基于动态双重前缀的模糊相似性连接算法
2022-04-01于长永王雯函温秀静赵宇海
于长永, 王雯函, 温秀静, 赵宇海
(东北大学 计算机科学与工程学院, 辽宁 沈阳 110169)
相似性查找和相似性连接是数据库中处理和分析数据的重要且基础的操作.相似性查找旨在查询与给定query满足相似性条件的数据库中的所有记录.相似性连接旨在从两个集合中找到所有相似的对.它们有许多实际应用,如数据清理与集成、近似重复检测和信息提取等.例如当两个购物网站要合并时,两个网站对同一商品的描述不完全一致,此时就需要找出两个网站中的同一商品并最终合并.因为该数据集很大,高效处理数据是一种重要需求,所以相似性连接在该情况下是一种必不可少的操作.
对于传统的Jaccard算法,根据过滤算法原理,大致可分为以下三种类型:①基于前缀过滤的算法;②基于鸽笼和划分思想的过滤算法;③基于树型数据结构的过滤算法.前缀过滤算法是基于两个数据的前缀至少共享一个元素来实现的[1-3].文献[1]首次提出了前缀过滤的思想,并利用倒排索引实现了快速的相似性连接算法;文献[2]通过将各记录中的元素按照频率由小到大的顺序排序优化了前缀过滤;文献[3]进一步缩小了前缀的长度,利用共享元素的位置信息对候选进行位置过滤,而且该文还对位置过滤的思想进行推广,提出了后缀过滤.基于鸽笼和划分的过滤算法[4-6]主要思想是先根据鸽笼原理将每条记录划分为特定个数的不相交的段,再将这些段作为签名构建索引,最后计算出至少有一个共有段的记录对的集合作为候选集.文献[4]首次利用鸽笼原理提出了PartEnum;文献[5]首次提出了基于全局元素划分的鸽笼过滤算法;文献[6]则在鸽笼原理的基础上进行了优化,提出了一个新的过滤框架来覆盖基于鸽笼原理的过滤框架,并且大多数基于鸽笼原理进行分区的算法都有可能通过采用这个新原理来提高过滤功能.基于树型数据结构的过滤算法[7-8]与上述算法不同,它们不生成签名来构建倒排索引,而是将记录组织到树中,在树中进行过滤.
由于传统的相似性连接问题在寻找相似对时有一些情况并不适用.例如{sweet,hot}和{hit,sweot},虽然它们很相似,但是不论是基于token的相似性函数或者基于字符的相似性函数,它们的相似度都很低,并且基于token的相似性函数的相似度甚至为0,所以文献[9]首次提出了模糊相似性连接问题,利用该算法提出的token敏感签名在前缀过滤的基础上进行过滤可减少候选的数量;并且该算法在记录级使用基于token的相似性函数,而在元素级仅仅支持基于字符的相似性函数.文献[10]则在记录级以及元素级都支持基于token的相似性函数.其在前缀过滤生成签名的部分进行了改进,利用该算法生成的签名以及其提出的检测过滤器和最近邻过滤器进行过滤可大量减少候选的数量,但它在过滤的过程中并没有考虑到token的长度、元素的长度以及token在元素中的位置对过滤性能的影响,所以其过滤效率并不是很高.由于文献[11]是基于鸽笼原理划分记录中的元素来生成签名,共享同一签名的元素对应的记录视为候选对,但由于该算法并没有考虑到记录中匹配的元素的个数对整体相似性的影响,在记录之间一旦有匹配的元素就将其视为候选对,造成候选集中假阳性较高,并且由于该算法通过将全局元素划分来对应各个元素的划分,所以部分元素的划分中可能生成空集,但没有考虑到出现空集时的处理办法.为了解决这些问题,本文提出了一个基于动态双重前缀的相似性连接算法.与之前的基于前缀过滤算法不同的是,之前的算法采用固定前缀,而本文采用了双重前缀方法,即在查找候选以及构建索引时使用不同的前缀来提高过滤效力.在此基础上又对双重前缀过滤方法进行了优化,在保证不漏解的情况下取各种前缀生成的候选集合的交集来缩小候选集合.还设计了一种预验证方法来减少验证阶段所花费的不必要的时间.
