基于并行差分进化-梯度特征深度森林的废旧手机识别方法
2022-03-31王子轩张晓晓荆中岭韩红桂
王子轩,汤 健 ,夏 恒,张晓晓,荆中岭,韩红桂
(1.北京工业大学信息学部 北京 100024;2.智慧环保北京实验室 北京 100124;3.北京抱扑再生环保科技有限公司 北京 100124)
1 引言
随着科技的发展和5G的迅速普及,智能手机的更迭速度不断加快.据Strategy Analytics预测,2021年全球智能手机的出货量将同比反弹6.5%,总量达13.8亿部[1].人们更换手机速度的加快是导致其出货量不断提高的主要原因,这也导致个人闲置手机的累计量逐年增多.因此,国内外市场对手机回收产业的回收效率提出更高要求.废旧手机(used moble phone,UMP)作为一种典型的城市再生资源,利用无人化、智能化的回收装备对其进行回收,能够节省大量人工成本.其中:智能化UMP识别方法是完成上述任务的关键.
本文将UMP回收装备的实拍图片作为建模数据集,旨在解决应用于回收装备的UMP识别算法可信度低的问题.以现阶段内置图像识别方法的UMP回收装备为例,回收过程如下:首先,用户根据操作指示将UMP放入回收装备;接着,通过内部摄像头采集手机背部图像;然后,通过智能算法模块对待回收UMP的品牌等特征信息进行识别;最后,根据识别结果提示用户登记相关信息,进而完成回收.
针对UMP识别的研究,现阶段仅有BP神经网络、卷积神经网络(convolutional neural network,CNN)模型应用于回收装备[2],但上述模型的识别精度无法达到回收需求,在回收装备中仅作为识别参考项,后续还需工作人员进行分类,无法有效节省人工成本.因此,建立面向回收装备的高精度、强鲁棒性的UMP识别模型以提高其智能化程度是亟待解决的实际问题.
基于上述研究背景,文献[3]提出“面向智能回收装备的废旧手机深度森林识别模型”,文献[4]采用差分进化算法对其参数进行优化,旨在通过智能化识别算法提高回收效率并降低人工成本,但并未对UMP实拍图像进行定位裁剪等预处理,还存在模型识别率低和参数优化耗时长等待解决问题.
基于回收装备的UMP实拍图像的定位裁剪能够减少无关背景对识别精度的影响,还可降低图像像素和降低模型复杂度.手机定位裁剪问题与“车牌检测”、“红外行人检测”等问题类似.对于上述问题,文献[5]使用YOLOv3算法检测红外图像中的行人;文献[6]使用SLPNet对道路中车牌进行定位检测;文献[7]将Faster-RCNN算法用于超新星的自动检测.上述研究均在包含大量无关背景的图像中使用图像检测算法获取相关内容,与本文需求一致.因此,在UMP识别之初,有必要使用图像检测算法对UMP回收装备拍摄图像的相关区域进行定位裁剪,以减少无关背景的影响.
深度森林(deep forest,DF)模型与深度神经网络模型(deep neural network,DNN)相比,具有超参数少、模型深度自适应等特点,其已被证实在小样本分类问题中具有良好的性能表现[8-9].但是,DF的滑动窗格参数决定了模型性能[10],窗格太小会导致目标过于分散,窗格太大会包含更多无用的背景信息.在数据量较少的UMP识别问题中,DF模型的计算依赖于显存配置,窗格过小也会生成过多的特征,进而产生“休斯效应”;窗格过大则会占用过多计算资源,导致模型极易崩溃.文献[11-12]将含有滑动窗的特征预处理部分更换为卷积特征,使模型能够获取抽象特征,但该种方法所获取特征的可解释性差,难以针对实际问题对预处理部分进行改进.因此,需面向UMP识别问题对DF模型进行改进,提高模型处理图像像素能力的同时,生成适合手机识别问题的特征.
差分进化算法(differential evolution,DE)因具有结构简单、收敛速度快、鲁棒性强等优点,被广泛用于解决连续变量的全局优化问题[13-15].因此,在前文研究中将其作为DF超参数的优化方法,但DE优化时间随模型复杂度的增加而增加,且算法效果依赖于最大迭代次数的设定,错误的设定会使进化时间进一步增加.原始DE算法固有的运算成本导致其无法在短暂时间内完成DF模型的超参数更新.因此,需对DE结构进行改进,提高其进化效率.
综上,本文在实际需求驱动下对相关算法进行改进,提出一种用于真实场景下UMP识别的并行差分进化(parallel differential evolution,PDE)-梯度特征深度森林(gradient feature deep forest,GfDF)识别模型,通过实验验证所提方法在识别精度和训练时间方面的有效性.
2 废旧手机识别问题建模
2.1 废旧手机识别问题描述
在UMP回收装备工作中,易出现摆放位置偏差和手机背部反光等问题,这使得手机图像质量不高(如图1所示),存在镜像、模糊、手机倒置等问题.

