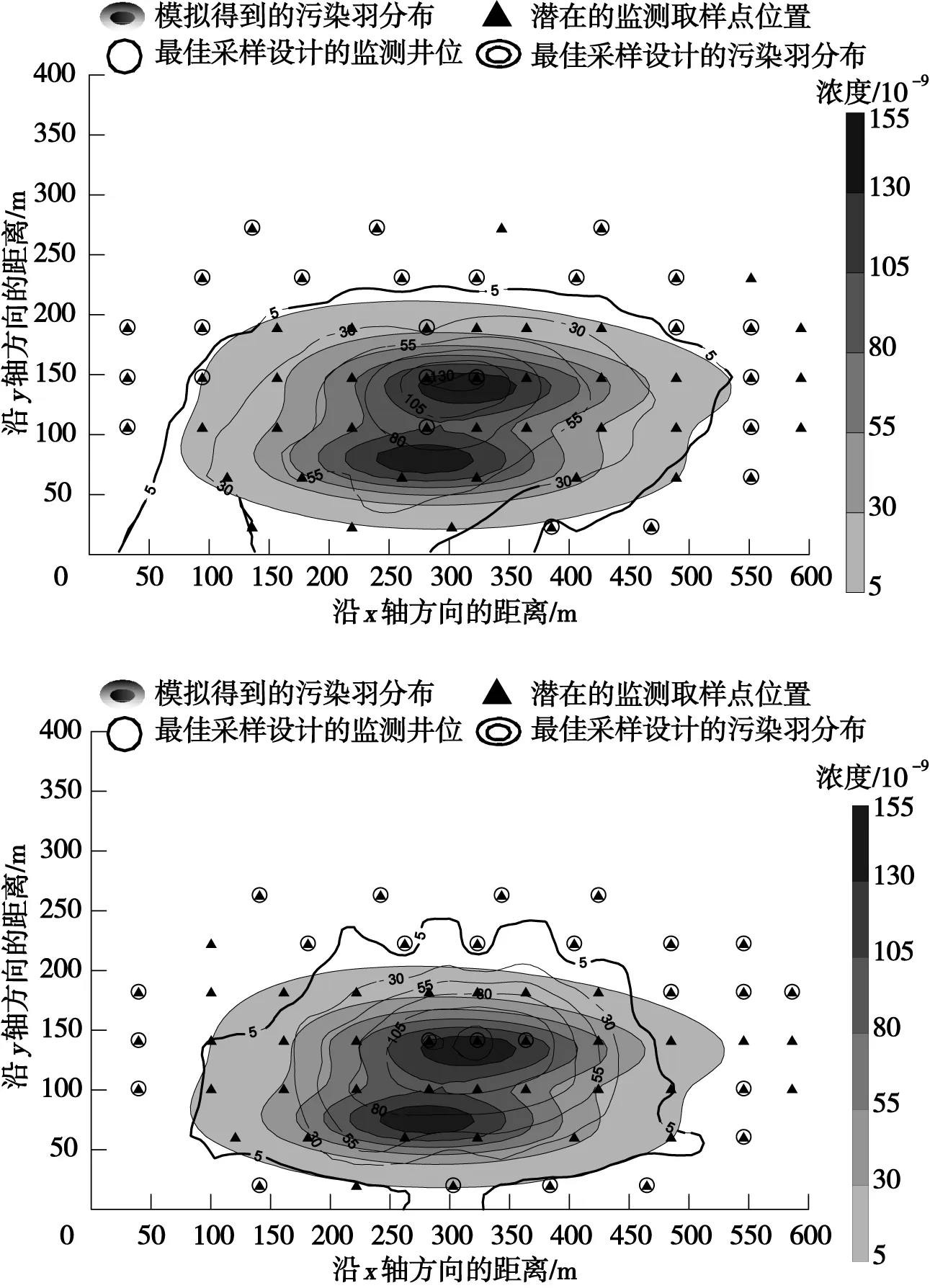
图5 地下水污染监测网基于OK、IDW的最佳 采样设计(双污染源)Fig.5 The best sampling design of the groundwater pollution monitoring network based on OK and IDW (dual pollution sources)
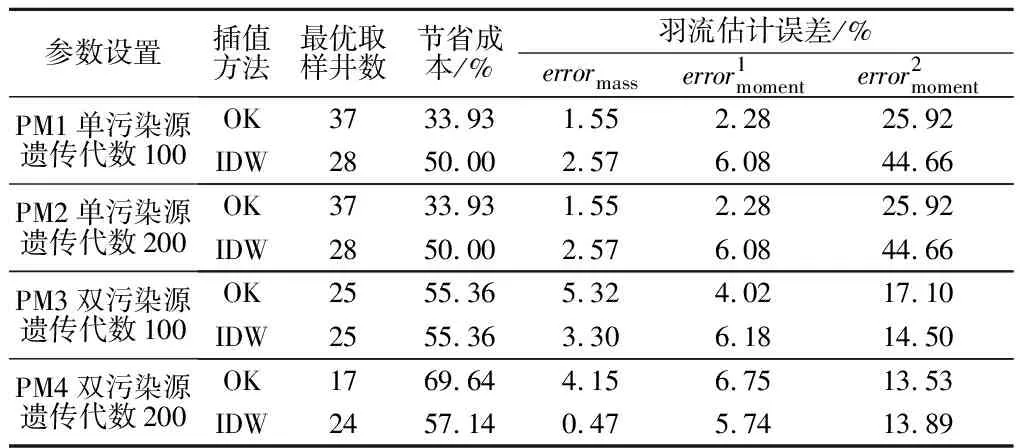
表1 单、双污染源地下水监测网优化结果Tab.1 Optimized results of groundwater monitoring network for single and double pollution sources
3.3 单、双污染源对优化结果收敛的影响
很难知道什么时候最优或接近最优解是使用遗传算法的一个难点,Reed等[20]指出遗传算法在收敛前必须满足2个条件。①潜在采样位置的一个子集必须由上一代中大约90%的个体选择;②所有剩余的采样点不能被上一代中超过10%的个体选择。
研究采用的遗传代数是根据大量试验得出的,采用的是在目标函数(包含惩罚量)不发生显著变化或不变化时的代数。目标函数随遗传代数的演化如图6所示。在单污染源场地,遗传算法中的目标函数会随着遗传代数的增加不断减小,最后趋于稳定值,基于OK插值方法的优化设计目标函数在第64代时收敛,之后便不再发生变化,基于IDW插值方法的优化设计目标函数在第82代时收敛。在双污染源场地,两种插值方法的优化设计目标函数随着遗传代数的增加,起初减小的幅度很大,在大约50代之后,变化幅度很小,但不能收敛到一个值。

图6 目标函数随遗传代数的演化Fig.6 The objective function evolves with genetic algebra