1 问题定义

与之前的研究[9-11]一样,本文也采用fuzzy overlap来实现模糊相似性连接.给定两条记录R与S和元素级相似性阈值δ,构建一个二部图G=((X,Y),E),X与Y中的顶点分别是记录R与S中的元素.对于任意的两个元素ri和sj,如果sim(ri,sj)≥δ,在二部图ri和sj之间会存在一条边,该边的权重为ri和sj的相似值.下面是fuzzy overlap的定义.
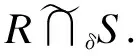
下面利用fuzzy overlap来定义带有元素级相似性阈值δ限制的记录级相似性函数.
Fuzzy-Jaccard Similarity:
Fuzzy-Dice Similarity:
Fuzzy-Cosine Similarity:
2 基于任选前缀的相似性连接算法
2.1 任选前缀
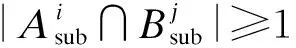
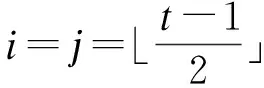
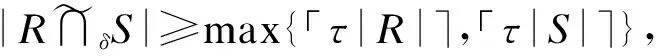
对于Jaccard相似性,若元素ri和sj,满足sim(ri,sj)≥δ,则|ri∩sj|≥max{「δ|ri|⎤,「δ|sj|⎤},即ri和sj至少共享max{「δ|ri|⎤,「δ|sj|⎤}个token.将ttoken=max{「δ|ri|⎤,「δ|sj|⎤}称为元素级overlap阈值.
下面利用记录级fuzzy overlap阈值trecord和元素级overlap阈值ttoken定义模糊Jaccard相似性连接问题中记录的双重任选前缀.
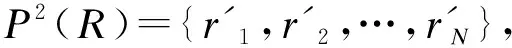
根据定理1和上面的共享元素与共享token的数量,很容易得到以下的结论:
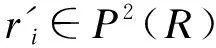
2)ri和sj满足长度过滤;
3)ri和sj对于共享token满足位置过滤.
基于定理2,提出了基于双重任选前缀的模糊Jaccard相似性连接算法,如表1所示.

表1 算法1
2.2 查询最优任选前缀
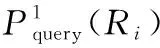
AS-prefixttoken(ri,j)=
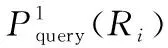
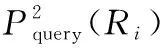
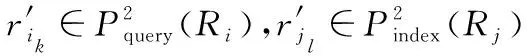
基于上述分析,提出OptimalPrefixQuery(Ri)算法,如表2所示.

表2 算法2
2.3 索引最优任选前缀
在传统前缀方法中,所有的记录按照同一个顺序将元素进行排序,然后选取前面固定个元素作为该记录的前缀.其中的顺序一般选择元素的频数升序的顺序.被选择的前缀中的元素是该记录中频数较低的元素.这样做有利于减少频数高的元素引起的大量候选.本文采用这种方法来选择索引前缀,称之为低频前缀.同时,选择索引前缀时在低频前缀的基础上作了一些改进.
由于Ri的索引前缀仅用于与其后面处理的记录的过滤,即是否与Ri+1,Ri+2,…,Rn形成候选.因此,构造查询前缀时,考虑的不应该是各个token在所有记录中的频数.对于待处理记录Ri,选择所有未处理记录Ri,Ri+1,Ri+2,…,Rn中各个token的低频前缀作为索引前缀.
基于上述分析提出ImprLowFrePrefixIndex(Ri)算法,如表3所示.

表3 算法3
2.4 索引
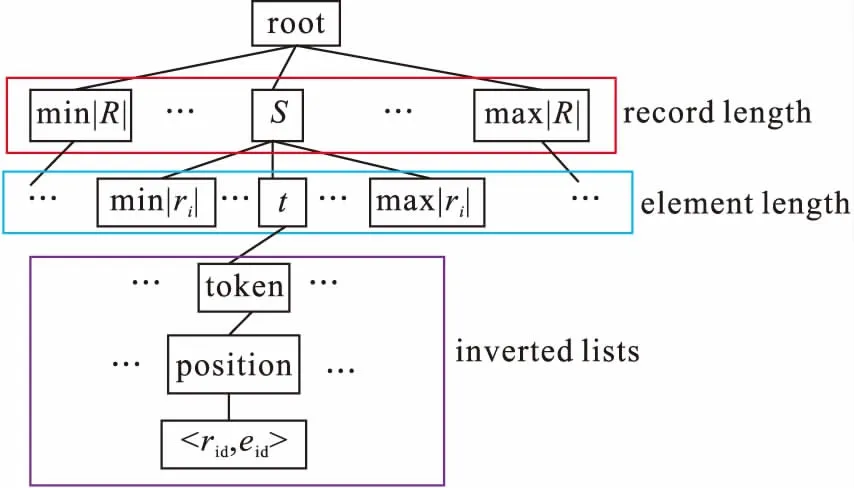
图1 树的索引结构
下面介绍在token生成候选集合时如何利用该索引结构进行过滤,如表4所示.

