基于爬虫技术的医疗行业舆情监控系统的设计与实现
2022-03-30孟庆昊李青君
孟庆昊,沈 妍,李青君,苏 波
(首都师范大学 物理系,北京 100037)
以互联网为媒介的网络舆情信息是网民在特定事件中的态度、意见和看法,具有强烈的情感表达色彩[1]。在21世纪这个信息化的时代背景下,数以亿计的用户在微博上围绕国家政策、民计民生、娱乐八卦等话题不断产生出海量的体现着个人意志的舆情数据,若不加以引导,任由其肆意发展那么谣言重伤、恶语相向将会充斥着整个社会,由此可见建立一个完善的舆情监控体系显得尤为重要[2]。
2020年新冠肺炎席卷全球,医疗行业受到社会广泛关注,随之而来的便是海量舆情信息的爆发,针对这一社会现状,本课题以Python作为开发语言,设计实现一套基于爬虫技术的医疗行业舆情监控系统。摒弃以往数据获取方式,为解决数据信息获取困难等问题。本系统使用通用爬虫作为数据源获取手段进行系统开发,并以CSV文件的形式存储数据。系统以自然语言处理作为工作核心,使用Sonw模型、朴素贝叶斯算法、Jieba分词、LDA聚类以及关键词提取等技术对初始数据集进行处理和分析,使用PyEcharts、Tkinter工具将处理结果和舆情信息以可视化界面的方式向用户展示出来。
1 网络爬虫简介
网络爬虫(Web Crawler)又称为网络蜘蛛(Web Spider),是一个智能抓取网页的程序,网络爬虫最初设计用于搜索引擎中,成为搜索引擎不可缺少的组成部分。首先给定一些种子链接放到爬虫队列中,网络爬虫通过链接对应的页面抓取新链接放到队列中,继续抓取更多的链接,重复这一周而复始的过程,直到满足爬虫设定的终止条件为止[3]。按照爬虫的功能、结构、爬行策略以及实现技术的不同,网络爬虫可以划分为3大类:通用爬虫(General Crawler)、聚焦爬虫(Focused Crawler)和深度爬虫(Deep Crawler)。
2 舆情监控系统的设计与实现
2.1 技术可行性分析
本舆情监控系统使用Anaconda进行开发,用到了一些Python自带的库文件:包括Pyecharts可视化库、CVS存储爬取数据、Tkinter库搭建操作界面等。本系统所用技术如下:
(1)Anaconda是主流的Python IDE之一,拥有很多方便高效的工具,是Python开发人员的得力助手。另外还支持基于Django框架的专业Web开发,是一款开源的Python开发平台。
(2)本系统主要借助了一些Python内置的库文件,如re、selenium、pandas、requests、os、pickle等模块。这些模块拿之即用,免去了繁琐的开发过程,极大地提高了开发效率。
(3)Ui界面采用Python内置的Tkinter,相较于Pyqt5小巧,并且高效,完全能胜任本系统的功能需求。
2.2 功能需求分析
2.2.1 舆情采集模块
舆情采集利用网络爬虫技术来完成微博上关于医疗卫生行业热点话题的信息采集。
