不同方法对冬小麦地块级估产的适用性研究
2022-03-25王哲奇
柳 琳 徐 鹏 王哲奇
(1. 正元地理信息集团股份有限公司, 北京 100000;2. 绍兴市上虞区规划管理服务中心, 浙江 绍兴 321300)
0 引言
冬小麦是中国的主要粮食作物,播种面积占粮食播种面积的1/5。及时、准确地监测预报大范围冬小麦产量数据,可为政府部门根据国内外农产品市场需求的变化,调整农业种植结构提供科学依据。
遥感技术提供了快速估算大面积冬小麦产量的唯一经济、可行的方法。文献分析发现目前遥感估产中最为有效的方法有2种:一是利用数据同化技术,把遥感反演参数信息融入作物机理过程模型之中,实现大面积作物生长状态及产量模拟的目的[1-2],如基于Wofost[3]、Oryza2000[4]、WheatSM[5]、ChinaAgroys[6]四个作物模型所构建的中国作物生长模拟监测系统(crop growth monitoring system-china,CGMS-China),CGMS-China对冬小麦各主产省的平均预报相对误差为7%[7];二是基于统计模型方法的遥感估产。支持向量回归这种传统统计学习方法并不适合大规模数据处理,当前基于神经网络法的作物估产得到了快速发展[8]。同时,随机森林(random forest,RF)是一种基于分类与回归树的机器学习算法,由BREIMAN提出[9],相对于传统决策树构建方法,其优越性体现在同等运算率下的高预测精度,以及在处理多维特征上对多重共线性并不敏感的特性[10],目前在农作物产量预估方面,也取得了优于支持向量机(support vector machine,SVM)、反向传播(back propagation neural network,BP)神经网络等算法的性能[11-12];KAUL等[13-14]结合气候、气象和土壤等数据用人工神经网络进行作物估产,在不同区域中人工神经网络相比于多元线性回归模型都有了优越表现。WANG等[15]在You的研究基础上,使用深度学习方法对巴西的大豆进行估产,在解决遥感应用的实际需求中,发现深度学习方法在遥感数据分析中具有极大的应用潜力。
本文以中国冬小麦主要产区黄河中下游河南省为研究对象,以像元和地块为基本单元,使用Sentinel-2遥感数据和实地采样数据,分别建立基于长短期记忆网络(long short-term memory,LSTM)、RF、SVM的冬小麦估产模型,进行精度对比和适用性评价,旨在为冬小麦估产提出新的研究思路。
1 研究区概况与数据来源
1.1 研究区概况
河南省是我国重要的人口和农业大省,跨31°23′N~36°22′N,踞东经110°22′E~116°38′E,地势西高东低。河南省所处纬度是亚热带季风气候带与温带季风气候带的交界处,具有雨热同期、复杂多样的气候特点。河南省粮棉油等主要农产品产量均居全国前列,是全国重要的优质农产品生产基地。2009年全年粮食总产达到1 078亿斤,连续四年突破千亿斤,连续10年产量居全国第一。因此,研究适合于河南省农作物估产的遥感评估方法至关重要。
1.2 Sentinel-2多光谱数据