观察图6可知,无论是单污染源还是双污染源情况下,将遗传代数定为100代是比较合理的。由图6可知,对单污染源的场地进行地下水污染监测网优化时尽量考虑OK插值方法;对双污染源场地进行监测网优化时,2种插值方法均可使用,可以采用一种插值方法计算,另一种方法进行验算。
4 结论
(1)将模拟—优化方法应用到本文算例中,在不显著降低污染物总体质量和羽流矩估计精度的前提下,可以实现高达50%~60%的潜在成本节约。且在使用该方法时需要在目标函数中添加约束违反量,用于权衡减少监测成本与提高质量和羽流矩估计精度这2种相互矛盾的目标。
(2)对于本文的场地提出的监测网优化模型,当污染源只有1个时,基于IDW插值方法的优化设计与基于OK插值方法的优化设计相比,取样井数更少,能节省更多潜在的成本。但是基于OK插值方法的优化设计能够得到更准确的总体质量估计和羽流矩估计,因此,在实际应用中,更多采用的是基于OK插值方法的优化设计方案。
(3)当污染源为2个时,基于2种插值方法的优化设计取样井数、污染物质量、一阶矩、二阶矩估计误差相差不明显,且变化无规律。随着遗传的进行,基于OK与IDW插值方法的优化设计的精确度也随之变化,有时基于OK插值方法的优化设计更精确、更节省成本,有时则相反。在实际应用中,两种插值方法都可采用。
(4)目标函数(含惩罚量)随着遗传代数的增加,逐渐趋于定值或变化很小。在单污染源场地,目标函数会随遗传的进行收敛到一个定值,将此定值所对应的最小遗传代数作为终止遗传算法的条件较为合理;在双污染源场地,随着遗传的进行,目标函数变化幅度逐渐变小,但不收敛到某一值。
(5)与单污染源相比,在保证地下水污染羽流估计精度的前提下,对双污染源的场地进行地下水污染监测网优化更具成本效益。