2.2.2 数据处理模块与舆情应用模块对爬取到的数据进一步筛选统计处理,需完成下述功能:舆情信息查询即实现对医疗舆情信息的基于关键词的数据查询功能;
统计分析即对医疗舆情信息进行归类汇总,通过自然语言处理,根据不同条件形成可视化数据;
舆情预警是整个系统的核心功能之一,通过文本的情感倾向性分析,进行舆情信息正负面情绪识别,并对负面医疗舆情进行预警。
2.2.3 系统管理模块
该模块实现用户注册、用户登录、医疗关键字设定等主要系统功能。
2.3 系统设计
2.3.1 系统总体结构设计
通过对医疗行业舆情监控系统的整体分析,将系统功能划分为4大功能模块,其体系结构如图1所示。
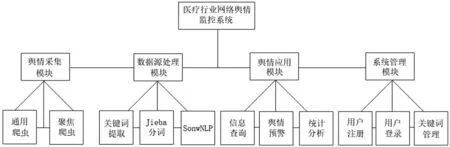
图1 系统总体结构图
2.3.2 数据处理流程设计
系统数据处理模块主要完成对微博上公开的医疗行业舆情信息的清洗、处理和存储,为接下来实现数据可视化展示打下基础。系统数据处理流程图如图2所示。
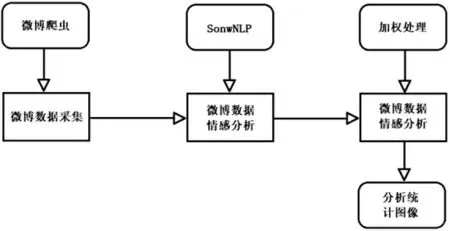
图2 数据处理流程图
2.4 系统实现
2.4.1 情感分析功能
舆情信息的情感分析处理是基于Python的SonwNLP模型作为情感分析的模型,该模型原理是机器学习中的Naive-Bayes分类方法,对数据文本利用Jieba分词工具进行分词并使用哈工大停用词表去除停用词[4]。在此基础处理后,提取单句的关键词信息,将单句评论的词汇作为模型特征:(ω1,ω2,...,ωn),再利用朴素贝叶斯公式进行打分:
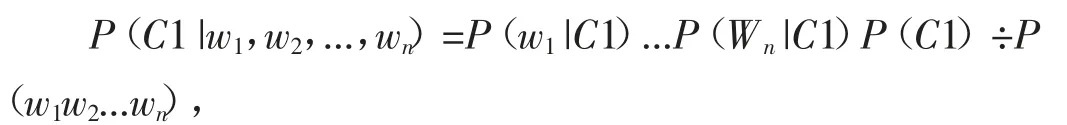
其中:C1代表积极类情绪,等式右边的计算基于训练好的模型,分数越高代表语句情感越积极。情感分析功能实现如图3所示。
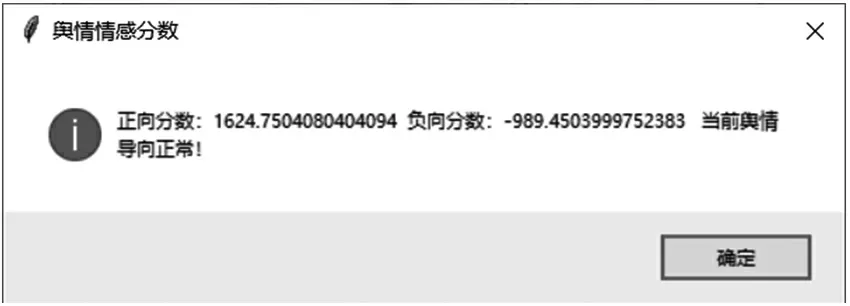
图3 情感分析结果图
2.4.2 关键词搜索功能
舆情信息关键词搜索功能涉及的核心算法有LDA聚类、关键词提取技术等。首先根据关键词信息对整个数据源LDA聚类,筛选出符合要求的微博数据。作为一个主题生成模型,同时也是一个三层贝叶斯概率模型,用于基于关键词的数据筛选效果良好[5]。接着使用NLP技术中的关键词提取技术,对符合条件的微博数据进行关键词提取整合。最后交付可视化系统进行展示。如图4所示为搜索关键词为“医疗”时用户关注的舆情信息词云生成图。

图4 关键词搜索词云生成图
2.4.3 可视化功能实现
通过对舆情信息获取模块爬到的数据源经过上述处理后,利用Python可视化包库进行数据统计、画出数据分析结果柱状图、饼状图、关键词词云等可视化图像。医疗行业网络舆情监控系统主界面如图5所示。
图5 系统界面图
3 结论
本课题选取通用爬虫作为数据获取工具,以自然语言处理技术作为核心工作,成功设计出一套基于爬虫技术的医疗行业舆情监控系统,对时下热点话题——新冠肺炎的舆论监控和导向起到了一定的作用。