Sentinel-2是高分辨率多光谱成像卫星,携带一枚多光谱成像仪(multispectral imager,MSI),高度为786 km,可覆盖13个光谱波段,幅宽达290 km。一颗卫星的重访周期为10 d,两颗互补,重访周期为5 d。可见光、近红外、短波红外,具有不同的空间分辨率,地面分辨率分别有10、20和60 m。在光学数据中,Sentinel-2数据是唯一一个在红边范围含有三个波段的数据,这对监测农作物信息非常有效,因此可将其用作冬小麦估产的数据来源。
1.3 地面采样数据
此次研究选取河南省62个产量大县作为小麦调查区域,根据县域内小麦面积,每县均匀预选取10~15个点,按照导航定位至目标地块。重点关注低产、受灾地块,到达田块后先大致观察并记录田块的情况,例如倒伏、病虫害等,并依据实际到达位置记录地块经纬度。依次用取样框取样,取样时记录样本框中(样框大小30 cm×30 cm)的穗数,用于计算亩穗数;然后从框中取5个穗(需要满足水分仪测量需求,提前一天实测,如有需要,适当增加穗数),脱粒用于计算平均穗粒数。每个地块测5次穗数,一共取25个穗,共采集产量样本点6 090个。
2 研究方法
2.1 随机森林
随机森林(RF)是一种集成学习方法,是基分类器的分类回归树算法(classification and regression tree,CART)构建的决策树。针对分类问题,利用投票法进行最后结果的计算;针对回归问题,采用简单平均方法得到最终结果,由于这里随机森林回归是由简单平均方法进行最后结果的集成,容易导致低值高估以及高值低估问题。
随机森林的抽样机制包括Bagging以及Boosting,其中Bagging是在每次训练过程中,从原始样本集有放回地随机抽取一个子集,再利用该子集对分类器进行训练。而Boosting则是对每个样本赋予权重,代表该样本被选入训练集中的概率,Boosting还会对每个分类器也赋予权重,代表该分类器分类结果的置信度,在模型训练过程中,会根据预测样本与真实样本差异,动态调整权重,使得模型可以学习到困难样本。随机森林具有两种随机机制,即随机选取训练样本以及随机选取属性集,即使用部分属性集进行分类器构建。随机性的引入使得随机森林方法避免陷入过拟合并且具有很好的抗噪声能力,提高了学习稳定性。
2.2 支持向量机
支持向量机(SVM)是一种监督学习算法,基本思想是使用核函数将输入数据转换到高维空间,核函数既可以是线性,也可以是非线性,完全取决于实际应用中自变量与因变量关系。支持向量机既可以用于分类,也可以用于回归。当将其用于分类时其目标是寻找合适的超平面分隔不同类的样本,并最大化距离超平面最近的数据与超平面的间隔;当将其用于回归任务时,其目标是最小化距离超平面最远数据与超平面间隔。本文的单产预估属于回归任务。
随机森林、支持向量机等机器学习算法显著优点是在较少的假设下,可以通过信息挖掘较好地实现大范围的作物产量预估,过程简单,且具有普适性的潜力。相比于作物模型,该方法无法表达各因素对产量影响的具体机理。同时,本文发现,利用不同生长时段的样本建模,模型的预测精度不同,表明变量的时段是模型非常重要的影响因素之一。
2.3 网格搜索
在机器学习模型中,需要人工选择的参数称为超参数,如随机森林中决策树的个数、人工神经网络模型中隐藏层层数和每层的节点个数、正则项中常数大小等。超参数选择不恰当,就会出现欠拟合或者过拟合问题。在选择超参数时,有两个途径,一是凭经验微调;另一个是选择不同大小参数,带入模型中,挑选最优参数。