表4 算法 4
3 优 化
3.1 生成候选的优化
给定两个集合A,B,若在A的某一个任意任选前缀与B的任意任选前缀中有公共token,即在A的候选集合中有B;而在另一任选前缀中与B并没有公共token,即此时A的候选集合中并没有B,那么此时可以断定集合A与B并不相似.
基于此现象,为了减小验证过程所花费的时间,可以在集合中多次选取不同任选前缀,利用不同任选前缀生成的候选的交集来缩小候选集合.然后将此发现应用到二重前缀过滤算法中.
定理3设R1为任意一条记录,C″为采用R1的任选前缀生成的候选集合,C为采用最优任选前缀生成的候选集合,那么R1的最终候选集合为C′←C∩C″.
基于上述分析,提出了优化生成候选算法,该算法分为三阶段来完成.首先初始化候选集合C′为空集并确定任意选择的前缀生成的候选集合C″.在每个元素中任意选择N1个token将其加入到S1(Ri)中,随后在S1(Ri)中任意选择N2个子元素添加到S2(Ri)中,确定S2(Ri)中的每个子元素中的每个token生成的候选,并将候选对添加到C″中.然后确定采用最优任选前缀生成的候选集合C.利用OptimalPrefixQuery()来生成记录的查询前缀,利用生成的查询前缀以及GenCandi()来确定查询前缀生成的候选集合C.最后取C″与C的交集.
3.2 预验证最大区分任选前缀
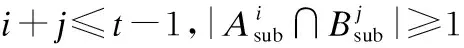
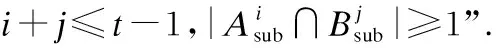
(1)
存在一个匹配,使得
(2)
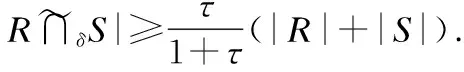
存在一个匹配,边的个数为
e≥d;
(3)
对于任意的i+j≤d-1,
(4)
由式(3)和式(4)可以推出,在二部图中去掉任意少于等于d-1个顶点,图中至少还有一条边存在.
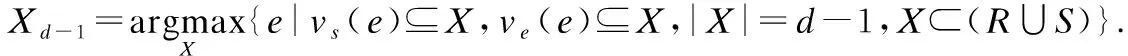
定理4(最大区分前缀确认) 记录R和S的m最大区分前缀的二部图中至少存在一条边等价于记录R和S的二部图中存在一个匹配,其包含边的个数e≥d.
由于在预验证阶段,所有候选对的记录的长度都已知,所以d很容易求得.根据定理4可知,如果在R1与R2的d最大区分前缀的二部图中仍有两个顶点之间互相连接,那么该候选对经过预验证进入最终候选集合进行最后验证.否则,R1与R2不能通过过滤器被过滤掉.
基于上述分析,本文提出了预验证阶段最大区分任选前缀算法.首先根据求得的R1与R2中元素之间的相似值来构建相应的二部图.随后根据两个记录的长度计算最大匹配中元素个数阈值d,并且根据阈值d来确定二部图中需去除d-1个顶点.然后在二部图中去除度数最大的顶点以及与该顶点相连接的边,每去除一个顶点以及相连接的边后都需更新各顶点的度数.此时若二部图G中仍有两个顶点之间有边相连,那么该预候选对经过预验证进入验证阶段.否则,该候选对被过滤掉.
4 结果与讨论
所有实验均在具有Intel Xeon(R)CPU处理器,16 GB RAM,运行Ubuntu 14.04.1的服务器上进行. 所有算法均使用C ++实现,并使用GCC 4.8.4进行编译.
