基于单阶段目标检测算法的羊肉多分体实时分类检测
2022-04-07赵世达王树才郝广钊张一驰杨华建
赵世达 王树才,2 郝广钊 张一驰 杨华建
(1.华中农业大学工学院, 武汉 430070; 2.农业农村部长江中下游农业装备重点实验室, 武汉 430070;3.青岛建华食品机械制造有限公司, 胶州 266300)
0 引言
羊肉分体是依据家畜屠宰行业分割标准将羊胴体分割后得到的产物,一般为6分体、8分体两大类,与大众饮食习惯息息相关,同时与家畜产品增值存在直接关系。目前,我国羊肉产品生产加工企业大多采用半自动化生产工艺,特别是羊肉分体分拣环节,全部依赖人工完成,工作量大,环境恶劣,且存在一定的食品安全隐患[1-2]。因而对羊肉分体进行自动化分拣很有必要,但完成以上目标的先决条件在于羊肉分体种类的准确、快速获取,因此,实现羊肉多分体的实时分类检测具有重要意义。
近年来,在羊体目标检测研究中,广泛采用的方法大多基于图像处理、光谱技术结合机器学习展开。即根据羊体或各羊肉分体在图像中所呈现的不同特征表达进行特征提取,例如颜色、纹理、轮廓、区域中心坐标等,再将各特征以机器学习的方式构建分类器[3-6]。这些方法虽然可以实现特定羊体参数准确识别,但存在人工提取目标特征困难,工作繁琐,选用机器学习设计的模型适应性差、实时性不足的缺点,特别是羊肉分体种类多样、自然特征表达复杂、部分特征具有相似情形,同时,输送带场景中包含多个、多类且可能遮挡的羊肉分体,以上特点对上述文献方法的展开带来困难。
基于深度卷积神经网络的目标检测方法具备对简单、抽象特征的强大自主学习能力,其准确率、泛化能力均优于基于传统HOG[7]、SIFT[8]等人为特征结合机器学习的检测方法,能够较好地解决上述问题。现阶段,众多学者将基于深度学习的目标检测应用至各家畜目标识别任务中[9-14]。基于深度学习的目标检测算法在家畜养殖领域中的良好表现,使得探讨将该方法用于羊肉多分体实时分类检测成为可能。
目前,基于深度卷积神经网络的目标检测主要包括两类,一类是先生成候选区域,再对候选区域进行分类和回归的二阶段检测器,检测精度高,但速度较慢[15]。代表有Faster R-CNN[16]、Mask R-CNN[17]、TridentNet[18];另一类是不需要产生候选区域,基于回归思想直接进行目标分类和回归的单阶段检测器,较二阶段检测器具备较优的实时性,但精度较差[19-20],例如YOLO v1-v3[21]、SSD[22]、RetinaNet[23]等。本文首先建立羊肉分体图像数据集,然后基于检测速度较快的单阶段目标检测算法YOLO v3针对羊肉多分体图像数据集展开研究,获取输送带场景下图像中的多个、多类羊肉分体的类别与位置,然后更换主干网络为轻量级神经网络MobileNet V3[24]优化羊肉多分体识别模型的检测速度。在此基础上,建立包含亮、暗两种亮度水平的附加光照数据集以及代表羊肉分体遮挡情形的附加遮挡数据集,用以验证优化后模型的泛化能力以及抗遮挡能力,并且通过选用形体差异较为显著的颈部、腹肋肉分体测试优化后模型的鲁棒性。最后引入Mask R-CNN、Faster R-CNN、Cascade R-CNN、SSD 4种常用的目标检测算法进行对比试验,并验证MobileNet V1[25]、ResNet34、ResNet50[26]共3种特征提取网络下模型的识别性能。
1 材料与方法
1.1 试验材料与图像采集
试验以成年波尔山羊经分割后得到的羊肉6分体作为研究对象,图像采集于内蒙古自治区美洋洋食品股份有限公司的羊胴体分割生产车间。在输送带场景下,固定华谷动力科技公司生产的WP-UC600型CCD相机于羊肉分体样本正上方0.6 m处,搭配Z4S-LE-SV-1214H型欧姆龙镜头获取图像,期间无特定背景及光源,不限定拍摄时间。由于同分割批次的羊胴体存在质量、体态、年龄相似情况,为增大羊肉各分体之间的差异性以提高模型的泛化能力,随机采集6批次羊胴体,共计2 100副。最终经人工筛选后得到3 600幅包含多个、多类的羊肉分体图像,分辨率为2 448像素×3 264像素。图像采集装置示意图与样本示例如图1、2所示。
