基于深度森林的CT图像结直肠息肉检测研究
2022-04-05陈祎琼范国华毕家泽
陈祎琼, 刘 澳, 范国华, 毕家泽, 陈 滔
(1.安徽农业大学 信息与计算机学院, 安徽 合肥 230036; 2.安徽省北斗精准农业信息工程实验室, 安徽 合肥 230036;3.安徽农业大学 工学院, 安徽 合肥 230036)
最近几年中,结直肠癌是最常见的恶性肿瘤之一。根据美国癌症协会的报告[1],结直肠癌在美国的致死率与患病率在所有癌症中排名第二。多数结直肠癌起于黏膜息肉,其产生与多种因素相关[2],起始于异常的腺窝,后逐渐演变成息肉,最终发展为结肠直肠癌,整个过程可持续多年。结直肠息肉的早期检测是预防结直肠癌、降低发病率、死亡率的有效途径,如何正确地判断结直肠息肉的存在成为了一个值得思考的问题。
针对CT图像中结直肠息肉是否存在分类的问题,国内外学者展开了深入地研究,并将演变成的息肉特征与智能算法结合,陈奕志等[3]研究出一种基于深度学习的结直肠息肉自动检测,取得了可观的判断效果。左艳等[4]提出医学影像处理智能化与人工智能手段结合。Rajpurkar等[5]使用改进的Dense Net[6]对X线胸片图像进行分类。Shen等[7]使用卷积神经网络、随机森林与支持向量机对肺部CT图像进行肺结节良、恶性分类。秦喜文等[8]将深度森林算法与慢性肾病结合,众多学者为防治结直肠息肉提供医学依据。随着各行业对人工智能(artificial intelligence)需求的增加,也伴随着深度学习(Deep Learning)概念的提出,深度神经网络(Deep Neural Network,DNN)由于其强大的表征学习能力和拟合能力,成为医学等领域的研究热点之一。
DNN也有着明显的缺陷:(1)训练通常需要大量的训练数据,即使是后来学者对于训练数据采取一系列的方式进行数据增强,但深度神经网络依旧很难直接面对数据量较小的人物,即使身处于大数据时代,许多实际任务由于大量客观因素,导致缺乏足够的标记数据量,所以深度神经网络在这些任务中的性能较差。(2)训练时间过长,在深度神经网络学习的过程中,深度神经网络是一个极为复杂的模型,在训练过程中所需硬件与软件设施的配备要求较高。
深度森林(Deep Forest)[9]一种新的决策树集成方法。此算法与深度神经网络的存在不同,该算法对训练样本数据要求不高,并且具有强大的表征学习能力,训练速度可观、参数鲁棒性好等许多优势。
人工智能技术的终极目标是让学习到的模型具有与人类相当的解决问题的能力。国内外学者对结直肠息肉研究主要集中于对结直肠息癌的诊断研究,以提高诊断成功率。本文提出利用深度森林方法对拍摄的CT图像中是否含有结直肠息肉进行分类,并采用了7种方法进行建模比较研究,经实验研究发现使用深度森林方法在结直肠息肉CT图像数据集中具有较好的分类效果。
1 深度森林模型原理
深度森林是以决策树为基础构建的深层模型,是一个基于树的新的集成学习方法,与深度神经网络不同,深度森林整体包括多粒度扫描(multi-grained scanning,MGS)和级联森林(cascade forest,CF)两个阶段。在多粒度扫描阶段进行医学影像的特征学习,提取其样本特征之后,再送入级联森林进行分类预测。
1.1 随机森林
随机森林(Random Forests,RF)[10]是一种基于集成学习的算法,是一个包含多棵相互独立决策树的分类器,将多棵决策树集成起来,其输出的类别是由个别树输出的类别的众数而决定。
随机森林预测模型最终输出结果通过投票方式获得:
(1)
其中:F(X)为组合预测模型;fi为单棵决策树预测模型;R为预测结果;I(·)为示性函数;n为RF中决策树的数量。
RF算法步骤:
1)假设原始训练集为D,利用自助采样方法有放回地抽取k个样本集,循环k次,生成k个样本集D*={D1,D2,...,Dk}。
2)设每个样本有M个原始变量,则在M中随机抽取mtry个变量(mtry≤M),当每个决策树的节点进行分裂时,需要在mtry中选择分类能力最优的变量作为该节点的分裂属性,重复该步骤,生成k棵决策树;
3)由上述步骤生成的k棵决策树组成随机森林,随机森林的分类结果由公式(1)得出。
随机森林分类模型的实现过程如图1所示。