网格搜索(Grid Search)是一种用来选取最优参数的穷举搜索法:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终结果。当模型中有多个参数需要确定时,网格搜索算法使用每组超参数训练模型并挑选验证集误差最小的超参数组合。
2.4 长短期记忆网络
长短期记忆网络(LSTM)是一种循环神经网络(recurrent neural network,RNN)特殊类型,可以学习长期依赖信息。所有RNN都具有一种重复神经网络模块的链式形式。在标准RNN中,这个重复的结构模块只有一个非常简单的结构tanh层。而在LSTM中,tanh层结构复杂得多。
LSTM的关键是细胞状态,通过精心设计“门”的结构来去除或增加信息到细胞状态。LSTM有三个门:遗忘门、输入门、输出门。LSTM的第一步是通过遗忘门决定,会从细胞状态中丢弃冗余信息,然后通过输入门确定新信息被存放在细胞状态中,最终通过输出门确定输出值。这种运算方式理解起来就是将上一时刻的部分信息进行压缩或更新,然后再加上本时刻信息,通过这种方式来记忆长期信息。
由于独特的设计结构,LSTM适合于处理和预测中间隔和延迟非常长的重要事件,例如本文中的冬小麦估产。本文所用的LSTM模型,其中包括四层LSTM模型,并且还添加Dropout层以防止模型过拟合。
2.5 精度验证
根据相关系数(R)、均方根误差(root mean squared error,RMSE)对从Sentinel-2多光谱数据中得到的冬小麦估产结果进行了准确性分析。
3 结果分析与讨论
3.1 像元级产量预估
本文采用SVM模型、RF模型机器学习方法以及LSTM模型深度学习方法,进行像元级的冬小麦产量预估。利用格网搜索进行机器学习参数的优化,使用均方根误差作为优化参数标准。SVM模型的最优参数为:使用线性核函数,惩罚因子C为800,gamma值为0.01。RF模型的最优参数为:使用bootstrap框架,最大的弱学习器n_estimators为200,最大特征数max_features为6。
图1为得到的结果,在实验中,以8∶2比例随机划分训练集和测试集。SVM模型,训练集预估产量与实测产量R=0.57,测试集预估产量与实测产量R=0.50。RF模型,训练集预估产量与实测产量R=0.96,测试集预估产量与实测产量R=0.59。

(a)为SVM在训练集上的精度
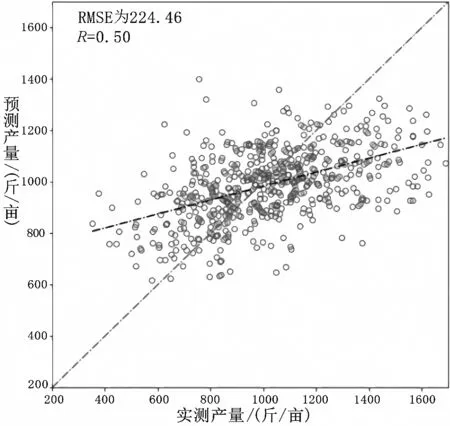
(b)为SVM在测试集上的精度

(c)为RF在训练集上的精度

(d)为RF在测试集上的精度
从实验结果分析,RF模型的总体精度要高于SVM模型,其原因可能为RF的预测能力对输入数据集的适应能力更强。本实验的输入数据为Sentinel-2影像原始波段序列数据,数据的特征维度较高,SVM模型易受到共线性影响,其精度要低于RF模型。但是RF模型的结果呈明显地过拟合现象,主要原因为其训练集精度要远高于测试集精度。因此SVM模型、RF模型泛化能力还有待提高,更适用于区域内小范围的估产。