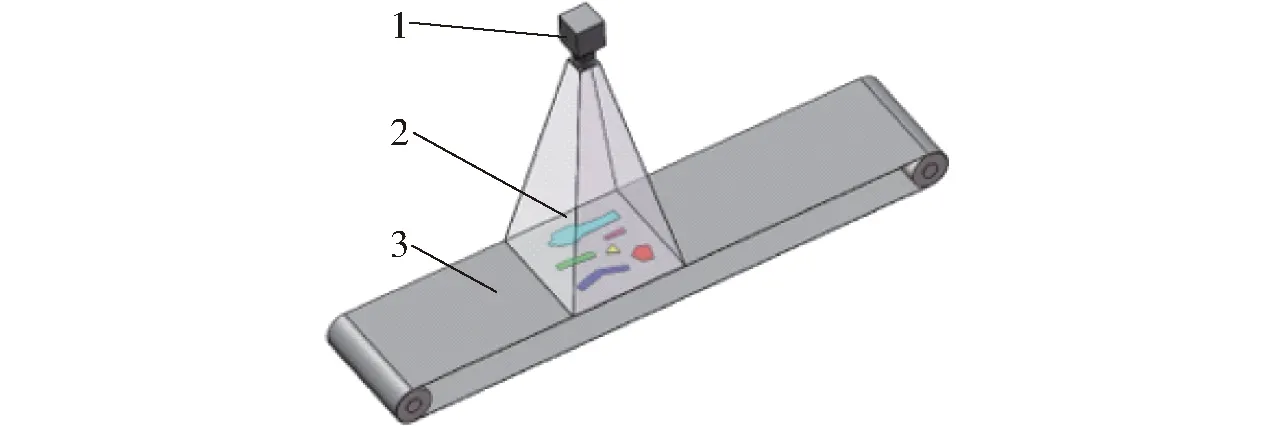
图1 羊肉多分体图像采集装置示意图Fig.1 Illustration of image acquisition device1.相机 2.羊肉多分体 3.输送带
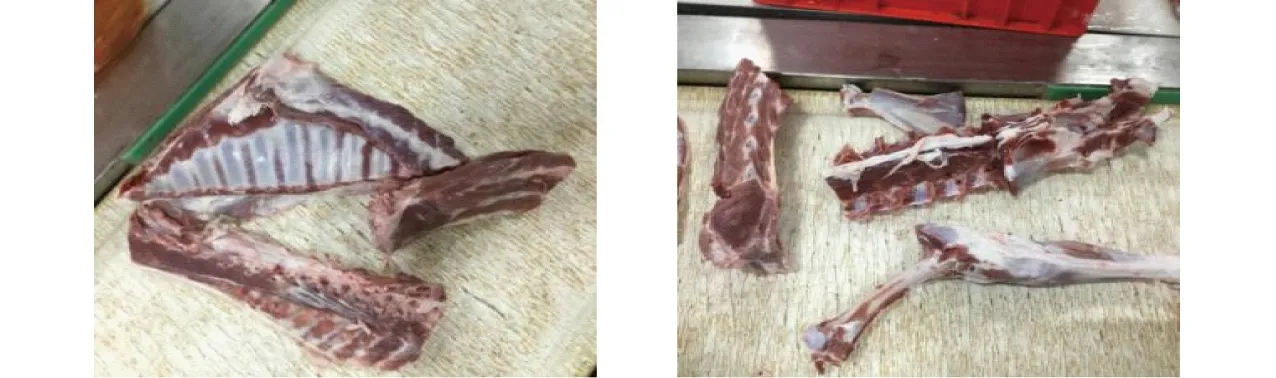
图2 羊肉多分体图像样本示例Fig.2 Example of multipartite images of mutton
本文羊肉6分体分别为腰椎骨、胸椎骨、颈部、腹肋肉、肩胛骨和腿骨,其中,腰椎骨与胸椎骨是制作羊蝎子和法排的原材料,腹肋肉使用场景更为广泛,其它3类也有其独特价值,如图3所示。可以看出各类羊肉分体表现出的颜色、纹理、轮廓等特征差异明显,并且尺寸区别较大。另外,通常情况下由于羊体尺寸不同导致相同种类的羊肉分体尺寸也存在较大的差异,多尺度特征显著。以上特点要求羊肉多分体识别方法需要具备多尺度特征检测能力。

图3 羊肉各分体图像样本示例Fig.3 Sample image samples of each split of mutton
1.2 样本预处理及生成数据集
基于深度卷积神经网络的目标检测精度与样本数据集规模显著相关,在保证图像自然特征表达情况下,扩充训练图像数量不仅能够提高模型准确率,还可以满足深层网络对数据的要求,减少过拟合现象[27],因此,对本试验小规模羊肉分体图像进行图像增广以扩充数据量很有必要。本文采用翻转、旋转、平移3种方式进行图像数据扩充,再以比例不变性原则将图像缩放至412像素×412像素,建立羊肉多分体图像数据集,其中训练集7 200幅,测试集1 400幅,验证集400幅。另外,参考VOC数据集格式使用LabelImg图像标注工具对6类羊肉分体进行标记,设定腰椎骨、胸椎骨、颈部、腹肋肉、肩胛骨和腿骨的标签分别为Sheep1、Sheep2、Sheep3、Sheep4、Sheep5和Sheep6。最终,据统计,羊肉多分体图像数据集中上述各类羊肉分体的数量比例分布趋近于5∶4∶3∶6∶2∶7,各分体的数量如表1所示。
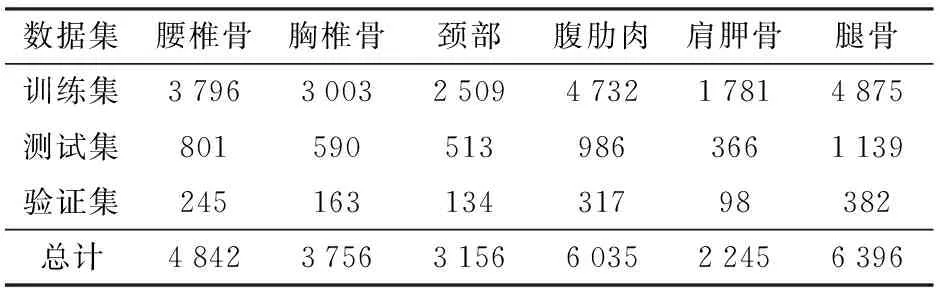
表1 羊肉分体数据集种类及其数量Tab.1 Types and quantities of mutton multi-part datasets
1.3 YOLO v3算法原理
1.3.1YOLO v3网络结构
YOLO v3属于单阶段目标检测算法的一种,该网络结构由DarkNet53特征提取网络与YOLO v3多尺度分支两部分组成。其中DarkNet53特征提取网络通过设置阶跃连接加深网络深度,以提高特征提取能力,同时加快模型收敛。YOLO v3多尺度分支部分引入特征金字塔(Feature pyramid networks,FPN)结构将网络划分为3个分支,分别对应检测小目标、中目标和大目标,利用获取目标多尺寸特征图感受野的形式,增强多尺度目标检测能力,提升模型的鲁棒性。YOLO v3网络结构如图4所示。

图4 YOLO v3网络结构图Fig.4 Architecture for YOLO v3 network
首先,将尺寸为412像素×412像素的羊肉多分体图像输入DarkNet53特征提取网络,经特征通道数为32与64、卷积核尺寸为3×3的卷积核以步长1和步长2遍历图像。然后卷积层(Conv)输出特征由批归一化(BN)和Leaky_ReLU激活函数处理后得到208×208×64的特征图。最后输入卷积核尺寸为1×1的残差模块,通过下采样输出尺寸为104×104×128的特征图,之后交替卷积,直至输出尺寸为13×13×1 024的特征向量至YOLO v3多尺度分支的大目标和中目标分支。其中,中目标分支将特征向量上采样后与DarkNet53网络中输出尺寸为26×26×512的特征图拼接,经多次卷积后一部分输入至小目标分支,另一部分输出尺寸为26×26×255的特征结果。输入至小目标分支的特征向量上采样后与52×52×256的残差模块输出特征拼接,最终得到52×52×255的特征图,由于该特征图感受野较小,使得YOLO v3对小尺寸目标能够保持较高的检测精度。