图1 随机森林算法流程
1.2 多粒度扫描模块
多粒度扫描模块是在深度森林模型中引入了类似卷积神经网络的多个滑动窗口。MGS通过使用不同大小的滑动窗口扫描原始输入图像,进行特征提取,生成多个维度的特征实例。将每个特征实例送入一个随机森林和一个完全随机森林进行训练提取类概率向量,最后通过拼接各森林的类概率向量得到转换特征向量。多粒度扫描模块的实现过程如图2所示。

图2 多粒度扫描模块实现过程
1.3 级联森林模块
级联森林为一个拥有自主生长结构的深度树集成方法,每个级联层包含两个随机森林和两个完全随机森林,通过多个森林多层级联得出分类预测结果。相比神经网络,级联森林具有训练过程效率高、可扩展性强且对超参数不敏感等特性。
级联森林的输入特征向量是由多粒度扫描模块产生的样本转换特征向量,级联层学习训练过程中输出的类概率向量结果与原始特征向量拼接作为下一层的输入,每次扩展新的级联层后,模型会评估当前级联森林在验证集上的性能,若无显著性能增益,训练过程将终止,有效减少模型的复杂度。在最后一层将级联森林产生的所有类向量计平均值作为预测类别概率结果,其中最大值对应的类别作为深度森林模型的分类结果。
为了避免级联森林在训练过程中产生过拟合的现象,对每个森林的训练都采用k折交叉验证后产生的类向量。将数据分割成k份,其中一份作为验证数据,其他k-1份用于训练,交叉验证重复k次。每个实例将产生k-1个类向量,对其取平均值后得到下一个级联层的输入类向量。级联森林模块的实现过程如图3所示。
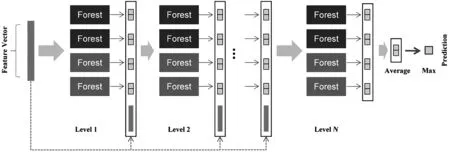
图3 级联森林模块实现过程
2 数据预处理
实验所使用的图像数据均来自百度AI Studio公开的数据集,该数据集包含了1 500张结直肠CT图像,其中857张存在息肉,数据按照8∶2的比例划分为训练集与测试集。由于数据集结直肠息肉CT图像的病灶区域不同、图像摄片时受到各种噪声的干扰所以本文对图像进行预处理操作[11]。预处理包含两个阶段,第一阶段对每张图片采用随机旋转90°倍数的方法进行数据增强,旋转图片不会造成CT图像信息的损失,适合作为本实验数据集扩充的手段,扩充后的数据集为2 700张。数据集扩充结果如表1所示。

表1 数据集扩充结果
第二阶段对CT图像进行灰度化、归一化处理并使用中值滤波算法对CT图像的噪声进行过滤,提高图像清晰度,图像处理前后的对比如图4所示。

(a)原始图像 (b)处理后图像
3 实验结果及分析
3.1 评估指标
CT图像中结直肠息肉检测为二分类问题,有E和N两个分类,分类模型中评估指标的混淆矩阵(Confusion Matrix)计算如表2所示。

表2 二分类问题混淆矩阵
由混淆矩阵计算出的模型评估指标包括分类精度(Accuracy)、召回率(Recall)、精确率(Precision)和F1值,各指标定义如下:
分类精度(准确率)
(2)
召回率(查全率)
(3)
精确率(查准率)
(4)
F1值(F1Score)
(5)
其中:TP(True Positive)为真正例;FP(False Positive)为假正例;TN(True Negative)为真反例;FN(False Negative)为假反例[12];TP+TN+FP+FN=n,n为样本容量。
分类精度可以从总体上评价模型的性能,但在医学领域并不能满足模型评估需求。对于本文结直肠息肉的识别问题,分类精度表明有多少CT图像被正确识别出是否存在息肉,在医学模型评估中,被模型识别出患者中确实存在息肉的患者所占比例也是评价模型性能的重要指标[13],所以本文把F1值(精确率和召回率的调和均值)作为评估指标之一。
3.2 深度森林模型调整
深度森林中级联森林模块具有良好的自适应能力,在训练过程中可以根据模型性能自行确定级联层数量[14],需要手动调整的参数较少且对参数的敏感性低。该模块主要参数有级联层的最大数量、级联层中森林的数量(随机森林与完全随机森林)、单个森林中决策树的数量、基本估计量的选择等。级联森林模块中级联层森林数量与单个森林中决策树数量对结直肠息肉CT图像的分类精度如图5所示。