4.1 数据集
在三个广泛使用的数据集上来评估ASOP算法.DBLP:计算机科学出版物的数据集,其中包含题目、作者、出版商等属性.将每个属性看成一个元素,元素中的每个单词看作一个token,从中随机选择了100万个.QUERY LOG:搜索引擎中的查询日志.将每行中的单词看成一个元素,从中随机选择了80万个.WEBTABLE:大型WEB数据库,其中包含来自WEB的数百万个html表.本文从中随机选择了50万个.具体细节如表5所示.
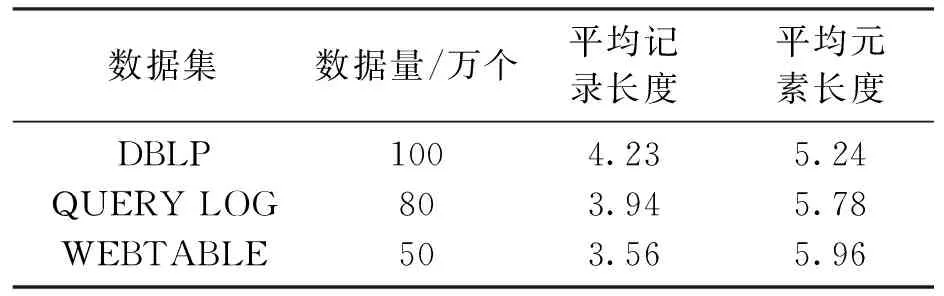
表5 数据集
4.2 本文算法的表现
用AS代表在第2节提出的基于任选前缀的相似性连接算法;ASO代表在第2节AS的基础上加上生成候选的优化算法;ASOP代表在ASO的基础上对候选进行预验证的过程.整个过程所需要的连接时间如图2所示.从图2中可以看到随着相似性阈值τ的增长,三种算法的连接时间都呈下降趋势,且ASOP算法的连接时间明显比ASO以及AS低很多.
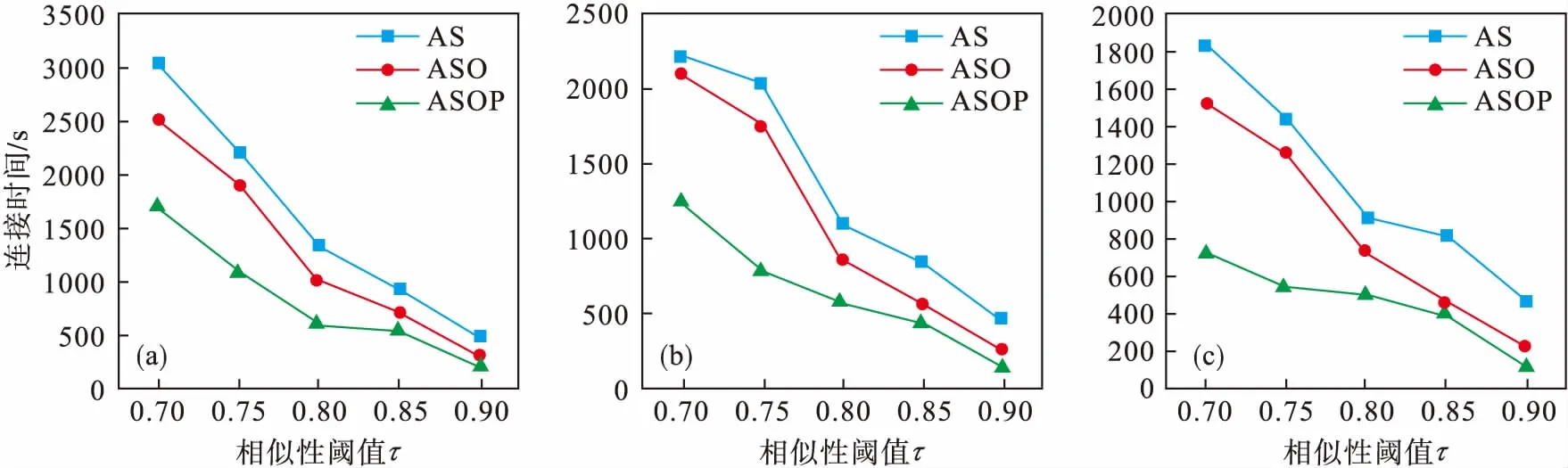
图2 不同数据集上所提算法的连接时间
4.3 与最先进的算法作比较
将本文的方法与最先进的两种算法Silkmoth以及MF-Join作比较.在该实验中,固定元素级相似性阈值δ=0.8,如图3所示.从图中可以看出:1)不论在哪个数据集中,本文提出的ASOP算法的整体性能要远好于Silkmoth以及MF-Join; 2)在三种数据集中,MF-Join的连接时间都要比Silkmoth少; 3)在三个数据集中,ASOP的连接时间要远低于MF-Join.