1.3.2边界框预测及损失函数
YOLO v3依据多尺度分支的3种特征图尺寸(S=13,26,52),将输入图像划分为S×S个网格,并对落入各网格中的目标进行滑动窗口计算,输出被检目标的边界框及其置信度。该置信度由各网格包含目标的概率与边界框准确度共同决定[28]。
YOLO v3采用9种锚点框(Anchor box),提高对多尺度目标的检测精度,各锚点框尺寸分别为10×13、16×30、33×23、30×61、62×45、59×119、116×90、156×198、373×326。其中,前3个锚点框适用于检测小尺寸的肩胛骨,中间3个锚点框对检测尺寸相对中等的腰椎骨、颈部和腿骨较为敏感,剩余锚点框更适用于检测尺寸较大的胸椎骨和腹肋肉。然后基于锚点框得到各检测目标预测边界框,再将置信度小于阈值的边界框剔除,采用非极大值抑制算法(Non-maximum suppression,NMS)[29],获取最终的被检目标边界框(Bounding boxes),本文设定阈值为0.5。该边界框尺寸与位置由4种参数bx、by、bw、bh决定,分别对应边界框相对于特征图的中心点坐标以及宽、高。图5为YOLO v3边界框原理图,其中Cx、Cy代表预测边界框中心所在网格左上角网格的坐标,Pw、Ph为该单元格对应先验框的宽和高,tx、ty为预测边界框中心距所处网格左上角的相对宽、高偏移量。bx、by、bw、bh计算式为

图5 YOLO v3边界框原理图Fig.5 Schematic of YOLO v3 boundary frame
(1)
(2)
式中σ——sigmoid函数
tw——预测边界框的宽方向偏移量
th——预测边界框的高方向偏移量
损失函数用来判断模型的预测值与真实值之间的差异程度,与网络的性能直接相关。YOLO v3网络训练过程中的损失值主要由边界框定位损失、边界框尺寸损失、置信度损失和类别损失4部分组成,该值越小则反映模型的训练效果越好,鲁棒性越强。其计算式为
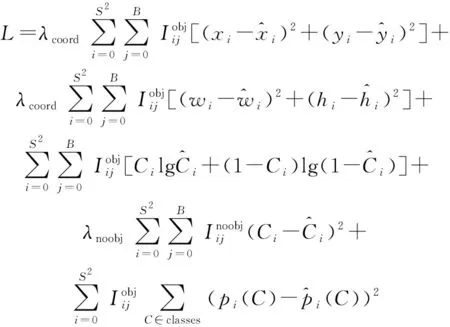
(3)
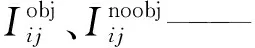
B——每个网格中预测边界框的个数
xi、yi——第i个网格边界框中心横、纵坐标
wi、hi——第i个网格边界框宽度、高度
Ci——预测目标类别
pi——预测类别概率
λnoobj——惩罚权重系数
1.4 判断标准
本文采用目标检测任务中常用的平均检测精度(mAP)作为量化分析羊肉多分体识别模型对羊肉分体分类检测效果的评判指标,该指标反映的是模型对腰椎骨、胸椎骨、颈部、腹肋肉、肩胛骨和腿骨6类羊肉分体类别检测精度(AP)的平均值,数值越大则表征模型的准确度越高。
为满足生产线实际需求,羊肉多分体识别模型不仅需要具备较高的检测精度,还要求良好的实时性。因此,除获取检测精度之外,测试模型的检测速度同样重要。本文选用模型单幅图像平均处理时间作为第二指标,判断模型的实时性。
2 试验与结果分析
基于单阶段目标检测算法的羊肉多分体实时分类检测主要包含4个步骤:采集羊肉多分体图像,经过预处理后建立羊肉多分体图像数据集;引入迁移学习针对羊肉多分体图像数据集训练YOLO v3,返回检测精度最优模型,并更换最优模型特征提取网络为轻量级神经网络MobileNet V3,优化模型的检测速度;分别通过附加亮度、遮挡数据集验证优化后模型的泛化能力和抗遮挡能力,以及测试优化后模型的鲁棒性;与常用目标检测算法进行对比试验,并进一步更换模型的特征提取网络验证优化后模型的综合检测能力。流程如图6所示。