图2为LSTM模型最终得到的预估产量,其预估产量与实际产量间的相关性比SVM模型的结果高,比RF模型的结果低。而在测试集上,LSTM模型对于高产部分的预估产量相关性要好于SVM模型和RF模型。对于LSTM模型最终预估精度还有进一步提高的空间,主要是因为模型结果以及参数还待优化,没有充分发掘深度学习模型的潜力,但LSTM模型泛化能力强、普适性高,更适用于大范围农作物估产。表1为三种模型的精度对比结果。

(a)训练集
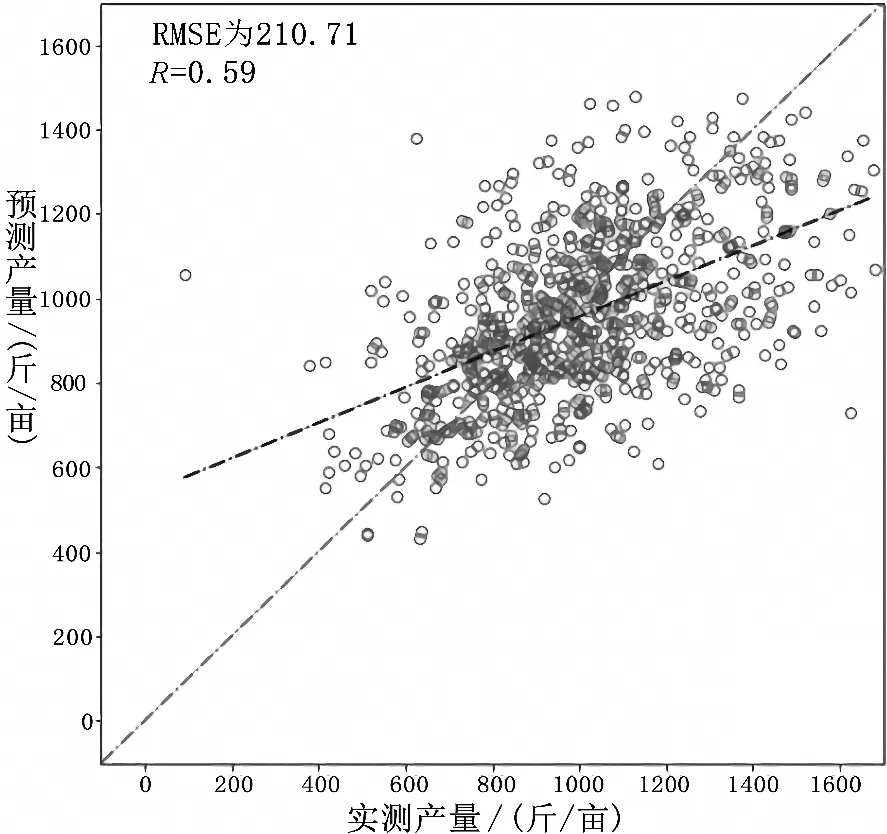
(b)测试集

表1 SVM,RF,LSTM模型精度对比
3.2 地块级的冬小麦产量预估
利用不同估产模型对地块级的冬小麦产量进行预估,地面采样时利用五个样点生成一个样方,在后续进行地块生成时,基于五个样点生成凸包多边形作为地块,五个样点的平均产量作为该地块的平均产量。
在进行地块数据提取的时候,基于时空遥感云服务平台(PIE Engine)进行数据预处理,每10 d进行影像的中值合成,生成原始影像的时间序列数据,并在地块范围内对影像数据取平均。后续的模型训练流程与像元级产量预估的模型训练流程相同。利用格网搜索优化机器学习参数,使用均方根误差作为优化参数的标准。SVM模型的最优参数为:使用线性核函数,惩罚因子C为200,gamma值为0.1;RF模型的最优参数为:使用bootstrap框架,最大的弱学习器n_estimators为200,最大特征数max_features为8。LSTM模型的最优参数为:使用fit函数,分割比例为0.2,训练周期为100次,数据块大小为16。
图3为使用SVM、RF、LSTM模型得到的最终的结果,其结果与直接进行像元级估产有明显的提高,对比来看,其均方根误差(RMSE)有一定程度的降低,且LSTM模型精度较高,分析其原因可能是地块区域内小麦产量实测样本数,足以表征整个地块的产量。因此LSTM模型更适用地块级的冬小麦估产。
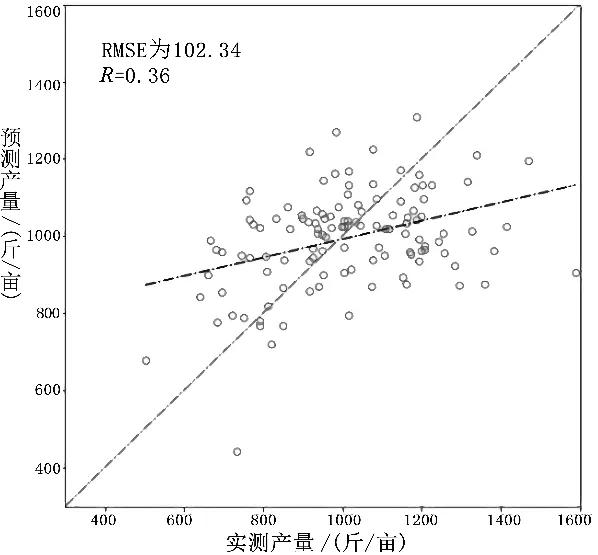
(a)SVM

(b)RF
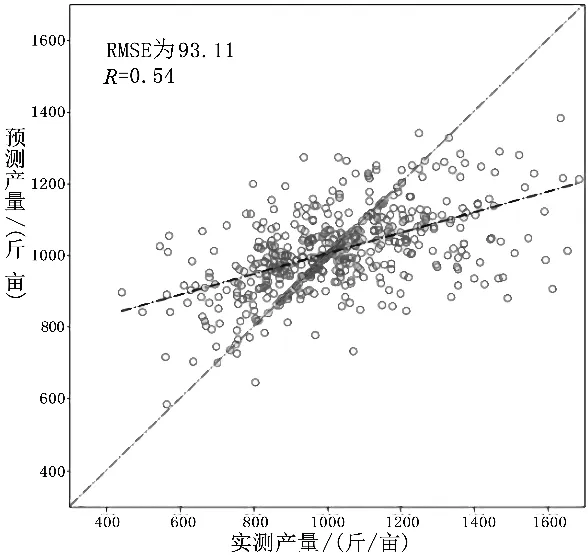
(c)LSTM
4 结束语
本文采用了SVM模型、RF模型机器学习方法以及LSTM模型深度学习方法,进行像元级和地块级的冬小麦产量预估,得出如下结论:
(1)进行像元级估产,SVM模型和RF模型易受到特征共线性的影响,且RF模型的结果呈现明显地过拟合现象,其训练集精度要远高于测试集精度,因此SVM模型和RF模型更适用于小范围的估产;
(2)进行地块级估产,LSTM模型估产精度明显高于SVM模型、RF模型,且LSTM模型泛化能力强、普适性高,因此LSTM模型更适用于大范围农作物地块级估产;
(3)构建LSTM模型需调节的参量相比SVM模型、RF模型更加合理,其模型结构影响最终预测估产结果精度,LSTM模型不仅能表征作物在生育期的生长变化,同时能够降低人为因素的干扰,估产结果更加客观真实。
虽然本文实现了利用LSTM模型进行河南省冬小麦的产量预估,但是精度有进一步提升空间。针对以上优势与不足,提出以下两点改进措施:
(1)利用一定大小的窗口提取周围像元的信息,将二维空间信息与该像元一维序列信息进行融合,以提高产量预估的精度;
(2)利用雷达SAR遥感数据对表层土壤物理性质比较敏感的特性,与具有热红外波段的光学影像融合,进行农作物的估产研究,可降低光学特征权重造成地过拟合影响估产精度。