接下来通过改变元素级相似性阈值δ来对三种算法的连接时间进行讨论.在该实验中,固定相似性阈值τ=0.85,实验结果如图4所示.从图中可以看出,不论在哪个数据集中,随着阈值δ的改变,本文算法的整体表现仍要好于Silkmoth和MF-Join.
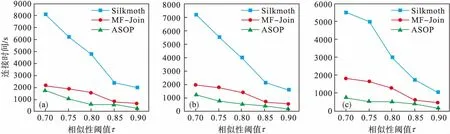
图3 改变τ的值与当前最先进的方法作比较
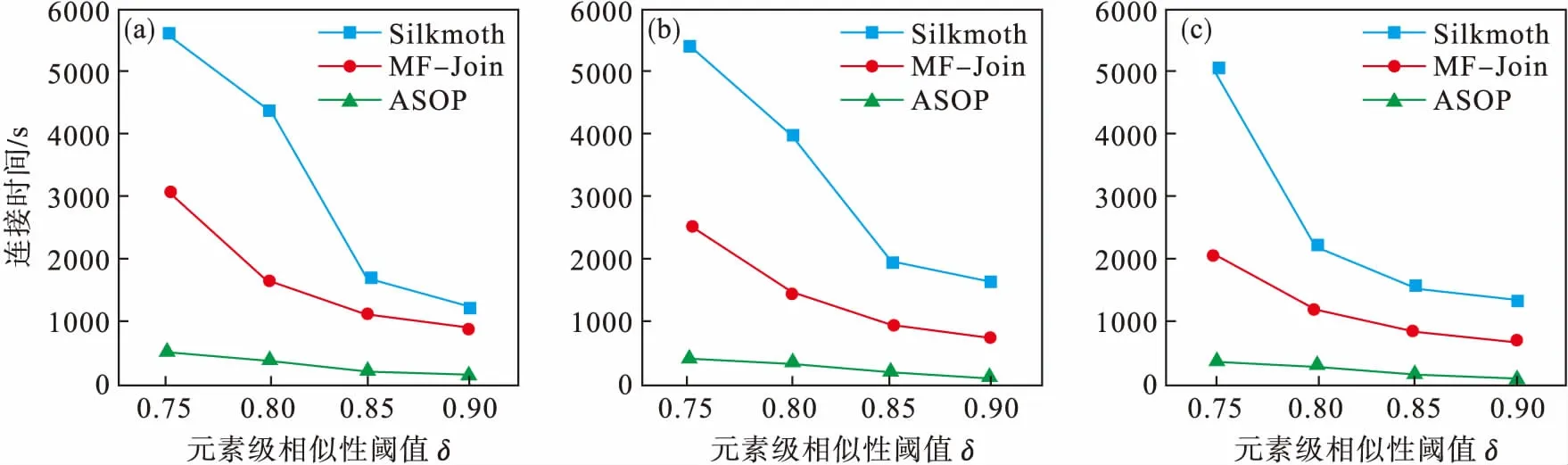
图4 改变δ的值与当前最先进的方法作比较
5 结 语
本文针对相似性连接问题,提出了ASOP算法,并在三个数据集上来评估该算法.从实验结果中可以看出,不论是连接过程所需要的时间、或是生成的候选对的数量,本文提出的ASOP算法的效率都优于Silkmoth以及MF-Join算法.但是由于在构建索引部分加入了token的长度以及位置信息,这就会导致索引所占的空间复杂度很大,今后可以在缩小索引空间上进一步优化.