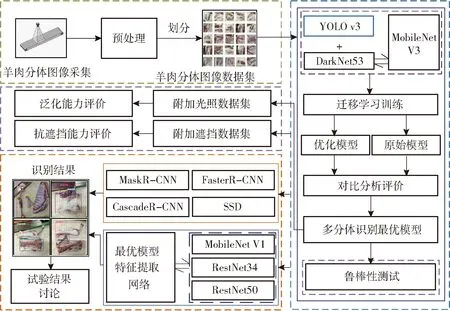
图6 羊肉多分体实时分类检测试验流程图Fig.6 Technical flowchart of experiment for real-time classification and detection test of mutton multipartite
2.1 试验环境
本文试验基于深度学习框架Tensorflow在Dell T5810塔式图形处理工作站上完成,计算机系统为Windows 10专业版操作系统,搭载Intel core64至强3.70 GHz W-2145处理器,内存和显卡分别为64 GB、NVIDIA P4000-8G。
2.2 基于迁移学习的YOLO v3网络训练
面对小规模数据样本的深度学习模型训练时,引入迁移学习可以降低过拟合及加速模型收敛,提升训练效果。因此,本文试验建立的所有模型在训练过程中均加载了基于ImageNet数据集的预训练权值。采用随机梯度下降(Stochastic gradient descent,SGD)优化器进行梯度下降,设置初始学习率及动量因子分别为0.001和0.9,batchsize和gamma系数为8和0.1。另外,设定训练过程中每迭代2 000次保存一次结果,共计40 000次,将保存的20个训练结果比较后,输出最优模型用于后期羊肉多分体图像数据集的输入。针对羊肉多分体图像数据集,引入迁移学习和未引入迁移学习的YOLO v3网络损失值及平均检测精度随迭代次数与循环次数的变化趋势如图7、8所示。

图7 引入迁移学习与未引入迁移学习损失值随迭代次数变化曲线Fig.7 Loss value changes with number of iterations during transfer learning and non-transfer learning
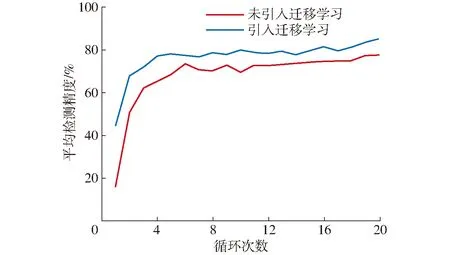
图8 引入迁移与未引入迁移学习平均检测精度随循环次数变化曲线Fig.8 The mAP changes with number of epoch during transfer learning and non-transfer learning
由图7、8可知,针对羊肉多分体图像数据集,加载预训练权值的YOLO v3网络损失值在训练初期迅速降低,当迭代次数达到8 000次时缓慢下降随即平滑,直至收敛于1.07。未加载预训练权值网络的训练损失值随迭代次数变化趋势与加载训练相似,均在训练开始时迅速减小,之后缓慢收敛,但其损失值明显大于采用迁移学习的训练方式。另外,针对羊肉多分体图像测试集,迁移学习训练得到的平均检测精度达到88.72%,较未引入迁移学习提升6.78个百分点,说明基于迁移学习方法训练网络可以降低羊肉多分体识别模型的损失值,提升识别精度。因此,为保证模型的识别准确率,试验后期所采用模型的训练均基于迁移学习方式完成。
2.3 YOLO v3对羊肉多分体数据集的识别结果
基于训练得到的最优模型针对羊肉多分体验证集展开测试,获取图像中6类羊肉分体的类别和位置,得到识别平均检测精度及单幅图像处理时间,以判断YOLO v3模型对羊肉多分体的识别精度和实时性。其中,获取单幅图像处理时间的方式为分别记录验证集各图像识别时间再求其均值。部分识别结果如图9所示。

图9 针对羊肉多分体验证集YOLO v3模型识别结果Fig.9 Recognition results of YOLO v3 model for mutton multipartite validation data sets