(a)森林的数量对分类精度的影响 (b)森林中决策树数量对分类精度的影响
由图5可以看出在本实验数据集上,模型性能整体相对稳定。在单个森林中决策树的数量增加到120棵时,模型的分类精度只有98.33%,在决策树的数量设置为20~60时,分类精度达到了99%,且此时模型拥有较少计算量与内存需求。增加级联层中森林的数量时,模型的性能也有所改变,当级联层中设置10个森林(5个随机森林与5个完全随机森林)时,模型达到了99.33%的分类精度。
综合以上实验结果以及模型实际运行效率,将级联森林模型级联层中森林的数量设置为10个(5个随机森林与5个完全随机森林)、每个森林中决策树的数量设置为60,并添加XGBoost作为模型的基本估计量,同时对级联层的最大层数不作要求。经过参数调整后的级联森林模型在测试集上的分类精度达到了99.67%。
完整的深度森林模型包含多粒度扫描模块与级联森林模块两部分,在级联森林模块调整为上述参数后,添加多粒度扫描模块进行实验。实验所使用CT图片大小为512×512,采用两种不同的窗口尺度集合与滑动步长进行实验,每个尺度对应1个随机森林与1个完全随机森林,森林中决策树数量均设置为20,实验结果如表3所示。

表3 多粒度扫描模块参数实验
由表3可以看出,加入多粒度扫描模块后,深度森林模型分类精度最高达到了97.00%,并且随着滑动窗口与滑动步长的减小,模型分类精度降低。取该实验分类精度最高的模型与不使用多粒度扫描模块的深度森林模型进行性能对比,结果如图6所示。

图6 深度森林模块选择实验结果
由图6可以看出,在本文数据集上,使用多粒度扫描模块的模型相比只使用级联森林的模型在测试集上A值与F1值分别下降了2.7%与2.4%。产生这种情况可能是因为多粒度扫描模块会产生多个只包含噪声的训练样本,对于结直肠息肉CT图像来说,有意义的图像仅在于息肉存在的部分,其他无意义的图像部分作为训练样本反而会造成模型泛化性能的下降,所以本文只使用深度森林模型中的级联森林模块。
3.3 不同分类模型比较
本文使用深度森林算法对结直肠息肉CT图像进行分类,为了比较模型的性能,采用K-最近邻(KNN)、随机森林(RF)、卷积神经网络(CNN)、支持向量机(SVM)、BP神经网络(BP)、朴素贝叶斯模型(NBM)与决策树(CART)7种算法进行实验比较,实验均使用处理后的数据集。
其中KNN、SVM与CART均采用基于十折交叉验证的网格搜索方法选择最优建模参数;对NBM中多项式模型、高斯模型与伯努利模型3种常见模型采用十折交叉验证方式分别进行性能评估后,选择多项式模型进行实验;对于CNN中主流模型,本文使用VGG16进行实验,其具有很好的CNN特征提取能力[15]。由于数据集规模大小对VGG16网络训练结果有较大影响,所以在图像预处理第1阶段的基础上,采用翻转、旋转的手段进一步扩大数据集,且第2阶段不进行灰度化处理。处理后数据集容量达到7 500张,将训练集中五分之一的数据作为验证集,总共进行了100次训练。

表4 不同实验方法比较结果
从表4可以看出,深度森林模型在分类精度、召回率、精确率、F1值均高于或等于其他7种分类算法。从分类精度上看,深度森林达到99.67%,其次为支持向量机与K-最近邻模型达到了99.33%的精度;从召回率上看,深度森林、BP神经网络、支持向量机、与K-最近邻模型均达到了100%,说明所有存在息肉的CT图像均被识别出来。从精确率上看,深度森林识别出存在息肉的图片中识别正确的图片占比达到99.40%,最低的为朴素贝叶斯模型,仅仅只有74.03%。
4 结 语
基于深度森林算法对结肠息肉CT图像进行识别分类,并与7种分类算法使用多项评估指标对比,结果表明该方法可提升结直肠息肉检测分类的效果。此外,深度森林在模型鲁棒性、可解释性、训练难易程度上具有优势,这使得本文提出的结直肠息肉CT图像检测方法在医学影像领域具有良好的通用性。本文只对结直肠息肉CT图像进行了分类检测,如何对息肉存在位置进行标注并对检测体系做进一步的优化,提供更加全面精准的检测报告,辅助医生根据CT影像筛查存在疾病的患者并为临床医生提供理论指导,将是下一步的研究重点。