图1 回收装备内部UMP实拍图Fig.1 UMP image taken by recycling equipment
由于UMP回收装备实拍图片数量较少且质量不高,常用模型需要大量标记样本进行训练,深度学习算法难以有效应用.因此对小样本手机识别方法进行研究至关重要.
2.2 废旧手机识别模型总体结构
为解决回收装备中UMP识别问题,可选方案有2种.
1)构建CNN网络:使用回收装备实拍图像或其他手机数据集构建UMP识别模型.但基于回收装备的手机图像数量稀少且与其他手机数据集差异性较大,这导致CNN识别精度较低,无法达到工业应用需求.
2)多模型串联的模块化结构:首先,利用目标检测模块在整张图中定位UMP位置;然后,针对UMP位置图像构建小样本识别模型.该种结构目标检测模型消除UMP图像中背景部分的影响,基于小样本图像的识别模型能够有效缓解UMP图像数据少的问题.
本文采取第2种模块化结构构建基于梯度特征深度森林的废旧手机识别方法.本文所提方法将UMP识别过程分为UMP定位裁剪、梯度特征深度森林(Gf-DF)识别两部分.首先,对回收装备拍摄的照片进行UMP定位和裁剪处理;接着,对裁剪后图像进行数据增强,以数据增强后的图像为数据集构建GfDF模型.本文所提UMP识别模型的整体结构如图2所示.

图2 废旧手机识别模型结构图Fig.2 The structure of the UMP regression model
2.3 废旧手机定位剪裁模块
UMP定位剪裁模块用于解决因摆放位置差异引起的图像不完整问题.考虑到该模块用于去除无关背景影响,同时TensorFlow框架中已集成基于ImageNet数据集的Faster-RCNN算法模型,从降低模型复杂度,降低训练成本角度,本文定位算法采用Faster-RCNN目标检测算法,其结构如图3所示.
Faster-RCNN算法是基于候选区域的目标检测算法,由主干网络特征提取、候选区域生成、框架精修分类3部分组成,如图3所示.该算法使用区域生成网络(region proposal network,RPN)替代RCNN族网络中的选择性搜索与候选框生成模块,其具有高准确率且检测时间与直接目标检测算法相近等优势[16].本文所提基于Faster-RCNN算法的UMP定位裁剪模块实现过程如下:
1)VGG16图像特征提取.基于CNN的图像特征提取质量决定了目标检测精度.不同深度CNN提取的特征存在差异性,目前已有ResNet18,VGG16,Res-Net50等CNN模型用于Faster-RCNN图像特征提取部分.已有研究表明采用VGG16作为Faster-RCNN主干网络,模型复杂度较低且提取效果较佳[17-18].
本文基于UMP实拍图像,采用不同主干网络进行“手机”目标检测并以IoU函数作为评价指标,如下所示:
其中:Y表示标注“手机”范围,S表示检测“手机”范围.
IoU评价结果如表1所示,可见ResNet50和VGG16的IoU指标均可达90%以上,且二者差距不明显.这表明在50层ResNet网络较深层的网络的作用并不显著,因此从降低模型复杂度角度考虑,本文采用VGG16作为主干网络,以提高运行效率.