实际生产过程中,羊体分割以间歇性、周期性的作业方式完成,导致分割得到的羊肉分体在输送带上呈现出随机片区的形式,表现为单幅图像包含多个、多类且重复的羊肉分体现象,如图9所示。图中,YOLO v3模型检测结果中没有出现错检与漏检的现象,可以以较高的置信度检测出各羊肉分体的类别,同时,各羊肉分体的边界框标记完整、准确,特别是图9a、9b中小尺寸的肩胛骨以及图9c、9d中尺寸明显不同的颈部均可以准确识别,以上结果说明YOLO v3羊肉多分体模型具备较高的检测精度以及良好的多尺度检测能力。最终,YOLO v3对羊肉多分体验证集的平均检测精度和单幅图像平均处理时间分别达到87.79%和96.1 ms,精度满足生产线的需求,但处理速度略慢,实时性有待提高。
2.4 YOLO v3网络检测速度优化
YOLO v3的特征提取部分为包含53个卷积层的卷积神经网络DarkNet53,该网络较深的多层结构有利于提取羊肉分体的多种抽象特征用于目标定位从而提升模型的识别精度,但随之增加的浮点计算量也加大了模型推断耗时,为实时性要求较高的识别任务带来困难。如果采用轻量级神经网络替代DarkNet53,则可以优化YOLO v3的检测速度。MobileNet V3网络属于轻量级神经网络中的一种,该网络在MobileNet V1深度可分离卷积模块(Depthwise separable convolution, DSC)和MobileNet V2逆残差结构(Inverse residual structure,IRS)的基础上添加了引入注意力机制的逆残差模块(Squeeze-and-excitation,SE),极大地减少网络参数量,有益于缩短模型的计算时间,同时采用H-Swish激活函数增加网络提取低维特征的非线性,例如羊肉各分体的颜色、纹理等特征,其结构如图10所示。因此,采用轻量级神经网络MobileNet V3替换DarkNet53作为YOLO v3的特征提取网络,试图在保证模型识别精度的前提下提升实时性。

图10 引入注意力机制的逆残差模块结构Fig.10 Structure of inverse residual module with SE
本文基于MobileNet V3替换特征提取网络DarkNet53得到优化后的YOLO v3-MobileNet V3模型,引入迁移学习进行训练,另外为保证模型收敛,将迭代次数扩充至60 000次,其余超参数设置与YOLO v3原始模型保持一致,之后针对羊肉多分体图像验证集展开识别精度和速度测试。训练过程中YOLO v3-MobileNet V3模型的平均检测精度随迭代次数变化趋势如图11所示,随着循环次数的增加,平均检测精度相应迅速提升然后平滑,直到稳定于循环25次左右。最终,针对验证集,训练得到最优YOLO v3-MobileNet V3模型的平均检测精度达到88.05%,与原始模型差距不显著,仍可以准确识别图像中羊肉多分体的类别与位置,但单幅图像平均处理时间为64.7 ms,较原始模型缩短31.4 ms,检测速度较原模型提升48.53%,说明更换特征提取网络为MobileNet V3,能够有效缩短对羊肉多分体的检测时耗,提升实时性,但对检测精度无明显影响。
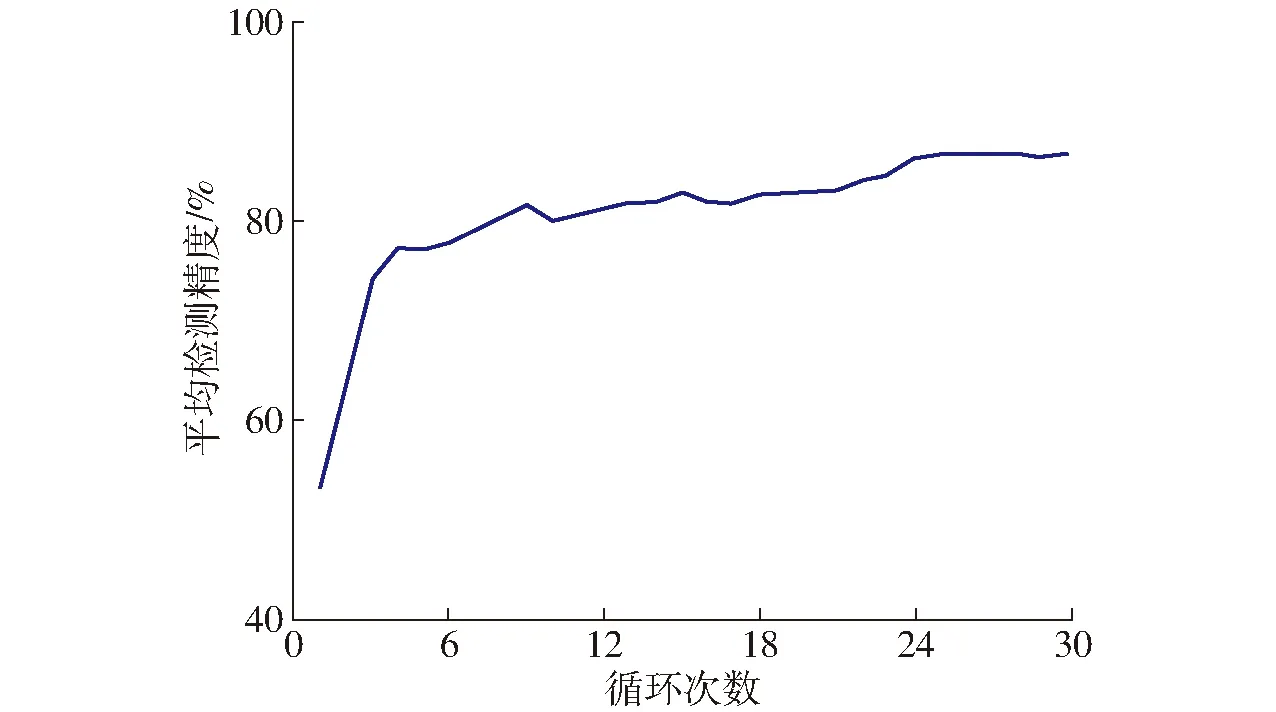
图11 优化模型平均检测精度随循环次数变化曲线Fig.11 Change trend of mAP value of optimization model
2.5 不同光照下羊肉多分体识别
为测试优化后羊肉多分体识别模型的泛化能力,随机选取600幅归一化后的羊肉分体图像,建立附加光照数据集,并将其RGB色彩空间转换为HSV色彩空间,基于Matlab图像处理工具箱设置1.3倍和0.7倍的图像亮度,以模拟亮、暗两种光照水平场景,进行羊肉多分体识别模型的泛化能力试验,其中调亮、调暗图像各300幅。针对附加光照数据集,优化后模型的部分识别结果如图12所示。

图12 针对附加光照数据集优化模型识别结果Fig.12 Recognition results of optimize model for additional lighting data sets