表1 不同主干网络检测结果Table 1 Results on different backbone networks
2)RPN生成候选框.首先,RPN网络根据VGG16卷积结果确定锚点(即候选框中心点);接着,根据锚点位置生成不同大小候选窗;然后,根据softmax函数确定各候选窗内前景和背景信息(如图3中RPN网络上侧所示);同时,RPN网络通过边框回归得到锚点偏移量,用于获取更精确边框(如图3中RPN网络下侧所示);最后,综合所有候选窗前景、背景信息和锚点偏移量获取最终候选框并将其送入下一部分.
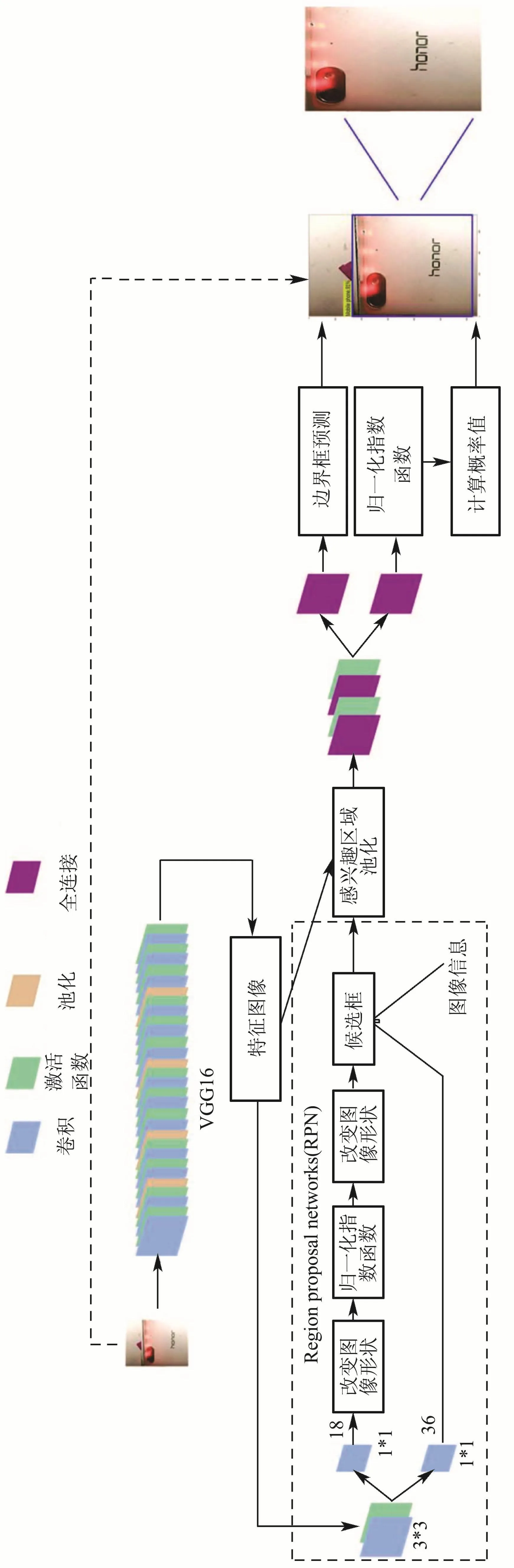
图3 Faster-RCNN结构图Fig.3 Structure of Faster-RCNN
3)候选框分类与图像裁剪.得到候选框后,通过全连接层和softmax函数对候选框内部物体进行分类,若边框内物体是手机的概率最大,则记录边框坐标;同时再次通过边框回归对“手机边框”进行精修,获得最终“手机边框”坐标;最后剪裁手机图片,将“手机边框”内图像传入识别模型中.
2.4 梯度特征深度森林GfDF手机识别模块
原始DF模型由多粒度扫描和级联森林两部分构成,其中:多粒度扫描模块用于特征提取,级联森林模块根据上一模块所提取特征进行识别.多粒度扫描采用滑动窗划分子特征和随机森林子特征提取相结合的方式对二维图像特征进行降维,该方式在增加子特征间联系的同时也加剧了计算资源的消耗,应用于像素较多的UMP图像数据时极易出现内存溢出问题.因此,针对上述问题对DF模型的特征提取部分进行改进.
根据先验知识,UMP识别主要依靠轮廓、摄像头位置、字符logo等纹理特征.HOG特征是计算机视觉和图像处理领域常用的描述图像局部纹理的特征,多用于目标识别领域[19].该特征提取仅涉及求导操作,在较复杂图片特征提取问题上占用计算资源小,速度远优于DF模型的多粒度扫描模块.此外,HOG特征获取过程也具有滑动窗思想.该方法通过改变胞元大小提取不同尺度纹理特征.基于上述优点,本文作者使用不同尺度组合的梯度特征(histogram of oriented gradient,HOG)提取模块代替多粒度扫描模块,实现针对废旧手机识别问题的DF算法改进.本文所述GfDF手机识别模型如图5所示,流程如下所示:
1)数据增强.回收装备拍摄的UMP图像因拍摄环境、手机摆放位置等差异而存在不同.图像倾斜程度尤其影响HOG特征提取结果,因此在训练模型前需对实验数据进行增强,以提高模型鲁棒性.本文方法中数据增强包括高斯噪声、椒盐噪声、图像翻转、图像旋转共4种,数据增强后的图像作为训练集输入后续识别模型.
2)多尺度HOG特征提取.
a)UMP灰度图像横纵坐标梯度提取.HOG特征注重图像轮廓纹理等特征,弱化光照对图像分类的影响,因此在特征提取前需对图像进行二值化,用于获得UMP灰度图像.设灰度图像中某像素点坐标(x,y),其水平方向梯度幅值gx和垂直方向梯度幅值gy如式(2)所示
其中f(x,y)为(x,y)的像素亮度值.
由此,像素坐标(x,y)方向梯度幅值m(x,y)和梯度方向θ(x,y)如式(3)-(4)所示:
b)胞元梯度特征统计,获取每个像素点的梯度值后,将若干相邻像素点组合成胞元特征,根据设定方向梯度的数量计算胞元内像素梯度直方图.例如,将方向梯度θ设置为4,则[0°,90°,180°,360°]作为梯度直方图统计对象,根据θ(x,y)将m(x,y)在统计对象上的投影值计入梯度直方图.进而,将胞元特征表示为梯度直方图矢量CellHOG.
文献[20]表明,当存在空间或序列的特征关系时,多粒度扫描有利于提高模型性能.滑动窗思想使特征能够表征图像像素位置信息,选取不同尺度滑动窗则能够表征不同视野下像素间的位置信息.文献[21]表明,多尺度特征融合能获取更多图像特征.基于上述思想,作者将HOG特征胞元特征作为放缩因子,选取不同胞元大小的HOG特征作为级联森林模型的输入特征,以实现特征增强.不同尺度HOG特征的线性组合如下所示:
3)级联森林识别.GfDF模型仍采用原始DF模型中的级联森林部分.首先,将多尺度HOG特征提取结果XHOG作为输入,利用随机森林(random forest,RF)和完全随机森林(complete random forest,CRF)并列构建识别子模型;接着,将识别子模型的结果和XHOG级联形成后构建新的识别子模型,若识别精度有所提高则重复上述步骤实现模型深度的自适应;否则,基于平均加权策略得到识别模型.此外,上述子模型的识别精度均采用交叉验证方式获得.
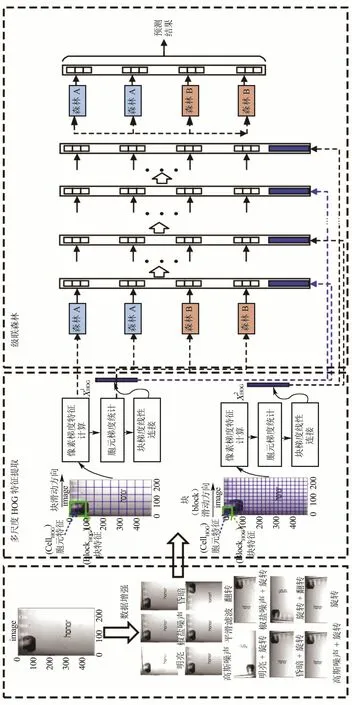
图4 GfDF识别模型结构Fig.4 Structure of GfDF recognition model proposed
3 并行差分进化参数寻优方法
深度模型参数是影响模型性能的重要因素.与DNN相比,DF及本文所提GfDF分类模型超参数数量远少于DNN模型,且GfDF模型参数多数为决策树参数,无法通过迭代获得最优值.已有研究表明,参数寻优算法能对多个参数同时寻优以提高识别模型精度[22].因此,本文拟采用差分进化算法(DE)对GfDF模型参数进行调整.