根据图12样本1、样本2识别结果可以看出,羊肉多分体在亮、暗两种光照强度下,优化后模型仍然可以准确识别图像中6类羊肉分体的类别,同时检测得到的各分体边界框标记正确、完整,羊肉分体真实轮廓与标记边界框无明显误差现象。最终,针对附加验证集,优化后羊肉多分体识别模型的平均检测精度达到85.16%,说明光照强度变化对该模型的识别效果影响并不明显,能够适应于不同亮度场景的羊肉多分体识别,具备较强的泛化能力。
2.6 遮挡状态下羊肉多分体识别
分割完成后的羊肉分体随机散落在呈匀速运动的输送带上,这种不确定的散落方式使得输送带上的片区羊肉分体存在少量叠放状况,造成部分羊肉分体被遮挡。如图13a所示,可以看出颈部分体叠落在胸椎骨与腹肋肉之间,造成腹肋肉部分特征丢失,图13c中胸椎骨分体置于腰椎骨上方,遮挡了部分腰椎骨,特别是颈部分体和腹肋肉分体的颜色、纹理特征十分相似,这种区域相交且特征相似的情况不利于被遮挡状态下的羊肉多分体识别。但是,图中羊肉分体未被遮挡部分仍保留了清晰、独立的自然特征,有利于排除羊肉分体遮挡造成的识别干扰。为测试羊肉多分体识别模型对遮挡状态下羊肉分体的识别效果,人工选取带遮挡特征的羊肉多分体图像200幅,作为附加遮挡数据集,对模型的综合识别检测能力展开测试,部分识别结果如图13所示。
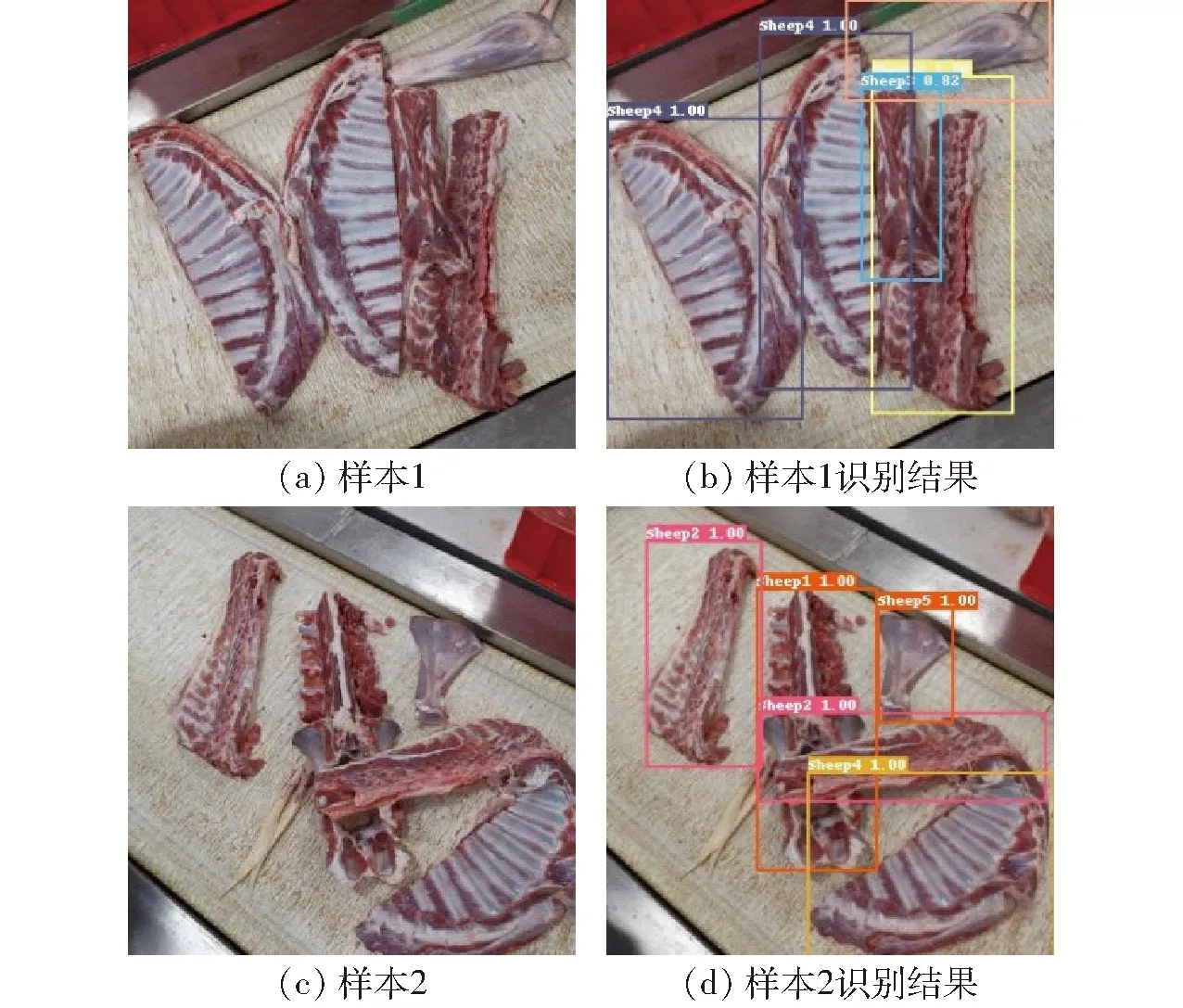
图13 针对附加遮挡数据集优化模型识别结果Fig.13 Recognition results of optimize model for additional occlusion data sets
根据图13a样本1、图13c样本2遮挡状态下的羊肉多分体识别结果,优化后的羊肉多分体识别模型可以准确区分叠落、遮挡状态下的颈部-胸椎骨、胸椎骨-腰椎骨。这可能是胸椎骨被颈部遮挡的像素区域面积相对未被遮挡区域较小,且存在粘连,对胸椎骨真实边界框定位影响较弱,从而识别模型仍能排除干扰,确定胸椎骨在图像中的位置,如图13a、13b所示。而图13c中腰椎骨被胸椎骨截断为中、小尺寸2部分,不利于单一目标的识别,但YOLO v3结构中的中目标识别分支、小目标识别分支,使得模型对截断后的多种尺寸部分敏感,仍然可以提取特征用于分类识别排除遮挡干扰。另外,YOLO v3的9种尺寸不同的锚点框能够充分囊括同一类目标被遮挡后的剩余部分,便于在求取真实边界框过程中将像素交并比及边界框置信度进行比较和统一,降低遮挡部分的误差。最终,针对附加遮挡数据集,优化后的羊肉多分体识别模型的平均检测精度达到83.47%,能够准确识别被遮挡羊肉多分体的类别及其位置,具备较强的抗遮挡能力与良好的识别性能。
2.7 优化后模型鲁棒性测试
羊肉多分体中同类分体之间存在个体尺寸差异较大的情况,为测试优化后模型对尺寸差异羊肉分体的识别能力,选择形体区别相对明显的颈部和腹肋肉进行鲁棒性试验。采集2组颈部与腹肋肉样本各200个,共计400个样本,建立附加多尺寸数据集。基于训练过程保存的最优优化后模型针对附加多尺寸数据集展开测试,部分识别结果如图14所示。

图14 针对附加多尺寸数据集优化模型识别结果Fig.14 Recognition results of optimize model for additional multi-dimensional data sets
由图14可以看出,相同类别的颈部和腹肋肉在外形轮廓、体尺寸上存在明显不同,特别是图14a颈部样本1中,颈部右侧端部的锁骨特征较颈部样本2不显著,图14c腹肋肉样本1与腹肋肉样本2相比,尺寸偏大且相对饱满,以上特点不利于模型的精准识别。而根据图14的识别结果,优化后模型可以有效排除上述因多尺寸差异带来的识别干扰,并且能够以较高的置信度得到分体类别,同时预测边界框位置误差相对较小。最终,针对附加多尺寸数据集,优化后模型的平均检测精度为80.79%,说明优化后模型针对多尺度特征明显的羊肉分体具备良好的鲁棒性。
2.8 与其他识别算法对比试验