DE广泛应用于求解多维空间中的整体最优解,但模型中的参数寻优需要对大量目标函数进行评估.经典DE算法的典型运行时间为数小时至数天[23].为改善DE进化耗时长问题,作者提出一种并行DE算法(parallel DE,PDE),其利用多种群并行和缩小子种群规模的方式缩减进化时间,同时以约束迭代中子种群进化方向的方式进一步提高进化效率.该算法可分为寻优参数编码、参数初始化、种群划分、并行进化共4部分.
1)寻优参数编码.首先,PDE算法对需要优化的参数进行编码,将实际问题转换到进化空间.GfDF识别模型中的HOG特征尺度表示在候选HOG特征组合中选取特征的尺度和数量,该参数直接影响后续模型的输入特征维度;因此,将作为优化参数之一.由第1.3小节可知,级联森林模型由不同类型的随机森林构成,本文选取随机森林中决策树数量J、决策树最大特征数Mj作为优化参数进行编码.
2)参数初始化.本文所提PDE算法包括种群NP规模fsize(NP)、子种群数量A、子种群放缩因子F、子种群交叉概率CR共4个超参数,其中:fsize(NP)和A作用于种群划分,影响算法的进化时间和收敛速度;F和CR作用于并行进化过程中的每个子种群,影响子种群收敛的速度.
3)种群划分.算法根据子种群数量A随机划分,其过程可表示为
其中fsize(·)代表种群NP的规模.
4)并行进化.其分为子种群独立进化和PDE整体进化两部分.其中:子种群在设定迭代次数内独立完成进化过程;整体进化环节需汇总各子种群的局部最优解,进而形成局部最优解集,根据相似度度量结果判断是否需要继续进化.
a)子种群独立进化.
进化过程之初,子种群会对当前子种群中的染色体进行解码和适应度评估.GfDF识别模型的适应度评估值决定了当前子种群是否需要在设定迭代次数内继续进化.以第α个子种群的第0代sub_NPα(0)为例代表第m条染色体.
子种群的进化策略与标准DE策略一致,分为“变异”、“交叉”和“选择”3个部分.
变异:PDE算法选用收敛性较强的DE/current-tobest/1策略完成子种群变异
交叉:子种群个体的交叉重组与染色体中待优化变量密切相关.第t+1代第m条候选染色体如下:
其中randk是在[0,1]生成的随机浮点数,当设定的交叉概率CR小于randk时,执行交叉重组操作.
每个子种群进化达到设定迭代次数或满足适应度评估值后,得到局部最优解,如下:
b)PDE整体进化.
完成一次并行进化后,汇总各子种群局部最优解得到局部最优解集合,如下:
PDE整体进化过程中,根据欧氏距离度量局部最优解集合中各元素的相似性,其中任意的两个元素,如其相似度Dα,β的计算如公下:
4 实验验证
为验证所提方法的有效性,在UMP实拍数据集上进行验证性和对比性实验.
4.1 数据集介绍及实验环境
本文所述UMP识别模型基于python3.7及Tensor-Flow-GPU-2.3.0框架构建.其训练和测试硬件环境如表2所示.

表2 硬件配置Table 2 Hardware con figuration
废旧手机回收装备的应用场景如图5所示,本文实验数据源于该装备的实拍图片.数据集共123张图像,包含8个类别的手机品牌,分别是华为(HUAWEI)、荣耀(Honor)、小米(Mi)、中兴(ZTE)、OPPO、VIVO、苹果(Apple)、其他品牌(Others).

图5 废旧手机回收装备应用场景Fig.5 Application scenarios of UMP equipment
数据集划分方面,由于所用DF模型具有交叉验证步骤,因此仅将数据按8:2划分为训练集和测试集.由于实验数据较少,采用数据增强手段对训练集和测试集样本进行扩充.将定位剪裁预处理后将处理后的UMP图像进行旋转、翻折、加噪声等数据增强操作,处理后的数据集共1476个样本.考虑到非90°的旋转操作再对图片进行放缩会导致手机图片失真.针对90°整倍数旋转,会产生旋转90°和旋转180°两种情况,对应的图片会变为270×480,480×270大小,针对上述现象,本文借鉴空间金字塔池化(spatial pyramid pooling,SPP)方式,通过设定HOG特征中block参数将不同block的HOG特征进行线性拼接,使最终特征向量长度一致.样本扩充如图6所示.

图6 数据增强示意图Fig.6 Effection of data enhancement
4.2 手机定位裁剪实验
由前文描述可知,原始数据集中存在大量异常样本(约60%),为解决数据集出现的图像不完整、镜像、倾斜等问题,本文采用Faster-RCNN算法对原始UMP图像进行“手机定位”,得到仅包含UMP特征的图片,实现背景和噪声干扰的消除.
本文所用回收装备实拍UMP图像数据较少,对异常图像进行人工标定并训练模型的方式难以实现,因此基于迁移学习思想采用TensorFlow_hub模块中固化的由ImageNet数据训练完成的Faster-RCNN模型实现“手机定位”.
原始数据集像素为640×480,长宽比为4:3,而当前市场常见手机比例为16:9.因此,在确定手机定位坐标后,将剪裁图像统一设定为480×270像素,并尽可能保证定位后手机图像的长宽比.
4.3 DF改进对比实验
首先验证多尺度HOG特征在梯度特征DF模型中的有效性;接着,以定位剪裁后的UMP图像作为数据集,将多尺度梯度特征DF模型与同规模滑动窗DF模型进行对比,以说明DF改进算法在识别精度和训练时间方面的优越性;最后,在数据量较少的基准图像数据集中进行验证,进一步说明本文所提DF改进算法在小样本图像分类问题中的有效性.
1)多尺度HOG特征有效性验证.不同胞元HOG特征可视化结果如图7所示,其中:左图为裁剪后UMP图像,右图为块尺度[2,2],胞元特征分别为[36,36],[25,25],[4,4]的HOG特征可视化结果.以剪裁、数据增强后的UMP数据作为数据集,不同尺度HOG特征的对比实验结果如表3所示.显然,胞元特征较小的特征图可获取更多纹理细节特征,但由于UMP图像数据量较少,模型不能通过小样本学习得到所有特征.随后,本文采用线性搜索方式获取效果显著胞元特征,结果如图7所示.

图7 HOG特征可视化Fig.7 HOG feature visualization

表3 不同尺度HOG特征对比实验结果Table 3 Comparison of results of HOG features at different scales
由图8可知,随着胞元的增大,单块HOG特征内将包含更多无关背景信息,同时模型的识别精度也会下降.因此,识别准确率随胞元特征增长呈现先增后减的趋势.

图8 胞元特征线性搜索结果Fig.8 Cell scale linear search results
不同尺度HOG特征组合实验的结果如表4所示.

表4 HOG特征组合对比实验结果Table 4 HOG feature combination comparison experiment results
由上述结果可知,不同尺度HOG特征进行线性拼接可有效提高UMP识别准确率;但拼接后特征数量超过模型表征能力,导致识别精度有所下降.如何从众多候选特征组合中获得最佳特征组合将是参数寻优部分的重点内容.
2)GfDF模型在UMP数据集中的有效性验证.由手机定位裁剪实验可知,废旧手机识别模型输入为480×270像素的图像.多次实验表明,原始DF模型受限于计算机内存,其无法根据480×270像素的UMP图像进行训练.因此,在对比实验中将图像尺寸缩小为原来的1/5(即96×54)进行训练.实验以原始图像输入的梯度特征DF模型,降维图像输入的GfDF模型、原始的DF模型为基础,胞元特征和滑动窗尺寸均为[25,25]+[60,60],分别从识别准确率、训练时间两个角度进行验证.GfDF及原始DF对比实验结果如图9所示.

图9 GfDF及原始DF的对比实验结果Fig.9 GfDF and original DF contrast experimen
降维数据输入的GfDF模型与原始的DF模型的识别准确率相近,但GfDF模型稳定性优于原始DF模型且训练时间明显缩短;像素为480×270的回收装备实拍UMP图片可直接传入GfDF模型进行识别,模型识别准确率略高于降维数据训练模型.
3)GfDF模型普适性验证.为进一步验证本文所提DF改进算法在小样本图像识别问题中的有效性,使用图像分类基准数据集分别构建原始DF模型和GfDF模型.识别效果和模型训练时间对比分别如表5和表6所示.