目前,随着卷积神经网络的发展,基于该技术的目标识别方法愈发多样,但面对不同对象与任务,不同方法的识别性能往往不同。为探究优化后羊肉多分体识别模型较其他常用识别算法的优劣性,引入Mask R-CNN、Faster R-CNN、Cascade R-CNN、SSD进行对比试验,另外,更换YOLO v3网络的特征提取网络为MobileNet V1、ResNet34和ResNet50与优化后羊肉多分体识别模型作进一步对比分析。以上算法的训练超参数与YOLO v3原始模型保持一致,然后利用分别得到的最优模型针对羊肉多分体验证集、附加亮度数据集、附加遮挡数据集展开测试,得到相应的mAP和单幅图像处理时间,用以评判各方法的识别效果。部分识别对比结果如图15所示。
由图15a可以看出,在原始、调亮、调暗和遮挡4种情况下,Mask R-CNN、Faster R-CNN、Cascade R-CNN均能够实现各羊肉分体的准确识别,无漏检现象,同时预测边界框定位正确,较目标真实位置无明显误差。特别是在调暗图像中,相邻腹肋肉分体紧密贴合处于黏连状态形成整体,以上方法同样能够以较高的置信度预测得到被检分体相应的类别和边界框位置。另外,在遮挡情况下,叠落状态的肩胛骨对胸椎骨分体部分形成遮挡,上述方法依然可以准确识别被遮挡的胸椎骨分体。而SSD面对羊肉多分体原始、调暗和遮挡状态时,产生漏检现象,主要表现为未能准确识别出相邻的肩胛骨和腿骨,另外,在调亮状态中,SSD方法预测得到的边界框与真实位置误差明显,腿骨端部部分没有完整标记,同时调暗情况下尺寸相对较小的肩胛骨预测类别概率只有75%。以上现象说明,针对羊肉多分体数据集,Mask R-CNN、Faster R-CNN、Cascade R-CNN具备较高的识别精度以及良好的泛化性和抗遮挡能力,在识别精度上能够满足实际的生产需求,而SSD识别能力较弱。其原因可能是基于候选区域思想设计Mask R-CNN、Faster R-CNN、Cascade R-CNN在图像目标检测过程中,先进行候选区域提取,区分可能存在目标的区域与背景,再对候选区域进行卷积、池化等运算进行边框回归与分类,有利于排除非目标区域的干扰,在目标密度较大时仍能保持较高的准确率。而SSD直接对输入图像进行处理,得到目标位置坐标值以及类别概率,再对位置进行修正,易受特征相似情况的影响,同时SSD的特征金字塔层特征全部来自于特征提取网络的最后一层,造成浅层包含小尺寸物体的特征信息丢失,因而对小尺寸的肩胛骨检测准确率较低。
图15b为更换特征提取网络为MobileNet V1、ResNet34和ResNet50后的YOLO v3识别模型与优化后模型对羊肉多分体图像在原始、调亮、调暗和遮挡4种状态下的识别结果。可以看出,4种模型均未出现漏检和错检现象,但在识别精度上存在差异,例如,YOLO v3-MobileNet V1和YOLO v3-ResNet34在调亮和调暗状态下对颈部分体、腿骨分体与肩胛骨的边界框与真实位置误差明显,而YOLO v3-ResNet50和优化后模型上述现象并不显著,说明YOLO v3-ResNet50与优化后模型在识别精度和泛化性、抗遮挡能力上均优于YOLO v3-MobileNet V1和YOLO v3-ResNet34。其原因可能是MobileNet V1采用的ReLU激活函数会破坏网络提取低维空间特征的非线性,导致线性瓶颈,而MobileNet V3则通过H-Swish激活函数和注意力机制逆残差模块改善了以上缺点,从而使得采用MobileNet V3的YOLO v3模型较MobileNet V1对羊肉分体特征定位更准确。另外ResNet50较ResNet34更深的神经网络结构,有利于深层抽象特征的提取,从而提高模型的识别精度。

图15 优化模型与其他模型和不同特征提取网络下的识别对比结果Fig.15 Recognition results of optimized model compared with other models and different feature extraction networks