表5 基准数据集的DF及GfDF识别精度对比Table 5 Comparison of DF and GfDF recognition accuracy of benchmark data sets

表6 不同数据集的DF及GfDF训练时间对比Table 6 Comparison of DF and GfDF training time of different data sets
由表5-6可知,GfDF在图像数据集上表现明显优于原始DF模型的性能.
4.4 PDE参数寻优实验
由第1.4小节可知,本文将HOG特征尺度XkHOG,级联森林模型的决策树数量J和决策树最大特征数Mj作为优化参数进行编码.最佳胞元特征为二维寻优问题,难以在短时间内获得最优解,且多种不同胞元特征的组合会进一步增加该参数寻优的候选空间,这使寻优算法的时间复杂度剧增.因此,在寻优之初通过前文实验经验对效果较优秀、跨度较大的胞元特征进行选择,通过排列组合的方式生成候选多尺度HOG特征并对其进行预编码.候选HOG特征如表7所示.

表7 HOG特征候选表Table 7 HOG feature candidate list
DE参数寻优问题中,种群差异性决定了解空间的覆盖范围,这使得初始种群范围的选取尤为重要.在PDE算法中,每个子种群功能与原始DE算法是一致的,而各子种群由初始种群划分得到.此外,子种群的数量决定了算法寻优时间,因此在PDE算法中的总种群设定包括种群规模和子种群切分数量两部分.优化效果及优化时间的箱线图如图10所示.


图10 GfDF及原始DF的对比实验结果Fig.10 PDE optimization box plot
为进一步说明所提结构化UMP识别模型中各模块必要性,作者采用控制变量法对识别模型进行分析,结果如表8所示.

表8 UMP识别模型消融实验表Table 8 UMP recognition model ablation experiment
最后,将本文所提方法与当前主流小样本分类模型进行比较,其中:微调(fine-tuning)方法中使用ImageNet作为原始数据集训练VGG16和ResNet50,将卷积层权重参数固定,采用本文所述废旧手机图像训练最后的全连接层参数;元学习(meta learning)方法中采用基于度量准则(metric based)的Siamese network,使用网络爬虫获取手机背部图像训练一个VGG16网络,再通过图像训练另一个VGG16网络,利用欧氏距离计算相同类别高清样本与实拍样本在对应模型中的高维特征相似度,具体结果如表9所示.

表9 多模型精度对比Table 9 Accuracy comparison of multiple models
由结果可知,GfDF方法精度虽然略低于微调方法的ResNet50网络,但本文所提方法无需在大规模数据集中进行预训练,训练成本较低、模型复杂度低.
5 结论
本文针对废旧手机回收装备中的手机识别算法存在的精度低、可信度差等问题,提出一种基于并行差分进化算法-梯度特征深度森林算法的识别方法,其创新点如下:
1)首次提出由手机定位裁剪模块、梯度特征深度森林识别模块、并行差分进化参数优化模块组成的识别算法,实现对回收装备拍摄废旧手机图片的定位裁剪和识别.
2)对原始深度森林模型进行改进,首次提出梯度特征深度森林模型,使其更加适用于基于纹理特征的废旧手机图像识别问题.此外,通过MNIST等基准图像数据集验证了所提方法相比于原始DF模型在识别精度上具有显著提升.
3)改进差分进化算法为并行模式,并首次将其应用于梯度特征深度森林模型超参数寻优问题.
实验表明,本方法对回收装备实拍图像识别准确率和训练时间均优于其他算法.但本文方法仍存在一定不足,例如:在多尺度特征选择方面并未筛选各尺度HOG特征中的有效信息,且研究过程中仅采用HOG特征作为分类特征,下一步本文作者将对手机图像不同区域提取不同尺度HOG特征进行加权组合,在特征工程部分增加颜色矩、特定位置纹理等特征,进一步提高识别模型在废旧手机回收问题中的可靠性.