实际生产线对羊肉多分体识别方法除要求具备较高的识别精度之外,还需要较短的处理时耗,因此,判断各方法针对羊肉多分体的识别实时性同样重要。获取了Mask R-CNN、Faster R-CNN、Cascade R-CNN、SSD、YOLO v3-MobileNet V1等方法针对羊肉多分体图像验证集的单幅图像处理时间以及平均检测精度,如表2所示。
由表2可知,针对羊肉多分体图像验证集,Mask R-CNN单幅图像平均处理时间最久,为694.4 ms,其次为Faster R-CNN(575.8 ms),Cascade R-CNN在二阶段目标检测算法中耗时最少,为237.5 ms,但仍比单目标检测算法中耗时最久的SSD多146.7 ms,其原因可能是二阶段目标检测算法先确定目标候选框再进行回归和预测的推理过程相对直接对图像进行回归计算的单目标检测算法更为复杂,造成耗时较久的情况。单目标检测算法中,优化后模型对单幅图像平均处理时间最短,为64.7 ms,然后是YOLO v3-MobileNet V1(67.2 ms),另外,YOLO v3在特征提取网络为ResNet34和ResNet50情况下单幅图像平均处理时间相差不大,可能是ResNet50网络深度虽然比ResNet34较深,但采用了1×1和3×3两种尺寸的卷积核,使得其网络参数量与只采用3×3尺寸卷积核的ResNet34相差不大,从而两种模型在处理时耗上较为接近。以上说明在实时性方面,优化后模型性能最优,能够满足实际生产需求,而两阶段目标检测算法耗时较久,与羊肉多分体的实时分类检测存在差距。在检测精度方面,优化后模型的平均检测精度最高,为88.05%,较SSD、YOLO v3-MobileNet V1、YOLO v3-ResNet34、YOLO v3-ResNet50分别高20.77、3.70、7.82、0.77个百分点。对比试验表明,优化后羊肉多分体识别模型可以兼顾较高的检测精度和良好的实时性,综合检测能力最优。

表2 各模型分类检测结果Tab.2 Classification and detection results of each model
3 结论
(1)基于单阶段目标检测算法的羊肉多分体识别模型以YOLO v3为主要网络,能够实现输送带场景图像中多个、多类羊肉分体类别的准确检测,同时边界框预测正确、完整,具备一定的多尺度检测能力,对羊肉多分体图像验证集的平均检测精度达到87.79%,在精度上能够满足实际生产线的需求。
(2)通过更换羊肉多分体识别模型的主干网络为MobileNet V3,可以有效提升实时性,但对检测精度无显著影响。针对羊肉多分体图像验证集,优化后模型单幅图像处理耗时为64.7 ms,较原始模型提升48.53%,说明本文方法在羊肉多分体实时分类检测任务中可以兼顾较高的识别精度和良好的实时性。
(3)设计的基于单阶段目标检测算法的羊肉多分体识别模型针对光照数据集、遮挡数据集、多尺度数据集平均检测精度分别达到85.16%、83.47%和80.79%,对光照变化、遮挡状态实际生产过程中常见的干扰因素及叠落情形具有较强的泛化能力和抗干扰能力,对多尺度特征显著的羊肉分体具备良好的鲁棒性。
(4)与Mask R-CNN、Faster R-CNN、Cascade R-CNN、SSD相比,对羊肉多分体图像验证集,优化后羊肉多分体识别模型较前3种模型识别精度相差不大,但单幅图像平均处理时间缩短,与引入MobileNet V1、ResNet34和ResNet50 3种不同特征提取网络的识别模型比较,优化后模型的平均检测精度为88.05%,较SSD、YOLO v3-MobileNet V1、YOLO v3-ResNet34、YOLO v3-ResNet50分别高20.77、3.70、7.82、0.77个百分点,综合检测能力最优。
